Mit dem Open-Source-Hive-BigQuery-Connector können Ihre Apache Hive-Arbeitslasten Daten aus BigQuery- und BigLake-Tabellen lesen und in diese schreiben. Sie können Daten im BigQuery-Speicher oder in Open-Source-Datenformaten in Cloud Storage speichern.
Der Hive-BigQuery-Connector implementiert die Hive Storage Handler API, damit Hive-Arbeitslasten in BigQuery- und BigLake-Tabellen integriert werden können. Die Hive-Ausführungs-Engine verarbeitet Rechenvorgänge wie Aggregationen und Joins. Der Connector verwaltet Interaktionen mit Daten, die in BigQuery oder in mit BigLake verbundenen Cloud Storage-Buckets gespeichert sind.
Das folgende Diagramm veranschaulicht, wie der Hive-BigQuery-Connector zwischen die Compute- und Datenebenen passt.
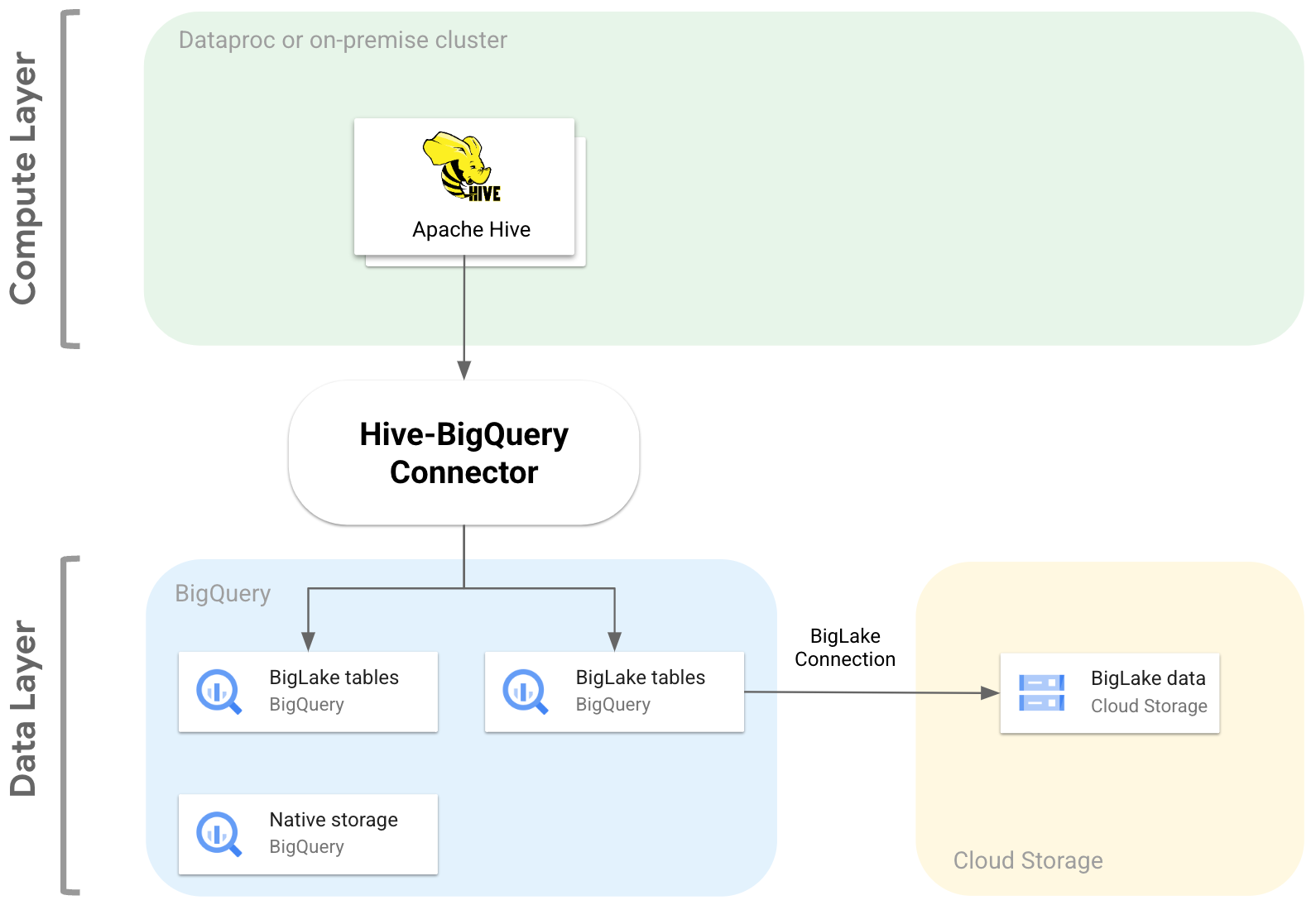
Anwendungsfälle
Hier sind einige Möglichkeiten, wie der Hive-BigQuery-Connector Sie in gängigen datengesteuerten Szenarien unterstützen kann:
Datenmigration Sie planen, Ihr Hive-Data Warehouse zu BigQuery zu migrieren und Ihre Hive-Abfragen dann schrittweise in den BigQuery-SQL-Dialekt zu übersetzen. Sie gehen davon aus, dass die Migration aufgrund der Größe Ihres Data Warehouse und der großen Anzahl verbundener Anwendungen viel Zeit in Anspruch nehmen wird, und müssen für Kontinuität während der Migrationsvorgänge sorgen. So funktioniert es:
- Sie verschieben Ihre Daten nach BigQuery.
