Cette page explique comment l'architecture Memorystore pour Redis Cluster prend en charge et fournit la haute disponibilité. Cette page explique également les configurations recommandées qui contribuent à améliorer les performances et la stabilité des instances.
Pour en savoir plus sur les considérations spécifiques à la région, consultez Zones géographiques et régions.
Haute disponibilité
Memorystore pour Redis Cluster repose sur une architecture à disponibilité élevée dans laquelle vos clients accèdent directement aux VM Memorystore pour Redis Cluster gérées. Pour ce faire, vos clients se connectent aux adresses réseau des partitions individuelles, comme décrit dans Se connecter à une instance Memorystore pour Redis Cluster.
La connexion directe aux partitions offre les avantages suivants :
La connexion directe évite tout point de défaillance unique, car chaque partition est conçue pour échouer indépendamment. Par exemple, si le trafic de plusieurs clients surcharge un emplacement (segment d'espace de clés), l'échec du shard limite l'impact au shard responsable de la diffusion de l'emplacement.
Une connexion directe évite les sauts intermédiaires, ce qui minimise le délai aller-retour (latence client) entre votre client et la VM Redis.
Configurations recommandées
Nous vous recommandons de créer des instances multizones à disponibilité élevée plutôt que des instances monozones, car elles offrent une meilleure fiabilité. Toutefois, si vous choisissez de provisionner une instance sans réplicas, nous vous recommandons de choisir une instance à zone unique. Pour en savoir plus, consultez Choisir une instance à zone unique si votre instance n'utilise pas de réplicas.
Pour activer la haute disponibilité de votre instance, vous devez provisionner au moins un nœud répliqué pour chaque partition. Vous pouvez le faire lorsque vous créez l'instance ou mettre à l'échelle le nombre de réplicas à au moins un réplica par shard. Les réplicas permettent un basculement automatique lors d'une maintenance planifiée et en cas de défaillance inattendue d'un shard.
Vous devez configurer votre client en suivant les conseils des bonnes pratiques concernant les clients Redis. En utilisant les bonnes pratiques recommandées, votre client OSS Redis peut gérer automatiquement et de manière fluide les changements de rôle (basculements automatiques) et d'attribution d'emplacements (remplacement de nœuds, effectuer un scaling horizontal/diminution du nombre de consommateurs) pour votre cluster sans aucun temps d'arrêt.
Instances dupliquées
Une instance Memorystore pour Redis Cluster à disponibilité élevée est une ressource régionale. Cela signifie que les VM principales et répliquées des partitions sont réparties sur plusieurs zones pour se prémunir contre une indisponibilité zonale. Memorystore pour Redis Cluster est compatible avec les instances comportant entre 0 et 5 réplicas par nœud.
Vous pouvez utiliser des répliques pour augmenter le débit de lecture en les mettant à l'échelle.
Pour ce faire, vous devez utiliser la commande READONLY afin d'établir une connexion qui permet à votre client de lire les répliques. Pour en savoir plus sur la lecture à partir de répliques, consultez Mise à l'échelle avec Redis Cluster.
