BigQuery
使用 BigQuery 連接器對 Google BigQuery 資料執行插入、刪除、更新和讀取作業。您也可以對 BigQuery 資料執行自訂 SQL 查詢。您可以使用 BigQuery 連接器整合多項 Google Cloud 服務或其他第三方服務 (例如 Cloud Storage 或 Amazon S3) 的資料。
事前準備
在 Google Cloud 專案中,執行下列工作:
- 確認已設定網路連線。如要瞭解網路模式,請參閱「網路連線」。
- 將 roles/connectors.admin IAM 角色授予設定連結器的使用者。
- 將
roles/bigquery.dataEditorIAM 角色授予要用於連接器的服務帳戶。如果您沒有服務帳戶,請務必建立服務帳戶。連接器和服務帳戶必須屬於同一個專案。 - 啟用下列服務:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
如要瞭解如何啟用服務,請參閱「啟用服務」。如果先前未啟用這些服務或權限,系統會在您設定連結器時提示啟用。
建立 BigQuery 連線
連線專屬於資料來源。也就是說,如果您有多個資料來源,則必須為每個資料來源建立個別的連線。如要建立連線,請按照下列步驟操作:
- 在 Cloud 控制台中,前往「Integration Connectors」>「Connections」頁面,然後選取或建立 Google Cloud 專案。
- 按一下「+ 建立新連線」,開啟「建立連線」頁面。
- 在「位置」部分,從「區域」清單中選取位置,然後按一下「下一步」。
如需所有支援的地區清單,請參閱「位置」一文。
- 在「連線詳細資料」部分中,執行下列操作:
- 從「連接器」清單中選取「BigQuery」。
- 從「連接器版本」清單中選取連接器版本。
- 在「連線名稱」欄位中,輸入連線執行個體的名稱。連線名稱可包含小寫英文字母、數字或連字號,名稱開頭須為英文字母,結尾須為英文字母或數字,且不得超過 49 個字元。
- 或者,可啟用 Cloud Logging,然後選取記錄層級。記錄層級預設為
Error。 - 服務帳戶:選取具備必要角色的服務帳戶。
- (選用) 設定連線節點設定。
- 節點數量下限:輸入連線節點數量下限。
- 節點數量上限:輸入連線節點數量上限。
- 專案 ID:資料所在的 Google Cloud 專案 ID。
- 資料集 ID:BigQuery 資料集的 ID。
- 如要支援 BigQuery 陣列資料類型,請選取「支援原生資料類型」。支援的陣列類型包括 Varchar、Int64、Float64、Long、Double、Bool 和 Timestamp。不支援巢狀陣列。
