将 FHIR R4 数据导入到医疗保健搜索应用后,您可以查询导入的数据以获取相关结果。您可以使用以下类型的查询进行搜索:
- 关键字查询
- 自然语言查询
- 包含生成式 AI 回答的自然语言查询
此外,您还可以使用按日期过滤的查询来过滤搜索结果。如需了解详情,请参阅定义 resource_datetime 过滤条件。
在 Google Cloud 控制台中进行搜索时,您必须先提供患者 ID,然后一次搜索一位患者的数据。使用 REST API 进行搜索时,您可以搜索整个数据存储区。
本页介绍了如何使用各种类型的查询搜索医疗保健数据。
Vertex AI Search 在搜索医疗保健数据方面的预期用途
Vertex AI Search 的预期用途不包括提供与疾病预防、诊断或治疗相关的信息。本产品不适用于解答有关诊断或治疗建议的问题。本产品的预期用途是检索和总结用户提供的现有医疗信息。
由于测试数据有限,此产品可能适用于也可能不适用于 0-18 岁和 85 岁及以上的年龄段。因此,在查看生成的输出时,客户必须考虑其源数据中子人口的代表性。
以下是一些有关本产品预期用途的示例:
探索性查询,用于查找与某个主题相关的患者信息:
- “总结阿司匹林的用途”
- “血压”
- “糖尿病管理?”
用于查找可映射到结构化查询的特定资源的导航查询:
- “显示最新的糖化血红蛋白”
提取式问题和答案,用于回答证据可能分散在多个资源中的具体问题:
- “此患者是否曾接受过头孢菌素治疗”
- “患者是否曾接受过精神病学评估”
以下示例说明了本产品不适合的用途:
诊断建议和治疗建议:
- “What is the differential diagnosis for this patient?”
- “我应该给患者开什么药?”
查询准则
以下准则可帮助您构建能够提供更优质搜索结果的查询:
搜索具有明确意图的查询:由于模型不知道您要查找的内容,因此最好提供有针对性的查询,而不是模糊的查询。例如,搜索关键字“高血压”比搜索关键字“摘要”更好。虽然查询“高血压”会从相关文档中提取特定结果,但查询“摘要”可能会从不相关的文档中提取结果。
保留上下文:由于搜索不是对话式的,因此最好为每个查询提供完整的上下文。例如,如果您的初始查询是“高血压”,并且您想跟进同一主题,那么“高血压是什么时候诊断出来的”比“它是什么时候诊断出来的”更适合作为第二个查询。
简化查询:尽可能将复杂的查询分解为更简单的查询。例如,您可以根据自己的目标,分别搜索“肌酐”“白蛋白”和“肌酐白蛋白比值”,而不是搜索“肌酐和白蛋白”。
避免要求模型进行推理:如果模型可以从搜索到的文档中逐字返回信息,而不是根据搜索到的信息进行计算或推断,那么搜索结果会更精确。例如,您可以查询“列出患者最近 10 次就诊时的体重”,然后单独计算体重变化,而不是查询“患者体重变化了多少”。
在结果中突出显示匹配项
