Cette page présente la réplication multirégionale pour Memorystore pour Redis Cluster.
Pour savoir comment gérer la réplication interrégionale, consultez Utiliser la réplication interrégionale.
La réplication interrégionale vous permet de créer des clusters secondaires à partir d'un cluster principal pour rendre votre cluster disponible en lecture dans différentes régions. Les clusters secondaires offrent également une redondance pour les scénarios de reprise après sinistre en cas d'indisponibilité régionale.
Voici les principaux concepts abordés sur cette page :
- Cluster principal Cluster en lecture/écriture dans une seule région.
- Cluster(s) secondaire(s) Un cluster secondaire est un cluster en lecture seule qui effectue une réplication à partir du cluster principal de manière asynchrone. Pour savoir comment promouvoir et dissocier des instances secondaires, consultez les sections Basculement et Dissociation de Utiliser la réplication interrégionale.
- Nœud de réplication. Nœud du shard du cluster principal qui est répliqué sur un nœud suiveur du cluster secondaire. N'importe quel nœud principal ou répliqué du shard peut servir de réplicateur.
- Nœuds suiveurs : Nœuds du cluster secondaire qui effectuent une réplication à partir d'un nœud de réplication du cluster principal. Seuls les nœuds principaux du cluster secondaire peuvent avoir le rôle de follower.
- Nombre de segments et attribution des emplacements. Les clusters principal et secondaire ont le même nombre de partitions et d'attributions d'emplacements.
Avantages
Voici les avantages de la réplication multirégionale sur Memorystore for Redis Cluster :
- Reprise après sinistre : Si la région du cluster principal devient indisponible, vous pouvez basculer vers un cluster secondaire dans une autre région ou le détacher pour traiter les requêtes de lecture et d'écriture. Les clusters secondaires sont toujours prêts à répondre aux requêtes de lecture sans émettre de commande de basculement ni de détachement.
- Données réparties géographiquement : La distribution géographique des données les rapproche de vous et réduit la latence en lecture.
- Équilibrage de charge géographique pour le trafic de lecture. En cas de connexions lentes ou surchargées dans une région, vous pouvez acheminer le trafic vers une autre région.
Comportement de la fonctionnalité
Cette section explique les comportements importants de la réplication interrégionale dont vous devez tenir compte.
- Faites évoluer la capacité de l'instance. Lorsque vous modifiez la capacité de l'instance du cluster principal, les clusters secondaires sont automatiquement mis à l'échelle pour correspondre au cluster principal.
- Mise à l'échelle du nombre d'instances répliquées. Vous pouvez ajuster le nombre de réplicas pour les clusters primaires et secondaires de manière indépendante en fonction des besoins de votre charge de travail. Les modifications apportées au nombre de réplicas sont locales et ne sont pas propagées aux autres clusters de la collection de clusters de réplication interrégionale.
- Basculement en cas de panne potentielle Vous pouvez effectuer une commutation pour promouvoir un cluster secondaire, même si le cluster principal est indisponible en raison d'une panne. Dans ce scénario, le cluster principal indisponible devient finalement un cluster secondaire une fois la panne résolue.
- Création d'un cluster secondaire en ligne Lorsque vous ajoutez un cluster secondaire à un cluster principal, le cluster principal reste en ligne. L'instance principale traite les requêtes tandis que l'instance secondaire est créée et réplique les données.
- Clusters secondaires : Vous pouvez en avoir jusqu'à deux. Ils peuvent se trouver dans toutes les régions disponibles. Si vous le souhaitez, ils peuvent tous être situés dans des régions différentes. Il est impossible de transformer un cluster existant en cluster secondaire. Seuls les nouveaux clusters peuvent être ajoutés en tant que clusters secondaires à un cluster existant.
- Paramètres synchronisés : La plupart des paramètres sont automatiquement synchronisés entre les clusters principal et secondaire. Pour en savoir plus sur ces paramètres, consultez Paramètres du cluster.
- Tarifs. Les clients qui utilisent la réplication interrégionale seront facturés pour tous les clusters secondaires provisionnés à cette fin. Pour chaque nœud et réplica déployés sur le cluster secondaire, les clients sont facturés comme pour tout autre cluster principal. De plus, les clients doivent payer des frais de réseau pour le transfert de données entre les clusters de différentes régions.
- Mise à jour de maintenance. Pour assurer la compatibilité avec la réplication multirégionale, votre cluster principal peut faire l'objet d'une mise à jour de maintenance lors de la création de votre cluster secondaire s'il n'exécute pas déjà la version logicielle requise. Ce processus de mise à jour peut entraîner une latence supplémentaire lors de la création de votre cluster secondaire. Pour en savoir plus sur la maintenance, consultez À propos de la maintenance.