- (選用) 如要為連線設定 Proxy 伺服器,請選取「使用 Proxy」並輸入 Proxy 詳細資料。
-
Proxy Auth Scheme:選取與 Proxy 伺服器進行驗證的驗證類型。系統支援下列驗證類型:
- 基本:基本 HTTP 驗證。
- 摘要:摘要 HTTP 驗證。
- Proxy 使用者:用於向 Proxy 伺服器驗證的使用者名稱。
- Proxy Password:使用者的密碼 Secret Manager 密鑰。
-
Proxy SSL Type:連線至 Proxy 伺服器時要使用的 SSL 類型。系統支援下列驗證類型:
- 自動:預設設定。如果網址是 HTTPS 網址,則會使用「Tunnel」(通道) 選項。如果網址是 HTTP 網址,系統會使用「永不」選項。
- 「Always」(一律):連線一律啟用 SSL。
- 「永不」:連線未啟用 SSL。
- 通道:連線是透過通道 Proxy 建立。Proxy 伺服器會開啟與遠端主機的連線,流量會透過 Proxy 來回傳送。
- 在「Proxy 伺服器」部分中,輸入 Proxy 伺服器的詳細資料。
- 點按「下一步」。
節點是用來處理交易的連線單位 (或備用資源)。如要處理更多連線交易,就需要更多節點;反之,如要處理較少的交易,則需要較少的節點。如要瞭解節點對連線器定價的影響,請參閱「 連線節點定價」。如未輸入任何值,系統預設會將節點下限設為 2 (提高可用性),節點上限則設為 50。
-
在「Authentication」(驗證) 部分,輸入驗證詳細資料。
- 選取要使用 OAuth 2.0 授權碼驗證,還是不進行驗證。
如要瞭解如何設定驗證,請參閱「設定驗證」。
- 點按「下一步」。
- 選取要使用 OAuth 2.0 授權碼驗證,還是不進行驗證。
- 查看連線和驗證詳細資料,然後按一下「建立」。
設定驗證機制
根據要使用的驗證方式輸入詳細資料。
- 不需驗證:如果不需要驗證,請選取這個選項。
- OAuth 2.0 - 授權碼:選取這個選項,即可使用以網路為基礎的使用者登入流程進行驗證。指定下列詳細資料:
- 用戶端 ID: 連線至後端 Google 服務時所需的用戶端 ID。
- 範圍: 以逗號分隔的所需範圍清單。如要查看所需 Google 服務支援的所有 OAuth 2.0 範圍,請參閱「Google API 適用的 OAuth 2.0 範圍」頁面中的相關部分。
- 用戶端密鑰: 選取 Secret Manager 密鑰。 設定這項授權前,您必須先建立 Secret Manager 密鑰。
