Document AI genera metriche di valutazione, come precisione e richiamo, per aiutarti a determinare le prestazioni predittive dei tuoi processori.
Queste metriche di valutazione vengono generate confrontando le entità restituite dal processore (le previsioni) con le annotazioni nei documenti di test. Se il processore non ha un set di test, devi prima creare un set di dati e etichettare i documenti di test.
Esegui una valutazione
Una valutazione viene eseguita automaticamente ogni volta che addestri o esegui l'upgrade di una versione del processore.
Puoi anche eseguire manualmente una valutazione. Questo è necessario per generare metriche aggiornate dopo aver modificato il set di test o se stai valutando una versione del processore preaddestrato.
UI web
Nella console Google Cloud , vai alla pagina Processori e scegli il tuo processore.
Nella scheda Valuta e testa, seleziona la versione del processore da valutare e poi fai clic su Esegui nuova valutazione.
Una volta completata, la pagina contiene le metriche di valutazione per tutte le etichette e per ogni singola etichetta.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Ottenere i risultati di una valutazione
UI web
Nella console Google Cloud , vai alla pagina Processori e scegli il tuo processore.
Nella scheda Valuta e verifica, seleziona la versione del processore per visualizzare la valutazione.
Una volta completata, la pagina contiene le metriche di valutazione per tutte le etichette e per ogni singola etichetta.
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Elenco di tutte le valutazioni per una versione del processore
Python
Per saperne di più, consulta la documentazione di riferimento dell'API Document AI Python.
Per eseguire l'autenticazione in Document AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
Metriche di valutazione per tutte le etichette
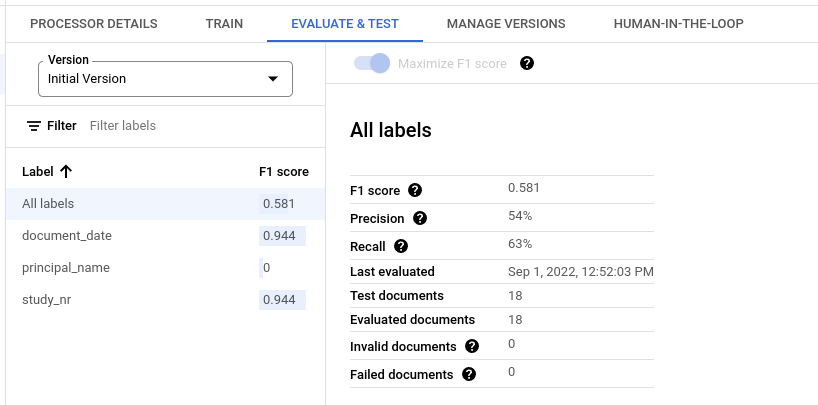
Le metriche per Tutte le etichette vengono calcolate in base al numero di veri positivi, falsi positivi e falsi negativi nel set di dati per tutte le etichette e, pertanto, sono ponderate in base al numero di volte in cui ogni etichetta viene visualizzata nel set di dati. Per le definizioni di questi termini, consulta Metriche di valutazione per le singole etichette.
