Nesta página, explicamos os principais conceitos e recursos do Inference Gateway do Google Kubernetes Engine (GKE), uma extensão do GKE Gateway para veiculação otimizada de aplicativos de IA generativa.
Nesta página, consideramos que você esteja familiarizado com o seguinte:
- Orquestração de IA/ML no GKE
- Terminologia da IA generativa
- Conceitos de rede do GKE, incluindo serviços e a API GKE Gateway
- Balanceamento de carga em Google Cloud, especialmente como os balanceadores de carga interagem com o GKE
Esta página é destinada aos seguintes perfis:
- Engenheiros de machine learning (ML), administradores e operadores de plataforma e especialistas em dados e IA interessados em usar os recursos de orquestração de contêineres do Kubernetes para veiculação de cargas de trabalho de IA/ML.
- Arquitetos de nuvem e especialistas Rede que interagem com redes do Kubernetes.
Visão geral
O gateway de inferência do GKE é uma extensão do gateway do GKE que oferece roteamento e balanceamento de carga otimizados para veicular cargas de trabalho de inteligência artificial (IA) generativa. Ele simplifica a implantação, o gerenciamento e a capacidade de observação das cargas de trabalho de inferência de IA.
Para escolher a estratégia ideal de balanceamento de carga para suas cargas de trabalho de IA/ML, consulte Escolher uma estratégia de balanceamento de carga para inferência de IA no GKE.
Recursos e benefícios
O GKE Inference Gateway oferece os seguintes recursos principais para veicular modelos de IA generativa de maneira eficiente para aplicativos de IA generativa no GKE:
- Métricas compatíveis:
KV cache hits: o número de pesquisas bem-sucedidas no cache de chave-valor (KV).- Utilização da GPU ou TPU: a porcentagem de tempo em que a GPU ou TPU está processando ativamente.
- Comprimento da fila de solicitações: o número de solicitações aguardando processamento.
- Balanceamento de carga otimizado para inferência: distribui solicitações para otimizar a performance de veiculação do modelo de IA. Ele usa métricas de servidores de modelos, como
KV cache hitsequeue length of pending requests, para consumir aceleradores (como GPUs e TPUs) de maneira mais eficiente para cargas de trabalho de IA generativa. Isso ativa o roteamento com reconhecimento de prefixo e cache, um recurso fundamental que envia solicitações com contexto compartilhado, identificado pela análise do corpo da solicitação, para a mesma réplica do modelo, maximizando os acertos de cache. Essa abordagem reduz drasticamente os cálculos redundantes e melhora o tempo até o primeiro token, tornando-a altamente eficaz para IA conversacional, geração aumentada de recuperação (RAG) e outras cargas de trabalho de IA generativa baseadas em modelos. - Disponibilização de modelos dinâmicos ajustados com LoRA: permite disponibilizar modelos dinâmicos ajustados com LoRA em um acelerador comum. Isso reduz o número de GPUs e TPUs necessárias para veicular modelos, multiplexando vários modelos LoRA refinados em um modelo de base e acelerador comuns.
- Escalonamento automático otimizado para inferência: o Autoescalador de pods horizontal (HPA, na sigla em inglês) do GKE usa métricas do servidor de modelos para escalonar automaticamente, o que ajuda a garantir o uso eficiente de recursos de computação e a otimizar a performance de inferência.
- Roteamento com reconhecimento de modelo: roteia solicitações de inferência com base nos nomes de modelo definidos nas especificações
OpenAI APIno cluster do GKE. É possível definir políticas de roteamento de gateway, como divisão de tráfego e espelhamento de solicitações, para gerenciar diferentes versões de modelos e simplificar os rollouts. Por exemplo, é possível direcionar solicitações para um nome de modelo específico a diferentes objetosInferencePool, cada um servindo uma versão diferente do modelo. Para mais informações sobre como configurar isso, consulte Configurar o roteamento com base no corpo. - Segurança de IA e filtragem de conteúdo integradas: o GKE Inference Gateway se integra ao Model Armor para aplicar verificações de segurança de IA e filtragem de conteúdo a comandos e respostas no gateway. Google CloudO Model Armor fornece registros de solicitações, respostas e processamento para análise retrospectiva e otimização. As interfaces abertas do GKE Inference Gateway permitem que provedores e desenvolvedores terceirizados integrem serviços personalizados ao processo de solicitação de inferência.
