Cette page présente les principaux concepts et fonctionnalités de Google Kubernetes Engine (GKE) Inference Gateway, une extension de GKE Gateway permettant de diffuser de manière optimisée des applications d'IA générative.
Sur cette page, nous partons du principe que vous connaissez les éléments suivants :
- Orchestration IA/ML sur GKE
- Terminologie de l'IA générative
- Concepts de mise en réseau GKE, y compris les services et l'API GKE Gateway
- Équilibrage de charge dans Google Cloud, en particulier l'interaction des équilibreurs de charge avec GKE
Cette page s'adresse aux personas suivants :
- Ingénieurs en machine learning (ML), administrateurs et opérateurs de plate-forme, et spécialistes des données et de l'IA qui souhaitent utiliser les fonctionnalités d'orchestration de conteneurs Kubernetes pour diffuser des charges de travail d'IA/de ML.
- Architectes cloud et spécialistes de la mise en réseau qui interagissent avec la mise en réseau Kubernetes.
Présentation
La passerelle d'inférence GKE est une extension de GKE Gateway qui fournit un routage et un équilibrage de charge optimisés pour le traitement des charges de travail d'intelligence artificielle (IA) générative. Il simplifie le déploiement, la gestion et l'observabilité des charges de travail d'inférence de l'IA.
Pour choisir la stratégie d'équilibrage de charge optimale pour vos charges de travail d'IA/ML, consultez Choisir une stratégie d'équilibrage de charge pour l'inférence d'IA sur GKE.
Fonctionnalités et avantages
GKE Inference Gateway offre les principales fonctionnalités suivantes pour diffuser efficacement des modèles d'IA générative pour les applications d'IA générative sur GKE :
- Métriques acceptées :
KV cache hits: nombre de recherches réussies dans le cache clé/valeur (KV).- Utilisation du GPU ou du TPU : pourcentage du temps pendant lequel le GPU ou le TPU traite activement les données.
- Longueur de la file d'attente des requêtes : nombre de requêtes en attente de traitement.
- Équilibrage de charge optimisé pour l'inférence : distribue les requêtes pour optimiser les performances de diffusion des modèles d'IA. Il utilise des métriques provenant des serveurs de modèles, telles que
KV cache hitsetqueue length of pending requests, pour consommer des accélérateurs (tels que les GPU et les TPU) plus efficacement pour les charges de travail d'IA générative. Cela permet le routage tenant compte du préfixe du cache, une fonctionnalité clé qui envoie les requêtes avec un contexte partagé, identifié en analysant le corps de la requête, à la même réplique de modèle en maximisant les accès au cache. Cette approche réduit considérablement les calculs redondants et améliore le délai avant le premier jeton, ce qui la rend très efficace pour l'IA conversationnelle, la génération augmentée par récupération (RAG) et d'autres charges de travail d'IA générative basées sur des modèles. - Diffusion de modèles affinés LoRA dynamiques : permet de diffuser des modèles affinés LoRA dynamiques sur un accélérateur commun. Cela réduit le nombre de GPU et de TPU nécessaires pour diffuser des modèles en multiplexant plusieurs modèles LoRA affinés sur un modèle de base et un accélérateur communs.
- Autoscaling optimisé pour l'inférence : l'autoscaler horizontal de pods (AHP) GKE utilise les métriques du serveur de modèle pour l'autoscaling, ce qui permet d'assurer une utilisation efficace des ressources de calcul et des performances d'inférence optimisées.
- Routage tenant compte des modèles : achemine les requêtes d'inférence en fonction des noms de modèles définis dans les spécifications
OpenAI APIde votre cluster GKE. Vous pouvez définir des règles de routage de passerelle, telles que la répartition du trafic et la mise en miroir des requêtes, pour gérer différentes versions de modèles et simplifier les déploiements de modèles. Par exemple, vous pouvez acheminer les requêtes pour un nom de modèle spécifique vers différents objetsInferencePool, chacun servant une version différente du modèle. Pour savoir comment configurer cette fonctionnalité, consultez Configurer le routage basé sur le corps. - Sécurité de l'IA et filtrage de contenu intégrés : GKE Inference Gateway s'intègre à Google Cloud Model Armor pour appliquer des vérifications de sécurité de l'IA et un filtrage de contenu aux requêtes et aux réponses au niveau de la passerelle. Model Armor fournit des journaux des requêtes, des réponses et du traitement pour l'analyse et l'optimisation rétrospectives. Les interfaces ouvertes de GKE Inference Gateway permettent aux fournisseurs et aux développeurs tiers d'intégrer des services personnalisés au processus de demande d'inférence.
