什么是自动扩缩
估算工作负载的“集群”工作器(节点)的“适当”数量非常困难,整个流水线的单个集群大小通常不是理想之选。用户启动的集群扩缩功能部分解决了此问题,但需要监控集群利用率和人工干预。
Dataproc AutoscalingPolicies API 提供自动管理集群资源的机制,还启用了集群工作器虚拟机的自动扩缩功能。Autoscaling Policy 是可重复使用的配置,描述了应如何扩缩使用该自动扩缩政策的集群工作器。该政策定义了扩缩边界、频率和积极性,以在整个集群生命周期内提供对集群资源的精细控制。
何时使用自动扩缩
使用自动扩缩:
在将数据储存在外部服务(如 Cloud Storage 或 BigQuery)的集群上
在处理许多作业的集群上
以扩缩单个作业集群
对 Spark 批处理作业使用增强的灵活性模式
自动扩缩功能不建议使用/用于:
HDFS:自动扩缩功能不适合对集群 HDFS 调整规模,因为:
- HDFS 利用率不是自动扩缩的信号。
- HDFS 数据仅托管在主要工作器上。主要工作器的数量必须足以托管所有 HDFS 数据。
- 停用 HDFS DataNode 可能会延迟移除工作器。在移除工作器之前,DataNode 会将 HDFS 块复制到其他 DataNode。此过程可能需要几个小时,具体取决于数据大小和复制因子。
YARN 节点标签:自动扩缩因 YARN-9088 而不支持 YARN 节点标签和属性
dataproc:am.primary_only。当使用节点标签时,YARN 错误地报告集群指标。Spark 结构化流:自动扩缩不支持 Spark 结构化流(请参阅自动扩缩和 Spark 结构化流)。
闲置集群:建议不要在集群处于闲置状态时使用自动扩缩将集群缩减到大小下限。由于创建新集群的速度与调整集群大小的速度一样快,请考虑删除闲置集群,然后重新创建。以下工具支持此“临时”模型:
使用 Dataproc 工作流在专用集群上安排一组作业,然后在作业完成之后删除该集群。如需更高级的编排,请使用以 Apache Airflow 为基础开发的 Cloud Composer。
对于处理临时查询或外部安排的工作负载的集群,请使用集群预定删除以在指定的空闲时间段后或在特定时间点时删除集群。
不同规模的工作负载:当小型作业和大型作业在集群上运行时,安全停用缩容会等待大型作业完成。结果是,长时间运行的作业会延迟对集群上运行的小型作业的资源进行自动扩缩,直到长时间运行的作业完成。为避免出现这种结果,请将大小相似的小型作业组合在一个集群中,并将每个长时间运行的作业隔离到单独的集群中。
启用自动扩缩功能
如需在集群上启用自动扩缩,请执行以下操作:
采用以下任一方式:
创建自动扩缩政策
gcloud CLI
您可以使用 gcloud dataproc autoscaling-policies import 命令创建自动扩缩政策。它会读取定义了自动扩缩政策的本地 YAML 文件。文件的格式和内容应与 autoscalingPolicies REST API 定义的配置对象和字段相匹配。
以下 YAML 示例定义了 Dataproc 标准集群的政策,其中包含所有必填字段。它还为主要工作器提供 minInstances 和 maxInstances 值,为辅助(抢占式)工作器提供 maxInstances 值,并指定 4 分钟 cooldownPeriod(默认值为 2 分钟)。workerConfig 配置主要工作器。在此示例中,minInstances 和 maxInstances 设置为相同的值,以避免扩缩主要工作器。
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
以下 YAML 示例定义了 Dataproc 标准集群的政策,其中包含所有必填和可选的自动扩缩政策字段。
