Nesta página, mostramos como usar a API para receber resumos de pesquisa com seus resultados. Também explicamos as opções disponíveis com os resumos gerados pela pesquisa. Apenas para dados não estruturados e de sites.
Para informações sobre como receber respostas de IA generativa para suas consultas de dados de saúde, consulte Pesquisar usando consultas em linguagem natural com respostas de IA generativa.
Antes de começar
Dependendo do tipo de app, siga estas instruções:
Para um app de pesquisa não estruturada: ative os Recursos avançados do LLM.
Para um app de pesquisa em sites, ative os seguintes recursos:
Indexação avançada de sites. Exige verificação de domínio.
Receber um resumo da pesquisa
Um resumo de pesquisa é uma breve sumarização dos principais resultados retornados em uma resposta de pesquisa. O resumo é extraído das respostas objetivas retornadas na resposta. Portanto, para receber um resumo, você também precisa receber respostas extrativas com os resultados da pesquisa. Para mais informações, consulte Receber respostas extrativas (prévia).
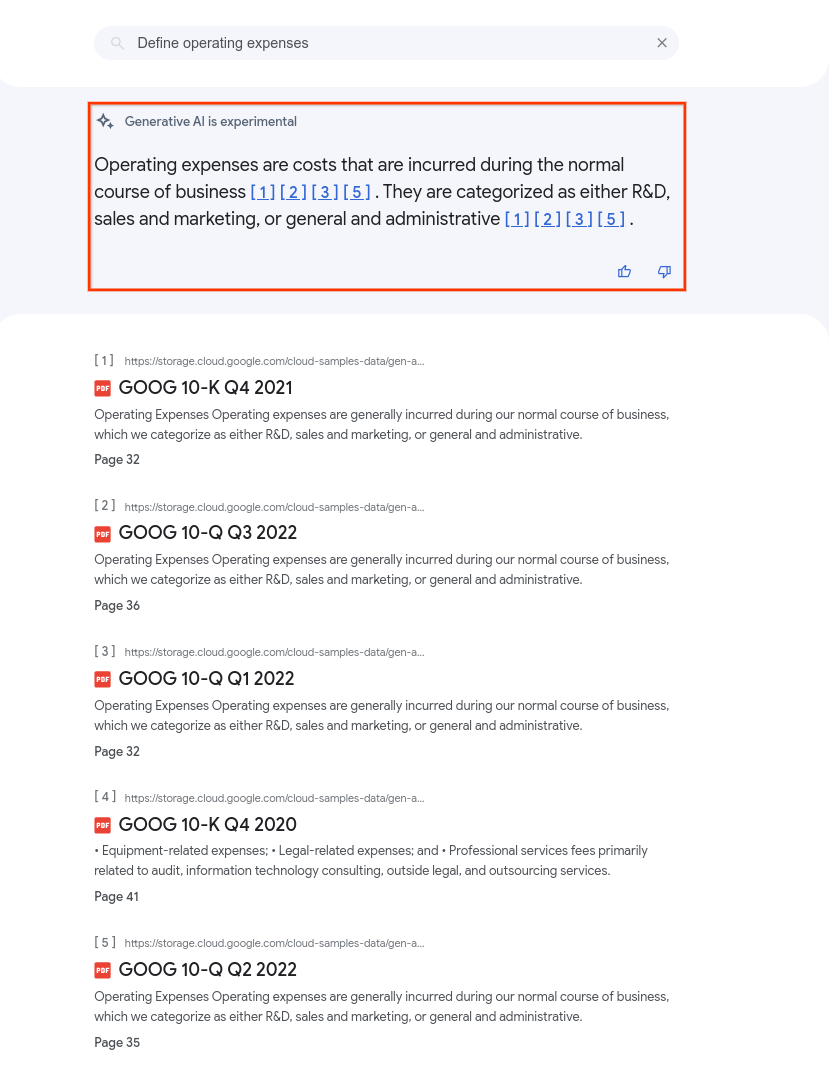
A imagem a seguir mostra o resumo quando os PDFs em um repositório de dados são consultados com
o summaryResultCount definido como 5. O conteúdo do resumo pode variar dependendo das configurações do app.
Os resumos da pesquisa podem incluir texto formatado em Markdown e tags HTML simples comumente entendidas por analisadores Markdown. Por isso, considere usar um analisador Markdown no seu aplicativo para renderizar texto Markdown.