- Mise en service spécifique au modèle
Priority: vous permet de spécifier la mise en servicePrioritydes modèles d'IA. Priorisez les requêtes sensibles à la latence par rapport aux jobs d'inférence par lot tolérants à la latence. Par exemple, vous pouvez donner la priorité aux requêtes provenant d'applications sensibles à la latence et abandonner les tâches moins sensibles au temps lorsque les ressources sont limitées. - Observabilité de l'inférence : fournit des métriques d'observabilité pour les requêtes d'inférence, telles que le taux de requêtes, la latence, les erreurs et la saturation. Surveillez les performances et le comportement de vos services d'inférence à l'aide de Cloud Monitoring et Cloud Logging, en tirant parti des tableaux de bord prédéfinis spécialisés pour obtenir des informations détaillées. Pour en savoir plus, consultez Afficher le tableau de bord GKE Inference Gateway.
- Gestion avancée des API avec Apigee : s'intègre à Apigee pour améliorer votre passerelle d'inférence avec des fonctionnalités telles que la sécurité des API, la limitation du débit et les quotas. Pour obtenir des instructions détaillées, consultez Configurer Apigee pour l'authentification et la gestion des API.
- Extensibilité : basée sur une extension d'inférence d'API Kubernetes Gateway extensible et Open Source qui prend en charge un algorithme de sélection de points de terminaison géré par l'utilisateur.
Comprendre les concepts clés
La passerelle d'inférence GKE améliore la passerelle GKE existante qui utilise des objets GatewayClass. GKE Inference Gateway introduit les nouvelles définitions de ressources personnalisées (CRD) de l'API Gateway suivantes, qui sont alignées sur l'extension de l'API Gateway Kubernetes OSS pour l'inférence :
- Objet
InferencePool: représente un groupe de pods (conteneurs) qui partagent la même configuration de calcul, le même type d'accélérateur, le même modèle de langage de base et le même serveur de modèle. Cela permet de regrouper et de gérer logiquement vos ressources de diffusion de modèles d'IA. Un seul objetInferencePoolpeut s'étendre sur plusieurs pods sur différents nœuds GKE et offre évolutivité et haute disponibilité. - Objet
InferenceObjective: spécifie le nom du modèle de diffusion à partir deInferencePoolselon la spécificationOpenAI API. L'objetInferenceObjectivespécifie également les propriétés de diffusion du modèle, telles que lePrioritydu modèle d'IA. La passerelle d'inférence GKE donne la préférence aux charges de travail dont la valeur de priorité est plus élevée. Cela vous permet de multiplexer les charges de travail d'IA critiques en termes de latence et tolérantes à la latence sur un cluster GKE. Vous pouvez également configurer l'objetInferenceObjectivepour diffuser des modèles LoRA affinés.
