Per addestrare, eseguire l'ottimizzazione dell'addestramento o valutare una versione del processore è necessario un set di dati etichettato dei documenti.
Questa pagina descrive come creare un set di dati, importare documenti e definire uno schema. Per etichettare i documenti importati, consulta Etichettare i documenti.
Questa pagina presuppone che tu abbia già creato un processore che supporti l'addestramento, l'ottimizzazione dell'addestramento o la valutazione. Se il tuo processore è supportato, vedrai la scheda Addestra nella console Google Cloud .
Opzioni di archiviazione dei set di dati
Puoi scegliere tra due opzioni per salvare il set di dati:
- Gestita da Google
- Cloud Storage personalizzato
A meno che tu non abbia requisiti speciali (ad esempio per conservare i documenti in un insieme di cartelle abilitate a CMEK), ti consigliamo l'opzione di archiviazione più semplice gestita da Google. Una volta creata, l'opzione di archiviazione del set di dati non può essere modificata per il processore.
La cartella o la sottocartella per una posizione Cloud Storage personalizzata deve iniziare vuota e deve essere trattata come di sola lettura. Qualsiasi modifica manuale ai suoi contenuti potrebbe rendere il set di dati inutilizzabile, con il rischio di perderlo. L'opzione di spazio di archiviazione gestito da Google non presenta questo rischio.
Segui questi passaggi per eseguire il provisioning della posizione di archiviazione.
Spazio di archiviazione gestito da Google (consigliato)
Visualizza le opzioni avanzate durante la creazione di un nuovo processore.
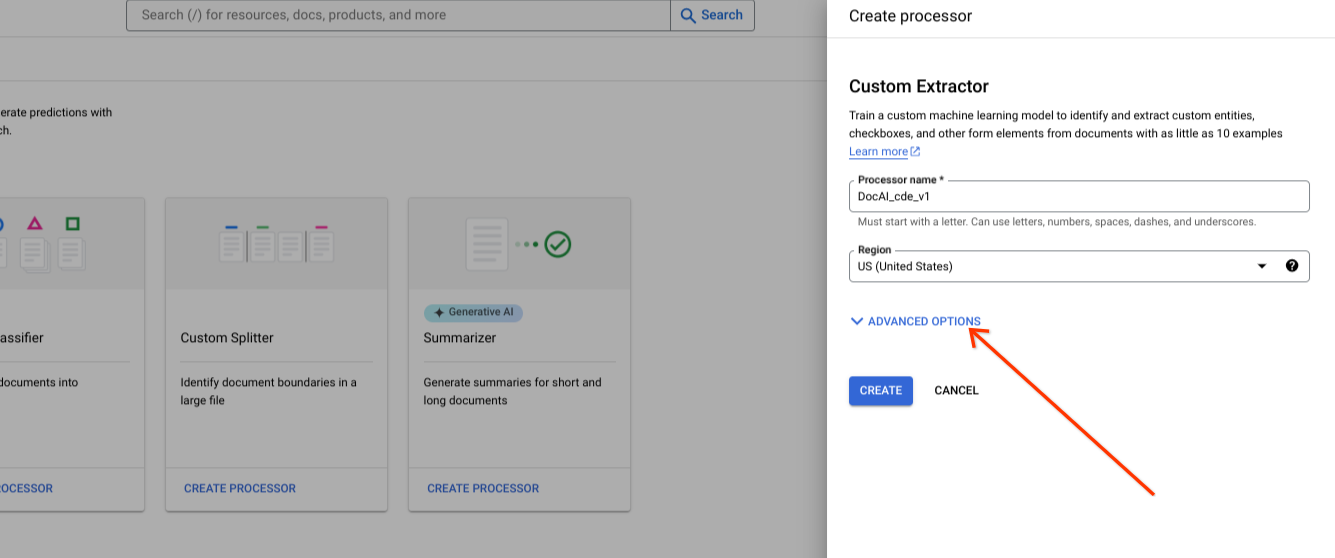
Mantieni l'opzione predefinita del gruppo di pulsanti di opzione per lo spazio di archiviazione gestito da Google.