Para receber um resumo da pesquisa, siga estas etapas:
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique valores parasummaryResultCountemaxExtractiveAnswerCount. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.No exemplo a seguir,
summarySpecindica que você quer um resumo da pesquisa gerado com base nos três principais resultados."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3 }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: o número de principais resultados para gerar o resumo da pesquisa. Se o número de resultados retornados for menor quesummaryResultCount, o resumo será gerado com base em todos os resultados.maxExtractiveAnswerCount: o número de respostas extraídas a serem retornadas para cada resultado da pesquisa. O valor padrão é 0 e o máximo é 1.
Receba o resumo da resposta da pesquisa. Uma propriedade
summaryé retornada em cada resposta.Confira um exemplo de resumo retornado no final de uma resposta de pesquisa:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform." }
Gerar resumos de partes semânticas
Ative a opção use_semantic_chunks para gerar resumos dos trechos de documentos mais relevantes. Usar partes semânticas para gerar resumos aumenta a capacidade de recordação e recuperação em comparação com o comportamento padrão de usar respostas extrativas.
Quando o chunking semântico está ativado para resumos, a resposta retorna o resumo e o conteúdo de cada parte usada.
Para usar os trechos semânticos na geração de resumos, siga estas etapas:
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique"use_semantic_chunks": true. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.O exemplo a seguir de
summarySpecindica que você quer um resumo da pesquisa que usa partes semânticas, quantos resultados incluir e se é necessário incluir citações."contentSearchSpec": { "summarySpec": { "useSemanticChunks": SEMANTIC_CHUNK_BOOLEAN, "summaryResultCount": SUMMARY_RESULT_COUNT, "includeCitations": CITATIONS_BOOLEAN, } }SEMANTIC_CHUNK_BOOLEAN: um booleano que especifica se os trechos semânticos serão usados para gerar o resumo da pesquisa. Se definido comotrue, os trechos semânticos serão usados.SUMMARY_RESULT_COUNT: o número de principais resultados para gerar o resumo da pesquisa. O valor máximo é10.CITATIONS_BOOLEAN: um booleano que especifica se as citações serão retornadas. Se você ativou o modo de fragmentação ao criar o repositório de dados, as citações se referem a fragmentos. Caso contrário, as citações se referem a documentos de origem. Para saber mais sobre o modo de fragmentação, consulte Analisar e fragmentar documentos.
Receba o resumo da resposta da pesquisa.
Confira um exemplo de resposta de pesquisa que inclui um resumo gerado com base em partes e citações. A parte
referencesda resposta contém o conteúdo dos trechos de texto usados para gerar o resumo.Resposta
{ "results": [ { "id": "123xyz", "document": { "name": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "id": "123xyz", "derivedStructData": { "link": "gs://examplebucket/alphabet-investor-pdfs/2004_google_annual_report.pdf" } } } ], "totalSize": 8375, "attributionToken": "abcdefg", "nextPageToken": "hijklmnop", "guidedSearchResult": {}, "summary": { "summaryText": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query. [1]", "summaryWithMetadata": { "summary": "Google's search technology uses a combination of techniques to determine the importance of a web page independent of a particular search query and to determine the relevance of that page to a particular search query.", "citationMetadata": { "citations": [ { "endIndex": "216", "sources": [ {} ] } ] }, "references": [ { "document": "projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/branches/0/documents/123xyz", "chunkContents": [ { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.", "pageIdentifier": "17" }, { "content": "Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.", "pageIdentifier": "17" }, { "content": "Groups contains more than 1 billion messages from Usenet Internet discussion groups dating back to 1981.The\ndiscussions in these groups cover a broad range of discourse and provide a comprehensive look at evolving\nviewpoints, debate and advice on many subjects.The new Google Groups adds in the ability to create your own\ngroups for you and your friends and an improved user interface.Google Mobile.Google Mobile offers people the ability to search and view both the "mobile web,"\nconsisting of pages created specifically for wireless devices, and the entire Google index of more than 8 billion\nweb pages.Google Mobile works on devices that support WAP, WAP 2.0, i-mode or j-sky mobile Internet\nprotocols.In addition, users can access a variety of information using Google SMS by typing a query to the\nGoogle shortcode.Google Mobile is available through many wireless and mobile phone services worldwide.