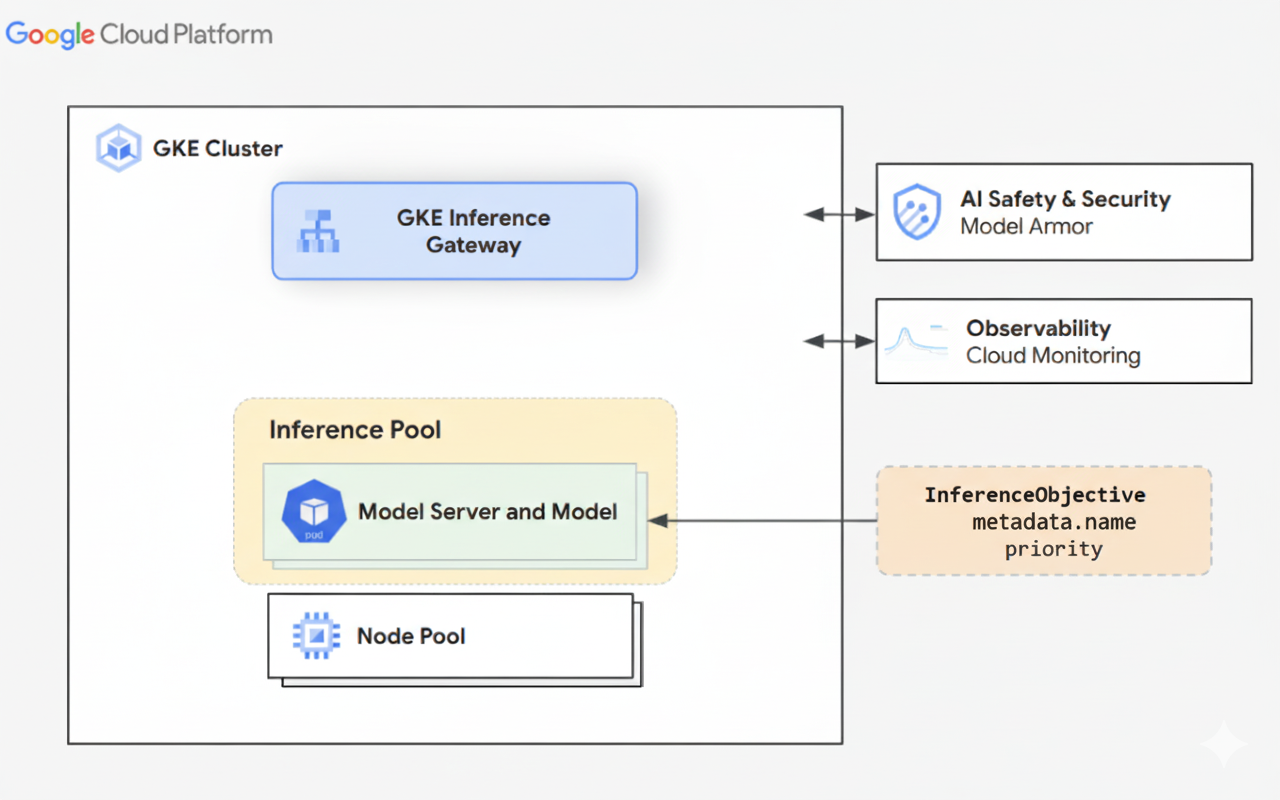
Le schéma suivant illustre GKE Inference Gateway et son intégration à la sécurité de l'IA, à l'observabilité et au service de modèles dans un cluster GKE.
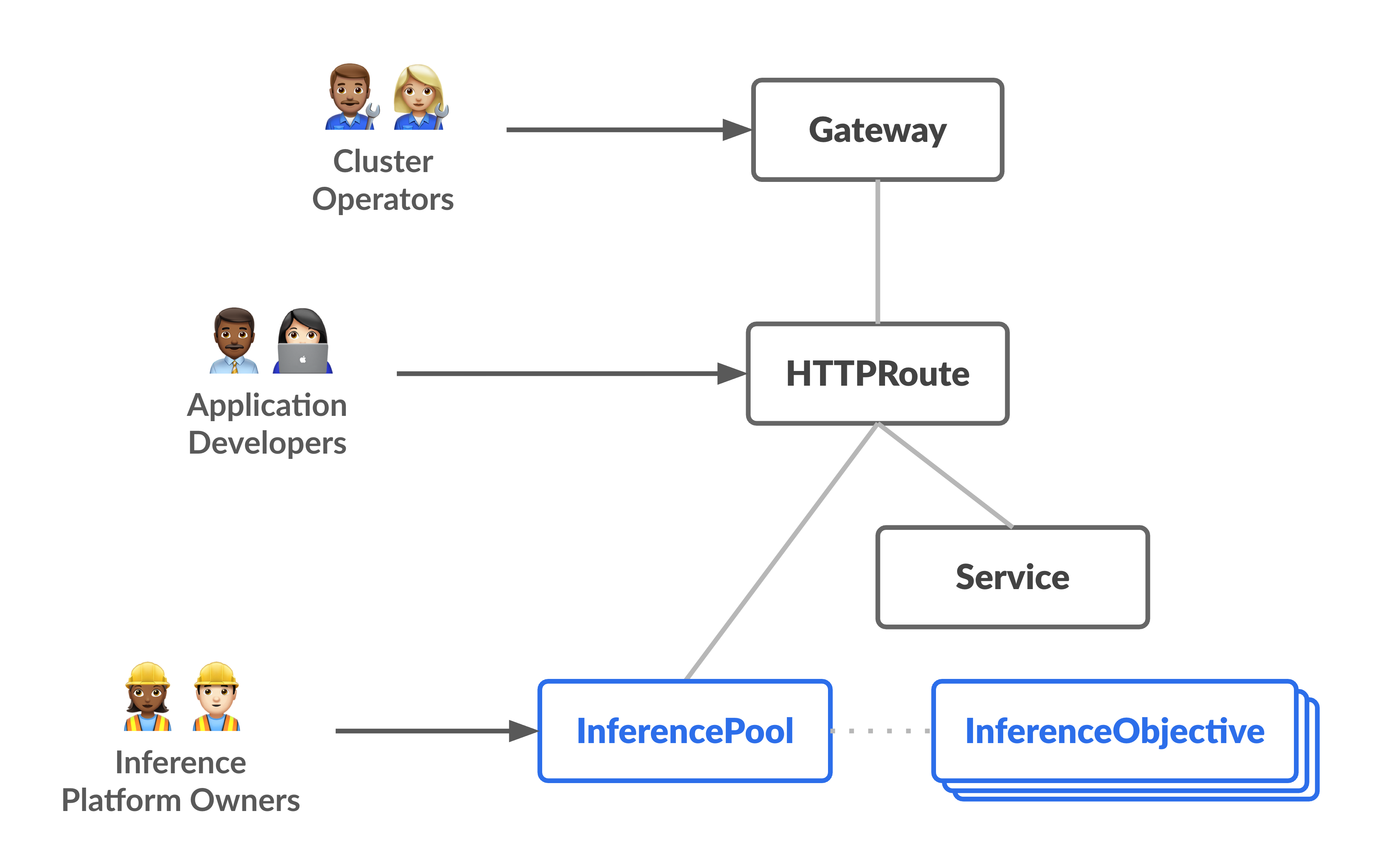
Le schéma suivant illustre le modèle de ressources axé sur deux nouvelles personnes axées sur l'inférence et les ressources qu'elles gèrent.
Fonctionnement de la passerelle d'inférence GKE
GKE Inference Gateway utilise des extensions de l'API Gateway et une logique de routage spécifique aux modèles pour gérer les requêtes client adressées à un modèle d'IA. Les étapes suivantes décrivent le flux de requête.
Fonctionnement du flux de demande
GKE Inference Gateway achemine les requêtes client de la requête initiale vers une instance de modèle. Cette section décrit comment GKE Inference Gateway traite les requêtes. Ce flux de requête est commun à tous les clients.
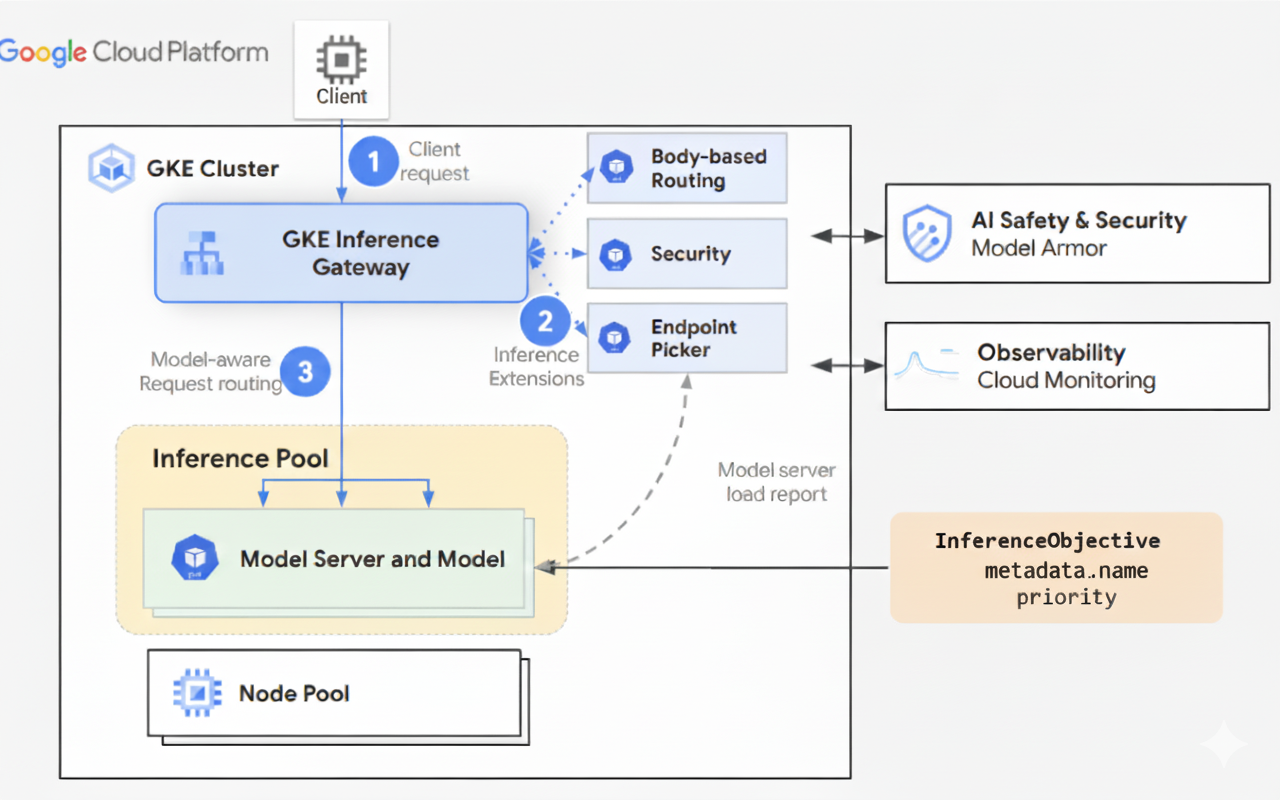