Precisione:la proporzione di previsioni che corrispondono alle annotazioni nel set di test. Definita come
True Positives / (True Positives + False Positives)Richiamo:la proporzione di annotazioni nel set di test che sono previste correttamente. Definita come
True Positives / (True Positives + False Negatives)Punteggio F1:la media armonica di precisione e richiamo, che combina precisione e richiamo in un'unica metrica, assegnando lo stesso peso a entrambe. Definita come
2 * (Precision * Recall) / (Precision + Recall)
Metriche di valutazione per singole etichette
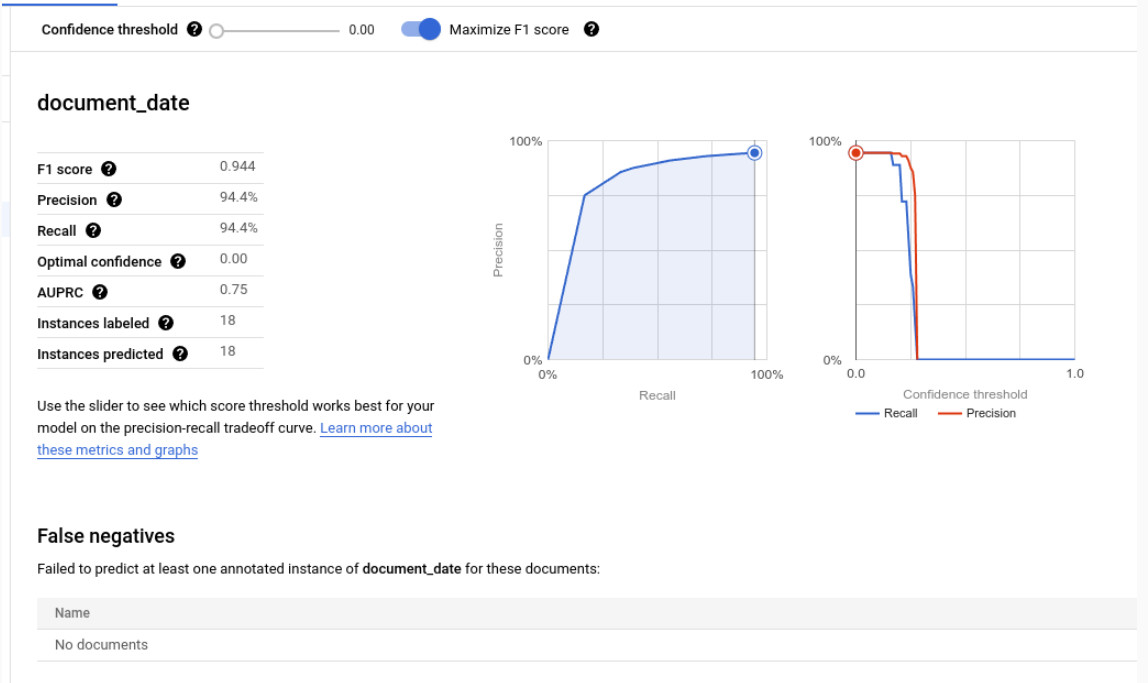
Veri positivi:le entità previste che corrispondono a un'annotazione nel documento di test. Per saperne di più, vedi Comportamento di corrispondenza.
Falsi positivi:le entità previste che non corrispondono ad alcuna annotazione nel documento di test.
Falsi negativi:le annotazioni nel documento di test che non corrispondono a nessuna delle entità previste.
- Falsi negativi (al di sotto della soglia): le annotazioni nel test documento che avrebbero corrisposto a un'entità prevista, ma ilvalore di affidabilitàa dell'entità prevista è inferiore alla soglia di confidenza specificata.
Soglia di confidenza
La logica di valutazione ignora tutte le previsioni con un livello di confidenza inferiore alla soglia di confidenza specificata, anche se la previsione è corretta. Document AI fornisce un elenco di falsi negativi (sotto la soglia), ovvero le annotazioni che avrebbero una corrispondenza se la soglia di affidabilità fosse impostata su un valore inferiore.
Document AI calcola automaticamente la soglia ottimale, che massimizza il punteggio F1 e, per impostazione predefinita, imposta la soglia di confidenza su questo valore ottimale.
Puoi scegliere la soglia di confidenza che preferisci spostando la barra del cursore. In generale, una soglia di confidenza più elevata comporta:
- maggiore precisione, perché le previsioni hanno più probabilità di essere corrette.
- un richiamo inferiore, perché ci sono meno previsioni.
Entità tabulari
Le metriche per un'etichetta padre non vengono calcolate facendo la media diretta delle metriche figlio, ma applicando la soglia di confidenza del padre a tutte le etichette figlio e aggregando i risultati.