\n\nGoogle Local.Google Local enables users to find relevant local businesses near a city, postal code, or specific\naddress.This service combines Yellow Page listings with information found on web pages, and plots their\nlocations on interactive maps.Google Print.Google Print brings information online that had previously not been available to web\nsearchers.Under this program, we enable a number of publishers to host their content and show their\npublications at the top of our search results.", "pageIdentifier": "17" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:\n\nGoogle AdWords Auction System.We use the Google AdWords auction system to enable advertisers to\nautomatically deliver relevant, targeted advertising.", "pageIdentifier": "21" }, { "content": "Votes cast by important web pages with high PageRank weigh more heavily and are\nmore influential in deciding the PageRank of pages on the web.Text-Matching Techniques.Our technology employs text-matching techniques that compare search queries\nwith the content of web pages to help determine relevance.Our text-based scoring techniques do far more than\ncount the number of times a search term appears on a web page.For example, our technology determines the\nproximity of individual search terms to each other on a given web page, and prioritizes results that have the\nsearch terms near each other.Many other aspects of a page's content are factored into the equation, as is the\ncontent of pages that link to the page in question.By combining query independent measures such as PageRank\nwith our text-matching techniques, we are able to deliver search results that are relevant to what people are\ntrying to find.\n\nAdvertising Technology\nOur advertising program serves millions of relevant, targeted ads each day based on search terms people\n\nenter or content they view on the web.The key elements of our advertising technology include:", "pageIdentifier": "21" }, { "content": "Google Maps—enables users to see maps, get directions, and find local businesses and services quickly\nand easily.Google Maps has several unique features, including draggable maps, integrated local search\nfrom Google Local, and keyboard shortcuts.Google Scholar—enables users to search specifically for scholarly literature, including peer-reviewed\npapers, theses, books, preprints, abstracts and technical reports from all broad areas of research.Google\nScholar can be used to find articles from a wide variety of academic publishers, professional societies,\npreprint repositories and universities, as well as scholarly articles available across the web.Google Suggest—guesses what you're typing and offers suggestions in real time.This is similar to\nGoogle's "Did you mean?"feature that offers alternative spellings for your query after you search, except\nthat it works in real time.Google Video—includes thousands of programs that play on our TVs every day.Google Video enables\nyou to search a growing archive of televised content—everything from sports to dinosaur\ndocumentaries to news shows.\n\n6", "pageIdentifier": "17" }, { "content": "Every search query we process involves the automated\nexecution of an auction, resulting in our advertising system often processing hundreds of millions of auctions per\nday.To determine whether an ad is relevant to a particular query, this system weighs an advertiser's willingness\nto pay for prominence in the ad listings (the CPC) and interest from users in the ad as measured by the click\nthrough rate and other factors.If an ad does not attract user clicks, it moves to a less prominent position on the\npage, even if the advertiser offers to pay a high amount.This prevents advertisers with irrelevant ads from\n"squatting" in top positions to gain exposure.Conversely, more relevant, well-targeted ads that are clicked on\nfrequently move up in ranking, with no need for advertisers to increase their bids.Because we are paid only\nwhen users click on ads, the AdWords ranking system aligns our interests equally with those of our advertisers\nand our users.The more relevant and useful the ad, the better for our users, for our advertisers and for us.\n\nThe AdWords auction system also incorporates our AdWords discounter, which automatically lowers the\namount advertisers actually pay to the minimum needed to maintain their ad position.", "pageIdentifier": "21" }, { "content": "Web Search Technology\nOur web search technology uses a combination of techniques to determine the importance of a web page\nindependent of a particular search query and to determine the relevance of that page to a particular search\nquery.We do not explain how we do ranking in great detail because some people try to manipulate our search\nresults for their own gain, rather than in an attempt to provide high-quality information to users.