- 密鑰版本: 用戶端密鑰的 Secret Manager 密鑰版本。
如果是 Authorization code 驗證類型,建立連線後必須授權連線。
授權連結
如果您使用 OAuth 2.0 - 授權碼驗證連線,請在建立連線後完成下列工作。
- 在「連線」頁面中,找出新建立的連線。
請注意,新連接器的「狀態」會顯示「需要授權」。
- 按一下「需要授權」。
系統隨即會顯示「Edit authorization」(編輯授權) 窗格。
- 將「重新導向 URI」值複製到外部應用程式。
- 驗證授權詳細資料。
- 按一下「Authorize」。
授權成功後,「連線」頁面的連線狀態會設為「有效」。
重新授權授權碼
如果您使用 Authorization code 驗證類型,且在 BigQuery 中進行任何設定變更,就必須重新授權 BigQuery 連線。如要重新授權連結,請按照下列步驟操作:
- 在「連線」頁面中,按一下所需連線。
系統隨即會開啟連線詳細資料頁面。
- 按一下「編輯」即可編輯連結詳細資料。
- 在「驗證」部分中,驗證「OAuth 2.0 - 授權碼」詳細資料。
視需要進行變更。
- 按一下 [儲存]。系統會將您帶往連線詳細資料頁面。
- 在「驗證」部分中,按一下「編輯授權」。系統會顯示「Authorize」(授權) 窗格。
- 按一下「Authorize」。
如果授權成功,「連線」頁面的連線狀態會設為「有效」。
在整合中使用的 BigQuery 連線
建立連線後,Apigee Integration 和 Application Integration 都會提供該連線。您可以在整合中透過「連線器」工作使用連線。
- 如要瞭解如何在 Apigee Integration 中建立及使用「連線器」工作,請參閱「連線器工作」。
- 如要瞭解如何在 Application Integration 中建立及使用「連線器」工作,請參閱「連線器工作」。
動作
本節說明 BigQuery 連接器提供的動作。
執行整合後,所有實體作業和動作的結果都會以 JSON 回應的形式,顯示在 Connectors 工作的 connectorOutputPayload 回應參數中。
CancelJob 動作
這項操作可取消正在執行的 BigQuery 工作。
下表說明 CancelJob 動作的輸入參數。
| 參數名稱 | 資料類型 | 說明 |
|---|---|---|
| JobId | 字串 | 要取消的工作 ID。這是必填欄位。 |
| 區域 | 字串 | 目前執行作業的區域。如果工作位於美國或歐盟地區,則不需要這項設定。 |