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
以下 YAML 示例定义了零规模集群的政策。
对于零规模集群,请勿添加workerConfig。
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
从本地终端或在 Cloud Shell 中运行以下 gcloud 命令以创建自动扩缩政策。提供政策的名称。此名称将成为政策 id,您可以在后续的 gcloud 命令中使用该名称来引用该政策。使用 --source 标志指定要导入的自动扩缩政策 YAML 文件的本地路径和文件名。
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
REST API
通过将 AutoscalingPolicy 定义为 autoscalingPolicies.create 请求的一部分来创建自动扩缩政策。
控制台
如需创建自动扩缩政策,请使用 API 控制台从 Dataproc 自动扩缩政策页面选择“创建政策”。在创建政策页面上,您可以选择政策建议面板,以填充特定作业类型或扩缩目标的自动扩缩政策字段。
创建自动扩缩集群
在创建自动扩缩政策后,创建将使用自动扩缩政策的集群。该集群必须与自动扩缩政策位于同一区域中。
gcloud CLI
在本地终端或在 Cloud Shell 中运行以下 gcloud 命令以创建自动扩缩集群。为集群提供名称,并使用 --autoscaling-policy 标志指定 policy ID(您在创建政策时指定的政策名称)或政策 resource URI (resource name)(请参阅自动扩缩政策 id 与 name 字段)。
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
可以通过将 AutoscalingConfig 添加到 clusters.create 请求中来创建自动扩缩集群。
控制台
您可以从 API 控制台的 Dataproc 创建集群页面上的“设置集群”面板的“自动扩缩政策”部分选择现有自动扩缩政策,以应用于新集群。
在现有集群上启用自动扩缩
在创建自动扩缩政策后,您可以在位于同一区域中的现有集群上启用该政策。
gcloud CLI
从本地终端或在 Cloud Shell 中运行以下 gcloud 命令,以在现有集群上启用自动扩缩政策。提供集群名称,并使用 --autoscaling-policy 标志指定 policy ID(您在创建政策时指定的政策名称)或政策 resource URI (resource name)(请参阅自动扩缩政策 id 与 name 字段)。
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
如需在现有集群上启用自动扩缩政策,请在 clusters.patch 请求的 updateMask 中设置政策的 AutoscalingConfig.policyUri。
控制台
Google API 控制台不支持在现有集群上启用自动扩缩政策。
多集群政策使用情况
自动扩缩政策定义了可应用于多个集群的扩缩行为。当多个集群共享类似工作负载或运行具有类似资源使用模式的作业时,自动扩缩政策非常适用。
您可以更新多个集群所使用的政策。更新会立即影响所有使用该政策的集群的自动扩缩行为(请参阅 autoscalingPolicies.update)。如果您不想将政策更新应用于使用该政策的集群,请先停用集群上的自动扩缩,然后再更新政策。
gcloud CLI
在本地终端或在 Cloud Shell 中运行以下 gcloud 命令,以停用集群的自动扩缩。
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
