Menangani respons pemrosesan
Respons terhadap permintaan pemrosesan berisi objek Document
yang menyimpan semua yang diketahui tentang dokumen yang diproses, termasuk semua
informasi terstruktur yang dapat diekstrak oleh Document AI.
Halaman ini menjelaskan tata letak objek Document dengan memberikan contoh dokumen,
lalu memetakan aspek hasil OCR ke elemen tertentu dari JSON objek Document.
Selain itu, juga menyediakan library klien, contoh kode, dan contoh kode SDK Document AI Toolbox.
Contoh kode ini menggunakan pemrosesan online, tetapi penguraian objek Document berfungsi sama untuk pemrosesan batch.
Gunakan penampil atau utilitas pengeditan JSON yang dirancang khusus untuk meluaskan atau menciutkan elemen. Meninjau JSON mentah dalam utilitas teks biasa tidak efisien.
Teks, tata letak, dan skor kualitas
Berikut adalah contoh dokumen teks:

Berikut adalah objek dokumen lengkap seperti yang ditampilkan oleh pemroses Enterprise Document OCR:
Output OCR ini juga selalu disertakan dalam output pemroses Document AI, karena OCR dijalankan oleh pemroses. Fitur ini menggunakan data OCR yang ada, sehingga Anda dapat memasukkan data JSON tersebut menggunakan opsi dokumen inline ke dalam pemroses Document AI.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Berikut beberapa kolom penting:
Teks mentah
Kolom text berisi teks yang dikenali oleh Document AI.
Teks ini tidak berisi struktur tata letak apa pun selain spasi, tab, dan
feed baris. Ini adalah satu-satunya kolom yang menyimpan informasi tekstual dokumen dan berfungsi sebagai sumber kebenaran teks dokumen. Kolom
lain dapat merujuk ke bagian kolom teks berdasarkan posisi (startIndex dan endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Ukuran halaman dan bahasa
Setiap page dalam objek dokumen sesuai dengan
halaman fisik dari dokumen contoh. Output JSON contoh berisi satu
halaman karena merupakan satu gambar PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- Kolom
pages[].detectedLanguages[]berisi bahasa yang ditemukan di halaman tertentu, beserta skor keyakinan.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Data OCR
OCR Document AI mendeteksi teks dengan berbagai perincian atau organisasi di halaman, seperti blok teks, paragraf, token, dan simbol (tingkat simbol bersifat opsional, jika dikonfigurasi untuk menghasilkan data tingkat simbol). Semua ini adalah anggota objek halaman.
Setiap elemen memiliki layout yang sesuai yang
mendeskripsikan posisi dan teksnya. Elemen visual non-teks
(seperti kotak centang) juga berada di tingkat halaman.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
Teks mentah dirujuk dalam objek textAnchor yang diindeks ke dalam string teks utama dengan startIndex dan endIndex.
Untuk
boundingPoly, sudut kiri atas halaman adalah titik asal(0,0). Nilai X positif berada di sebelah kanan, dan nilai Y positif berada di bawah.Objek
verticesmenggunakan koordinat yang sama dengan gambar asli, sedangkannormalizedVerticesberada dalam rentang[0,1]. Ada matriks transformasi yang menunjukkan ukuran pelurusan dan atribut normalisasi gambar lainnya.
- Untuk menggambar
boundingPoly, gambar segmen garis dari satu verteks ke verteks berikutnya. Kemudian, tutup poligon dengan menggambar segmen garis dari verteks terakhir kembali ke verteks pertama. Elemen orientasi tata letak menunjukkan apakah teks telah diputar relatif terhadap halaman.
Untuk membantu Anda memvisualisasikan struktur dokumen, gambar berikut menggambar poligon pembatas untuk page.paragraphs, page.lines, page.tokens.
Paragraf

Garis

Token

Blok

Prosesor Enterprise Document OCR dapat melakukan penilaian kualitas dokumen berdasarkan keterbacaannya.