GetJob 動作
這項動作可讓您擷取現有工作的設定資訊和執行狀態。
下表說明 GetJob 動作的輸入參數。
| 參數名稱 | 資料類型 | 說明 |
|---|---|---|
| JobId | 字串 | 要擷取設定的工作 ID。這是必填欄位。 |
| 區域 | 字串 | 目前執行作業的區域。如果工作位於美國或歐盟地區,則不需要這項設定。 |
InsertJob 動作
這項動作可讓您插入 BigQuery 工作,之後選取該工作即可擷取查詢結果。
下表說明 InsertJob 動作的輸入參數。
| 參數名稱 | 資料類型 | 說明 |
|---|---|---|
| 查詢 | 字串 | 要提交至 BigQuery 的查詢。這是必填欄位。 |
| IsDML | 字串 | 如果查詢是 DML 陳述式,則應設為 true,否則應設為 false。預設值為 false。 |
| DestinationTable | 字串 | 查詢的目的地資料表,格式為 DestProjectId:DestDatasetId.DestTable。 |
| WriteDisposition | 字串 | 指定如何將資料寫入目的地資料表,例如截斷現有結果、附加現有結果,或僅在資料表空白時寫入資料。支援的值如下:
|
| DryRun | 字串 | 指定作業執行是否為模擬測試。 |
| MaximumBytesBilled | 字串 | 指定作業可處理的位元組上限。如果工作嘗試處理的位元組數超過指定值,BigQuery 就會取消工作。 |
| 區域 | 字串 | 指定工作應執行的區域。 |
InsertLoadJob 動作
這項動作可讓您插入 BigQuery 載入工作,將 Google Cloud Storage 中的資料新增至現有資料表。
下表說明 InsertLoadJob 動作的輸入參數。
| 參數名稱 | 資料類型 | 說明 |
|---|---|---|
| SourceURIs | 字串 | 以空格分隔的 Google Cloud Storage URI 清單。 |
| SourceFormat | 字串 | 檔案的來源格式。支援的值如下:
|
| DestinationTable | 字串 | 查詢的目的地資料表,格式為 DestProjectId.DestDatasetId.DestTable。 |
| DestinationTableProperties | 字串 | JSON 物件,用於指定表格友善名稱、說明和標籤清單。 |
| DestinationTableSchema | 字串 | JSON 清單,指定用於建立資料表的欄位。 |