匹配项突出显示是一种配置,用于突出显示搜索结果中与搜索查询在上下文中匹配的部分文字。
以下资源类型的结果支持突出显示匹配项:
- 组成:突出显示
Composition.section[].text.div字段中的上下文相关文本。 - DiagnosticReport:突出显示
DiagnosticReport.conclusion字段中的上下文文本。 DocumentReference:突出显示
DocumentReference.content[0].attachment.url字段中引用的文档中的上下文文本。突出显示的文字包含在边界框内。边界框在搜索响应中由两组归一化坐标表示。支持匹配突出显示的文档是 PDF 文件和具有支持的类型的图片文件。下图显示了如何突出显示 DocumentReference 资源类型中的扫描文档中的文字:
图 1:在扫描的 DocumentReference 文档中突出显示匹配项。
使用 REST API 进行搜索时,您必须使用 matchHighlightingCondition 字段在搜索请求中启用匹配项突出显示功能。响应包含 match_highlighting 字段,您可以使用该字段在搜索应用中呈现突出显示的文字:
- 对于 Composition 和 DiagnosticReport 文档,
match_highlighting字段包含必须突出显示的令牌的起始和结束索引。 - 对于 DocumentReference 文档,
match_highlighting字段包含突出显示文本的边界框的坐标。边界框由两组归一化坐标表示,其原点位于文档的左上角。此字段还嵌套了page_number字段,该字段对于图片设置为0,对于 PDF 文件的第一页设置为1。
使用 Google Cloud 控制台预览搜索结果时,系统会默认启用匹配项突出显示功能。
准备工作
在搜索之前,请执行以下操作:
- 创建医疗保健搜索应用和医疗保健搜索数据存储区,并导入 FHIR R4 数据。如需了解详情,请参阅创建医疗保健搜索应用和创建医疗保健搜索数据存储区。
- 配置医疗数据的搜索结果。
- 如需在搜索时获取实用查询建议,请开启自动补全功能。这是预览版功能。
- 查看 Vertex AI Search 支持的 FHIR R4 资源列表。 如需了解详情,请参阅 Healthcare FHIR R4 数据架构参考文档。
使用关键字进行搜索
您可以使用关键字搜索医疗保健数据存储区。例如,您可以使用“a1c”“insulin”或“ulcer”等关键字进行搜索,以获取相关的 FHIR 资源。
下图显示了关键字为“脂类”时的搜索结果。此示例不包含摘要或生成式 AI 回答。
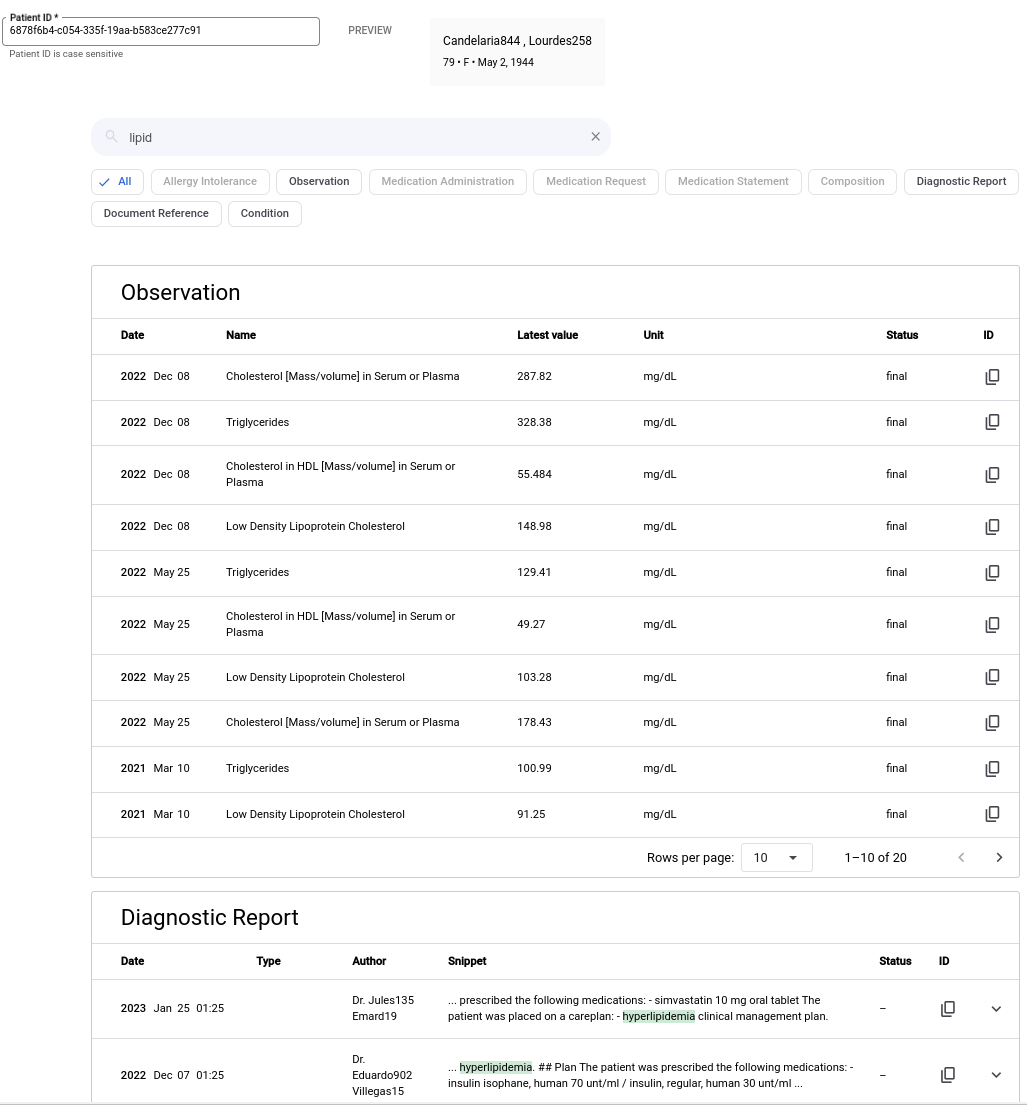
如需使用关键字进行搜索,请完成以下步骤。
控制台
在 Google Cloud 控制台中,前往 AI Applications 页面。