- Anda harus menyetel kolom
processOptions.ocrConfig.enableImageQualityScoresketrueuntuk mendapatkan data ini dalam respons API.
Penilaian kualitas ini adalah skor kualitas dalam [0, 1], dengan 1 berarti kualitas sempurna.
Skor kualitas ditampilkan di kolom Page.imageQualityScores.
Semua kerusakan yang terdeteksi dicantumkan sebagai quality/defect_* dan diurutkan secara menurun berdasarkan nilai keyakinan.
Berikut adalah PDF yang terlalu gelap dan buram sehingga tidak nyaman dibaca:
Berikut informasi kualitas dokumen yang ditampilkan oleh pemroses Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Contoh kode
Contoh kode berikut menunjukkan cara mengirim permintaan pemrosesan, lalu membaca dan mencetak kolom ke terminal:
Java
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Java Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Node.js
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Node.js Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Formulir dan tabel
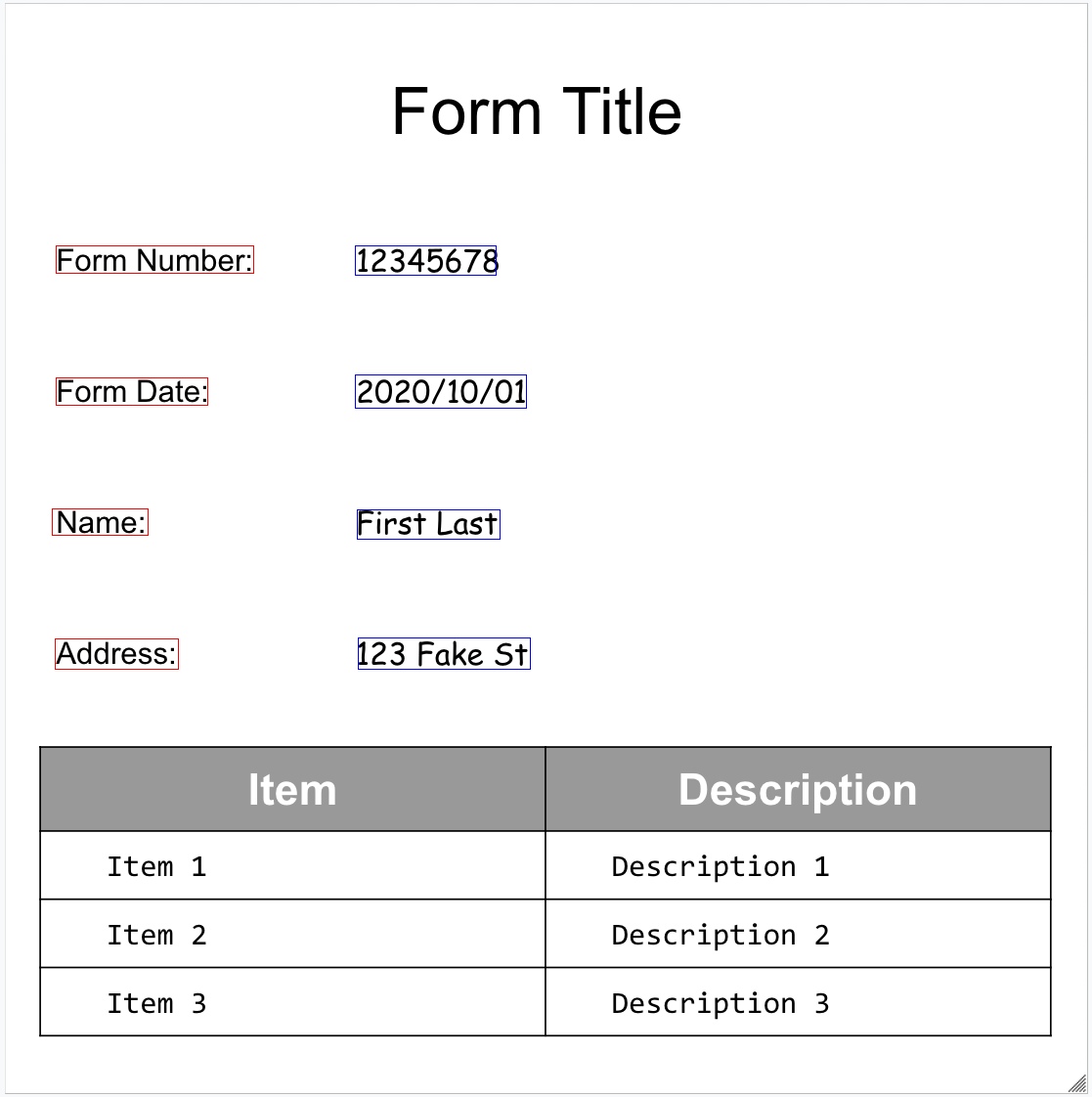
Berikut contoh formulir kami:
Berikut adalah objek dokumen lengkap seperti yang ditampilkan oleh Form Parser:
Berikut beberapa kolom penting:
Parser Formulir dapat mendeteksi FormFields
di halaman. Setiap kolom formulir memiliki nama dan nilai. Ini juga disebut
pasangan nilai kunci (KVP). Perhatikan bahwa KVP berbeda dengan entitas (skema) di
ekstraktor lain:
Nama entity dikonfigurasi. Kunci dalam KVP secara harfiah adalah teks kunci pada dokumen.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI juga dapat mendeteksi
Tablesdi halaman.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Ekstraksi tabel dalam Pengurai Formulir hanya mengenali tabel sederhana, yaitu tabel tanpa sel yang mencakup baris atau kolom. Jadi, rowSpan dan colSpan selalu 1.
Mulai dari versi pemroses
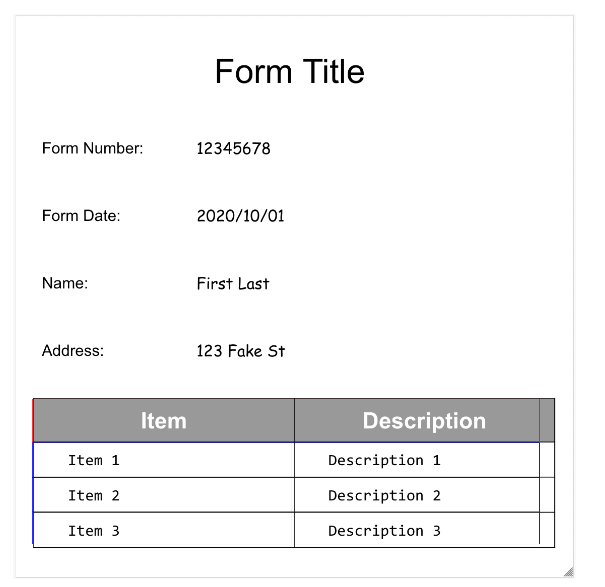
pretrained-form-parser-v2.0-2022-11-10, Form Parser juga dapat mengenali entity generik. Untuk mengetahui informasi selengkapnya, lihat Form Parser.Untuk membantu Anda memvisualisasikan struktur dokumen, gambar berikut menggambar poligon pembatas untuk
page.formFieldsdanpage.tables.Kotak centang dalam tabel. Parser Formulir dapat mendigitalkan kotak centang dari gambar dan PDF sebagai KVP. Memberikan contoh digitalisasi kotak centang sebagai pasangan nilai kunci.