| DestinationEncryptionConfiguration | 字串 | JSON 物件,用於指定資料表的 KMS 加密設定。 |
| SchemaUpdateOptions | 字串 | JSON 清單,指定更新目標資料表結構定義時要套用的選項。 |
| TimePartitioning | 字串 | JSON 物件,用於指定時間分割類型和欄位。 |
| RangePartitioning | 字串 | JSON 物件,用於指定範圍分割欄位和 bucket。 |
| 分群 | 字串 | JSON 物件,指定用於叢集的欄位。 |
| 自動偵測 | 字串 | 指定是否應自動判斷 JSON 和 CSV 檔案的選項和結構定義。 |
| CreateDisposition | 字串 | 指定目的地資料表不存在時是否要建立。支援的值如下:
|
| WriteDisposition | 字串 | 指定如何將資料寫入目的地資料表,例如截斷現有結果、附加現有結果,或僅在資料表空白時寫入資料。支援的值如下:
|
| 區域 | 字串 | 指定工作應執行的區域。Google Cloud Storage 資源和 BigQuery 資料集必須位於相同區域。 |
| DryRun | 字串 | 指定作業執行是否為模擬測試。預設值為 false。 |
| MaximumBadRecords | 字串 | 指定整個工作取消前可無效的記錄數量。根據預設,所有記錄都必須有效。預設值為 0。 |
| IgnoreUnknownValues | 字串 | 指定是否必須忽略輸入檔案中的不明欄位,或將其視為錯誤。預設會視為錯誤。預設值為 false。 |
| AvroUseLogicalTypes | 字串 | 指定是否必須使用 AVRO 邏輯型別,將 AVRO 資料轉換為 BigQuery 型別。預設值為 true。 |
| CSVSkipLeadingRows | 字串 | 指定要略過 CSV 檔案開頭的列數。這通常用於略過標題列。 |
| CSVEncoding | 字串 | CSV 檔案的編碼類型。支援的值如下:
|
| CSVNullMarker | 字串 | 如果提供這個字串,系統會將其用於 CSV 檔案中的 NULL 值。根據預設,CSV 檔案無法使用 NULL。 |
| CSVFieldDelimiter | 字串 | 用來分隔 CSV 檔案中資料欄的字元。預設值為半形逗號 (,)。 |
| CSVQuote | 字串 | CSV 檔案中用於引用欄位的字元。可設為空白,停用引號。預設值為雙引號 (")。 |