选择要查询的医疗保健搜索应用。
在导航菜单中,点击预览。
在患者 ID 字段中,输入要查询其数据的患者的 ID。患者 ID 区分大小写。
按 Enter 键或点击预览以提交患者 ID。
在在此处搜索搜索栏中,输入关键字进行搜索。
如果您启用了自动补全功能,那么在您输入内容时,搜索栏下方会显示自动补全建议列表。
按 Enter 键提交查询。
- 搜索结果会显示在分页表格中,并按 FHIR 资源类型进行分类。
- 默认情况下,所有 FHIR 资源类型的搜索结果都会按时间倒序显示。
可选。如需过滤结果,请选择搜索栏下方的一个或多个 FHIR 资源类别。
可选。如需按相关性对 Composition、DocumentReference 和 DiagnosticReport 资源的结果进行排序,请点击排序:按时间倒序过滤条件,然后从列表中选择相关性。如需了解详情,请参阅医疗保健搜索结果的排序方式。
REST
以下示例展示了如何在医疗保健搜索应用中使用关键字搜索单个患者的 FHIR R4 数据。此示例使用 servingConfigs.search 方法。
默认情况下,搜索结果会按时间倒序返回。 当您搜索 Composition、DiagnosticReport 和 DocumentReference 资源时,可以按相关性对搜索结果进行排序。如需了解详情,请参阅医疗保健搜索结果的排序方式。
使用关键字进行搜索。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "KEYWORD_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}} "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'替换以下内容:
PROJECT_ID:您的 Google Cloud 项目的 ID。APP_ID:要查询的 Vertex AI Search 应用的 ID。KEYWORD_QUERY:您要搜索的关键字,用于在过滤后的患者的临床数据中进行搜索,例如“diabetes”或“a1c”。PATIENT_ID:您要搜索其数据的患者的资源 ID。MATCH_HIGHLIGHTING_CONDITION:一个字符串,可以具有以下值:MATCH_HIGHLIGHTING_DISABLED:关闭所有文档中的匹配项突出显示功能。MATCH_HIGHLIGHTING_ENABLED:在所有文档中启用匹配项突出显示功能。 如果您将此字段留空或未指定此字段,匹配项突出显示功能会设置为MATCH_HIGHLIGHTING_DISABLED,并在所有文档中处于关闭状态。
使用自然语言查询进行搜索
借助 Vertex AI Search,您可以获得复杂自然语言查询的结果。例如,下图显示了自然语言查询“与糖尿病相关的化验结果”的结果。