- Disponibilização específica do modelo
Priority: permite especificar a disponibilizaçãoPriorityde modelos de IA. Priorize solicitações sensíveis à latência em vez de jobs de inferência em lote tolerantes à latência. Por exemplo, é possível priorizar solicitações de aplicativos sensíveis à latência e descartar tarefas menos sensíveis ao tempo quando os recursos estão limitados. - Observabilidade de inferência: fornece métricas de observabilidade para solicitações de inferência, como taxa de solicitação, latência, erros e saturação. Monitore a performance e o comportamento dos seus serviços de inferência com o Cloud Monitoring e o Cloud Logging, aproveitando painéis especializados pré-criados para insights detalhados. Para mais informações, consulte Ver o painel do GKE Inference Gateway.
- Gerenciamento avançado de APIs com a Apigee: integra-se à Apigee para aprimorar seu gateway de inferência com recursos como segurança de API, limitação de taxa e cotas. Para instruções detalhadas, consulte Configurar o Apigee para autenticação e gerenciamento de API.
- Extensibilidade: criado em uma extensão de inferência de API do gateway do Kubernetes de código aberto e extensível que oferece suporte a um algoritmo de seleção de endpoints gerenciado pelo usuário.
Entenda os principais conceitos
O gateway de inferência do GKE aprimora o gateway do GKE atual, que usa objetos GatewayClass. O gateway de inferência do GKE apresenta as seguintes novas definições de recursos personalizados (CRDs) da API Gateway, alinhadas com a extensão da API Gateway do Kubernetes OSS para inferência:
- Objeto
InferencePool: representa um grupo de pods (contêineres) que compartilham a mesma configuração de computação, tipo de acelerador, modelo de linguagem de base e servidor de modelo. Isso agrupa e gerencia logicamente os recursos de serviço do modelo de IA. Um único objetoInferencePoolpode abranger vários pods em diferentes nós do GKE e oferece escalonabilidade e alta disponibilidade. - Objeto
InferenceObjective: especifica o nome do modelo de serviço doInferencePoolde acordo com a especificaçãoOpenAI API. O objetoInferenceObjectivetambém especifica as propriedades de veiculação do modelo, como oPrioritydo modelo de IA. O gateway de inferência do GKE dá preferência a cargas de trabalho com um valor de prioridade mais alto. Isso permite multiplexar cargas de trabalho de IA com tolerância e sensibilidade à latência em um cluster do GKE. Também é possível configurar o objetoInferenceObjectivepara veicular modelos ajustados com LoRA.
O diagrama a seguir ilustra o GKE Inference Gateway e a integração dele com a segurança de IA, a capacidade de observação e a veiculação de modelos em um cluster do GKE.