| CSVAllowQuotedNewlines | 字串 | 指定 CSV 檔案是否可在引用欄位中使用換行符號。預設值為 false。 |
| CSVAllowJaggedRows | 字串 | 指定 CSV 檔案是否可包含缺少的欄位。預設值為 false。 |
| DSBackupProjectionFields | 字串 | 要從 Cloud Datastore 備份載入的欄位 JSON 清單。 |
| ParquetOptions | 字串 | JSON 物件,指定 Parquet 專屬的匯入選項。 |
| DecimalTargetTypes | 字串 | JSON 清單,提供套用至數值型別的偏好順序。 |
| HivePartitioningOptions | 字串 | 指定來源端分割選項的 JSON 物件。 |
執行自訂 SQL 查詢
如要建立自訂查詢,請按照下列步驟操作:
- 請按照詳細說明 新增連接器工作。
- 設定連接器工作時,請在要執行的動作類型中選取「動作」。
- 在「動作」清單中,選取「執行自訂查詢」,然後按一下「完成」。
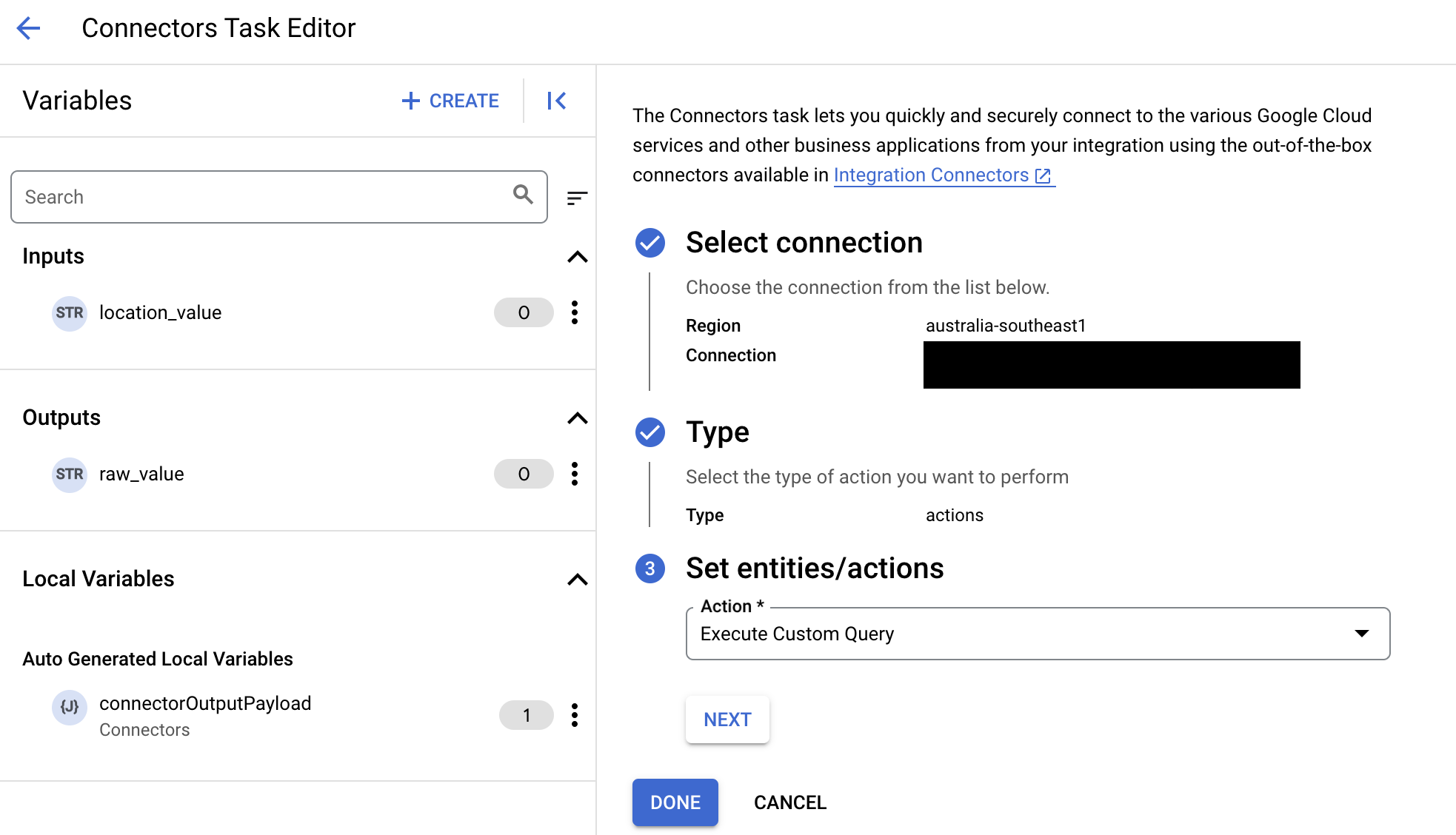
- 展開「Task input」(工作輸入) 區段,然後執行下列操作:
- 在「Timeout after」(逾時時間) 欄位中,輸入查詢執行前的等待秒數。
預設值:
180秒。 - 在「資料列數量上限」欄位中,輸入要從資料庫傳回的資料列數量上限。
預設值為
25。 - 如要更新自訂查詢,請按一下「編輯自訂指令碼」。「指令碼編輯器」對話方塊隨即開啟。
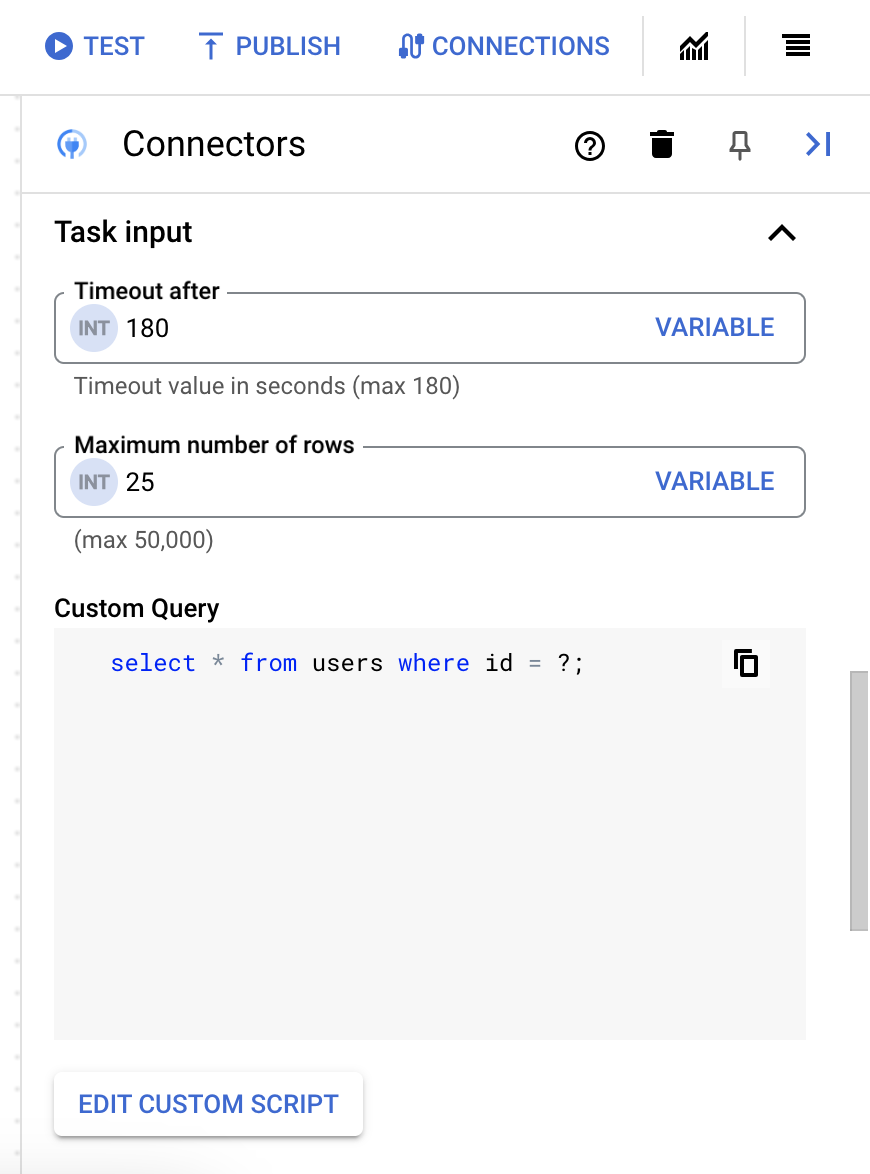
- 在「指令碼編輯器」對話方塊中輸入 SQL 查詢,然後按一下「儲存」。
您可以在 SQL 陳述式中使用問號 (?) 代表單一參數,該參數必須在查詢參數清單中指定。舉例來說,下列 SQL 查詢會從
Employees資料表選取與LastName資料欄指定值相符的所有資料列:SELECT * FROM Employees where LastName=?
- 如果您在 SQL 查詢中使用問號,請為每個問號點按「+ 新增參數名稱」,加入參數。執行整合時,這些參數會依序取代 SQL 查詢中的問號 (?)。舉例來說,如果您新增了三個問號 (?),就必須依序新增三個參數。
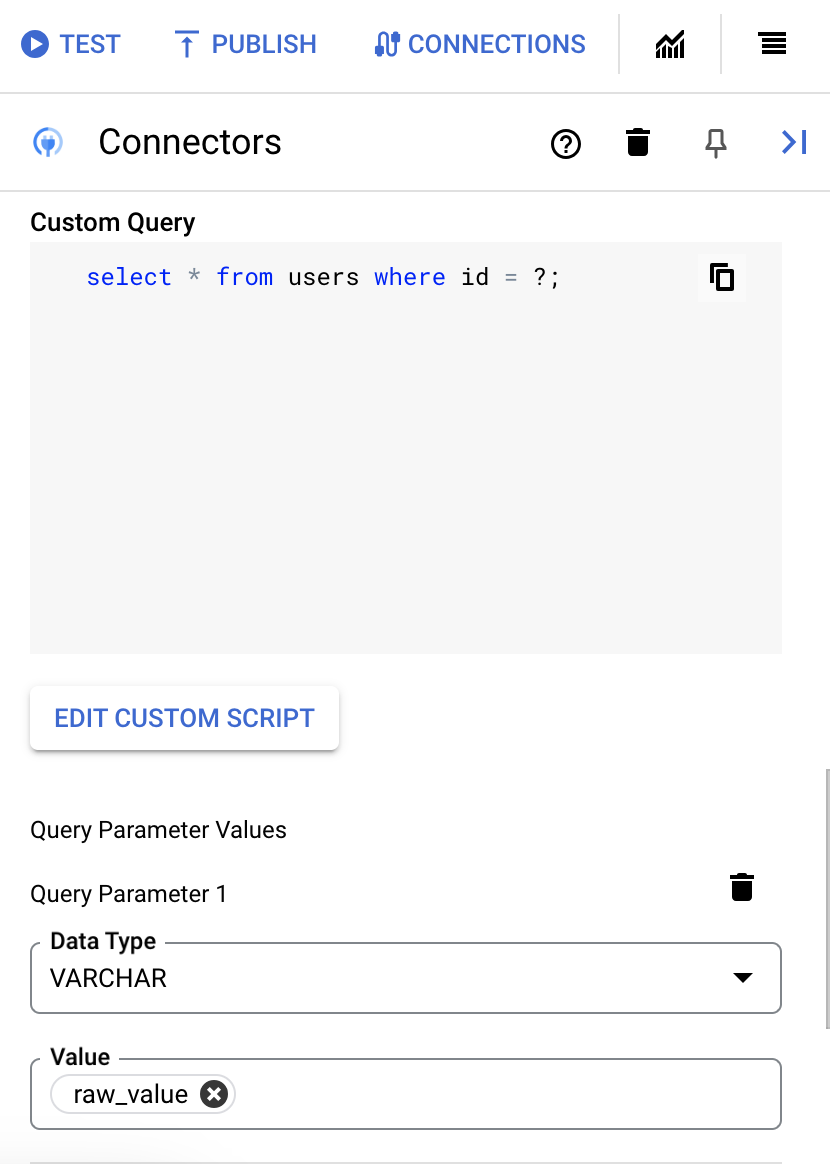
如要新增查詢參數,請按照下列步驟操作:
- 在「類型」清單中,選取參數的資料類型。
- 在「值」欄位中輸入參數值。
- 如要新增多個參數,請按一下「+ 新增查詢參數」。