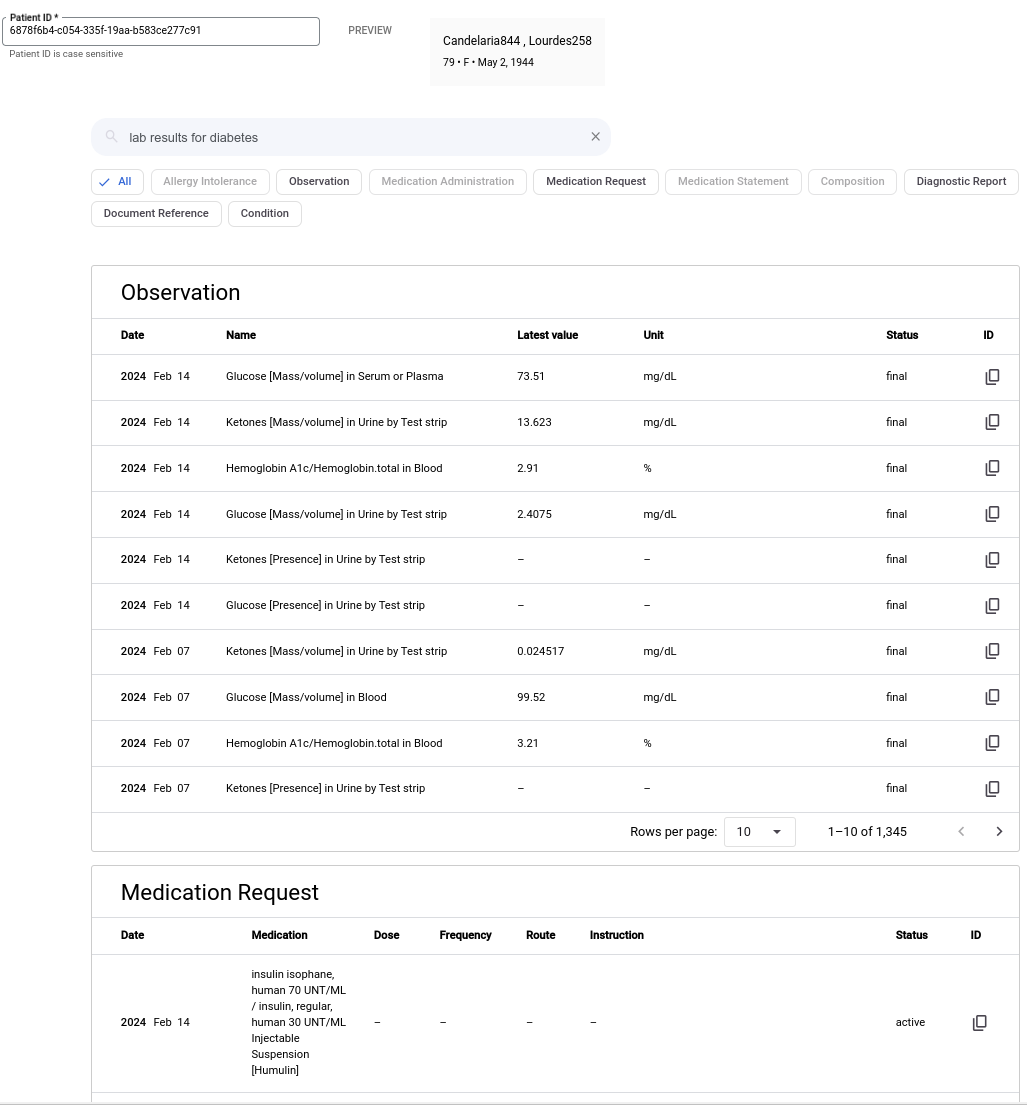
如需使用自然语言查询进行搜索,请完成以下步骤。
控制台
在 Google Cloud 控制台中,前往 AI Applications 页面。
选择要查询的医疗保健搜索应用。
在导航菜单中,点击预览。
在患者 ID 字段中,输入要查询其数据的患者的患者 ID。患者 ID 区分大小写。
按 Enter 键或点击预览以提交患者 ID。
在在此处搜索搜索栏中,输入自然语言查询内容,例如“与糖尿病相关的化验结果”。
如果您启用了自动补全功能,那么在您输入内容时,搜索栏下方会显示自动补全建议列表。
按 Enter 键提交查询。
- 搜索结果会显示在分页表格中,并按 FHIR 资源类型进行分类。
- 默认情况下,所有 FHIR 资源类型的搜索结果均按时间倒序显示。
可选。选择搜索栏下方的一个或多个 FHIR 资源类别,以过滤结果。
可选。如需按相关性对 Composition、DocumentReference 和 DiagnosticReport 资源的结果进行排序,请点击排序:按时间倒序过滤条件,然后从列表中选择相关性。如需了解详情,请参阅医疗保健搜索结果的排序方式。
REST
以下示例展示了如何使用自然语言查询在医疗保健搜索应用中搜索单个患者的 FHIR R4 数据。此示例使用 servingConfigs.search 方法。如需使用自然语言查询进行搜索,您必须将 naturalLanguageQueryUnderstandingSpec 字段添加到请求正文中。
默认情况下,搜索结果会按时间倒序返回。 当您搜索 Composition、DiagnosticReport 和 DocumentReference 资源时,可以按相关性对搜索结果进行排序。如需了解详情,请参阅医疗保健搜索结果的排序方式。
以自然语言发布查询。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "NATURAL_LANGUAGE_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}}, "naturalLanguageQueryUnderstandingSpec":{"filterExtractionCondition":"ENABLED"}, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'替换以下内容:
PROJECT_ID:您的 Google Cloud 项目的 ID。APP_ID:要查询的 Vertex AI Search 应用的 ID。NATURAL_LANGUAGE_QUERY:自然语言查询,例如“与糖尿病相关的化验结果”或“患者目前是否正在服用任何药物”。PATIENT_ID:您要搜索其数据的患者的资源 ID。MATCH_HIGHLIGHTING_CONDITION:一个字符串,可以具有以下值:MATCH_HIGHLIGHTING_DISABLED:关闭所有文档中的匹配项突出显示功能。MATCH_HIGHLIGHTING_ENABLED:在所有文档中启用匹配项突出显示功能。 如果您将此字段留空或未指定此字段,匹配项突出显示功能会设置为MATCH_HIGHLIGHTING_DISABLED,并在所有文档中处于关闭状态。
使用自然语言查询进行搜索,并获得生成式 AI 回答
当您使用自然语言查询搜索患者的 FHIR 数据时,可以选择在搜索结果中包含生成式 AI 回答。答案会总结搜索结果,还会显示用于生成答案的参考资料。
使用控制台时,您可以选择用于生成式 AI 回答的大语言模型 (LLM)。如需了解详情,请参阅为医疗保健数据配置搜索结果。
使用 REST API 时,您可以在 version 字段中指定以下某个 LLM 模型,以获取生成式 AI 回答:
gemini-1.5-flash-001/answer_gen/v1或stable:基于gemini-1.5-flash-001模型构建的稳定正式版模型。如需了解详情,请参阅正式发布 (GA) 的模型。gemini-1.5-pro-002或preview:基于gemini-1.5-pro模型的预览版模型。
下图展示了自然语言查询和生成式 AI 回答的示例。搜索摘要通过总结相关结果中的发现来提供查询的答案。您可以展开包含引用标记的细分,查看用于生成所选细分的参考资料。 并非所有生成的答案都包含引用。
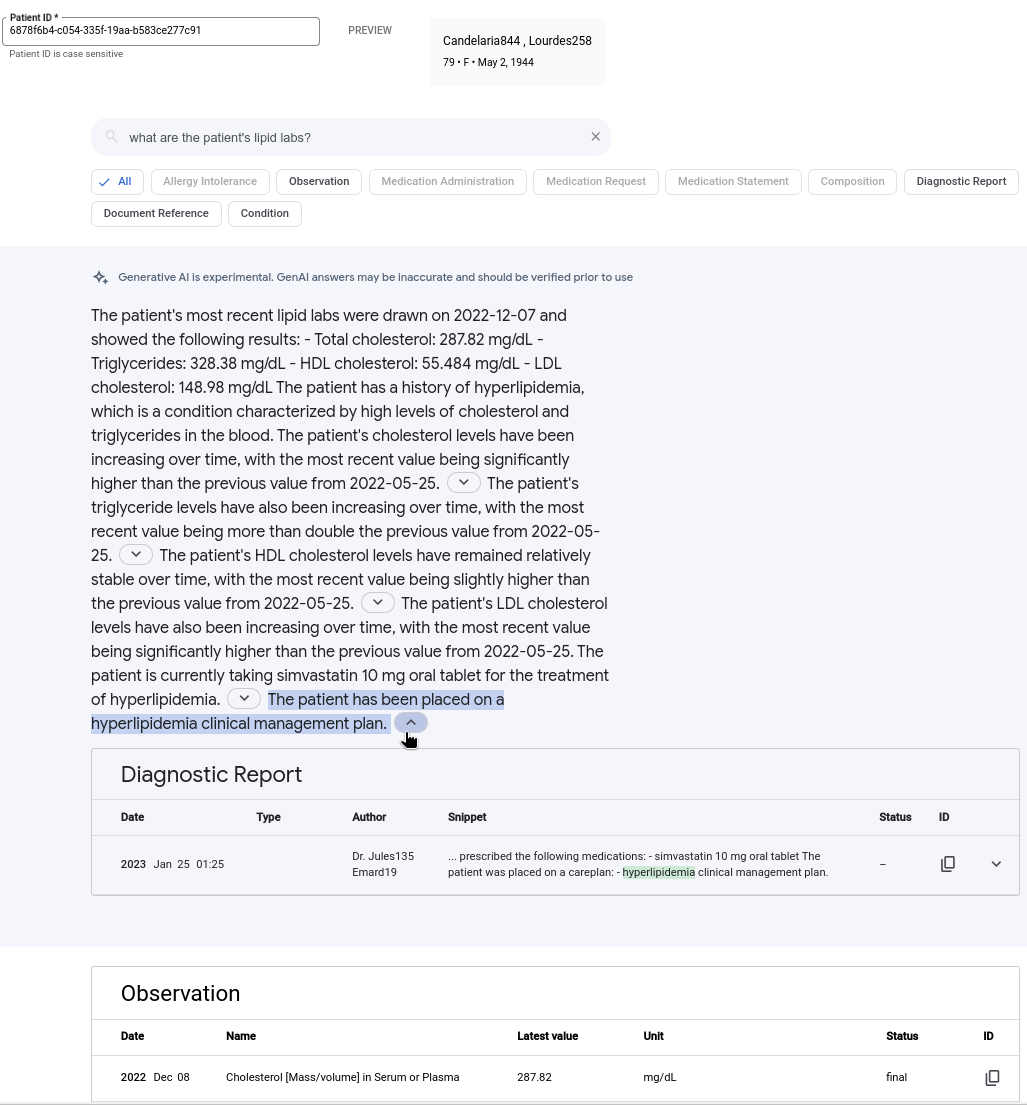
如需使用生成式 AI 回答进行搜索,请执行以下操作:
控制台
在 Google Cloud 控制台中,前往 AI Applications 页面。
选择要查询的医疗保健搜索应用。
在导航菜单中,点击配置。
自定义搜索微件:
- 在搜索类型字段中,选择搜索并获取答案。
- 选择要用于生成摘要的模型。如需了解详情,请参阅为医疗数据配置搜索结果
- 保存并发布您的偏好设置。
在导航菜单中,点击预览。
在患者 ID 字段中,输入要查询其数据的患者的患者 ID。患者 ID 区分大小写。
按 Enter 键或点击预览以提交患者 ID。
在在此处搜索搜索栏中,输入自然语言查询,例如“NSAID”“患者的血脂化验结果是什么”或“最新的 A1C 结果是什么”。
如果您启用了自动补全功能,那么在您输入内容时,搜索栏下方会显示自动补全建议列表。
按 Enter 键提交查询。
- 生成式 AI 回答会显示在搜索栏下方。
- 搜索结果会显示在分页表格中,并按 FHIR 资源类型进行分类。
- 默认情况下,所有 FHIR 资源类型的搜索结果均按时间倒序显示。
可选。展开回答中包含引用内容的部分,即可查看搜索结果中的参考内容。
可选。选择搜索栏下方的一个或多个 FHIR 资源类别,以过滤结果。