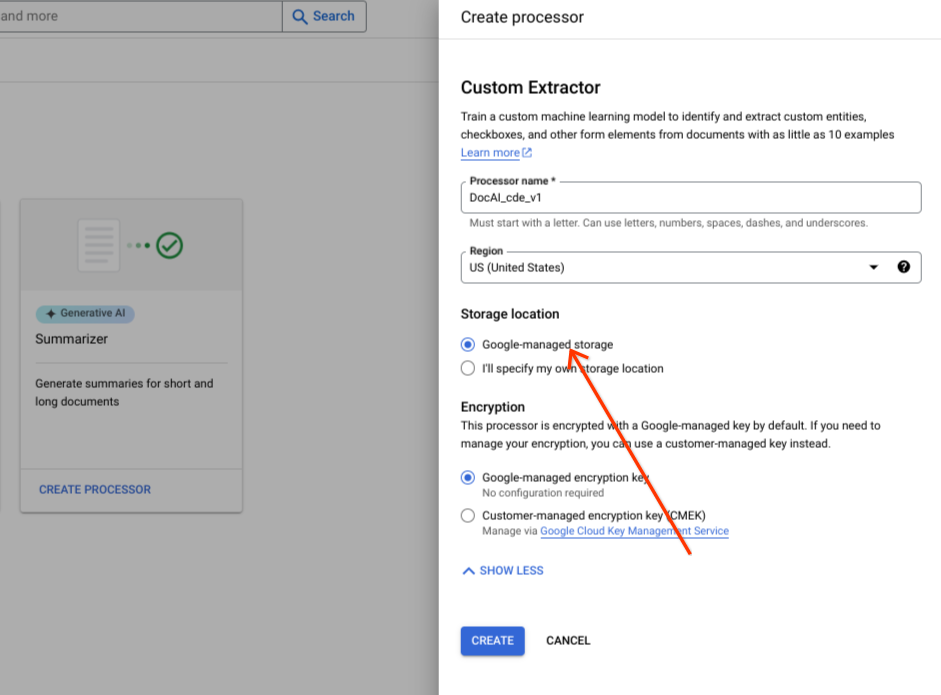
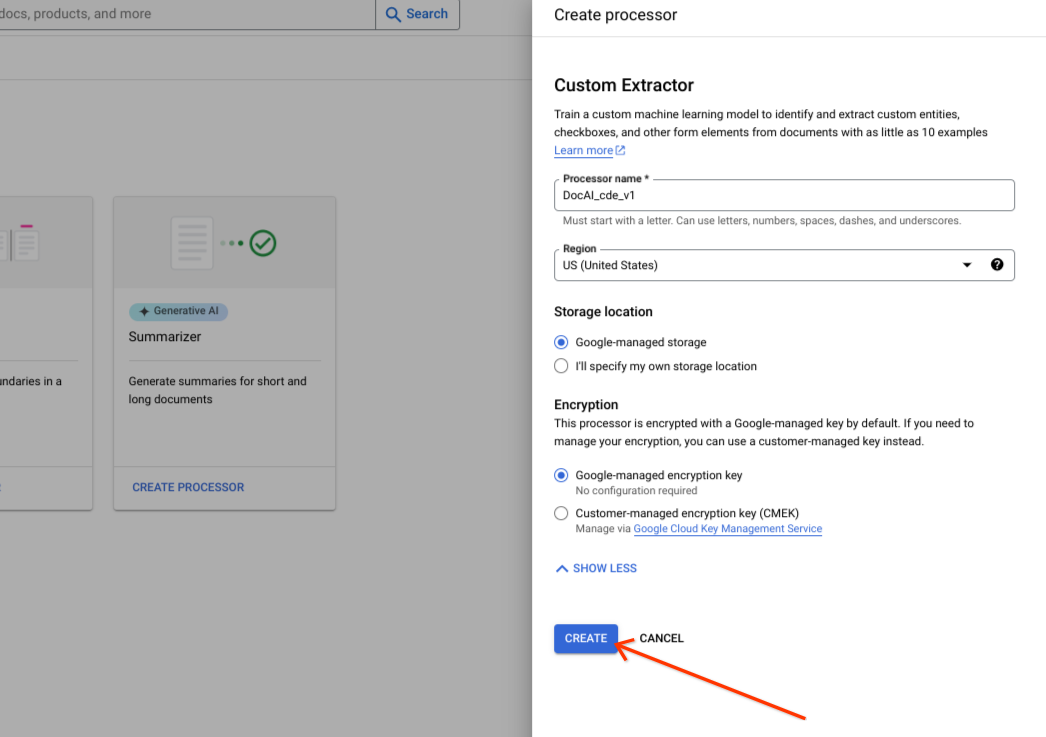
Seleziona Crea.