「執行自訂查詢」動作不支援陣列變數。
- 在「Timeout after」(逾時時間) 欄位中,輸入查詢執行前的等待秒數。
使用 Terraform 建立連線
您可以使用 Terraform 資源建立新連線。
如要瞭解如何套用或移除 Terraform 設定,請參閱「基本 Terraform 指令」。
如要查看用於建立連線的 Terraform 範本範例,請參閱範本範例。
使用 Terraform 建立這項連線時,您必須在 Terraform 設定檔中設定下列變數:
| 參數名稱 | 資料類型 | 必填 | 說明 |
|---|---|---|---|
| project_id | STRING | 是 | BigQuery 資料集所屬專案的 ID,例如 myproject。 |
| dataset_id | STRING | 否 | BigQuery 資料集的資料集 ID,不含專案名稱。例如:mydataset。 |
| proxy_enabled | BOOLEAN | 否 | 選取這個核取方塊,即可設定連線的 Proxy 伺服器。 |
| proxy_auth_scheme | ENUM | 否 | 用於向 ProxyServer Proxy 驗證的驗證類型。支援的值包括:BASIC、DIGEST、NONE |
| proxy_user | STRING | 否 | 用於向 ProxyServer Proxy 驗證的使用者名稱。 |
| proxy_password | SECRET | 否 | 用於向 ProxyServer 代理程式驗證的密碼。 |
| proxy_ssltype | ENUM | 否 | 連線至 ProxyServer Proxy 時要使用的 SSL 類型,支援的值包括:AUTO、ALWAYS、NEVER、TUNNEL |
系統限制
BigQuery 連接器每秒最多可處理 8 筆交易 (每個節點),並節流任何超出此限制的交易。根據預設,Integration Connectors 會為連線分配 2 個節點 (提高可用性)。
如要瞭解 Integration Connectors 適用的限制,請參閱「限制」一文。
支援的資料類型
這個連接器支援的資料類型如下:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- 時間
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
已知限制
向 Google Cloud 社群尋求協助
如要發布問題及討論這個連接器,請前往 Cloud 論壇的 Google Cloud 社群。