- Le client envoie une requête, mise en forme comme décrit dans la spécification de l'API OpenAI, au modèle exécuté dans GKE.
- La passerelle d'inférence GKE traite la requête à l'aide des extensions d'inférence suivantes :
- Extension de routage basé sur le corps : extrait l'identifiant du modèle du corps de la requête du client et l'envoie à GKE Inference Gateway.
GKE Inference Gateway utilise ensuite cet identifiant pour acheminer la requête en fonction des règles définies dans l'objet
HTTPRoutede l'API Gateway. Le routage du corps de la requête est semblable au routage basé sur le chemin d'URL. La différence est que le routage du corps de la requête utilise les données du corps de la requête. - Extension de sécurité : utilise Model Armor ou des solutions tierces compatibles pour appliquer des règles de sécurité spécifiques au modèle, y compris le filtrage de contenu, la détection des menaces, l'assainissement et la journalisation. L'extension de sécurité applique ces règles aux chemins de traitement des requêtes et des réponses.
- Extension de sélection de points de terminaison : surveille les métriques clés des serveurs de modèles dans
InferencePool. Il suit l'utilisation du cache clé/valeur (KV-cache), la longueur de la file d'attente des requêtes en attente, les index de cache de préfixe et les adaptateurs LoRA actifs sur chaque serveur de modèle. Elle achemine ensuite la requête vers la réplique de modèle optimale en fonction de ces métriques afin de minimiser la latence et de maximiser le débit pour l'inférence d'IA.
- Extension de routage basé sur le corps : extrait l'identifiant du modèle du corps de la requête du client et l'envoie à GKE Inference Gateway.
GKE Inference Gateway utilise ensuite cet identifiant pour acheminer la requête en fonction des règles définies dans l'objet
- La passerelle d'inférence GKE achemine la requête vers la réplique de modèle renvoyée par l'extension de sélection de point de terminaison.
Le schéma suivant illustre le flux de requêtes d'un client vers une instance de modèle via GKE Inference Gateway.