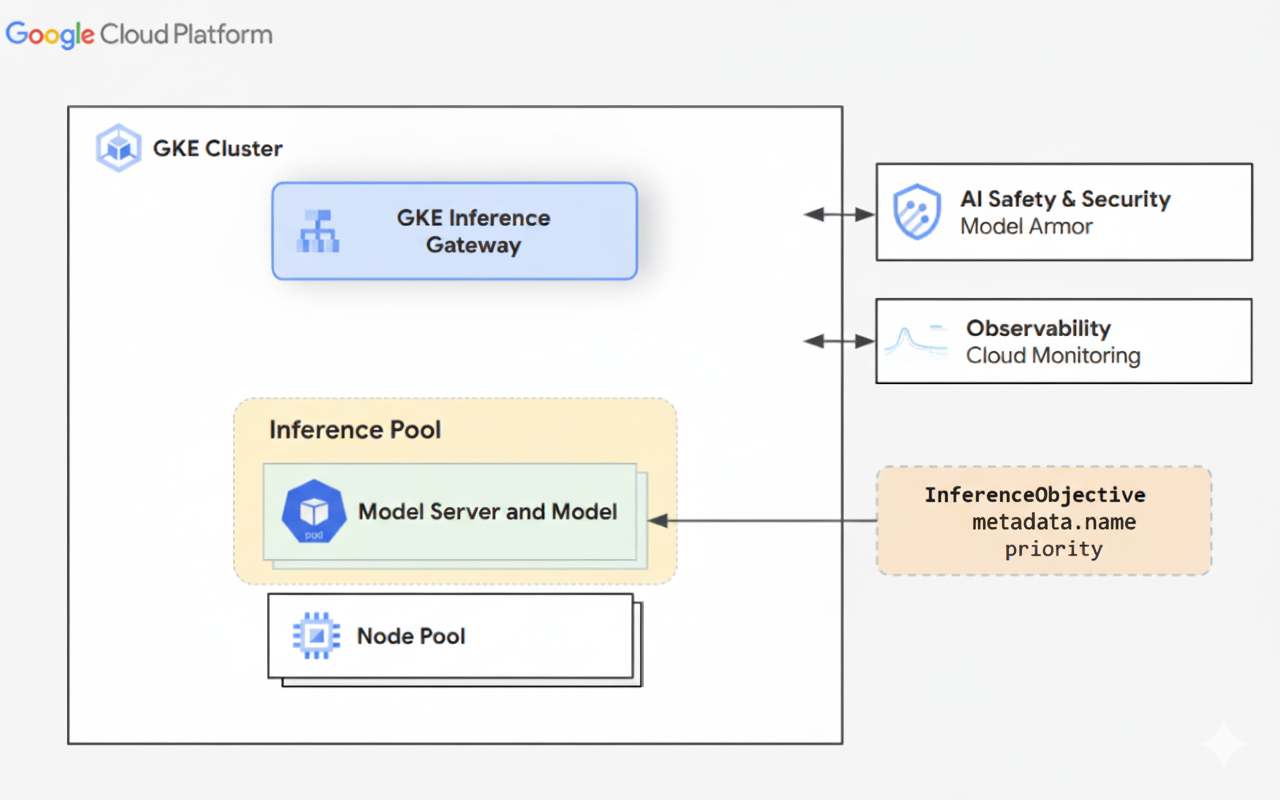
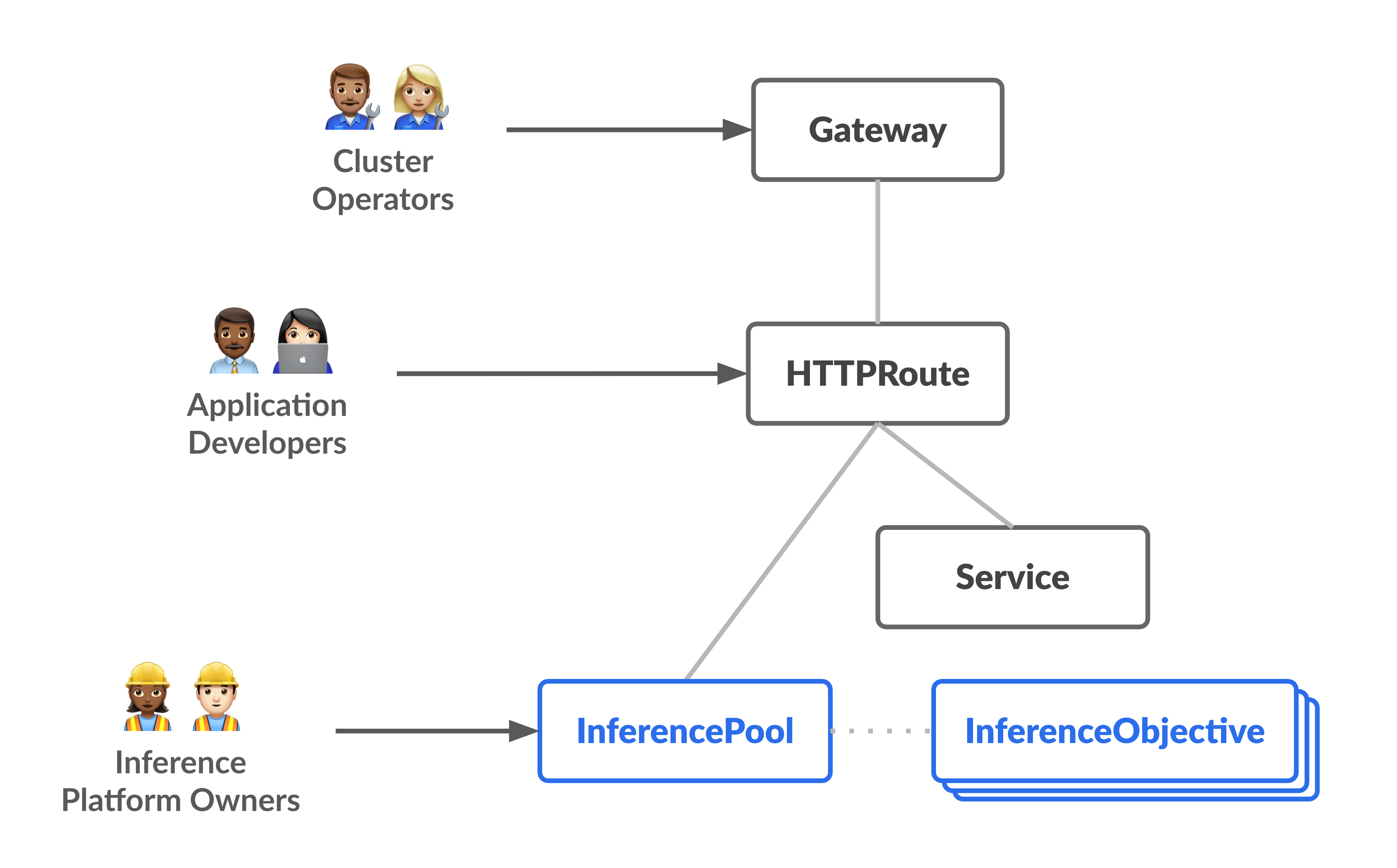
O diagrama a seguir ilustra o modelo de recursos que se concentra em duas novas personas focadas em inferência e os recursos que elas gerenciam.
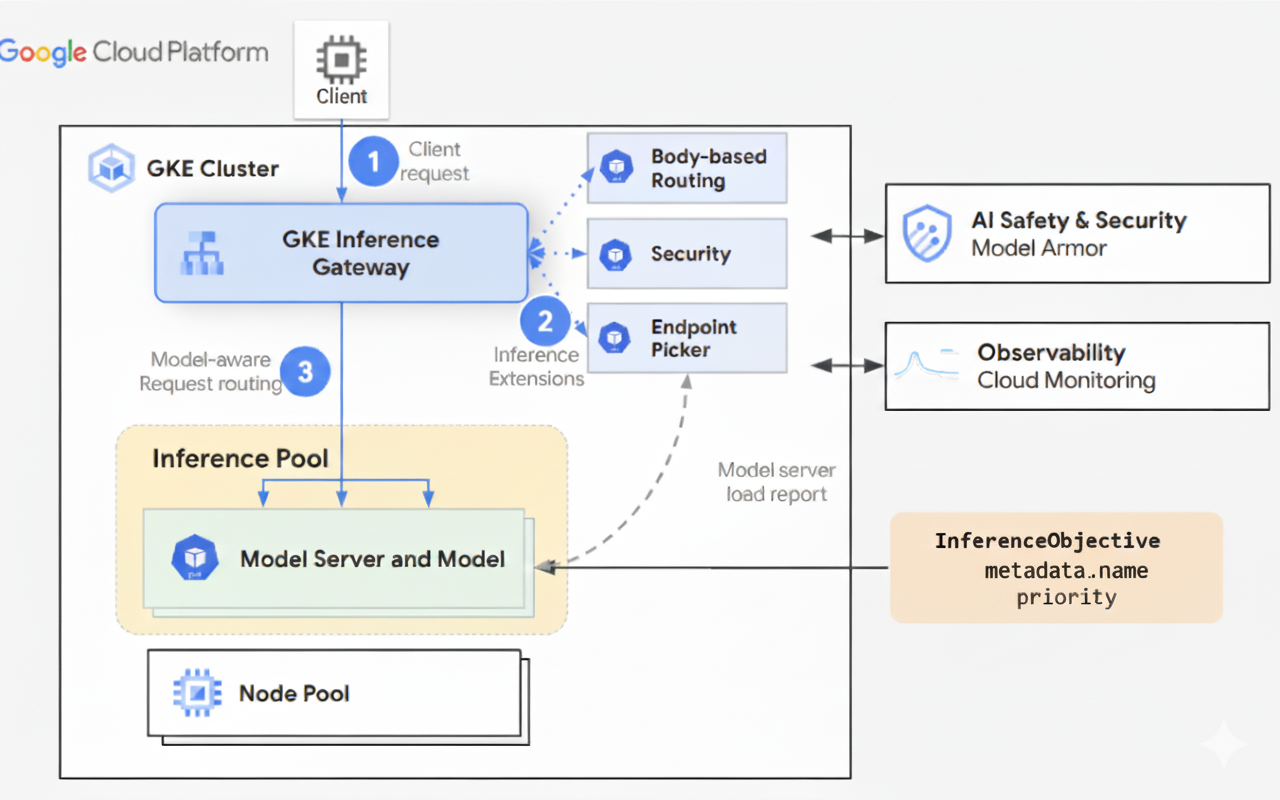
Como funciona o gateway de inferência do GKE
O GKE Inference Gateway usa extensões da API Gateway e lógica de roteamento específica do modelo para processar solicitações de clientes a um modelo de IA. As etapas a seguir descrevem o fluxo de solicitação.
Como funciona o fluxo de solicitação
O GKE Inference Gateway encaminha solicitações do cliente da solicitação inicial para uma instância de modelo. Nesta seção, descrevemos como o GKE Inference Gateway processa solicitações. Esse fluxo de solicitação é comum para todos os clientes.
- O cliente envia uma solicitação, formatada conforme descrito na especificação da API do OpenAI, para o modelo em execução no GKE.