- Mit dem Connector können Sie auf Ihre ursprünglichen Hive-Abfragen zugreifen und sie ausführen, während Sie die Hive-Abfragen nach und nach in den ANSI-kompatiblen SQL-Dialekt von BigQuery übersetzen.
- Nach Abschluss der Migration und Übersetzung wird Hive eingestellt.
Hive- und BigQuery-Workflows Sie planen, Hive für einige Aufgaben und BigQuery für Arbeitslasten zu verwenden, die von den Funktionen von BigQuery profitieren, z. B. BigQuery BI Engine oder BigQuery ML. Mit dem Connector können Sie Hive-Tabellen mit Ihren BigQuery-Tabellen verknüpfen.
Abhängigkeit von einem Open-Source-Software-Stack (OSS). Um eine Abhängigkeit von einem bestimmten Anbieter zu vermeiden, verwenden Sie einen vollständigen OSS-Stack für Ihr Data Warehouse. Das ist dein Tarif:
Sie migrieren Ihre Daten im ursprünglichen OSS-Format, z. B. Avro, Parquet oder ORC, mithilfe einer BigLake-Verbindung in Cloud Storage-Buckets.
Sie verwenden weiterhin Hive, um Ihre Abfragen im Hive-SQL-Dialekt auszuführen und zu verarbeiten.
Sie verwenden den Connector nach Bedarf, um eine Verbindung zu BigQuery herzustellen und von den folgenden Funktionen zu profitieren:
- Metadaten-Caching für eine bessere Abfrageleistung
- Schutz vor Datenverlust
- Zugriffssteuerung auf Spaltenebene
- Dynamische Datenmaskierung für Sicherheit und Governance in großem Umfang.
Features
Mit dem Hive-BigQuery-Connector können Sie mit Ihren BigQuery-Daten arbeiten und die folgenden Aufgaben ausführen:
- Abfragen mit MapReduce- und Tez-Ausführungs-Engines ausführen.
- BigQuery-Tabellen in Hive erstellen und löschen
- BigQuery- und BigLake-Tabellen mit Hive-Tabellen verknüpfen
- Schnelle Lesevorgänge aus BigQuery-Tabellen mit den Storage Read API-Streams und dem Apache Arrow-Format ausführen
- Sie können Daten mit den folgenden Methoden in BigQuery schreiben:
- Direkte Schreibvorgänge mit der BigQuery Storage Write API im ausstehenden Modus. Verwenden Sie diese Methode für Arbeitslasten, die eine niedrige Schreiblatenz erfordern, z. B. Dashboards in Echtzeit mit kurzen Aktualisierungszeiträumen.
- Indirektes Schreiben durch Bereitstellen temporärer Avro-Dateien in Cloud Storage und anschließendes Laden der Dateien in eine Zieltabelle mit der Load Job API. Diese Methode ist kostengünstiger als die direkte Methode, da für BigQuery-Ladejobs keine Gebühren anfallen. Da diese Methode langsamer ist, eignet sie sich am besten für Arbeitslasten, die nicht zeitkritisch sind.
Auf zeitpartitionierte und geclusterte BigQuery-Tabellen zugreifen Im folgenden Beispiel wird die Beziehung zwischen einer Hive-Tabelle und einer Tabelle definiert, die in BigQuery partitioniert und geclustert ist.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
Entfernen Sie Spalten, um zu vermeiden, dass unnötige Spalten aus der Datenschicht abgerufen werden.
Mit Predicate Pushdowns können Sie Datenzeilen in der BigQuery-Speicherebene vorab filtern. Mit dieser Technik lässt sich die allgemeine Abfrageleistung erheblich verbessern, da die Menge der Daten, die das Netzwerk durchlaufen, reduziert wird.
Hive-Datentypen werden automatisch in BigQuery-Datentypen konvertiert.
Integration in Spark SQL
Integration in Apache Pig und HCatalog.
Jetzt starten
Eine Anleitung zum Installieren und Konfigurieren des Hive-BigQuery-Connectors in einem Hive-Cluster finden Sie hier.