Fonctionnement de la répartition du trafic
GKE Inference Gateway distribue dynamiquement les requêtes d'inférence aux serveurs de modèles dans l'objet InferencePool. Cela permet d'optimiser l'utilisation des ressources et de maintenir les performances dans des conditions de charge variables.
La passerelle d'inférence GKE utilise les deux mécanismes suivants pour gérer la distribution du trafic :
Sélection du point de terminaison : sélectionne dynamiquement le serveur de modèle le plus adapté pour traiter une requête d'inférence. Il surveille la charge et la disponibilité du serveur, puis prend des décisions de routage optimales en calculant un
scorepour chaque serveur, en combinant un certain nombre d'heuristiques d'optimisation :- Routage tenant compte du cache de préfixes : la passerelle d'inférence GKE suit les index de cache de préfixes disponibles sur chaque serveur de modèles et attribue un score plus élevé à un serveur avec une correspondance de cache de préfixes plus longue.
- Routage en fonction de la charge : la passerelle d'inférence GKE surveille la charge du serveur (utilisation du cache KV et profondeur de la file d'attente), et attribue un score plus élevé à un serveur dont la charge est plus faible.
- Routage compatible avec LoRA : lorsque le service LoRA dynamique est activé, GKE Inference Gateway surveille les adaptateurs LoRA actifs par serveur et attribue un score plus élevé à un serveur avec l'adaptateur LoRA demandé actif ou avec de l'espace supplémentaire pour charger dynamiquement l'adaptateur LoRA demandé. Le serveur ayant le score total le plus élevé de tous les serveurs précédents est sélectionné.
Mise en file d'attente et suppression : gère le flux de requêtes et empêche la surcharge du trafic. GKE Inference Gateway stocke les requêtes entrantes dans une file d'attente et les hiérarchise en fonction de la priorité définie.
La passerelle d'inférence GKE utilise un système numérique Priority, également appelé Criticality, pour gérer le flux de requêtes et éviter la surcharge. Ce Priority est un champ d'entier facultatif défini par l'utilisateur pour chaque InferenceObjective. Plus la valeur est élevée, plus la demande est importante. Lorsque le système est sous pression, les requêtes dont la valeur Priority est inférieure à 0 sont considérées comme moins prioritaires et sont supprimées en premier, ce qui renvoie une erreur 429 pour protéger les charges de travail plus critiques. Par défaut, la valeur Priority est définie sur 0. Les requêtes ne sont abandonnées en raison de leur priorité que si leur Priority est explicitement défini sur une valeur inférieure à 0. Ce système vous permet de privilégier le trafic d'inférence en ligne sensible à la latence par rapport aux jobs par lot moins sensibles au temps.
GKE Inference Gateway est compatible avec l'inférence par flux pour les applications telles que les chatbots et la traduction en direct, qui nécessitent des mises à jour continues ou en temps quasi réel. L'inférence par flux de données fournit des réponses par blocs ou segments incrémentaux, au lieu d'une seule sortie complète. Si une erreur se produit lors d'une réponse de streaming, le flux se termine et le client reçoit un message d'erreur. GKE Inference Gateway ne relance pas les réponses de streaming.
Explorer des exemples d'applications
Cette section fournit des exemples d'utilisation de GKE Inference Gateway pour répondre à différents scénarios d'application d'IA générative.
Exemple 1 : Diffuser plusieurs modèles d'IA générative sur un cluster GKE
Une entreprise souhaite déployer plusieurs grands modèles de langage (LLM) pour traiter différentes charges de travail. Par exemple, ils peuvent vouloir déployer un modèle Gemma3 pour une interface de chatbot et un modèle Deepseek pour une application de recommandation. L'entreprise doit garantir des performances de diffusion optimales pour ces LLM.
La passerelle d'inférence GKE vous permet de déployer ces LLM sur votre cluster GKE avec la configuration d'accélérateur de votre choix dans un InferencePool. Vous pouvez ensuite acheminer les requêtes en fonction du nom du modèle (par exemple, chatbot et recommender) et de la propriété Priority.
Le schéma suivant illustre la manière dont la passerelle GKE Inference achemine les requêtes vers différents modèles en fonction du nom du modèle et de Priority.