- O gateway de inferência do GKE processa a solicitação usando as seguintes extensões de inferência:
- Extensão de roteamento com base no corpo: extrai o identificador do modelo do corpo da solicitação do cliente e o envia para o gateway de inferência do GKE.
Em seguida, o GKE Inference Gateway usa esse identificador para rotear a
solicitação com base nas regras definidas no objeto
HTTPRouteda API Gateway. O roteamento do corpo da solicitação é semelhante ao roteamento com base no caminho do URL. A diferença é que o roteamento do corpo da solicitação usa dados do corpo da solicitação. - Extensão de segurança: usa o Model Armor ou soluções de terceiros compatíveis para aplicar políticas de segurança específicas do modelo, que incluem filtragem de conteúdo, detecção de ameaças, limpeza e geração de registros. A extensão de segurança aplica essas políticas aos caminhos de processamento de solicitação e resposta.
- Extensão do seletor de endpoints: monitora as principais métricas dos servidores de modelos
no
InferencePool. Ele rastreia a utilização do cache de valor-chave (KV-cache), o comprimento da fila de solicitações pendentes, os índices de cache de prefixo e os adaptadores LoRA ativos em cada servidor de modelo. Em seguida, ele encaminha a solicitação para a réplica do modelo ideal com base nessas métricas para minimizar a latência e maximizar a taxa de transferência para inferência de IA.
- Extensão de roteamento com base no corpo: extrai o identificador do modelo do corpo da solicitação do cliente e o envia para o gateway de inferência do GKE.
Em seguida, o GKE Inference Gateway usa esse identificador para rotear a
solicitação com base nas regras definidas no objeto
- O GKE Inference Gateway encaminha a solicitação para a réplica do modelo retornada pela extensão do seletor de endpoints.
O diagrama a seguir ilustra o fluxo de solicitação de um cliente para uma instância de modelo pelo GKE Inference Gateway.