\n\nRanking Technology.One element of our technology for ranking web pages is called PageRank.While we\ndeveloped much of our ranking technology after Google was formed, PageRank was developed at Stanford\nUniversity with the involvement of our founders, and was therefore published as research.Most of our current\nranking technology is protected as trade-secret.PageRank is a query-independent technique for determining the\nimportance of web pages by looking at the link structure of the web.PageRank treats a link from web page A to\nweb page B as a "vote" by page A in favor of page B.The PageRank of a page is the sum of the PageRank of the\npages that link to it.The PageRank of a web page also depends on the importance (or PageRank) of the other\nweb pages casting the votes.", "pageIdentifier": "21" }, { "content": "The Company recognizes as revenue the fees charged advertisers each time a user clicks on one of the text\nbased ads that are displayed next to the search results on Google web sites.Effective January 1, 2004, the\nCompany offered a single pricing structure to all of its advertisers based on the AdWords cost per click model.\n\nGoogle AdSense is the program through which the Company distributes its advertisers' text-based ads for\ndisplay on the web sites of the Google Network members.In accordance with Emerging Issues Task Force\n("EITF") Issue No. 99 19, Reporting Revenue Gross as a Principal Versus Net as an Agent, the Company recognizes\nas revenues the fees it receives from its advertisers.This revenue is reported gross primarily because the\nCompany is the primary obligor to its advertisers.\n\nThe Company generates fees from search services through a variety of contractual arrangements, which\ninclude per-query search fees and search service hosting fees.Revenues from set up and support fees and search\nservice hosting fees are recognized on a straight-line basis over the term of the contract, which is the expected\nperiod during which these services will be provided.The Company's policy is to recognize revenues from per\nquery search fees in the period queries are made and results are delivered.\n\nThe Company provides search services pursuant to certain AdSense agreements.", "pageIdentifier": "85" }, { "content": "On Google Print pages, we provide links to book sellers that may\noffer the full versions of these publications for sale, and we show content-targeted ads that are served through\nthe Google AdSense program.Google Desktop Search.Google Desktop Search enables our users to perform a full text search on the\ncontents of their own computer, including email, files, instant messenger chats and web browser history.Users\ncan use this service to view web pages they have visited even when they are not online.Google Alerts.Google Alerts are email updates of the latest relevant Google results (web, news, etc.) based\non the user's choice of query or topic.Typical uses include monitoring a developing news story, keeping current\non a competitor or industry, getting the latest on a celebrity or event, or keeping tabs on a favorite sports team.Google Labs.Google Labs is our playground for our engineers and for adventurous Google users.On Google\nLabs, we post product prototypes and solicit feedback on how the technology could be used or improved.Current Google Labs examples include:Google Personalized Search—provides customized search results based on an individual user's interests.Froogle Wireless—gives people the ability to search for product information from their mobile phones\nand other wireless devices.", "pageIdentifier": "17" } ] } ] } } }
Receber citações
As citações, quando especificadas, são números colocados em linha em um resumo da pesquisa. Esses números indicam de quais resultados de pesquisa frases específicas no resumo foram retiradas.
Para receber citações, siga estas etapas:
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique"includeCitations": true. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.No exemplo a seguir,
summarySpecindica que você quer um resumo da pesquisa, que ele seja gerado com base nos três principais resultados da pesquisa e que as citações sejam incluídas no resumo."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "includeCitations": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: o número de principais resultados para gerar o resumo da pesquisa. Se o número de resultados retornados for menor quesummaryResultCount, o resumo será gerado com base em todos os resultados. O valor máximo é5.includeCitations: um booleano que especifica se as citações serão retornadas.maxExtractiveAnswerCount: o número de respostas extraídas a serem retornadas para cada resultado da pesquisa. O valor padrão é 0 e o máximo é 1.