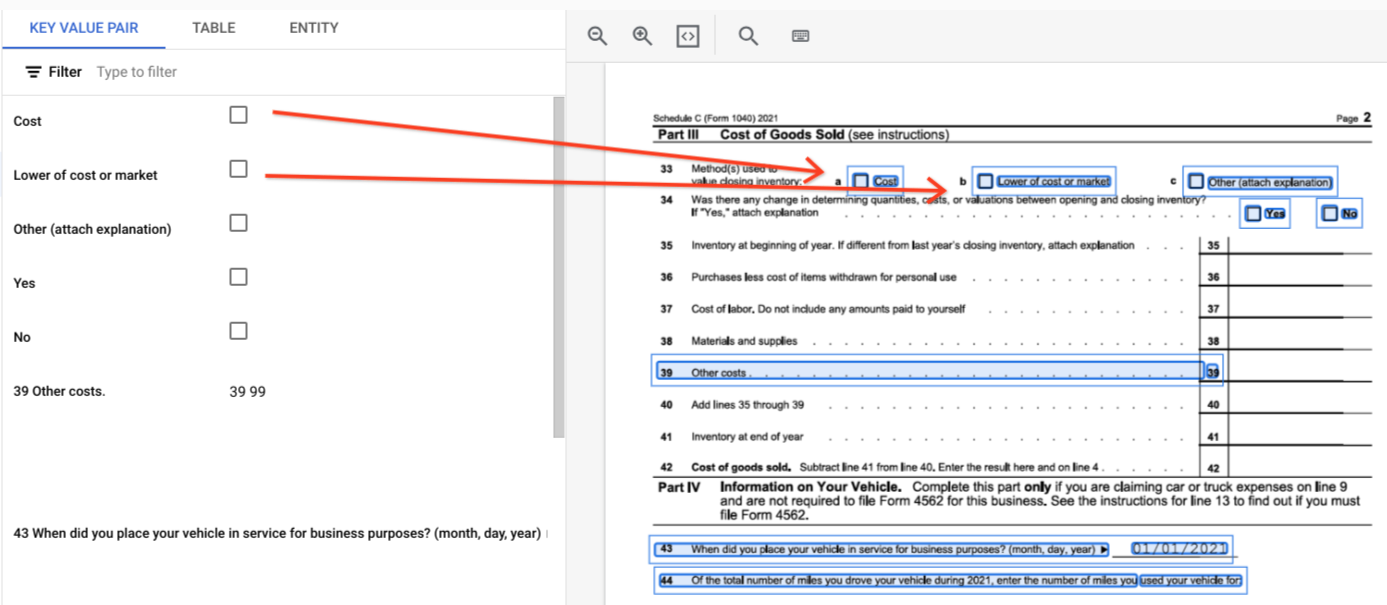
Di luar tabel, kotak centang ditampilkan sebagai elemen visual dalam Parser Formulir. Menandai kotak persegi yang memiliki tanda centang di atas UI dan unicode ✓ dalam JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
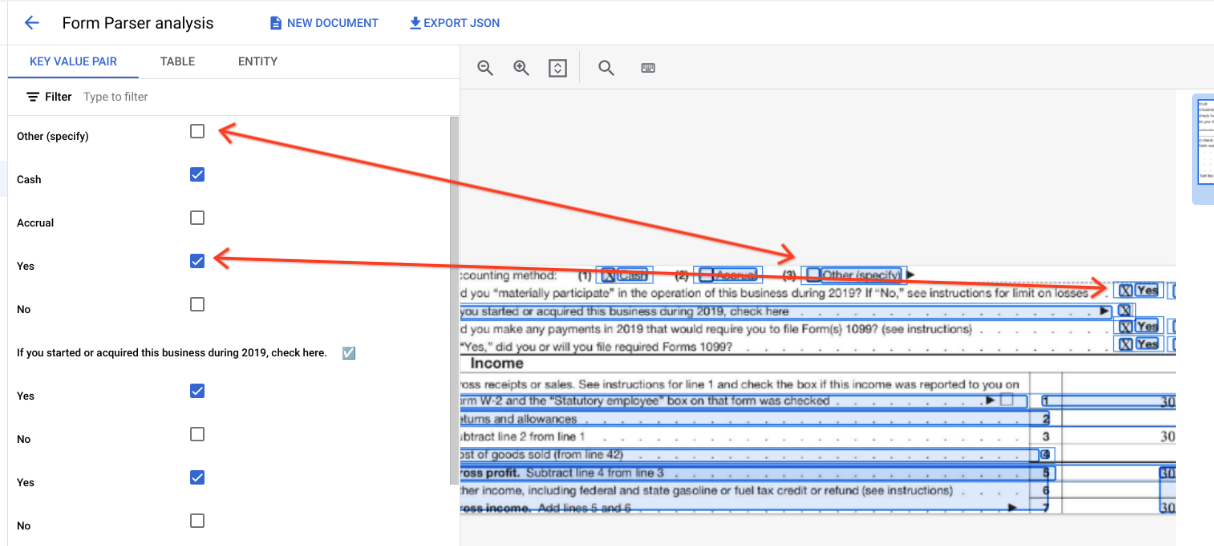
Dalam tabel, kotak centang muncul sebagai karakter Unicode seperti ✓ (dicentang) atau ☐ (tidak dicentang).
