Dataproc-Cluster mit Clientbibliotheken erstellen
Der unten aufgeführte Beispielcode zeigt Ihnen, wie Sie mit den Cloud-Clientbibliotheken einen Dataproc-Cluster erstellen, einen Job im Cluster ausführen und anschließend den Cluster löschen.
Sie können die Aufgaben auch hiermit ausführen:
- API REST-Anfragen in Kurzanleitung: API Explorer verwenden
- die Google Cloud -Console in Dataproc-Cluster mit der Google Cloud -Console erstellen
- die Google Cloud CLI in Dataproc-Cluster mit der Google Cloud CLI erstellen
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Installieren Sie die Clientbibliothek. Weitere Informationen finden Sie unter Entwicklungsumgebung einrichten.
- Authentifizierung einrichten
- Klonen Sie GitHub-Beispielcode und führen Sie ihn aus.
- Sehen Sie sich die Ausgabe an. Der Code gibt das Jobtreiberlog an den standardmäßigen Dataproc-Staging-Bucket in Cloud Storage aus. Sie können die Jobtreiberausgabe in der Google Cloud Konsole im Dataproc-Bereich Jobs Ihres Projekts aufrufen. Klicken Sie auf die Job-ID, um die Jobausgabe auf der Seite „Jobdetails“ anzuzeigen.
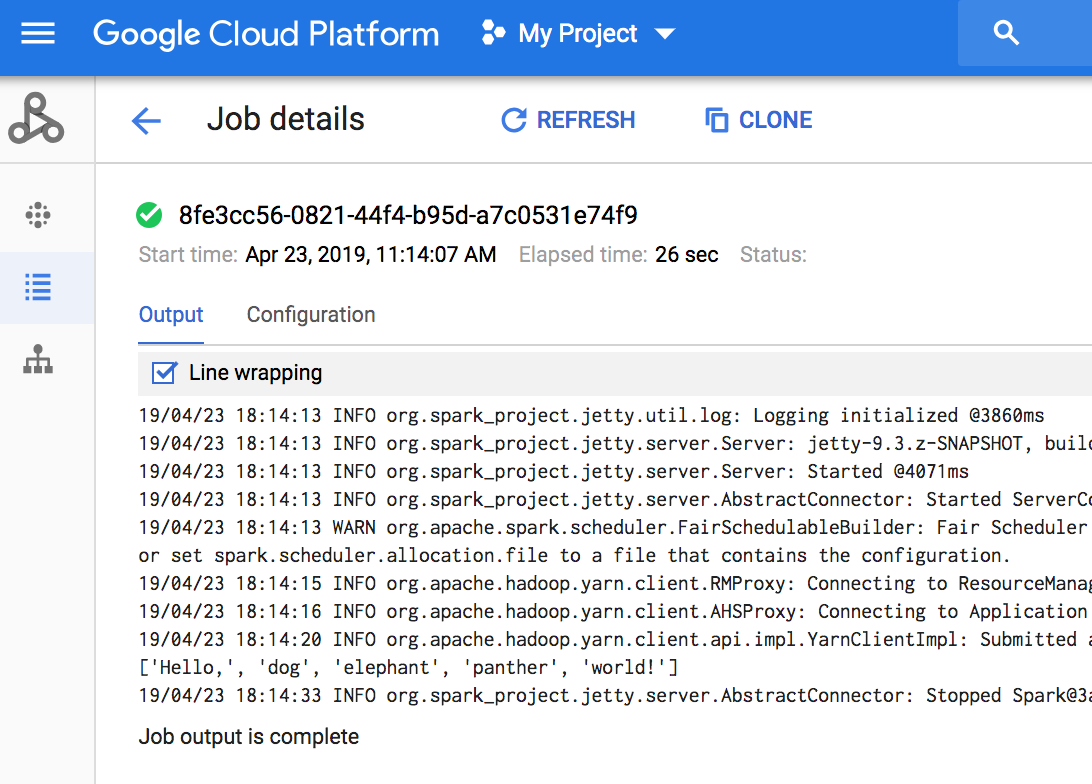
- Installieren Sie die Clientbibliothek. Weitere Informationen finden Sie unter Java-Entwicklungsumgebung einrichten.
- Authentifizierung einrichten
- Klonen Sie GitHub-Beispielcode und führen Sie ihn aus.
- Sehen Sie sich die Ausgabe an. Der Code gibt das Jobtreiberlog an den standardmäßigen Dataproc-Staging-Bucket in Cloud Storage aus. Sie können die Jobtreiberausgabe in der Google Cloud Konsole im Dataproc-Bereich Jobs Ihres Projekts aufrufen. Klicken Sie auf die Job-ID, um die Jobausgabe auf der Seite „Jobdetails“ anzuzeigen.
- Installieren Sie die Clientbibliothek. Weitere Informationen finden Sie unter Node.js-Entwicklungsumgebung einrichten.
- Authentifizierung einrichten
- Klonen Sie GitHub-Beispielcode und führen Sie ihn aus.
- Sehen Sie sich die Ausgabe an. Der Code gibt das Jobtreiberlog an den standardmäßigen Dataproc-Staging-Bucket in Cloud Storage aus. Sie können die Jobtreiberausgabe in der Google Cloud Konsole im Dataproc-Bereich Jobs Ihres Projekts aufrufen. Klicken Sie auf die Job-ID, um die Jobausgabe auf der Seite „Jobdetails“ anzuzeigen.
- Installieren Sie die Clientbibliothek. Weitere Informationen finden Sie unter Python-Entwicklungsumgebung einrichten.
- Authentifizierung einrichten
- Klonen Sie GitHub-Beispielcode und führen Sie ihn aus.
- Sehen Sie sich die Ausgabe an. Der Code gibt das Jobtreiberlog an den standardmäßigen Dataproc-Staging-Bucket in Cloud Storage aus. Sie können die Jobtreiberausgabe in der Google Cloud Konsole im Dataproc-Bereich Jobs Ihres Projekts aufrufen. Klicken Sie auf die Job-ID, um die Jobausgabe auf der Seite „Jobdetails“ anzuzeigen.
- Weitere Informationen finden Sie in der Dataproc Cloud-Clientbibliothek unter Zusätzliche Ressourcen.
Code ausführen
Anleitung ausprobieren:Klicken Sie auf In Cloud Shell öffnen, um eine Python-Anleitung für Cloud-Clientbibliotheken auszuführen, in der ein Cluster erstellt, ein PySpark-Job ausgeführt und der Cluster dann gelöscht wird.