可选。如需按相关性对 Composition、DocumentReference 和 DiagnosticReport 资源的结果进行排序,请点击排序:按时间倒序过滤条件,然后从列表中选择相关性。如需了解详情,请参阅医疗保健搜索结果的排序方式。
REST
以下示例展示了如何在医疗保健搜索应用中使用自然语言查询和生成式 AI 回答来搜索单个患者的 FHIR R4 数据。此示例使用 servingConfigs.search 方法。
- 如需使用自然语言查询进行搜索,您必须将
naturalLanguageQueryUnderstandingSpec字段添加到请求正文中。 - 如需添加内嵌引用索引,您必须添加
includeCitations字段。这是一个布尔值字段,默认设置为false。
默认情况下,搜索结果会按时间倒序返回。 当您搜索 Composition、DiagnosticReport 和 DocumentReference 资源时,可以按相关性对搜索结果进行排序。如需了解详情,请参阅医疗保健搜索结果的排序方式。
以自然语言发布查询。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec": { "snippetSpec": { "returnSnippet": true }, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } "summarySpec": { "summaryResultCount": 1, "includeCitations": true, "modelSpec": { "version": "MODEL_VERSION" } } }, "naturalLanguageQueryUnderstandingSpec": { "filterExtractionCondition": "ENABLED" } }'替换以下内容:
PROJECT_ID:您的 Google Cloud 项目的 ID。APP_ID:要查询的 Vertex AI Search 应用的 ID。QUERY:自然语言查询,例如“NSAID”“患者的血脂化验结果是什么”或“最近的 A1C 结果是什么”。如果查询中包含撇号',您必须将其替换为撇号的数字字符引用:'。PATIENT_ID:您要搜索其数据的患者的资源 ID。MODEL_VERSION:您要用于生成答案的模型版本。MATCH_HIGHLIGHTING_CONDITION:一个字符串,可以具有以下值:MATCH_HIGHLIGHTING_DISABLED:关闭所有文档中的匹配项突出显示功能。MATCH_HIGHLIGHTING_ENABLED:在所有文档中启用匹配项突出显示功能。 如果您将此字段留空或未指定此字段,匹配项突出显示功能会设置为MATCH_HIGHLIGHTING_DISABLED,并在所有文档中处于关闭状态。