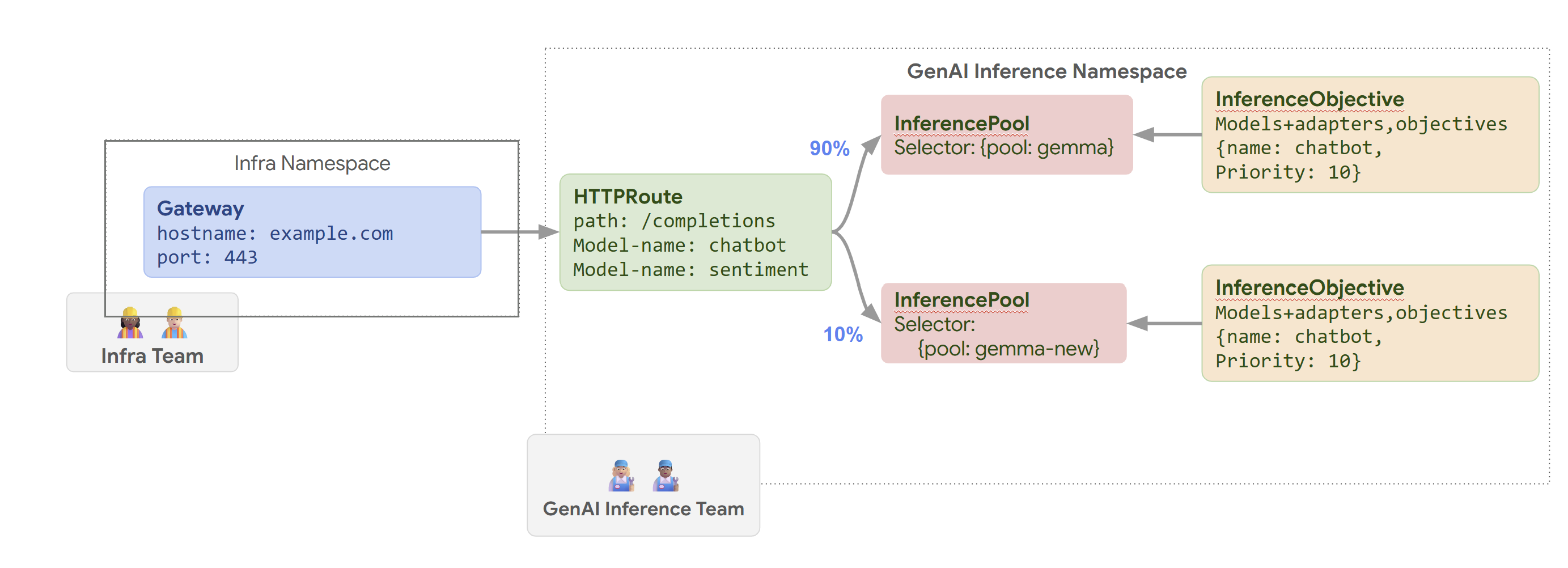
Ce schéma illustre la façon dont une requête adressée à un service d'IA générative sur example.com/completions est traitée par GKE Inference Gateway. La requête atteint d'abord un Gateway dans l'espace de noms Infra. Ce Gateway transmet la requête à un HTTPRoute dans l'espace de noms GenAI Inference, qui est configuré pour gérer les requêtes pour les modèles de chatbot et d'analyse des sentiments. Pour le modèle de chatbot, HTTPRoute répartit le trafic : 90 % est dirigé vers un InferencePool exécutant la version actuelle du modèle (sélectionnée par {pool: gemma}) et 10 % est dirigé vers un pool avec une version plus récente ({pool: gemma-new}), généralement pour les tests Canary.
Les deux pools sont associés à un InferenceObjective qui attribue un Priority de 10 aux requêtes pour le modèle de chatbot, ce qui garantit que ces requêtes sont traitées en priorité.