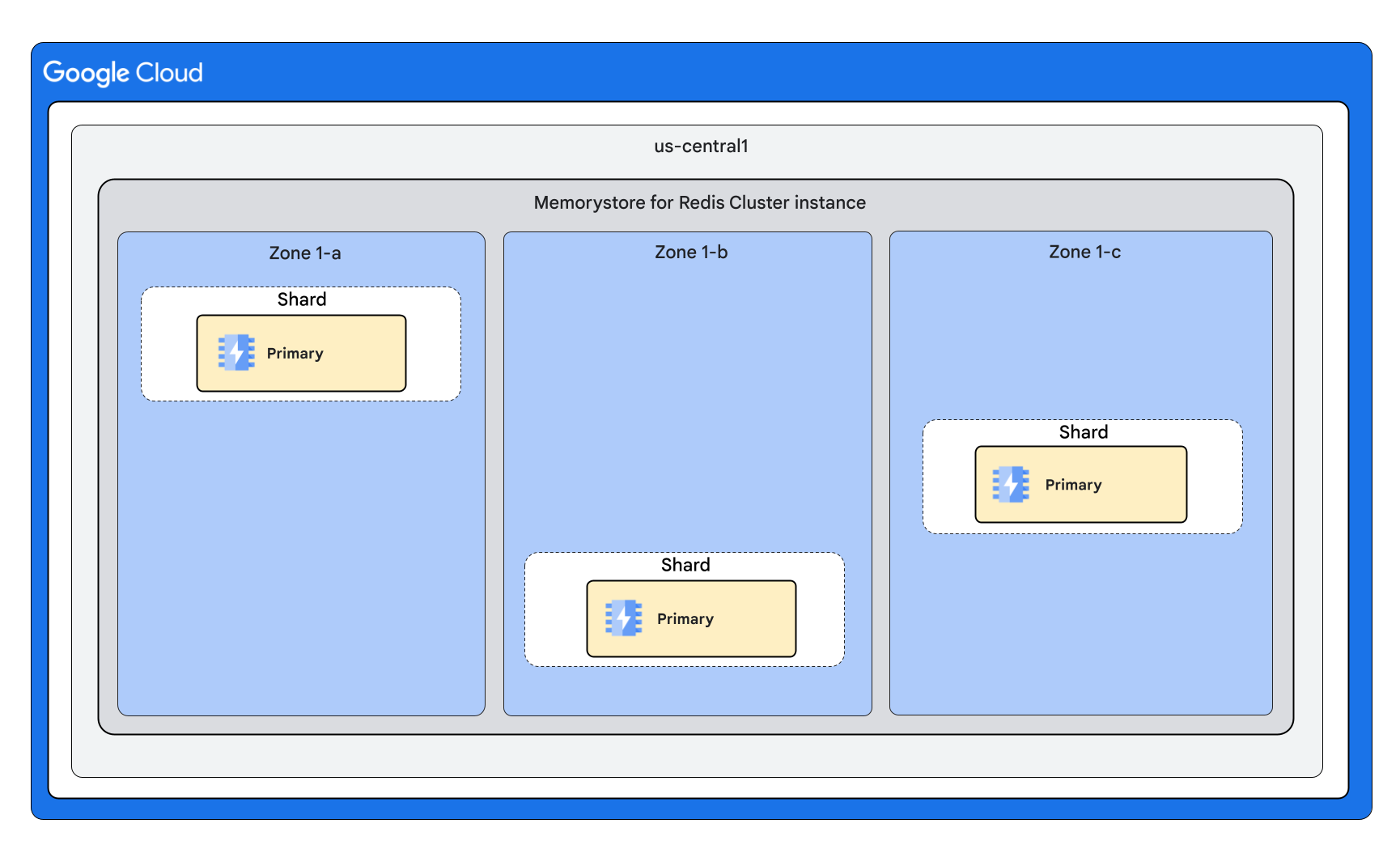
Forme du cluster avec 0 réplique par nœud
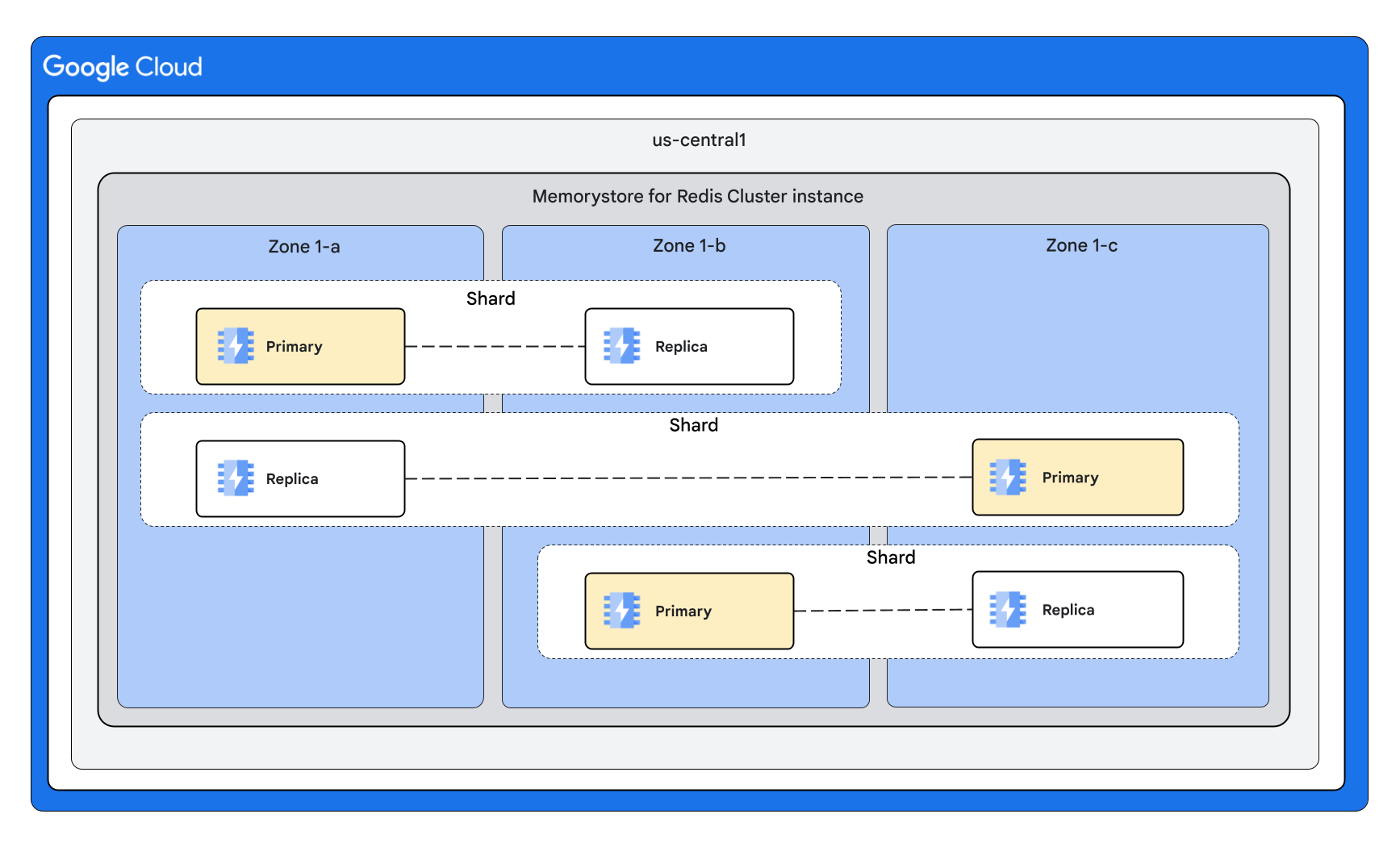
Forme du cluster avec un réplica par nœud
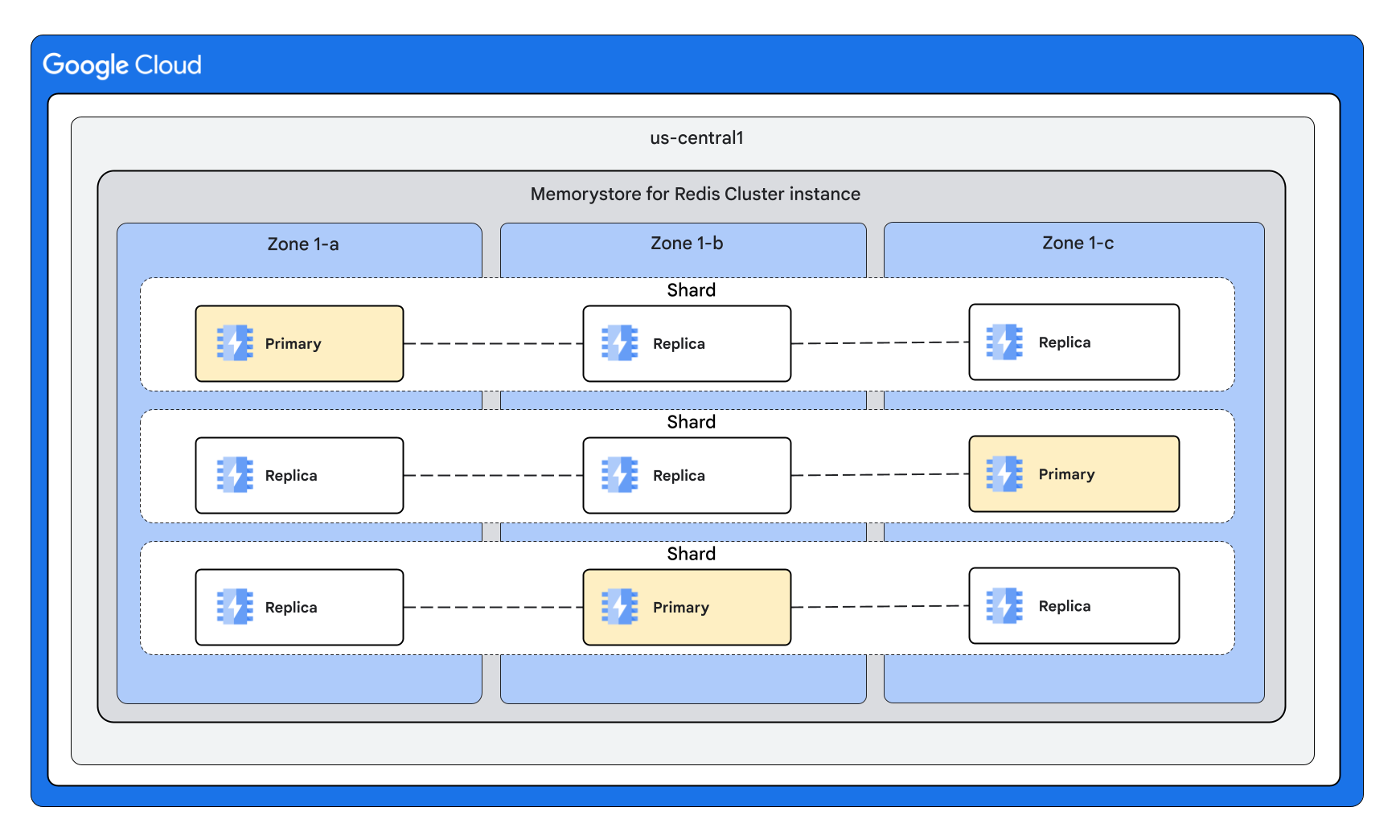
Forme du cluster avec plusieurs répliques par nœud
Basculement automatique
Les basculements automatiques au sein d'un shard peuvent se produire en raison d'une maintenance ou d'une défaillance inattendue du nœud principal. Lors d'un basculement, une instance répliquée est promue au rang d'instance principale. Vous pouvez configurer explicitement les répliques. Le service peut également provisionner temporairement des réplicas supplémentaires lors de la maintenance interne pour éviter tout temps d'arrêt.
Les basculements automatiques empêchent la perte de données lors des mises à jour de maintenance. Pour en savoir plus sur le comportement du basculement automatique pendant la maintenance, consultez Comportement du basculement automatique pendant la maintenance.
Durée du basculement et de la réparation des nœuds
Les basculements automatiques peuvent prendre plusieurs dizaines de secondes pour les événements imprévus tels qu'un plantage du processus du nœud principal ou une défaillance matérielle. Pendant ce temps, le système détecte la défaillance et choisit une instance répliquée comme nouvelle instance principale.
