Esta página oferece uma vista geral da replicação entre regiões para o Memorystore for Redis Cluster.
Para obter instruções sobre como gerir a replicação entre regiões, consulte o artigo Trabalhe com a replicação entre regiões.
A replicação entre regiões permite-lhe criar clusters secundários a partir de um cluster principal para disponibilizar o cluster para leituras em diferentes regiões. Os clusters secundários também oferecem redundância para cenários de recuperação de desastres em caso de falhas regionais.
Os conceitos-chave nesta página incluem o seguinte:
- Cluster principal. Um cluster de leitura/escrita numa única região.
- Clusters secundários. Um cluster secundário é um cluster só de leitura que é replicado a partir do cluster principal de forma assíncrona. Para obter informações sobre a promoção e a desassociação de servidores secundários, consulte as secções Alternância e Desassociar do artigo Como trabalhar com a replicação entre regiões.
- Nó replicador. Um nó no fragmento do cluster principal que é replicado para um nó seguidor no cluster secundário. Qualquer nó principal ou de réplica no fragmento pode desempenhar a função de replicador.
- Nós seguidor. Nós no cluster secundário que são replicados a partir de um nó replicador no cluster principal. Apenas os nós principais no cluster secundário podem ter a função de seguidor.
- Número de fragmentos e atribuição de espaços. Os clusters principal e secundário têm o mesmo número de fragmentos e atribuições de espaços.
Vantagens
As vantagens da replicação entre regiões no Memorystore for Redis Cluster incluem o seguinte:
- Recuperação de desastres. Se a região do cluster principal ficar indisponível, pode mudar para um cluster secundário noutra região ou separá-lo para atender pedidos de leitura e escrita. Os clusters secundários estão sempre prontos para publicar pedidos de leitura sem emitir um comando de comutação ou desanexação.
- Dados distribuídos geograficamente. A distribuição geográfica dos dados aproxima-os de si e diminui a latência de leitura.
- Balanceamento de carga geográfico para tráfego de leitura. No caso de ligações lentas ou sobrecarregadas numa região, pode encaminhar o tráfego para outra região.
Comportamento das funcionalidades
Esta secção explica o comportamento importante da replicação entre regiões que deve ter em atenção.
- Aumentar a capacidade da instância. Quando dimensiona a capacidade da instância do cluster principal, os clusters secundários são dimensionados automaticamente para corresponder ao principal.
- Aumentar o número de réplicas. Pode dimensionar o número de réplicas para clusters primários e secundários de forma independente com base nas necessidades da carga de trabalho. As atualizações à contagem de réplicas são apenas locais e não são propagadas a outros clusters na coleção de clusters de replicação entre regiões.
- Alternância durante uma potencial indisponibilidade. Pode fazer uma comutação para promover um cluster secundário, mesmo que o cluster principal esteja indisponível devido a uma interrupção. Neste cenário, o cluster principal indisponível torna-se eventualmente um cluster secundário quando a indisponibilidade é resolvida.
- Criação de clusters secundários online. Quando adiciona um cluster secundário a um cluster principal, o cluster principal permanece online. O servidor principal processa pedidos enquanto o secundário é criado e replica dados.
- Clusters secundários. Pode ter até dois secundários. Podem estar localizados em todas as regiões disponíveis. Se quiser, podem estar localizados em regiões diferentes. Não é possível tornar um cluster existente num cluster secundário. Só é possível adicionar novos clusters como clusters secundários a um cluster existente.
- Definições sincronizadas. A maioria das definições é sincronizada automaticamente entre os clusters principal e secundário. Para mais informações sobre estas definições, consulte o artigo Definições de cluster.
- Preços. Os clientes que usam a replicação entre regiões vão receber cobranças por todos os clusters secundários aprovisionados para a replicação entre regiões. Para cada nó e réplica implementados no cluster secundário, os clientes são cobrados como em qualquer outro cluster principal. Além disso, os clientes incorrem em custos de rede pela transferência de dados entre clusters em regiões diferentes.
- Atualização de manutenção. Para garantir a compatibilidade com a replicação entre regiões, o cluster principal pode ser submetido a uma atualização de manutenção durante a criação do cluster secundário, se ainda não estiver a executar a versão de software necessária. Este processo de atualização pode introduzir alguma latência adicional quando cria o cluster secundário. Para mais informações sobre a manutenção, consulte o artigo Acerca da manutenção.