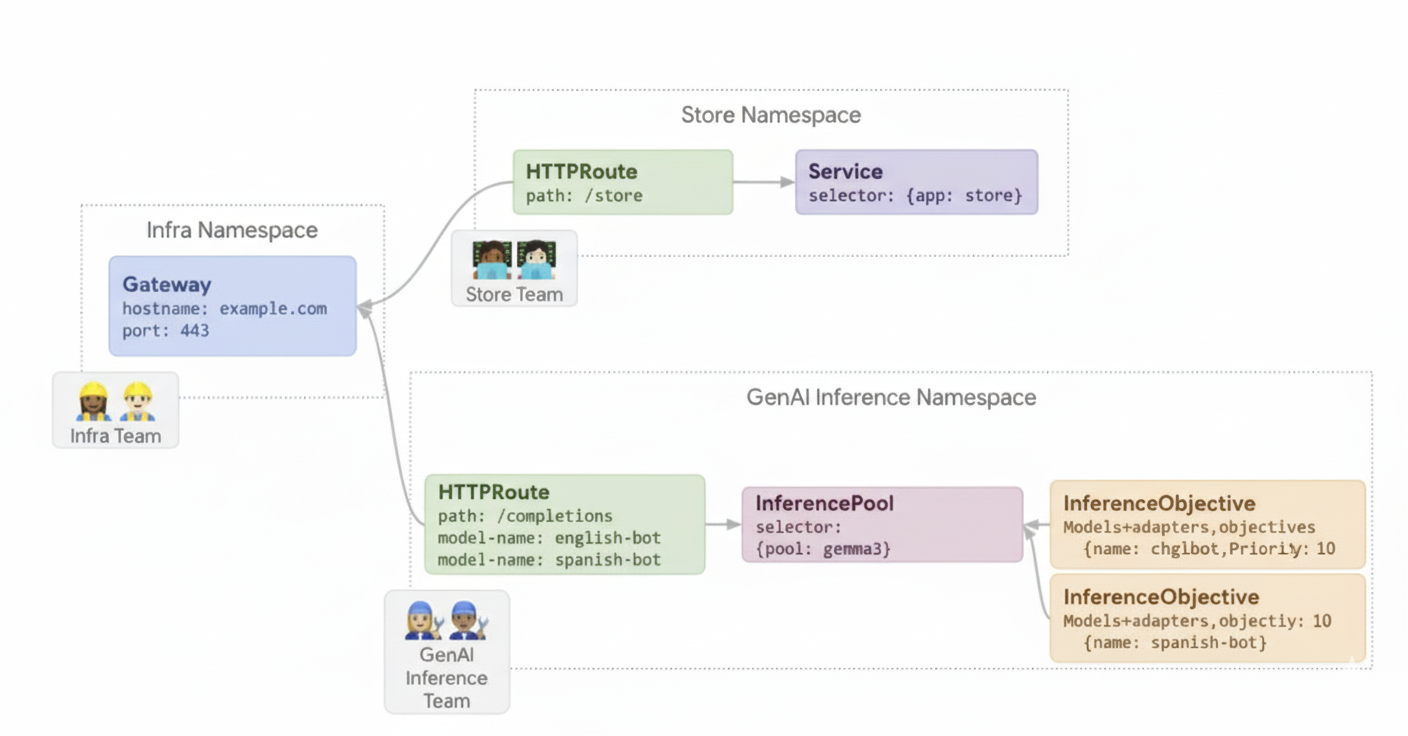
Exemple 2 : Mettre en service des adaptateurs LoRA sur un accélérateur partagé
Une entreprise souhaite diffuser des LLM pour l'analyse de documents et se concentre sur des audiences dans plusieurs langues, comme l'anglais et l'espagnol. Ils ont affiné des modèles pour chaque langue, mais doivent utiliser efficacement leur capacité de GPU et de TPU. Vous pouvez utiliser la passerelle d'inférence GKE pour déployer des adaptateurs LoRA affinés dynamiques pour chaque langue (par exemple, english-bot et spanish-bot) sur un modèle de base commun (par exemple, llm-base) et un accélérateur. Cela vous permet de réduire le nombre d'accélérateurs requis en regroupant plusieurs modèles sur un accélérateur commun.
Le schéma suivant illustre la manière dont GKE Inference Gateway diffuse plusieurs adaptateurs LoRA sur un accélérateur partagé.
Étapes suivantes
- Déployer GKE Inference Gateway
- Personnaliser la configuration de GKE Inference Gateway
- Diffuser un LLM avec GKE Inference Gateway