Utiliser la réplication interrégionale
L'utilisation de la réplication multirégionale Memorystore for Redis Cluster implique les tâches suivantes :
- Créez un cluster secondaire. Vous créez un cluster secondaire qui effectue une réplication continue à partir de votre cluster principal.
- Affichez un cluster secondaire. Vous pouvez afficher des informations sur un cluster secondaire, y compris le nom du cluster principal et l'autre cluster secondaire du groupe de réplication.
Dissociez les clusters secondaires. Dissocier des clusters secondaires consiste à les séparer de leur cluster principal. Vous obtenez ainsi des clusters indépendants entièrement fonctionnels, qui permettent les lectures et les écritures. Après une opération de dissociation, les clusters secondaires ne répliquent plus les données du cluster principal auquel ils étaient auparavant associés. Le cluster principal d'origine et les clusters nouvellement dissociés (anciens clusters secondaires) fonctionnent comme des clusters indépendants sans aucune relation entre eux.
Il existe deux scénarios principaux pour détacher des clusters secondaires :
- Migration régionale : Migrez de manière planifiée les ressources Memorystore for Redis Cluster de leur région principale vers une autre région.
- Reprise après sinistre : Activez rapidement les ressources Memorystore pour Redis Cluster dans une région secondaire si les ressources de la région principale deviennent indisponibles. Si les clusters secondaires n'étaient pas entièrement synchronisés avec le cluster principal, des données pourraient être perdues.
Basculez vos clusters. Une commutation vous permet d'inverser les rôles de votre cluster principal et de votre cluster secondaire. Vous pouvez effectuer une permutation pour tester votre configuration de reprise après sinistre, lors d'un véritable scénario de reprise après sinistre ou pour migrer votre charge de travail. Lorsque vous terminez la permutation, le sens de la réplication est inversé. L'ancien cluster secondaire peut accepter les lectures et les écritures, tandis que l'ancien cluster principal passe en lecture seule.
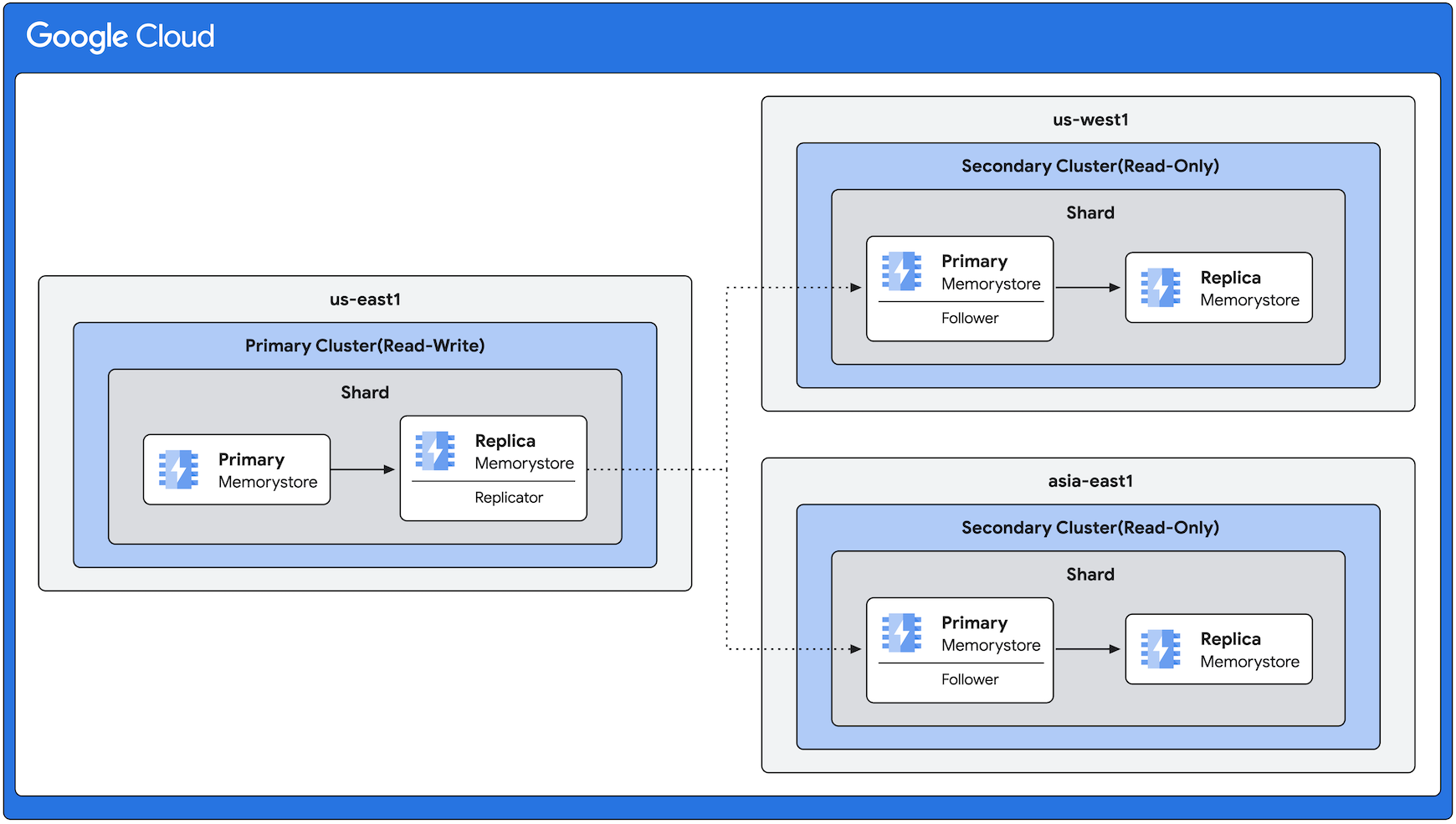
Exemple d'architecture de réplication interrégionale
Le schéma suivant montre un cluster principal dans la région us-east1 avec des clusters secondaires dans les régions us-west1 et asia-east1. La réplication s'effectue toujours de us-east1 vers les autres régions. Notez que même si le schéma suivant montre le même nombre de répliques dans toutes les régions, la fonctionnalité de réplication interrégionale vous permet d'avoir un nombre de répliques variable en fonction de vos besoins.
Paramètres du cluster
Cette section explique quels paramètres sont requis, copiés ou remplacés pour les clusters principaux et secondaires qui utilisent la réplication interrégionale. Il explique également quels paramètres sont configurés sur le compte principal et lesquels le sont localement.
Paramètres requis pour créer un cluster secondaire