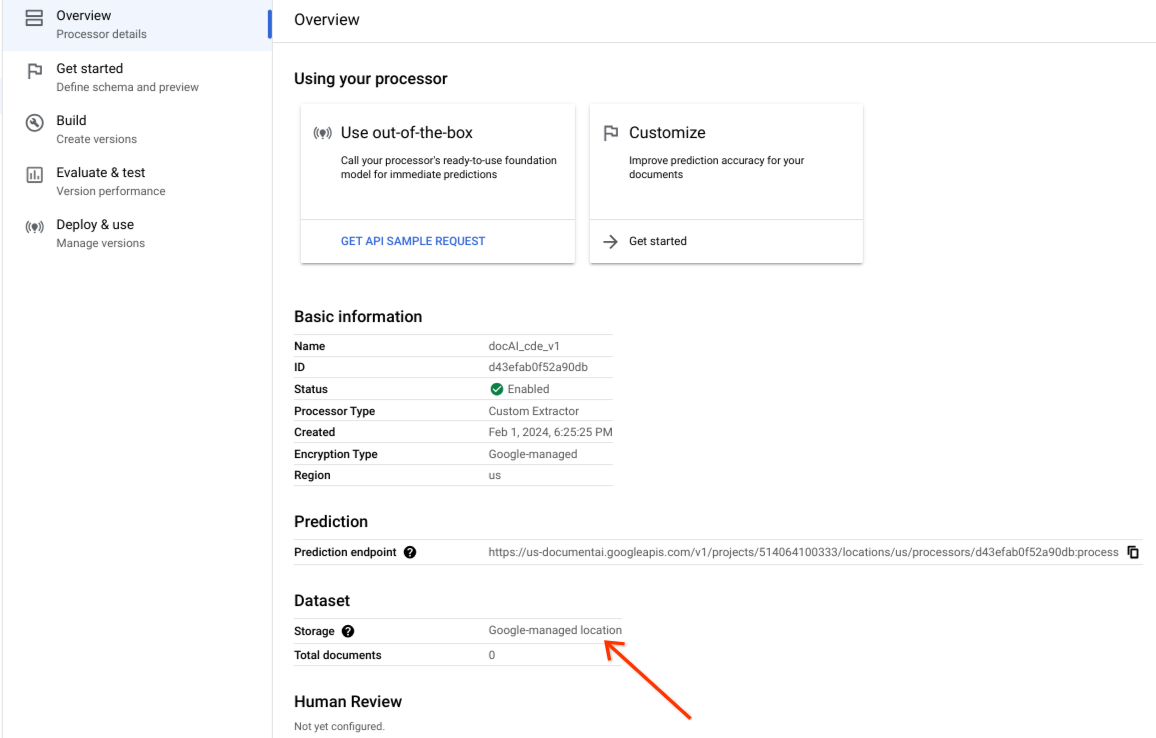
Verifica che il set di dati sia stato creato correttamente e che la posizione del set di dati sia gestita da Google.
Opzione di spazio di archiviazione personalizzato
Attiva o disattiva le opzioni avanzate.
Seleziona Specificherò personalmente la località di archiviazione.
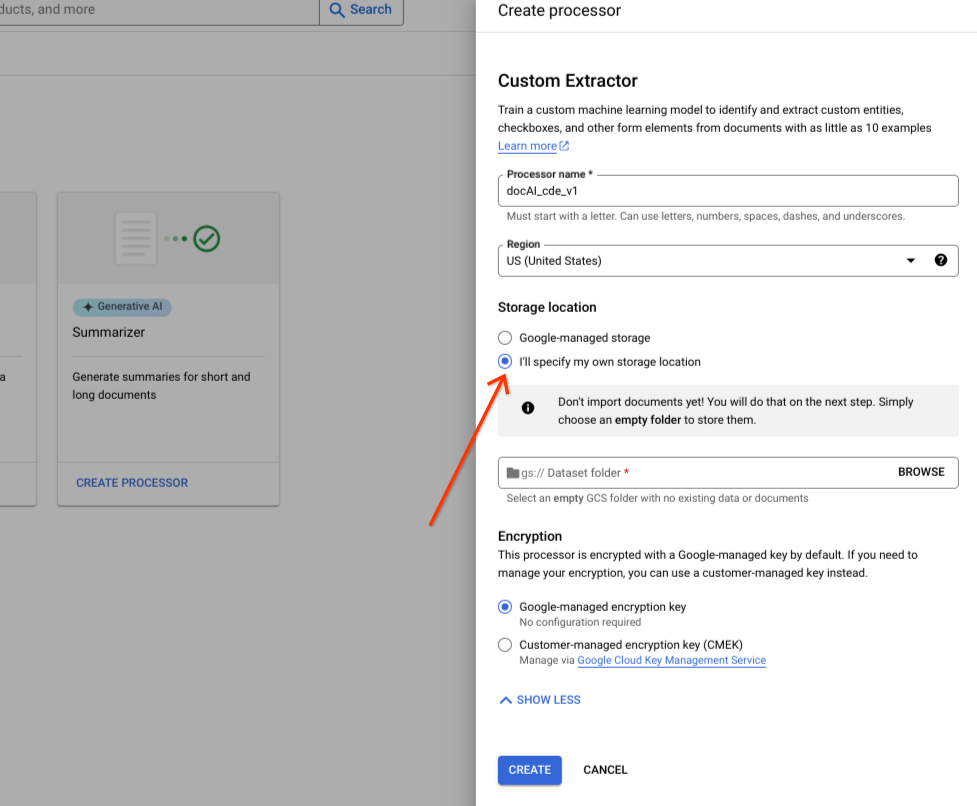
Scegli una cartella Cloud Storage dal componente di input.