Kotak centang yang terisi memiliki nilai sebagai filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. Kotak centang yang tidak dicentang memiliki nilai unfilled_checkbox.
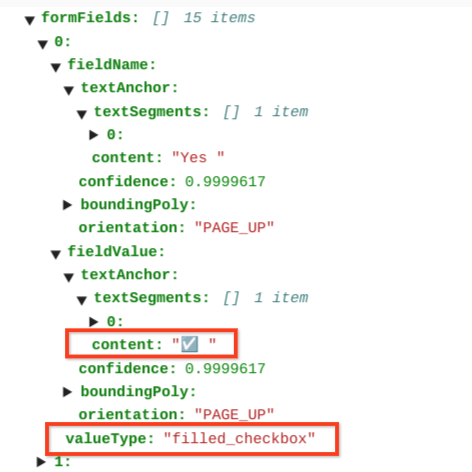
Kolom konten menampilkan nilai konten kotak centang yang ditandai ✓ di
jalur pages>formFields>x>fieldValue>textAnchor>content.
Untuk membantu Anda memvisualisasikan struktur dokumen, gambar berikut menggambar poligon pembatas untuk page.formFields dan page.tables.
Kolom Formulir
Tabel
Contoh kode
Contoh kode berikut menunjukkan cara mengirim permintaan pemrosesan, lalu membaca dan mencetak kolom ke terminal:
Java
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Java Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Node.js
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Node.js Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Entitas, entitas bertingkat, dan nilai yang dinormalisasi
Sebagian besar pemroses khusus mengekstrak data terstruktur yang didasarkan pada skema yang ditetapkan dengan baik. Misalnya, Invoice parser
mendeteksi kolom tertentu seperti invoice_date dan supplier_name. Berikut contoh invoice:
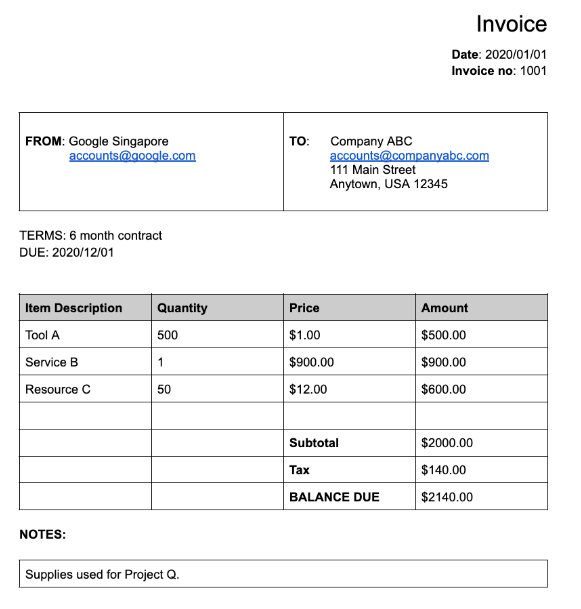
Berikut objek dokumen lengkap seperti yang ditampilkan oleh Invoice parser:
Berikut adalah beberapa bagian penting dari objek dokumen:
Kolom yang terdeteksi:
Entitiesberisi kolom yang dapat dideteksi oleh pemroses, misalnya,invoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Untuk kolom tertentu, pemroses juga menormalisasi nilai. Dalam contoh ini, tanggal telah dinormalisasi dari
2020/01/01menjadi2020-01-01.Normalisasi: Untuk banyak kolom tertentu yang didukung, pemroses juga menormalisasi nilai dan juga menampilkan
entity. KolomnormalizedValueditambahkan ke kolom yang diekstrak mentah yang diperoleh melaluitextAnchorsetiap entitas. Oleh karena itu, teks literal dinormalisasi, yang sering kali memecah nilai teks menjadi sub-kolom. Misalnya, tanggal 1 September 2024 akan ditampilkan sebagai:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
Dalam contoh ini, tanggal telah dinormalisasi dari 01/01/2020 menjadi 01-01-2020, format standar untuk mengurangi pasca-pemrosesan dan memungkinkan konversi ke format yang dipilih.