La soglia ottimale per il genitore è il valore della soglia di confidenza che, se applicato a tutti i figli, produce il punteggio F1 massimo per il genitore.
Comportamento di corrispondenza
Un'entità prevista corrisponde a un'annotazione se:
- il tipo di entità prevista
(
entity.type) corrisponde al nome dell'etichetta dell'annotazione - il valore dell'entità prevista
(
entity.mention_textoentity.normalized_value.text) corrisponde al valore di testo dell'annotazione, soggetto a corrispondenza fuzzy se è attivata.
Tieni presente che per la corrispondenza vengono utilizzati solo il tipo e il valore di testo. Non vengono utilizzate altre informazioni, come ancore di testo e riquadri di selezione (ad eccezione delle entità tabellari descritte di seguito).
Etichette a singola o più occorrenze
Le etichette a singola occorrenza hanno un valore per documento (ad esempio, l'ID fattura), anche se questo valore viene annotato più volte nello stesso documento (ad esempio, l'ID fattura viene visualizzato in ogni pagina dello stesso documento). Anche se le annotazioni multiple hanno testi diversi, vengono considerate uguali. In altre parole, se un'entità prevista corrisponde a una delle annotazioni, viene conteggiata come corrispondenza. Le annotazioni aggiuntive sono considerate menzioni duplicate e non contribuiscono al conteggio di veri positivi, falsi positivi o falsi negativi.
Le etichette a più occorrenze possono avere valori diversi. Pertanto, ogni entità e annotazione prevista viene considerata e abbinata separatamente. Se un documento contiene N annotazioni per un'etichetta a più occorrenze, possono esserci N corrispondenze con le entità previste. Ogni entità e annotazione previste vengono conteggiate in modo indipendente come vero positivo, falso positivo o falso negativo.
Corrispondenza parziale
Il pulsante di attivazione/disattivazione Corrispondenza fuzzy ti consente di rendere più o meno rigide alcune regole di corrispondenza per diminuire o aumentare il numero di corrispondenze.
Ad esempio, senza la corrispondenza approssimativa, la stringa ABC non corrisponde a abc a causa
della capitalizzazione. ma con la corrispondenza parziale, corrispondono.
Quando la corrispondenza approssimativa è attivata, ecco le modifiche alla regola:
Normalizzazione degli spazi vuoti:rimuove gli spazi vuoti iniziali e finali e comprime gli spazi vuoti intermedi consecutivi (incluse le nuove righe) in singoli spazi.
Rimozione della punteggiatura iniziale/finale:rimuove i seguenti caratteri di punteggiatura iniziali/finali
!,.:;-"?|.Corrispondenza senza distinzione tra maiuscole e minuscole:converte tutti i caratteri in minuscolo.
Normalizzazione della valuta:per le etichette con il tipo di dati
money, rimuovi i simboli di valuta iniziali e finali.
Entità tabulari
Le entità e le annotazioni principali non hanno valori di testo e vengono abbinate in base ai rettangoli di selezione combinati dei relativi elementi secondari. Se è presente un solo genitore previsto e un solo genitore annotato, questi vengono abbinati automaticamente, indipendentemente dai rettangoli di selezione.
Una volta abbinati i genitori, i figli vengono abbinati come se fossero entità non tabellari. Se i genitori non vengono abbinati, Document AI non tenterà di abbinare i loro figli. Ciò significa che le entità secondarie possono essere considerate errate, anche con gli stessi contenuti di testo, se le entità principali non corrispondono.
Le entità padre / figlio sono una funzionalità di anteprima e sono supportate solo per le tabelle con un livello di nidificazione.
Esportare le metriche di valutazione
Nella console Google Cloud , vai alla pagina Processori e scegli il tuo processore.
Nella scheda Valuta e testa, fai clic su Scarica metriche per scaricare le metriche di valutazione come file JSON.