REST API
要停用集群上的自动扩缩,请将 AutoscalingConfig.policyUri 设置为空字符串,并在 clusters.patch 请求中设置 update_mask=config.autoscaling_config.policy_uri。
控制台
Google API 控制台不支持停用集群上的自动扩缩。
- 正由一个或多个集群使用的政策无法删除(请参阅 autoscalingPolicies.delete)。
自动扩缩的工作原理
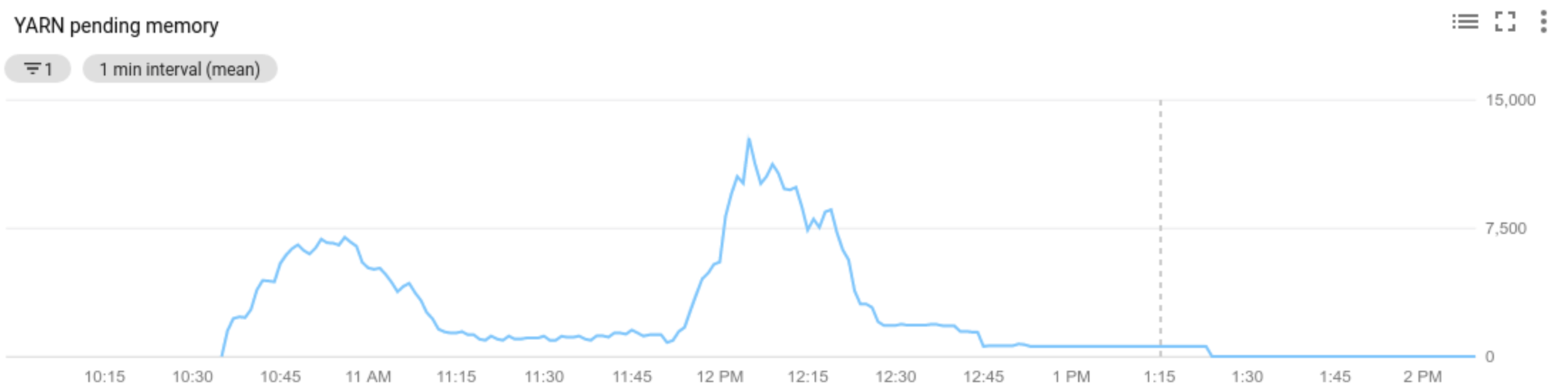
自动扩缩功能会在每个“冷却期”过后检查集群的 Hadoop YARN 指标,以确定是否扩缩集群,如果需要扩缩,则确定更新的规模。
YARN 待处理资源指标(待处理内存或待处理核心)的值决定了是扩容还是缩容。值大于
0表示 YARN 作业正在等待资源,并且可能需要扩容。0值表示 YARN 有足够的资源,因此可能不需要缩容或其他更改。如果待处理资源数 > 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
如果待处理资源为 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
默认情况下,从 Dataproc 映像 2.2 开始,自动扩缩器会监控 YARN 内存和 YARN 核心,以便针对内存和核心分别评估
estimated_worker_count,并选择生成的较大工作器数量。对于之前的映像版本,自动扩缩器仅监控 YARN 内存,除非您启用基于核心的自动扩缩。$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
根据需要更改的估算工作器数量,自动扩缩功能使用
scaleUpFactor或scaleDownFactor来计算工作器数量的实际更改:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
scaleUpFactor 或 scaleDownFactor 为 1.0 意味着自动扩缩执行扩缩,以使待处理或可用资源为 0(完全利用率)。
计算工作器数量的更改后,
scaleUpMinWorkerFraction和scaleDownMinWorkerFraction会充当阈值,以确定自动扩缩是否会扩缩集群。一小部分表示即使Δworkers较小,自动扩缩也应该进行扩缩。较大部分表示仅在Δworkers较大时才应进行扩缩。IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
如果要扩缩的工作器数量大到足以触发扩缩,则自动扩缩会使用
workerConfig和secondaryWorkerConfig和weight的minInstancesmaxInstances边界(主要工作器与辅助工作器的比率),以确定如何在主要和辅助工作器实例组之间拆分工作器数量。这些计算的结果是针对扩缩阶段的集群的最终自动扩缩更改。如果满足以下条件,则在使用映像版本 2.0.57+、2.1.5+ 及更高映像版本创建的集群上,自动扩缩缩容请求会被取消:
- 正在进行缩容,且安全停用超时值为非零,并且
活跃 YARN 工作器(“活跃工作器”)数量加上自动扩缩器建议的工作器 (
Δworkers) 总数变化量等于或大于DECOMMISSIONINGYARN 工作器(“停用工作器”),如以下公式所示:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
如需查看缩容取消示例,请参阅自动扩缩何时取消缩容操作?。
自动扩缩配置建议
本部分包含有助于您配置自动扩缩的建议。
避免扩缩主要工作器