Como trabalhar com a replicação entre regiões
Trabalhar com a replicação entre regiões do Memorystore for Redis Cluster envolve as seguintes tarefas:
- Crie um cluster secundário. Cria um cluster secundário que é replicado continuamente a partir do cluster principal.
- Veja um cluster secundário. Pode ver informações sobre um cluster secundário, incluindo o nome do cluster principal e o outro cluster secundário no grupo de replicação.
Desassocie clusters secundários. A separação de clusters secundários é uma operação na qual separa os clusters secundários do respetivo cluster principal. Isto torna-os clusters totalmente funcionais e independentes que permitem leituras e escritas. Após uma operação de desassociação, os clusters secundários deixam de replicar dados do cluster principal ao qual estavam associados anteriormente. O cluster principal original e os clusters recentemente separados (antigos secundários) funcionam como clusters independentes sem relação entre si.
Existem dois cenários principais para desassociar clusters secundários:
- Migração regional. Realizar uma migração planeada dos recursos do Memorystore for Redis Cluster da respetiva região principal para outra região.
- Recuperação de desastres. Ative rapidamente os recursos do Memorystore for Redis Cluster numa região secundária caso os recursos na região principal fiquem indisponíveis. Se os clusters secundários não estiverem totalmente sincronizados com o cluster principal, pode ocorrer alguma perda de dados.
Mude os seus clusters. Uma comutação permite-lhe inverter as funções do cluster principal e secundário. Pode fazer uma comutação para testar a configuração de recuperação de desastres, durante um cenário real de recuperação de desastres ou para fazer uma migração da sua carga de trabalho. Quando conclui a mudança, a direção da replicação é invertida e o cluster secundário antigo pode aceitar leituras e escritas, enquanto o cluster principal antigo muda para só de leitura.
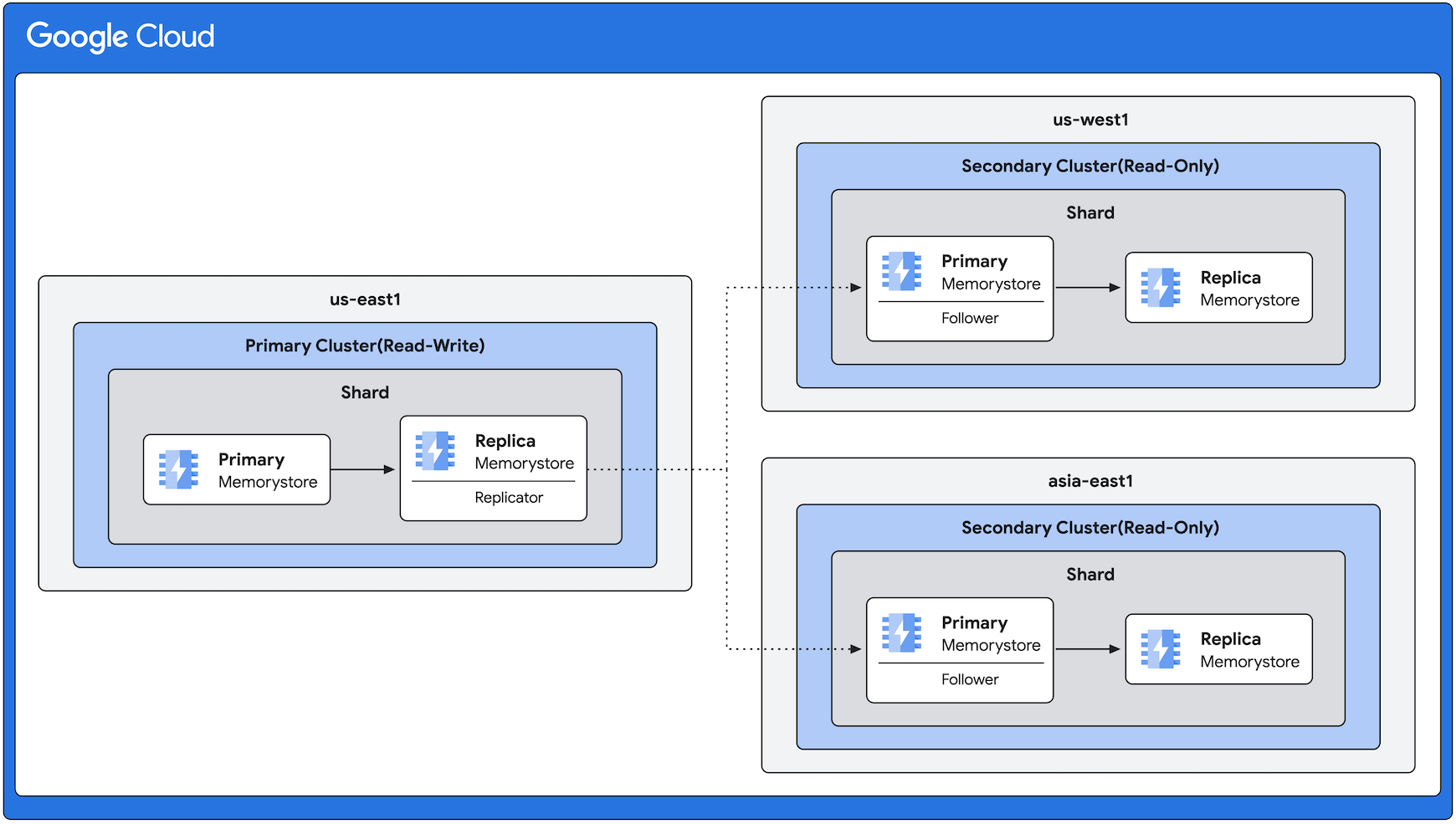
Exemplo de arquitetura de replicação entre regiões
O diagrama seguinte mostra um cluster principal na região us-east1 com clusters secundários em us-west1 e asia-east1. A direção da replicação é sempre de us-east1 para as outras regiões. Tenha em atenção que, embora o diagrama seguinte mostre o mesmo número de réplicas em todas as regiões, a funcionalidade de replicação entre regiões dá-lhe a flexibilidade de ter um número variável de réplicas de acordo com os seus requisitos.
Definições do cluster
Esta secção explica que definições são necessárias, copiadas ou substituídas para clusters principais e secundários que usam a replicação entre regiões. Também explica que definições estão configuradas no dispositivo principal e que definições estão configuradas localmente.