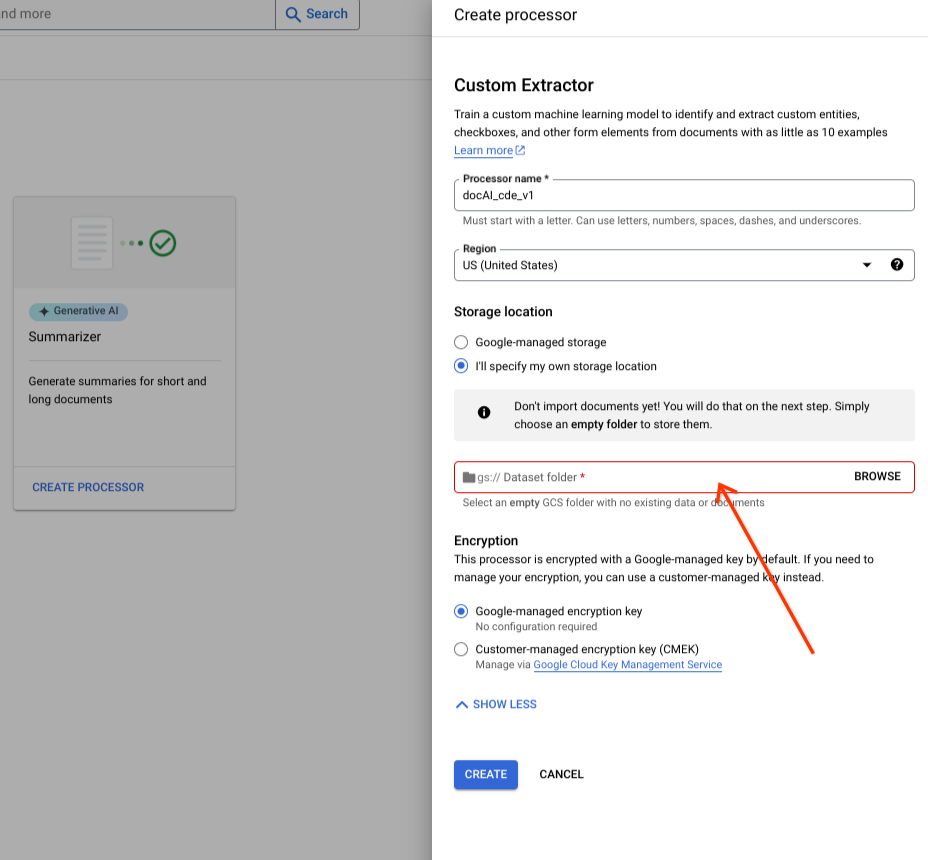
Seleziona Crea.
Operazioni API Dataset
Questo esempio mostra come utilizzare il metodo
processors.updateDataset
per creare un set di dati. Una risorsa del set di dati è una risorsa singleton in un processore,
il che significa che non esiste un RPC per la creazione di risorse. In alternativa, puoi utilizzare la
RPC updateDataset per impostare le preferenze. Document AI offre un'opzione per archiviare i documenti del set di dati in un bucket Cloud Storage fornito da te
o per farli gestire automaticamente da Google.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Bucket fornito
Segui i passaggi successivi per creare una richiesta di set di dati con un bucket Cloud Storage che fornisci.
Metodo HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON della richiesta:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Gestita da Google
Se vuoi creare il set di dati gestito da Google, aggiorna le seguenti informazioni:
Metodo HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON della richiesta:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Per inviare la richiesta, puoi utilizzare Curl:
Salva il corpo della richiesta in un file denominato request.json. Esegui questo comando:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Importa documenti
Un set di dati appena creato è vuoto. Per aggiungere documenti, seleziona Importa documenti e seleziona una o più cartelle Cloud Storage che contengono i documenti che vuoi aggiungere al tuo set di dati.
Se Cloud Storage si trova in un progetto Google Cloud diverso, assicurati di concedere l'accesso in modo che Document AI possa leggere i file da quella posizione. In particolare, devi concedere il ruolo
Visualizzatore oggetti Storage all'agente di servizio principale di
Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Per saperne di più, consulta Service agent.