Alamat juga sering dinormalisasi, yang memecah elemen alamat menjadi kolom individual. Angka dinormalisasi dengan memiliki bilangan bulat atau floating point sebagai normalizedValue.
- Pengayaan: Pemroses dan kolom tertentu juga mendukung pengayaan.
Misalnya,
supplier_nameasli dalam dokumenGoogle Singaporetelah dinormalisasi terhadap Enterprise Knowledge Graph menjadiGoogle Asia Pacific, Singapore. Perhatikan juga bahwa karena Enterprise Knowledge Graph berisi informasi tentang Google, Document AI menyimpulkansupplier_addressmeskipun tidak ada dalam dokumen sampel.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Kolom bertingkat: Skema (kolom) bertingkat dapat dibuat dengan terlebih dahulu mendeklarasikan entity sebagai induk, lalu membuat entity turunan di bawah induk. Respons penguraian untuk induk mencakup kolom turunan dalam elemen
propertiesdari kolom induk. Dalam contoh berikut,line_itemadalah kolom induk yang memiliki dua kolom turunan:line_item/descriptiondanline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Parser berikut mengikutinya:
- Ekstrak (Pengekstrak Kustom)
- Lama
- Parser laporan mutasi bank
- Parser biaya
- Parser Invoice
- Parser PaySlip
- Parser W2
Contoh kode
Contoh kode berikut menunjukkan cara mengirim permintaan pemrosesan, lalu membaca dan mencetak kolom dari pemroses khusus ke terminal:
Java
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Java Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Node.js
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Node.js Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Pengekstrak Dokumen Kustom
Prosesor Pengekstrak Dokumen Kustom dapat mengekstraksi entity kustom dari dokumen yang tidak memiliki prosesor terlatih yang tersedia. Hal ini dapat dilakukan dengan melatih model kustom atau menggunakan Model Dasar AI Generatif untuk mengekstrak entity bernama tanpa pelatihan apa pun. Untuk mengetahui informasi selengkapnya, lihat Membuat Pengekstrak Dokumen Kustom di konsol.
- Jika Anda melatih model kustom, prosesor dapat digunakan dengan cara yang sama persis dengan prosesor ekstraksi entity terlatih.
- Jika menggunakan model dasar, Anda dapat membuat versi pemroses untuk mengekstrak entity tertentu untuk setiap permintaan, atau Anda dapat mengonfigurasinya berdasarkan per permintaan.
Untuk mengetahui informasi tentang struktur output, lihat Entitas, entitas bertingkat, dan nilai yang dinormalisasi.
Contoh kode
Jika Anda menggunakan model kustom atau membuat versi pemroses menggunakan model dasar, gunakan contoh kode ekstraksi entity.