Como funciona a distribuição de tráfego
O GKE Inference Gateway distribui dinamicamente as solicitações de inferência para servidores de modelo no objeto InferencePool. Isso ajuda a otimizar a utilização de recursos e manter a performance em diferentes condições de carga.
O gateway de inferência do GKE usa os dois mecanismos a seguir para gerenciar a distribuição de tráfego:
Seleção de endpoint: seleciona dinamicamente o servidor de modelo mais adequado para processar uma solicitação de inferência. Ele monitora a carga e a disponibilidade do servidor e toma decisões de roteamento ideais calculando um
scorepara cada servidor, combinando várias heurísticas de otimização:- Roteamento com reconhecimento de cache de prefixo: o gateway de inferência do GKE rastreia os índices de cache de prefixo disponíveis em cada servidor de modelo e atribui uma pontuação mais alta a um servidor com uma correspondência de cache de prefixo mais longa.
- Roteamento com reconhecimento de carga: o gateway de inferência do GKE monitora a carga do servidor (utilização do cache KV e profundidade da fila pendente) e atribui uma pontuação maior a um servidor com carga menor.
- Roteamento com reconhecimento de LoRA: quando o serviço dinâmico de LoRA está ativado, o GKE Inference Gateway monitora os adaptadores LoRA ativos por servidor e atribui uma pontuação mais alta a um servidor com o adaptador LoRA solicitado ativo ou espaço adicional para carregar dinamicamente o adaptador LoRA solicitado. Um servidor com a maior pontuação total de todos os itens anteriores é escolhido.
Enfileiramento e redução: gerencia o fluxo de solicitações e evita a sobrecarga de tráfego. O GKE Inference Gateway armazena as solicitações recebidas em uma fila e prioriza as solicitações com base na prioridade definida.
O gateway de inferência do GKE usa um sistema numérico Priority, também conhecido como
Criticality, para gerenciar o fluxo de solicitações e evitar sobrecarga. Esse Priority é um campo inteiro opcional definido pelo usuário para cada InferenceObjective. Um valor mais alto significa uma solicitação mais importante. Quando o sistema está sob pressão, as solicitações com um Priority menor que 0 são consideradas de prioridade mais baixa e são descartadas primeiro, retornando um erro 429 para proteger cargas de trabalho mais críticas. Por padrão, o Priority é 0. As solicitações só serão
descartadas devido à prioridade se o Priority delas for definido explicitamente como um valor menor
que 0. Com esse sistema, é possível priorizar o tráfego de inferência on-line sensível à latência em vez de jobs em lote menos sensíveis ao tempo.
O GKE Inference Gateway oferece suporte à inferência de streaming para aplicativos como chatbots e tradução simultânea, que exigem atualizações contínuas ou quase em tempo real. A inferência de streaming entrega respostas em partes ou segmentos incrementais, em vez de uma única saída completa. Se ocorrer um erro durante uma resposta de streaming, o stream será encerrado, e o cliente vai receber uma mensagem de erro. O gateway de inferência do GKE não tenta novamente respostas de streaming.
Conheça exemplos de aplicativos
Nesta seção, apresentamos exemplos de como usar o GKE Inference Gateway para lidar com vários cenários de aplicativos de IA generativa.
Exemplo 1: disponibilizar vários modelos de IA generativa em um cluster do GKE
Uma empresa quer implantar vários modelos de linguagem grandes (LLMs) para atender a diferentes cargas de trabalho. Por exemplo, talvez eles queiram implantar um modelo Gemma3 para uma interface de chatbot e um modelo Deepseek para um aplicativo de recomendação. A empresa precisa garantir o desempenho ideal de veiculação para esses LLMs.
Com o gateway de inferência do GKE, é possível implantar esses LLMs no cluster do GKE com a configuração de acelerador escolhida em um InferencePool. Em seguida, é possível encaminhar solicitações com base no nome do modelo (como
chatbot e recommender) e na propriedade Priority.
O diagrama a seguir ilustra como o gateway de inferência do GKE encaminha solicitações
para diferentes modelos com base no nome do modelo e em Priority.