Receba o resumo, com citações, da resposta da pesquisa. Uma propriedade
summaryé retornada em cada resposta.Confira um exemplo de resumo, com citações e metadados de citação, retornado no final de uma resposta de pesquisa:
"summary": { "summaryText": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse [1]. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform [2, 3].", "summaryWithMetadata": { "summary": "BigQuery is Google Cloud's fully managed and completely serverless enterprise data warehouse. BigQuery supports all data types, works across clouds, and has built-in machine learning and business intelligence, all within a unified platform.", "citationMetadata": { "citations": [ { "startIndex": "0", "endIndex": "101", "sources": [ { "uri": "gs://example-dataset/html/6344007140738632642.html", "title": "About BigQuery", "id": "b6344007140738632642", "referenceIndex": "0" }, { "uri": "gs://example-dataset/html/1365490014946172719.html", "title": "Google Cloud article", "id": "b1365490014946172719", "referenceIndex": "1" }, { "uri": "gs://example-dataset/html/2687910668117268120.html", "title": "BigQuery document", "id": "a2687910668117268120", "referenceIndex": "2" } ] }, { "startIndex": "103", "endIndex": "230", "sources": [ { "referenceIndex": "0" }, { "referenceIndex": "1" }, { "referenceIndex": "2", } ] } ] }, "references": [ { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b6344007140738632642", "uri": "https://example.com/bigqueryA" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/b1365490014946172719", "uri": "https://example.com/bigqueryB" }, { "title": "Sports in the United States", "docName": "projects/123/locations/global/collections/default_collection/dataStores/ds-123/branches/0/documents/a268791066811726812", "uri": "https://example.com/bigqueryC" } ] } }summaryText: o resumo da pesquisa, com números de citação. Os números das citações se referem aos resultados da pesquisa retornados e são indexados de 1 em diante. Por exemplo,[1]significa que a frase é atribuída ao primeiro resultado da pesquisa.[2, 3]significa que a frase é atribuída ao segundo e ao terceiro resultados da pesquisa.citations: para cada frase no resumo que tem uma citação, lista os metadados dessa citação.startIndex: indica o início da frase, medido em bytes Unicode.endIndex: indica o fim da frase, medido em bytes Unicode.sources: lista oreferenceIndexde cada fonte incluída na citação da frase.referenceIndexé o número de índice atribuído a uma fonte. OreferenceIndexda primeira fonte nem sempre é retornado explicitamente na resposta. ComoreferenceIndexé indexado em 0, a primeira fonte sempre tem umreferenceIndexde 0.references: lista os metadados de cada referência citada no resumo. Os metadados incluemtitle,docNameeuri.
Ignorar consultas adversárias
Consultas adversárias incluem comentários negativos ou são projetadas para gerar resultados não seguros e que violam a política. Você pode especificar que nenhum resumo de pesquisa seja retornado para consultas adversárias. Quando uma consulta adversária é ignorada, a propriedade
summaryText contém texto padrão indicando que nenhum resumo da pesquisa
foi retornado. Os documentos de pesquisa são retornados para consultas adversárias, mesmo que os resumos de pesquisa não sejam.
Para especificar que nenhum resumo de pesquisa deve ser retornado para consultas adversárias, siga estas etapas:
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique"ignoreAdversarialQuery": true. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.No exemplo a seguir,
summarySpecindica que você quer um resumo da pesquisa, que ele deve ser gerado com base nos três principais resultados da pesquisa, mas que nenhum resumo deve ser retornado para consultas adversárias."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreAdversarialQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: o número de principais resultados para gerar o resumo da pesquisa. Se o número de resultados retornados for menor quesummaryResultCount, o resumo será gerado com base em todos os resultados. O valor máximo é5.ignoreAdversarialQuery: um booleano que especifica que nenhum resumo de pesquisa deve ser retornado para consultas adversárias.maxExtractiveAnswerCount: o número de respostas extraídas a serem retornadas para cada resultado da pesquisa. O valor padrão é 0 e o máximo é 1.
Consulte a propriedade
summaryretornada para uma solicitação de pesquisa adversária.Veja um exemplo:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "ADVERSARIAL_QUERY_IGNORED" ] }summaryText: texto padrão indicando que nenhum resumo da pesquisa foi retornado.summarySkippedReasons: uma enumeração com valores para os motivos de resumo ignorado.
Ignorar consultas que não buscam um resumo
Consultas que não buscam resumos retornam resultados que não são adequados para resumo. Por exemplo, "por que o céu é azul" e "quem é o melhor jogador de futebol do mundo?" são consultas que buscam um resumo, mas "aeroporto de São Francisco" e "copa do mundo 2026" não são. Provavelmente são consultas de navegação. Você pode especificar que nenhum resumo de pesquisa seja retornado para consultas que não buscam resumos. Os documentos de pesquisa são retornados para consultas que não buscam resumos, mesmo que os resumos de pesquisa não sejam.
Para especificar que nenhum resumo de pesquisa deve ser retornado para consultas que não buscam resumos, siga estas etapas:
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique"ignoreNonSummarySeekingQuery": true. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.No exemplo a seguir,
summarySpecindica que você quer um resumo da pesquisa, que deve ser gerado com base nos três principais resultados da pesquisa, mas que nenhum resumo deve ser retornado para consultas que não buscam um resumo."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "ignoreNonSummarySeekingQuery": true }, "extractiveContentSpec": { "maxExtractiveAnswerCount" : 1} }summaryResultCount: o número de principais resultados para gerar o resumo da pesquisa. Se o número de resultados retornados for menor quesummaryResultCount, o resumo será gerado com base em todos os resultados. O valor máximo é5.ignoreNonSummarySeekingQuery: um booleano que especifica que nenhum resumo de pesquisa deve ser retornado para consultas que não buscam resumos.maxExtractiveAnswerCount: o número de respostas extraídas a serem retornadas para cada resultado da pesquisa. O valor padrão é 0 e o máximo é 1.