Contoh kode berikut menunjukkan cara mengonfigurasi entity tertentu untuk Ekstraktor Dokumen Kustom model dasar berdasarkan per permintaan dan mencetak entity yang diekstrak:
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Ringkasan
Prosesor Summarizer menggunakan Model Dasar AI Generatif untuk meringkas teks yang diekstrak dari dokumen. Panjang dan format respons dapat disesuaikan dengan cara berikut:
- Panjang
BRIEF: Ringkasan singkat satu atau dua kalimatMODERATE: Ringkasan sepanjang satu paragrafCOMPREHENSIVE: Opsi terpanjang yang tersedia
- Format
Anda dapat membuat versi pemroses untuk durasi dan format tertentu, atau mengonfigurasinya berdasarkan per permintaan.
Teks yang diringkas akan muncul di Document.entities.normalizedValue.text. Anda dapat menemukan file JSON output contoh lengkap di Output pemroses contoh.
Untuk mengetahui informasi selengkapnya, lihat Membangun perangkum dokumen di konsol.
Contoh kode
Contoh kode berikut menunjukkan cara mengonfigurasi panjang dan format tertentu dalam permintaan pemrosesan dan mencetak teks yang diringkas:
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Pemecahan dan klasifikasi
Berikut adalah PDF komposit 10 halaman yang berisi berbagai jenis dokumen dan formulir:
Berikut objek dokumen lengkap seperti yang ditampilkan oleh pemisah dan pengklasifikasi dokumen pinjaman:
Setiap dokumen yang terdeteksi oleh pemisah diwakili oleh
entity. Contoh:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchormenunjukkan bahwa dokumen ini terdiri dari 2 halaman. Perhatikan bahwapageRefs[].pageberbasis nol dan merupakan indeks ke dalam kolomdocument.pages[].Entity.typemenentukan bahwa dokumen ini adalah formulir Schedule SE 1040. Untuk daftar lengkap jenis dokumen yang dapat diidentifikasi, lihat Jenis dokumen yang diidentifikasi dalam dokumentasi pemroses.
Untuk mengetahui informasi selengkapnya, lihat Perilaku pemisah dokumen.
Contoh kode
Pemecah mengidentifikasi batas halaman, tetapi tidak benar-benar memecah dokumen input untuk Anda. Anda dapat menggunakan Toolbox Document AI untuk memisahkan file PDF secara fisik menggunakan batas halaman. Contoh kode berikut mencetak rentang halaman tanpa memisahkan PDF:
Java
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Java Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Node.js
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Node.js Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Document yang diproses.
Python
Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi API Python Document AI.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Toolbox Document AI
Document AI Toolbox adalah SDK untuk Python yang menyediakan fungsi utilitas untuk mengelola, memanipulasi, dan mengekstrak informasi dari respons dokumen.
Objek ini membuat objek dokumen "yang di-wrap" dari respons dokumen yang diproses dari file JSON di
Cloud Storage, file JSON lokal, atau output langsung dari metode process_document().
Aplikasi ini dapat melakukan tindakan berikut:
- Gabungkan file JSON
Documentyang terfragmentasi dari Pemrosesan Batch menjadi satu dokumen "gabungan". - Mengekspor shard sebagai
Documentterpadu. -
Dapatkan output
Documentdari: - Akses teks dari
Pages,Lines,Paragraphs,FormFields, danTablestanpa menangani informasiLayout. - Telusuri
Pagesyang berisi string target atau cocok dengan ekspresi reguler. - Telusuri
FormFieldsberdasarkan nama. - Telusuri
Entitiesmenurut jenis. - Konversikan
Tableske DataFrame Pandas atau CSV. - Sisipkan
EntitiesdanFormFieldske dalam tabel BigQuery. - Membagi file PDF berdasarkan output dari pemroses Splitter/Classifier.
- Ekstrak gambar
EntitiesdariDocumentkotak pembatas. -
Mengonversi
Documentske dan dari format yang umum digunakan:- Cloud Vision API
AnnotateFileResponse - hOCR
- Format pemrosesan dokumen pihak ketiga
- Cloud Vision API
- Buat batch dokumen untuk diproses dari folder Cloud Storage.
Contoh Kode
Contoh kode berikut menunjukkan cara menggunakan Toolbox Document AI.