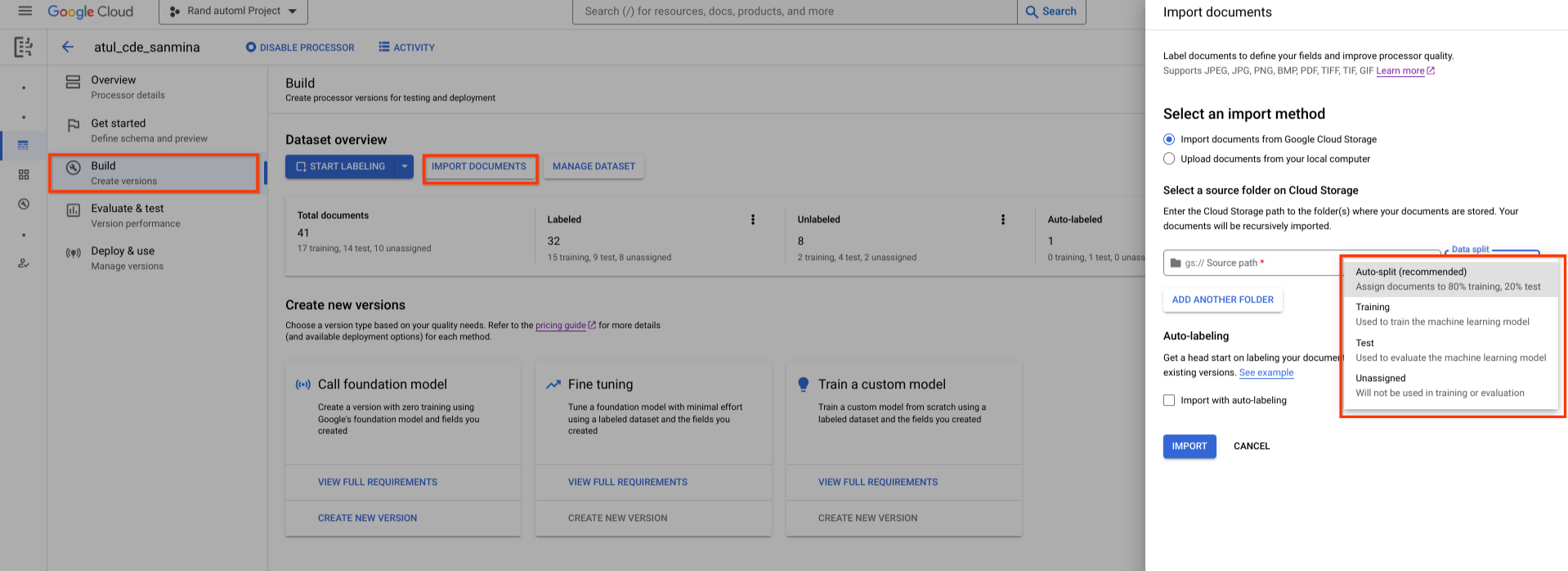
Poi, scegli una delle seguenti opzioni di assegnazione:
- Addestramento: assegna al set di addestramento.
- Test: assegna al set di test.
- Suddivisione automatica: esegue lo shuffling casuale dei documenti nei set di addestramento e test.
- Non assegnato: non viene utilizzato per l'addestramento o la valutazione. Puoi assegnare manualmente in un secondo momento.
Puoi sempre modificare le assegnazioni in un secondo momento.
Quando selezioni Importa, Document AI importa tutti i
tipi di file supportati, nonché i file JSON
Document nel
set di dati. Per i file JSON Document, Document AI importa il documento e converte il relativo entities in istanze di etichette.
Document AI non modifica la cartella di importazione né legge la cartella dopo che l'importazione è stata completata.
Seleziona Attività nella parte superiore della pagina per aprire il riquadro Attività, che elenca i file importati correttamente e quelli che non sono stati importati.
Se hai già una versione esistente del processore, puoi selezionare la casella di controllo Importa con etichettatura automatica nella finestra di dialogo Importa documenti. I documenti vengono etichettati automaticamente utilizzando il processore precedente al momento dell'importazione. Non puoi eseguire l'addestramento o l'addestramento incrementale su documenti etichettati automaticamente né utilizzarli nel set di test senza contrassegnarli come etichettati. Dopo aver importato i documenti etichettati automaticamente, esamina e correggi manualmente i documenti etichettati automaticamente. Poi seleziona Salva per salvare le correzioni e contrassegnare il documento come etichettato. Puoi quindi assegnare i documenti in modo appropriato. Consulta la sezione Etichettatura automatica.