主要工作器运行 HDFS Datanode,而辅助工作器是计算专用工作器。使用辅助工作器可让您高效地扩缩计算资源,而无需预配存储,从而实现更快的扩缩能力。HDFS Namenode 可能存在多个竞态条件,导致 HDFS 损坏,从而使停用过程无限期卡住。为避免出现此问题,请避免扩缩主要工作器。例如:none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100。
您需要对集群创建命令进行一些修改:
- 设置
--num-workers=10以匹配自动扩缩政策的主要工作器组大小。 - 设置
--secondary-worker-type=non-preemptible以将辅助工作器配置为非抢占式工作器。(除非需要抢占式虚拟机)。 - 将硬件配置从主要工作器复制到辅助工作器。例如,将
--secondary-worker-boot-disk-size=1000GB设置为与--worker-boot-disk-size=1000GB匹配。
对 Spark 批处理作业使用增强的灵活性模式
将增强的灵活模式 (EFM) 与自动扩缩搭配使用,可实现以下目的:
在作业运行期间更快地缩容集群
防止因集群缩容而中断正在运行的作业
最大限度地减少因抢占抢占式辅助工作器而导致正在运行的作业中断
启用 EFM 后,自动扩缩政策的安全停用超时值必须设置为 0s。自动扩缩政策只能自动扩缩辅助工作器。
选择安全停用超时
从集群中移除节点时,自动扩缩功能支持 YARN 安全停用。通过安全停用功能,应用可以在不同阶段之间完成数据重排,从而避免阻碍作业进度。自动扩缩政策中提供的安全停用超时是指在移除节点之前 YARN 等待运行应用(停用开始时运行的应用)的持续时间上限。
如果进程未在指定的安全停用超时期内完成,则工作器节点会被强制关停,从而可能导致数据丢失或服务中断。为避免这种可能性,请将安全停用超时设置为大于集群将处理的最长作业所需时间的值。例如,如果您预计最长的作业会运行一小时,请将超时设置为至少一小时 (1h)。
请考虑将花费时间超过 1 小时的作业迁移到其临时集群,以免禁用安全停用。
设置 scaleUpFactor
scaleUpFactor 控制自动扩缩程序应该以怎样的积极程度对集群进行扩容。指定介于 0.0 到 1.0 之间的数字,以设置导致添加节点的 YARN 待处理资源的小数值。
例如,如果有 100 个待处理容器,每个容器请求 512MB,则待处理 YARN 内存将达到 50GB。如果 scaleUpFactor 为 0.5,则自动扩缩程序将添加足够的节点来添加 25GB 的 YARN 内存。同样,如果为 0.1,则自动扩缩程序将添加足够节点以达到 5GB。请注意,这些值对应于 YARN 内存,而不是虚拟机上实际可用的总内存。
对于 MapReduce 作业和启用了动态分配功能的 Spark 作业,建议您首先使用 0.05。对于具有固定数量的执行程序的 Spark 作业和 Tez 作业,请使用 1.0。scaleUpFactor 为 1.0 意味着自动扩缩执行扩缩,以使待处理或可用资源为 0(完全利用率)。
设置 scaleDownFactor
scaleDownFactor 控制自动扩缩程序应该以怎样的积极程度对集群进行缩减。指定介于 0.0 到 1.0 之间的数字,以设置导致移除节点的 YARN 可用资源的小数值。
对于需要频繁扩容和缩容的大多数多作业集群,请将此值保留为 1.0。由于安全停用,缩容操作的速度比扩容操作要慢得多。设置 scaleDownFactor=1.0 可设置积极缩容速率,从而最大限度地减少缩容操作的数量,以达到适当的集群大小。
对于需要更高稳定性的集群,请设置较低的 scaleDownFactor 以降低缩容速率。
将此值设置为 0.0 可防缩容集群,例如,在使用临时集群或单作业集群时。