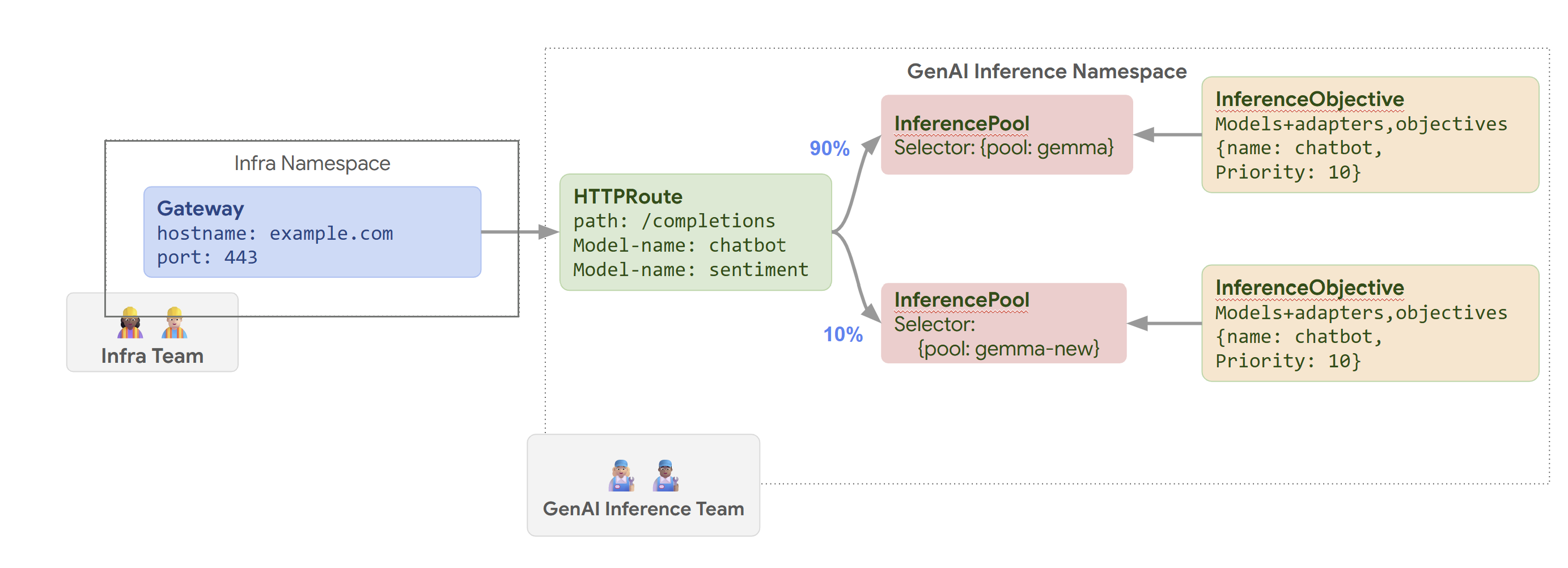
Este diagrama ilustra como uma solicitação para um serviço de IA generativa em
example.com/completions é processada pelo gateway de inferência do GKE. A solicitação
primeiro chega a um Gateway no namespace Infra. Esse Gateway encaminha a
solicitação para um HTTPRoute no namespace GenAI Inference, que é
configurado para processar solicitações de modelos de chatbot e de sentimentos. Para o modelo de chatbot, o HTTPRoute divide o tráfego: 90% são direcionados a um InferencePool que executa a versão atual do modelo (selecionada por {pool: gemma}), e 10% vão para um pool com uma versão mais recente ({pool: gemma-new}), geralmente para testes canários.
Os dois pools estão vinculados a um InferenceObjective que atribui um Priority de 10 a solicitações para o modelo de chatbot, garantindo que essas solicitações sejam tratadas como de alta prioridade.