Importa documenti RPC
Questo esempio mostra come utilizzare il metodo dataset.importDocuments per importare documenti nel set di dati.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Set di dati di addestramento o di test
Se vuoi aggiungere documenti al set di dati di addestramento o di test:
Metodo HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON della richiesta:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Set di dati di addestramento e test
Se vuoi suddividere automaticamente i documenti tra il set di dati di addestramento e quello di test:
Metodo HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON della richiesta:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}RPC Delete documents
Questo esempio mostra come utilizzare il metodo dataset.batchDeleteDocuments per eliminare documenti dal set di dati.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Elimina documenti
Metodo HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsJSON della richiesta:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Assegnare documenti al set di addestramento o test
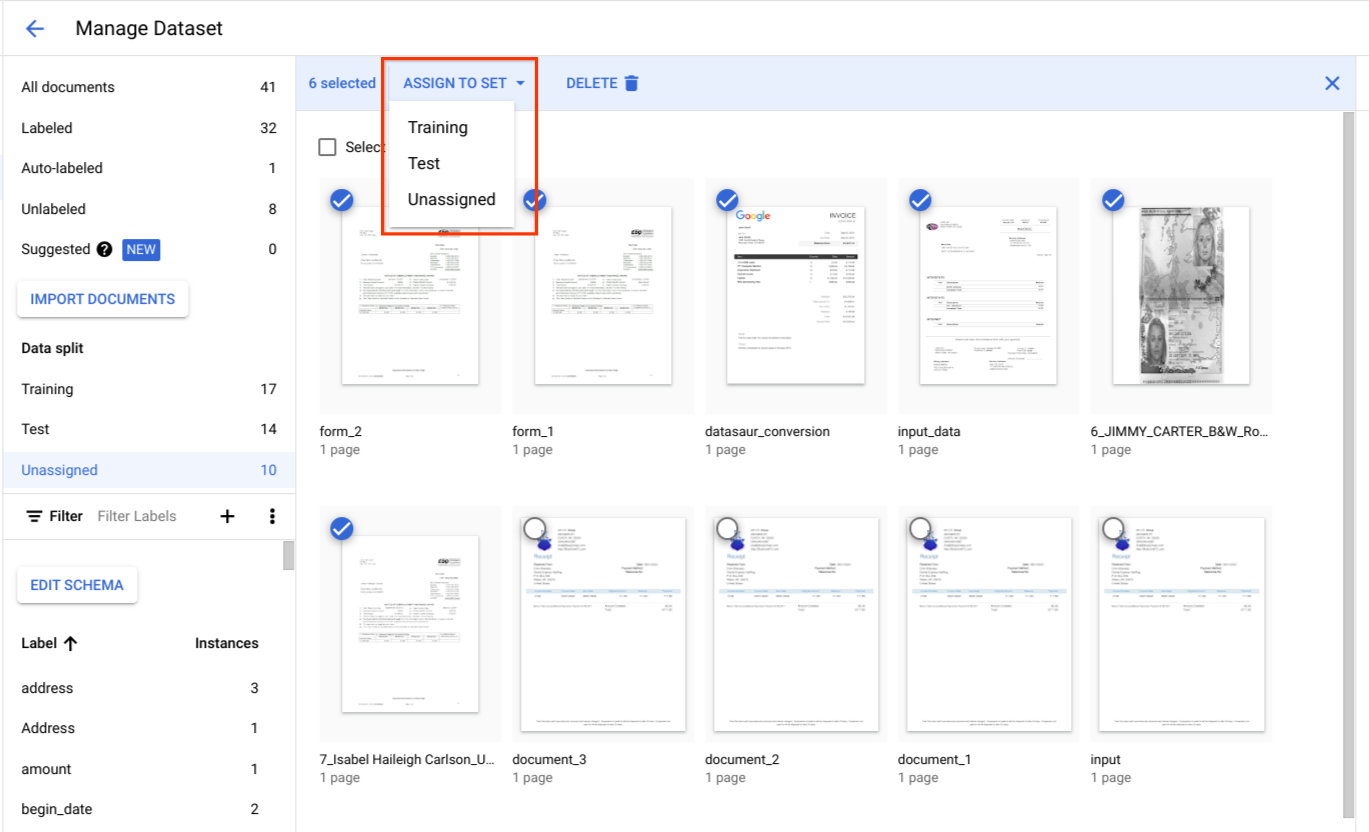
In Suddivisione dati, seleziona i documenti e assegnali al set di addestramento, al set di test o a Nessun set.
Best practice per il set di test
La qualità del set di test determina la qualità della valutazione.
Il set di test deve essere creato all'inizio del ciclo di sviluppo del processore e bloccato in modo da poter monitorare la qualità del processore nel tempo.
Per il set di test, consigliamo almeno 100 documenti per tipo di documento. È fondamentale assicurarsi che il set di test sia rappresentativo dei tipi di documenti che i clienti utilizzano per il modello in fase di sviluppo.
Il set di test deve essere rappresentativo del traffico di produzione in termini di frequenza. Ad esempio, se stai elaborando moduli W2 e prevedi che il 70% sia relativo all'anno 2020 e il 30% all'anno 2019, circa il 70% del set di test deve essere costituito da documenti W2 2020. Questa composizione del set di test garantisce che a ogni sottotipo di documento venga data l'importanza appropriata durante la valutazione del rendimento del processore. Inoltre, se estrai i nomi delle persone da moduli internazionali, assicurati che il set di test includa moduli di tutti i paesi target.
Best practice per il set di addestramento
I documenti già inclusi nel set di test non devono essere inclusi nel set di addestramento.
A differenza del set di test, il set di addestramento finale non deve essere rappresentativo dell'utilizzo da parte del cliente in termini di diversità o frequenza dei documenti. Alcune etichette sono più difficili da addestrare rispetto ad altre. Pertanto, potresti ottenere un rendimento migliore se inclini il set di addestramento verso queste etichette.