Consulte a propriedade
summaryretornada para uma solicitação de pesquisa que não busca um resumo.Veja um exemplo:
"summary": { "summaryText": "We do not have a summary for your query. Here are some search results.", "summarySkippedReasons": [ "NON_SUMMARY_SEEKING_QUERY_IGNORED" ] }summaryText: texto padrão indicando que nenhum resumo da pesquisa foi retornado.summarySkippedReasons: uma enumeração com valores para os motivos de resumo ignorado.
Receba resumos personalizados
Você pode receber resumos personalizados fornecendo instruções em linguagem natural.
Esse recurso está disponível para o widget de pesquisa usando o console e para
a API inserindo instruções no campo modelPromptSpec.preamble.
Você pode pedir personalizações como tamanho, nível de detalhes, estilo de saída (como "simples"), idioma da saída, foco da resposta e formato (como tabelas, marcadores e XML).
Por exemplo, para a consulta What are the benefits of bigquery?, você pode
inserir instruções de personalização como nos exemplos a seguir:
Exemplo de instrução:
please show the answer format in an ordered listExemplo de resposta:
The benefits of BigQuery are: 1. Increased business productivity 2. IT staff productivity 3. Reduced infrastructure costs 4. Loading and exporting data are freeExemplo de instrução:
give a very detailed answerExemplo de resposta:
BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse that enables businesses to analyze all their data very quickly. It is a fully managed service that takes care of provisioning, scaling, and managing the underlying infrastructure, so you can focus on analyzing your data. BigQuery is also integrated with other Google Cloud services, such as Google Kubernetes Engine, Cloud Data Fusion, and Cloud Dataproc, making it easy to build and deploy data pipelines. Here are some of the benefits of using BigQuery: * **Fast and scalable:** BigQuery can process petabytes of data very quickly, and it can scale to handle even the most demanding workloads. * **Cost-effective:** BigQuery is a very cost-effective way to store and analyze data. You only pay for the data that you use, and there are no upfront costs or commitments. * **Secure:** BigQuery is a secure platform that meets the needs of even the most security-conscious organizations. * **Easy to use:** BigQuery is easy to use, even for non-technical users. It has a simple and intuitive user interface, and it supports a variety of data sources. * **Integrated with other Google Cloud services:** BigQuery is integrated with other Google Cloud services, making it easy to build and deploy data pipelines. If you are looking for a fast, scalable, and cost-effective way to analyze your data, then BigQuery is a great option.
Práticas recomendadas para resumos personalizados
Se você planeja usar esse recurso, faça o seguinte:
- Peça apenas uma personalização por vez. Não combine personalizações, por exemplo, pedindo uma tabela HTML em francês.
- O Google recomenda que você imponha limites às personalizações que os usuários finais podem solicitar. Por exemplo, ofereça um seletor com um conjunto de personalizações predefinidas.
Personalizar resumos
É possível receber resumos personalizados apenas para o widget de pesquisa usando o console ou, para qualquer solicitação de pesquisa, usando a API.
Para receber um resumo personalizado, siga estas etapas:
Console
No console Google Cloud , acesse a página Aplicativos de IA.
Clique no nome do app que você quer editar.
Acesse Configurações > Interface.
Verifique se o Tipo de pesquisa do widget está definido como Pesquisar com uma resposta ou Pesquisar com acompanhamentos. Esse recurso não está disponível se a opção Pesquisa estiver selecionada.
Ative a opção Ativar a personalização de resumo.
Para inserir instruções de resumo, faça o seguinte:
- Insira instruções de formato livre: digite suas próprias instruções em linguagem natural no campo Preâmbulo.
- Usar instruções de modelo: clique em Substituir por um modelo e selecione uma das instruções predefinidas. O modelo predefinido aparece no campo Preâmbulo depois que você o seleciona.
Teste a geração de resumo personalizada para seu app pesquisando no painel Prévia.
Para redefinir o conjunto de instruções salvo por último, clique em Redefinir preâmbulo.
Para salvar as configurações no widget, clique em Salvar e publicar.