- Projet Google Cloud Il s'agit du projet dans lequel se trouve votre cluster principal et dans lequel le cluster secondaire sera créé.
- Région : Il s'agit de la région dans laquelle vous souhaitez placer votre cluster secondaire.
- Configuration de Private Service Connect. Il s'agit de la configuration réseau de votre cluster.
- Cluster principal Lorsque vous créez un cluster secondaire, vous devez indiquer un cluster principal. Tout cluster autre qu'un cluster secondaire peut être utilisé comme cluster principal. Si vous n'avez pas de cluster principal, vous devez d'abord en créer un.
Paramètres copiés à partir de l'instance principale lors de la création de l'instance
Lors de la création du cluster secondaire, celui-ci copie les paramètres suivants du cluster principal :
- Nombre de segments
- Mode d'authentification IAM
- Mode de chiffrement en transit
- Configurations du moteur Redis
- Version du moteur Redis
- Type de nœud
- Mode Persistance
Remplacer autorisé lors de la création de l'instance
Les paramètres suivants permettent de remplacer la valeur par défaut lors de la création de l'instance.
- Configuration de la distribution des zones
- Nombre de répliques
- Intervalles de maintenance
- Protection contre la suppression
- Sauvegardes automatiques
Mettre à jour les paramètres du cluster
Lorsque vous mettez à jour les paramètres d'un cluster, certains ne peuvent être modifiés que sur le cluster principal. Les modifications sont ensuite automatiquement synchronisées avec les clusters secondaires. D'autres paramètres peuvent être modifiés indépendamment sur les clusters principaux et secondaires. Ils ne sont appliqués qu'au niveau local et ne sont pas synchronisés avec les autres clusters.
Définir sur "Principal"
Les paramètres suivants doivent être modifiés sur le serveur principal. La mise à jour est synchronisée avec le serveur secondaire :
Définie localement
Vous configurez ces paramètres localement :
- Protection contre la suppression
- Nombre de répliques
- Intervalles de maintenance
- Points de terminaison du cluster
- Sauvegardes automatiques
Bonnes pratiques pour le transfert
Lorsque vous effectuez un basculement, nous vous recommandons de suivre les instructions de cette section pour que votre application puisse suivre les écritures et les envoyer au cluster approprié.
- Empêchez votre application d'écrire sur le cluster principal.
Déterminez le cluster secondaire à promouvoir (si vous avez le choix entre plusieurs clusters secondaires). Voici quelques facteurs qui peuvent vous aider à déterminer quel secondaire promouvoir :
Proximité de votre application par rapport au cluster. Cela peut avoir une incidence sur la latence d'écriture.
Cluster le plus à jour en termes de données.
Cluster dont les paramètres sont les plus proches de ceux des clusters principaux.
Attendez que l'opération de basculement se termine.
Mettez à jour l'application pour envoyer les écritures au cluster promu que vous avez choisi à l'étape 2.