All'inizio, non esiste un modo semplice per capire quali etichette sono difficili. Devi iniziare con un piccolo set di addestramento iniziale campionato in modo casuale utilizzando lo stesso approccio descritto per il set di test. Questo set di addestramento iniziale deve contenere circa il 10% del numero totale di documenti che intendi annotare. Quindi, puoi valutare in modo iterativo la qualità del processore (cercando pattern di errore specifici) e aggiungere altri dati di addestramento.
Definisci lo schema del processore
Dopo aver creato un set di dati, puoi definire uno schema del processore prima o dopo aver importato i documenti.
schema del processore definisce le etichette, ad esempio nome e indirizzo, da estrarre dai documenti.
Seleziona Modifica schema e poi crea, modifica, attiva e disattiva le etichette in base alle tue esigenze.
Al termine, assicurati di selezionare Salva.
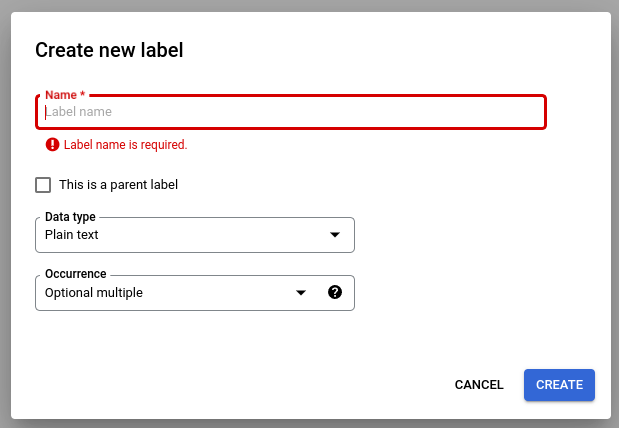
Note sulla gestione delle etichette dello schema:
Una volta creata un'etichetta dello schema, il nome non può essere modificato.
Un'etichetta dello schema può essere modificata o eliminata solo se non sono presenti versioni del processore addestrate. È possibile modificare solo il tipo di dati e il tipo di occorrenza.
La disattivazione di un'etichetta non influisce neanche sulla previsione. Quando invii una richiesta di elaborazione, la versione del processore estrae tutte le etichette attive al momento dell'addestramento.
Ottieni schema di dati
Questo esempio mostra come utilizzare il set di dati.
getDatasetSchema
per ottenere lo schema corrente. DatasetSchema è una risorsa singleton, che viene
creata automaticamente quando crei una risorsa del set di dati.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Ottieni schema di dati
Metodo HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Aggiorna lo schema del documento
Questo esempio mostra come utilizzare
dataset.updateDatasetSchema
per aggiornare lo schema corrente. Questo esempio mostra un comando per aggiornare lo schema del
set di dati in modo che abbia un'etichetta. Se vuoi aggiungere una nuova etichetta, non eliminare
o aggiornare quelle esistenti, puoi chiamare prima getDatasetSchema e apportare
le modifiche appropriate nella sua risposta.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Aggiorna schema
Metodo HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaJSON della richiesta:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Scegli gli attributi delle etichette
Tipo di dati
Plain text: un valore di stringa.Number: un numero intero o con rappresentazione in virgola mobile.Money: un importo di valore monetario. Quando etichetti, non includere il simbolo della valuta.- Quando l'entità viene estratta, viene normalizzata in
google.type.Money.
- Quando l'entità viene estratta, viene normalizzata in
Currency: un simbolo di valuta.Datetime: un valore di data o ora.- Quando l'entità viene estratta, viene
normalizzata nel formato di testo
ISO 8601.
- Quando l'entità viene estratta, viene
normalizzata nel formato di testo
Address: un indirizzo della sede.- Quando l'entità viene estratta, viene normalizzata e arricchita con EKG.
Checkbox: un valore booleanotrueofalse.Signature: un valore booleanotrueofalseinnormalized_value.signature_valueche indica se è presente una firma. Supporta i metodiderive.mention_text: un valore booleanoDetectedo""vuoto inhas_signedche indica se è presente una firma. Supporta i metodiderive.normalized_value.text: un valore booleanoDetectedo""vuoto inhas_signedche indica se è presente una firma. Supporta i metodiderive.normalized_value.boolean_valuenon è compilato.
Metodo
- Quando l'entità è
extracted, vengono compilati i campitextAnchor,type,mentionTextepageAnchor. - Quando l'entità è
derived, i valori derivati potrebbero non essere presenti nel testo del documento. Non sono compilati i campitextAnchorepageAnchor.pageRefs[].bounding_poly.
Occorrenza
Scegli REQUIRED se un'entità deve sempre essere presente nei documenti di un
determinato tipo. Scegli OPTIONAL se non esiste questa aspettativa.