REST
Envie uma solicitação de pesquisa que inclua
contentSearchSpec.summarySpece especifique a instrução de personalização emmodelPromptSpec.preamble. Para mais informações sobre como enviar uma solicitação de pesquisa, consulte Receber resultados da pesquisa.No exemplo a seguir,
summarySpecindica que você quer um resumo da pesquisa, que deve ser gerado com base nos três principais resultados e personalizado como se estivesse sendo explicado para uma criança de 10 anos."contentSearchSpec": { "summarySpec": { "summaryResultCount": 3, "modelPromptSpec": { "preamble": "explain like you would to a ten year old" } } }summaryResultCount: o número de principais resultados para gerar o resumo da pesquisa. Se o número de resultados retornados for menor quesummaryResultCount, o resumo será gerado com base em todos os resultados. O valor máximo é5.preamble: a instrução para personalização.
Receba o resumo personalizado da resposta da pesquisa.
Confira um exemplo de resumo personalizado que é retornado:
"summary": { "summaryText": "BigQuery is a serverless data warehouse that helps you analyze all your data very quickly. It's very easy to use and you don't need to worry about managing servers or infrastructure. BigQuery is also very scalable, so you can analyze large datasets without any problems." }summaryText: o resumo da pesquisa personalizada.
Especificar o modelo de resumo
Você pode especificar o modelo que quer usar para gerar resumos.
É possível especificar stable, preview ou uma versão específica do modelo por nome.
Para conferir as versões de modelo disponíveis, consulte Versões e ciclo de vida do modelo de geração de respostas.
Para mudar a versão do modelo:
Envie uma solicitação de pesquisa que inclua
ContentSearchSpec.SummarySpec.ModelSpecpara especificar a versão do modelo."contentSearchSpec": { "summarySpec": { "modelSpec": { "version": "MODEL_VERSION" } } }MODEL_VERSION: especifica qual modelo usar para gerar resumos. Os valores aceitos são:
stable: string. Especificação padrão quando nenhum valor é especificado.stableaponta para uma versão de modelo GA ajustada para geração de respostas. O modelostablemuda à medida que novas versões de disponibilidade geral são lançadas e as anteriores são desativadas. Para conferir a versão atualizada que ostableaponta, consulte Versões e ciclo de vida do modelo de geração de respostas.preview: string. Opreviewaponta para o modelo mais recente do Gemini para perguntas e respostas. Para mais informações sobre o Gemini, consulte Visão geral dos modelos.- Para especificar uma versão de modelo, insira o nome dela, como
gemini-1.5-flash-002/answer_gen/v1. Para ver as versões compatíveis, consulte Versões e ciclo de vida do modelo de geração de respostas.
Por exemplo, a solicitação de pesquisa a seguir especifica preview como a versão do modelo:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://discoveryengine.googleapis.com/v1/projects/exampleproject/locations/global/collections/default_collection/dataStores/exampledatastore/servingConfigs/default_search:search" \
-d '{
"query": "what is bigquery",
"contentSearchSpec": {
"summarySpec": {
"modelSpec": {
"version": "preview"
}
}
}
}'
Limitações dos resumos gerados pela pesquisa
Você pode encontrar as seguintes limitações ao usar resumos de pesquisa:
Como os LLMs são usados para gerar resumos e citações de pesquisa, as limitações deles também se aplicam aos resumos da Vertex AI para Pesquisa.
Para informações gerais sobre essas limitações de LLM, consulte Limitações da API PaLM na documentação da Vertex AI.
Consultas de pesquisa que exigem raciocínio lógico ou analítico complexo ou compreensão do mundo podem levar a resumos que contêm informações incorretas (alucinações) ou que não estão presentes nos dados não estruturados ou do site.
Algumas declarações no resumo da pesquisa podem não ter uma citação:
Se o sistema determinar que uma declaração não precisa de embasamento, ela não vai incluir uma citação. Frases como "Aqui está o que encontrei" ou "Há muitos métodos que você pode seguir" não têm citações.
A falta de citações também pode indicar que não foi encontrada uma referência válida. Fatos sem citações podem não ser confiáveis.
Em casos raros, as citações podem ser atribuídas incorretamente a uma declaração.
Documentos complexos podem ser analisados incorretamente pelo LLM. Nesse caso, o resumo pode estar incompleto ou incorreto.
Como as instruções de personalização estão em linguagem natural, não é possível garantir a adesão a elas em todas as solicitações.