Esta página mostra como realizar operações de implementação incremental, que implementam gradualmente novas versões da sua infraestrutura de inferência para o GKE Inference Gateway. Esta entrada permite-lhe fazer atualizações seguras e controladas à sua infraestrutura de inferência. Pode atualizar nós, modelos base e adaptadores LoRA com uma interrupção mínima do serviço. Esta página também fornece orientações sobre a divisão do tráfego e as reversões para garantir implementações fiáveis.
Esta página destina-se a administradores de contas e identidades do GKE e a programadores que pretendam realizar operações de implementação para o GKE Inference Gateway.
Os seguintes exemplos de utilização são suportados:
- Implementação da atualização do nó (computação, acelerador)
- Implementação da atualização do modelo base
Atualize uma implementação de nós
As atualizações de nós migram em segurança as cargas de trabalho de inferência para novo hardware de nós ou configurações de aceleradores. Este processo ocorre de forma controlada sem interromper o serviço de modelos. Use atualizações de nós para minimizar a interrupção do serviço durante as atualizações de hardware, as atualizações de controladores ou a resolução de problemas de segurança.
Crie um novo
InferencePool: implemente umInferencePoolconfigurado com as especificações de hardware ou de nó atualizadas.Divida o tráfego através de um
HTTPRoute: configure umHTTPRoutepara distribuir o tráfego entre os recursosInferencePoolexistentes e novos. Use o campoweightembackendRefspara gerir a percentagem de tráfego direcionada para os novos nós.Manter uma
InferenceObjectiveconsistente: mantenha a configuraçãoInferenceObjectiveexistente para garantir um comportamento uniforme do modelo nas duas configurações de nós.Mantenha os recursos originais: mantenha os nós
InferencePoole os nós originais ativos durante a implementação para permitir reversões, se necessário.
Por exemplo, pode criar um novo InferencePool denominado llm-new. Configure este conjunto com a mesma configuração de modelo que o seu llm existente
InferencePool. Implemente o pool num novo conjunto de nós no cluster. Use um objeto HTTPRoute para dividir o tráfego entre o llm original e o novo llm-new InferencePool. Esta técnica permite-lhe atualizar incrementalmente os nós do modelo.
O diagrama seguinte ilustra como o GKE Inference Gateway implementa uma atualização de nós.
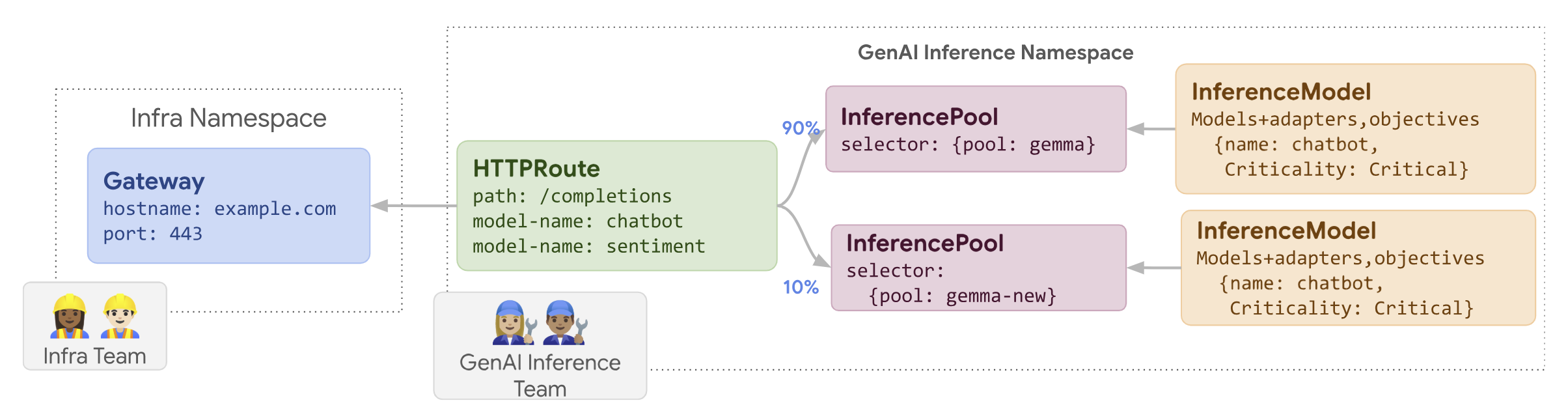
Para implementar uma atualização de nós, siga estes passos:
Guarde o seguinte manifesto de exemplo como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10Aplique o manifesto de exemplo ao seu cluster:
kubectl apply -f routes-to-llm.yaml
O llm InferencePool original recebe a maior parte do tráfego, enquanto o llm-new InferencePool recebe o resto. Aumente gradualmente o peso do tráfego
para o llm-new InferencePool para concluir a implementação da atualização do nó.
Implemente um modelo base
As atualizações do modelo base são implementadas em fases para um novo MDL/CE base, mantendo a compatibilidade com os adaptadores LoRA existentes. Pode usar implementações de atualizações do modelo base para atualizar para arquiteturas de modelos melhoradas ou resolver problemas específicos do modelo.
Para implementar uma atualização do modelo base:
- Implementar nova infraestrutura: crie novos nós e um novo
InferencePoolconfigurado com o novo modelo base que escolheu. - Configurar a distribuição de tráfego: use um
HTTPRoutepara dividir o tráfego entre oInferencePoolexistente (que usa o modelo base antigo) e o novoInferencePool(que usa o novo modelo base). O campobackendRefs weightcontrola a percentagem de tráfego atribuída a cada conjunto. - Manter a integridade da
InferenceObjective: mantenha a configuração daInferenceObjectiveinalterada. Isto garante que o sistema aplica os adaptadores LoRA de forma consistente em ambas as versões do modelo base. - Preserve a capacidade de reversão: mantenha os nós originais e
InferencePooldurante a implementação para facilitar uma reversão, se necessário.
Cria um novo InferencePool com o nome llm-pool-version-2. Este conjunto implementa
uma nova versão do modelo base num novo conjunto de nós. Ao configurar um HTTPRoute, conforme mostrado no exemplo fornecido, pode dividir o tráfego de forma incremental entre o llm-pool original e o llm-pool-version-2. Isto permite-lhe controlar as atualizações do modelo base no seu cluster.
Para implementar uma atualização do modelo base, siga estes passos:
Guarde o seguinte manifesto de exemplo como
routes-to-llm.yaml:apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10Aplique o manifesto de exemplo ao seu cluster:
kubectl apply -f routes-to-llm.yaml
O llm-pool InferencePool original recebe a maior parte do tráfego, enquanto o llm-pool-version-2 InferencePool recebe o resto. Aumente gradualmente o peso do tráfego para o llm-pool-version-2 InferencePool para concluir a implementação da atualização do modelo base.