Scegli ONCE se un'entità deve avere un valore, anche se lo stesso
valore viene visualizzato più volte nello stesso documento. Scegli MULTIPLE se è previsto che un'entità abbia più valori.
Etichette principali e secondarie
Le etichette padre-figlio (note anche come entità tabellari) vengono utilizzate per etichettare i dati in una tabella. La tabella seguente contiene 3 righe e 4 colonne.

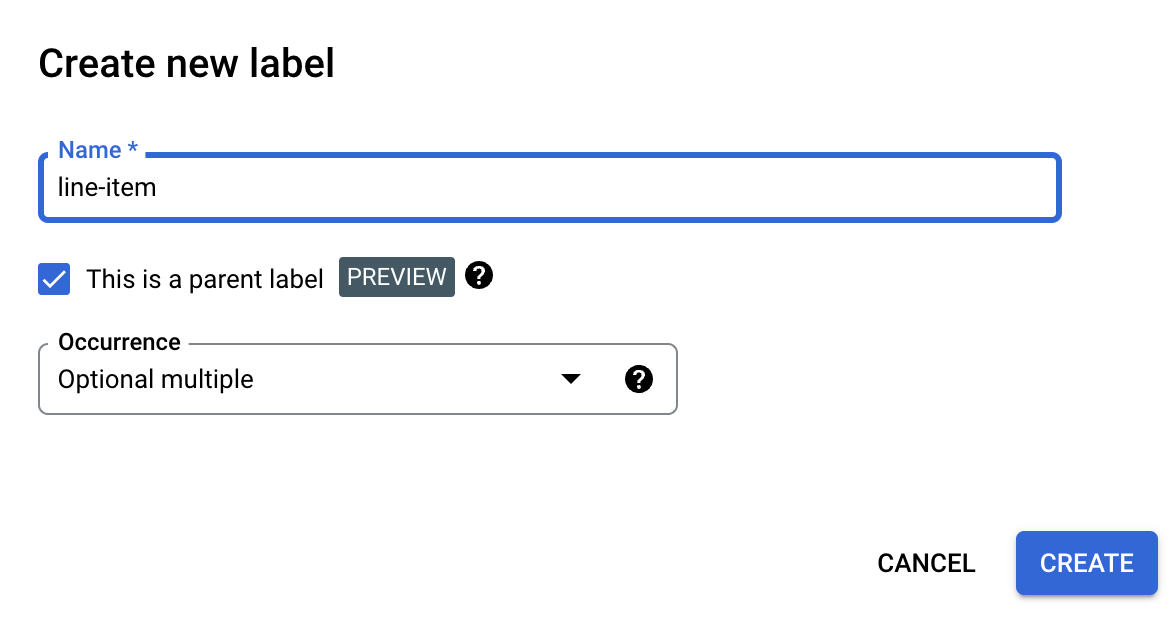
Puoi definire queste tabelle utilizzando le etichette padre-figlio. In questo esempio, l'etichetta
principale line-item definisce una riga della tabella.
Creare un'etichetta principale
Nella pagina Modifica schema, seleziona Crea etichetta.
Seleziona la casella di controllo Questa è un'etichetta principale e inserisci le altre informazioni. L'etichetta principale deve contenere un'occorrenza di
optional_multipleorequire_multiplein modo che possa essere ripetuta per acquisire tutte le righe della tabella.Seleziona Salva.
L'etichetta principale viene visualizzata nella pagina Modifica schema, con l'opzione Aggiungi etichetta secondaria accanto.
Per creare un'etichetta secondaria
Accanto all'etichetta principale nella pagina Modifica schema, seleziona Aggiungi etichetta secondaria.
Inserisci le informazioni per l'etichetta secondaria.
Seleziona Salva.
Ripeti l'operazione per ogni etichetta secondaria che vuoi aggiungere.
Le etichette secondarie vengono visualizzate con rientro sotto l'etichetta principale nella pagina Modifica schema.

Le etichette padre-figlio sono una funzionalità in anteprima e sono supportate solo per le tabelle. La profondità di nidificazione è limitata a 1, il che significa che le entità secondarie non possono contenere altre entità secondarie.
Creare etichette dello schema da documenti etichettati
Crea automaticamente le etichette dello schema importando file JSON Document pre-etichettati.
Durante l'importazione di Document, le etichette dello schema appena aggiunte vengono aggiunte all'editor dello schema. Seleziona "Modifica schema" per verificare o
modificare il tipo di dati e il tipo di occorrenza delle nuove etichette dello schema. Una volta confermato, seleziona
le etichette dello schema e seleziona Attiva.
Set di dati di esempio
Per aiutarti a iniziare a utilizzare Document AI Workbench, i set di dati vengono forniti in un bucket Cloud Storage pubblico che include file JSON di esempio Document pre-etichettati e senza etichetta di più tipi di documenti.
Questi possono essere utilizzati per l'addestramento o per estrattori personalizzati a seconda del tipo di documento.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/