Dokumen ini menjelaskan cara kerja tim Dukungan dan tim engineering produk dalam mengatasi insiden dan memberikan info terbaru kepada Anda. Google Cloud
Diagram berikut menunjukkan tanggung jawab tim dukungan dan rekayasa produk.

Bagian berikut menjelaskan tanggung jawab ini.
Deteksi
Google Cloud menggunakan pemantauan internal dan sintetis untuk mendeteksi insiden. Untuk mengetahui informasi selengkapnya, lihat Bab 6 dalam buku Site Reliability Engineering.
Respons awal
Saat insiden terdeteksi, tim Google Cloud Kesehatan Layanan akan mengelola komunikasi dengan pelanggan. Notifikasi awal insiden biasanya singkat, sering kali hanya menyebutkan produk yang bermasalah. Hal ini karena kami lebih memprioritaskan notifikasi yang bersifat cepat daripada mendetail. Detailnya dapat diberikan dalam info terbaru selanjutnya.
Untuk memberikan informasi sebanyak mungkin kepada Anda tanpa membuat Anda kewalahan dengan masalah yang tidak memengaruhi Anda, saluran komunikasi yang berbeda akan digunakan, bergantung pada cakupan dan tingkat keparahan masalah:
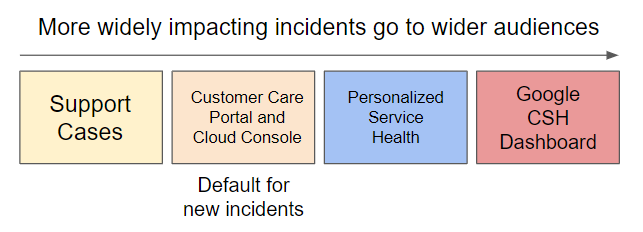
Investigasi
Tim engineering produk bertanggung jawab untuk menyelidiki akar penyebab insiden. Manajemen insiden sering kali dilakukan oleh Site Reliability Engineer, tetapi bisa dilakukan oleh software engineer atau yang lainnya, bergantung pada situasi dan produk. Untuk mengetahui informasi selengkapnya, lihat Bab 12 dalam Buku Site Reliability Engineering.
Mitigasi dan perbaikan
Masalah dianggap telah diperbaiki hanya jika perubahan yang dibuat diyakini oleh Google akan meniadakan dampak yang timbul untuk selamanya. Misalnya, perbaikan dapat menghapus perubahan yang memicu insiden.
Saat insiden sedang berlangsung, Service Health dan tim produk akan mencoba memitigasi masalah. Mitigasi adalah tindakan untuk mengurangi dampak atau cakupan masalah, misalnya dengan menyediakan resource tambahan sementara untuk produk yang mengalami kelebihan beban.
Jika mitigasi tidak ditemukan, jika memungkinkan, tim Status Layanan akan menemukan dan menyampaikan solusinya. Solusinya berupa langkah-langkah yang dapat Anda ambil untuk mengatasi kebutuhan yang mendasari, meskipun terjadi insiden. Solusinya mungkin menggunakan setelan yang berbeda untuk panggilan API guna menghindari jalur kode yang bermasalah.
Tindak lanjuti
Saat insiden berlangsung, tim Service Health akan memberikan info terbaru secara rutin. Info terbaru biasanya berupa:
Informasi selengkapnya tentang insiden tersebut, seperti pesan error, zona atau wilayah yang terpengaruh, fitur mana yang terpengaruh, atau persentase dampaknya.
Progres menuju mitigasi, termasuk semua solusinya.
Linimasa komunikasi, yang disesuaikan dengan insiden.
Perubahan status, seperti saat insiden diperbaiki.
Retrospektif
Semua insiden menjalani retrospeksi internal untuk sepenuhnya memahami insiden dan mengidentifikasi peningkatan keandalan yang dapat dilakukan oleh Google. Peningkatan ini kemudian dilacak dan diterapkan. Untuk mengetahui informasi selengkapnya, lihat Bab 15 dalam Buku Site Reliability Engineering.
Laporan insiden
Saat insiden memiliki dampak yang sangat besar dan serius, Google memberikan laporan insiden yang menjelaskan gejala, dampak, penyebab utama, perbaikan, dan pencegahan insiden di masa mendatang. Seperti halnya retrospektif, kami memberikan perhatian khusus pada langkah-langkah yang kami ambil untuk belajar dari masalah dan meningkatkan keandalan. Tujuan Google menulis dan merilis retrospektif adalah agar transparan dan menunjukkan komitmen kami dalam membangun produk yang stabil bagi pelanggan.