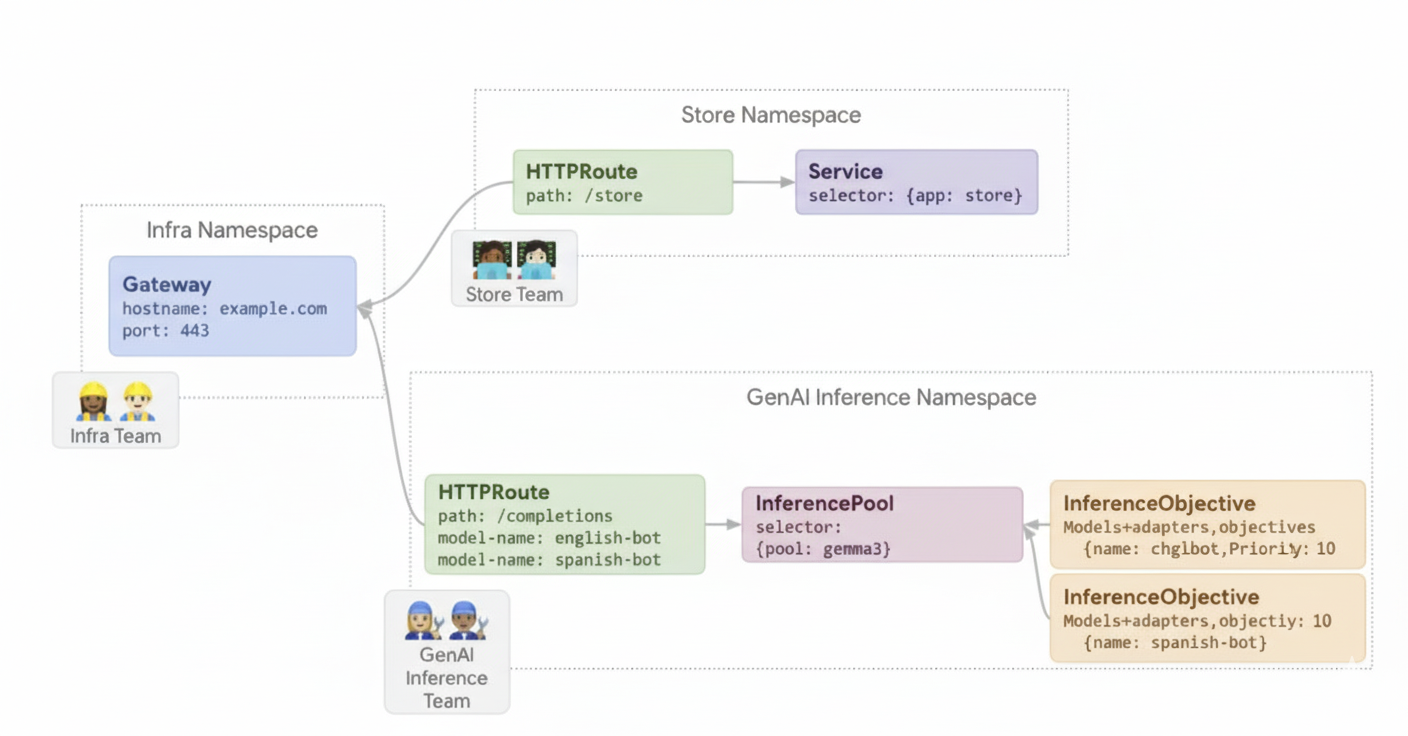
Exemplo 2: veicular adaptadores LoRA em um acelerador compartilhado
Uma empresa quer veicular LLMs para análise de documentos e se concentra em públicos-alvo em vários idiomas, como inglês e espanhol. Eles têm modelos ajustados para cada idioma, mas precisam usar a capacidade de GPU e TPU de maneira eficiente. É possível usar o gateway de inferência do GKE para implantar adaptadores dinâmicos de ajuste refinado de LoRA para cada idioma (por exemplo, english-bot e spanish-bot) em um modelo de base comum (por exemplo, llm-base) e um acelerador. Isso permite reduzir o número de aceleradores necessários ao agrupar vários modelos em um acelerador comum.
O diagrama a seguir ilustra como o GKE Inference Gateway atende a vários adaptadores LoRA em um acelerador compartilhado.
A seguir
- Implantar o GKE Inference Gateway
- Personalizar a configuração do GKE Inference Gateway
- Disponibilizar um LLM com o gateway de inferência do GKE