La réparation d'un nœud peut prendre plusieurs minutes avant que le service ne remplace le nœud défaillant. Cela s'applique à tous les nœuds principaux et de réplique. Pour les instances à disponibilité élevée (aucune instance répliquée provisionnée), la réparation d'un nœud principal défaillant prend également quelques minutes.
Comportement du client lors d'un basculement non planifié
Les connexions client sont susceptibles d'être réinitialisées en fonction de la nature de l'échec. Après la récupération automatique, les connexions doivent être réessayées avec l'algorithme de backoff exponentiel pour éviter de surcharger les nœuds principaux et répliqués.
Les clients qui utilisent des réplicas pour le débit de lecture doivent se préparer à une dégradation temporaire de la capacité jusqu'à ce que le nœud défaillant soit automatiquement remplacé.
Écritures perdues
Lors d'un basculement résultant d'une défaillance inattendue, les écritures confirmées peuvent être perdues en raison de la nature asynchrone du protocole de réplication de Redis.
Les applications clientes peuvent utiliser la commande Redis WAIT pour améliorer la sécurité des données dans le monde réel. Il s'agit d'une approche au mieux qui présente des compromis, comme expliqué dans la documentation de la commande Redis WAIT.
Impact d'une panne de zone unique sur l'espace de clés
Cette section décrit l'impact d'une panne dans une seule zone sur une instance de cluster Memorystore pour Redis.
Instances multizones
Instances à haute disponibilité : en cas de défaillance d'une zone, l'intégralité de l'espace de clés est disponible pour les opérations de lecture et d'écriture. Toutefois, comme certaines instances dupliquées avec accès en lecture sont indisponibles, la capacité de lecture est réduite. Nous vous recommandons vivement de surprovisionner la capacité du cluster afin que l'instance dispose d'une capacité de lecture suffisante en cas de panne d'une seule zone (ce qui est rare). Une fois la panne terminée, les réplicas de la zone concernée sont restaurés et la capacité de lecture du cluster revient à sa valeur configurée. Pour en savoir plus, consultez Modèles d'applications évolutives et fiables.
Instances non HA (sans réplicas) : si une zone est en panne, la partie de l'espace de clés provisionnée dans la zone concernée fait l'objet d'un vidage des données et n'est pas disponible pour les écritures ou les lectures pendant toute la durée de la panne. Une fois l'indisponibilité terminée, les instances principales de la zone concernée sont restaurées et la capacité du cluster revient à sa valeur configurée.
Instances à zone unique
- Instances HD et non HD : si la zone dans laquelle l'instance est provisionnée est en panne, le cluster est indisponible et les données sont vidées. Si une autre zone est indisponible, le cluster continue de diffuser les requêtes de lecture et d'écriture. Une fois la panne terminée, la capacité configurée du cluster est restaurée.
Bonnes pratiques
Cette section décrit les bonnes pratiques concernant la haute disponibilité et les répliques.
Ajouter une instance répliquée
L'ajout d'un réplica nécessite un instantané RDB. Les instantanés RDB utilisent un fork de processus et un mécanisme de copie à l'écriture pour prendre un instantané des données de nœud. En fonction du modèle d'écriture dans les nœuds, la mémoire utilisée par les nœuds augmente à mesure que les pages concernées par les écritures sont copiées. L'empreinte mémoire peut atteindre le double de la taille des données dans le nœud.
Pour vous assurer que les nœuds disposent de suffisamment de mémoire pour effectuer l'instantané, conservez ou définissez maxmemory à 80 % de la capacité du nœud afin que 20 % soient réservés aux frais généraux. Cette surcharge de mémoire, en plus des instantanés de surveillance, vous aide à gérer votre charge de travail pour obtenir des instantanés réussis. De plus, lorsque vous ajoutez des réplicas, réduisez le trafic en écriture autant que possible. Pour en savoir plus, consultez Surveiller un cluster avec une charge d'écriture élevée.