Parâmetros obrigatórios para criar um cluster secundário
- Projeto do Google Cloud. Este é o projeto onde o cluster principal está localizado e onde o cluster secundário vai ser criado.
- Região. Esta é a região onde quer colocar o cluster secundário.
- Configuração do Private Service Connect. Esta é a configuração de rede do seu cluster.
- Cluster principal. Tem de indicar um cluster principal para o cluster secundário quando cria o cluster secundário. Qualquer cluster que não seja um cluster secundário pode ser usado como cluster principal. Se não tiver um cluster principal, deve criá-lo primeiro.
Definições copiadas do principal durante a criação da instância
Durante a criação do cluster secundário, este copia as seguintes definições do cluster principal:
- Quantidade de fragmentos
- Modo de autenticação IAM
- Modo de encriptação em trânsito
- Configurações do motor Redis
- Versão do motor Redis
- Tipo de nó
- Modo de persistência
Substituição permitida durante a criação da instância
As seguintes definições permitem uma substituição da predefinição durante a criação da instância.
- Configuração da distribuição de zonas
- Contagem de réplicas
- Janelas de manutenção
- Proteção contra eliminação
- Cópias de segurança automáticas
Atualize as definições do cluster
Quando atualiza as definições do cluster, algumas definições só podem ser alteradas no cluster principal e as alterações são sincronizadas automaticamente com os clusters secundários. Outras definições podem ser alteradas de forma independente nos clusters principal e secundário, e estas são aplicadas apenas localmente e não sincronizadas com os outros clusters.
Definir como principal
As seguintes definições têm de ser alteradas no dispositivo principal, e a atualização é sincronizada com o dispositivo secundário:
Definida localmente
Configura estas definições localmente:
- Proteção contra eliminação
- Contagem de réplicas
- Períodos de manutenção
- Agrupe pontos finais
- Cópias de segurança automáticas
Práticas recomendadas para a mudança
Quando fizer uma comutação, recomendamos que siga as instruções nesta secção para que a sua aplicação possa monitorizar as gravações e enviá-las para o cluster adequado.
- Impedir que a sua aplicação escreva no cluster principal.
Determine o cluster secundário a promover (se existirem vários secundários à escolha). Seguem-se alguns fatores que podem ajudar a determinar que objetivo secundário promover:
A proximidade da sua aplicação ao cluster. Isto pode afetar a latência de escrita.
O cluster que está mais atualizado em termos de dados.
O cluster mais próximo em termos de definições dos clusters principais.
Aguarde pela conclusão da operação de comutação.
Atualize a aplicação para enviar as gravações para o cluster recém-promovido que escolheu no passo 2.