设置 scaleUpMinWorkerFraction 和 scaleDownMinWorkerFraction
scaleUpMinWorkerFraction 和 scaleDownMinWorkerFraction 与 scaleUpFactor 或 scaleDownFactor 搭配使用,默认值为 0.0。它们表示自动扩缩器将扩容或缩容集群时的阈值:发出扩容或缩容请求所需的集群大小的最小增加或减少小数值。
示例:除非 scaleUpMinWorkerFraction 小于或等于 0.05 (5%),否则自动扩缩器不会发出向包含 100 个节点的集群添加 5 个工作器的更新请求。如果设置为 0.1,自动扩缩器不会发出扩容集群的请求。同样,如果 scaleDownMinWorkerFraction 为 0.05,则自动扩缩器不会发出移除至少 5 个节点的请求。
默认值为 0.0,表示没有阈值。
强烈建议对大型集群(超过 100 个节点)设置较高的 scaleDownMinWorkerFractionthresholds,以避免进行不必要的小规模扩缩操作。
选择冷却期
cooldownPeriod 设置一个时间段,在此期间,自动扩缩器不会发出更改集群大小的请求。您可以使用此参数来限制自动扩缩器对集群大小的更改频率。
cooldownPeriod 的最小值和默认值均为两分钟。如果在政策中设置了较短的 cooldownPeriod,工作负载更改会更快地影响集群大小,但集群可能会进行不必要的扩容或缩减。推荐做法是在使用较短的 cooldownPeriod 时将政策的 scaleUpMinWorkerFraction、scaleDownMinWorkerFraction 和 设置为非零值。这可确保仅在资源利用率的变化足以保证集群更新时,集群才可以扩容或缩容。
如果您的工作负载对集群大小的更改很敏感,您可以延长冷却期。例如,如果您要运行批处理作业,可以将冷却期设置为 10 分钟或更长时间。尝试使用不同的冷却期,找到最适合工作负载的值。
工作器计数边界和群组权重
每个工作器组都具有 minInstances 和 maxInstances,用于为每个组的大小配置硬性限制。
每个组还有一个名为 weight 的参数,用于在两个组之间配置目标平衡。请注意,此参数只是一个提示,如果某个组的大小达到最小值或最大值,则只能在其他组中添加或移除节点。因此,weight 通常始终保留为默认的 1。
使用基于核心数的自动扩缩
对于 CPU 密集型应用,最佳实践是使用主要资源计算器进行资源分配。这是自 Dataproc 映像版本 2.2 起的默认 YARN 配置。对于早期映像版本,Dataproc 会将 YARN 配置为使用内存指标进行资源分配,除非您在创建集群时设置以下属性,以将 YARN 配置为使用主要资源计算器:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
自动扩缩指标和日志
以下资源和工具可帮助您监控自动扩缩操作及其对集群和它的作业产生的影响。
Cloud Monitoring
使用 Cloud Monitoring 来执行下列操作:
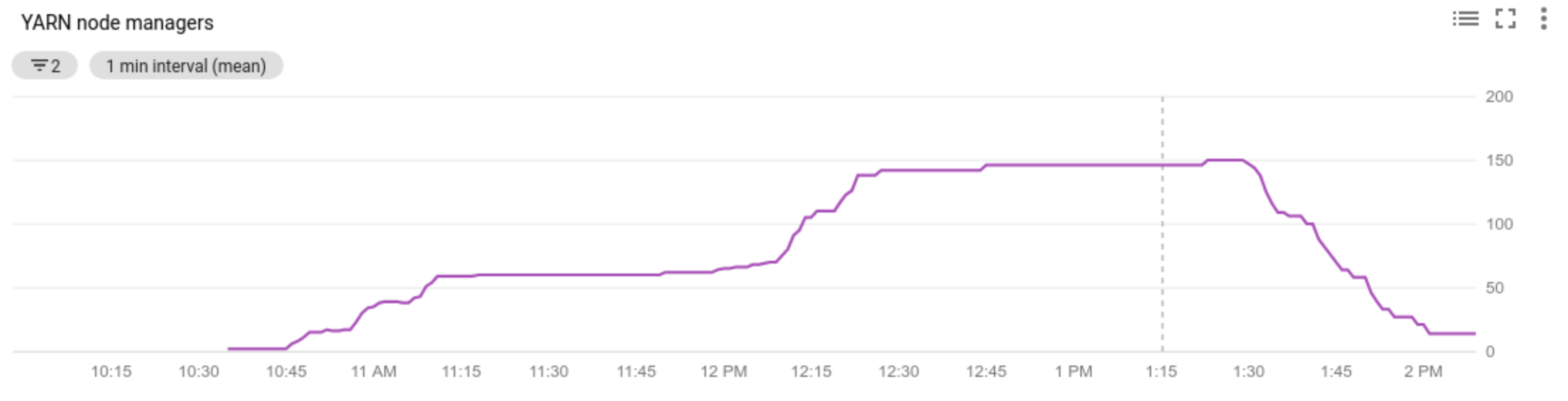
- 查看自动扩缩功能使用的指标
- 查看集群中的节点管理器数量
- 了解为何自动扩缩功能已经扩缩或未扩缩您的集群
Cloud Logging
使用 Cloud Logging 通过 Dataproc 自动扩缩器查看日志。
1) 查找集群的日志。
2) 选择 dataproc.googleapis.com/autoscaler。
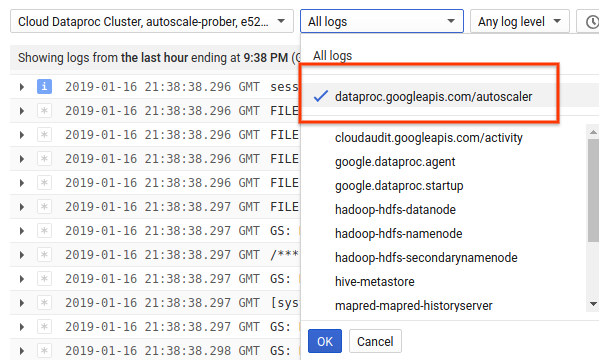
3) 展开日志消息以查看 status 字段。日志采用机器可读的 JSON 格式。
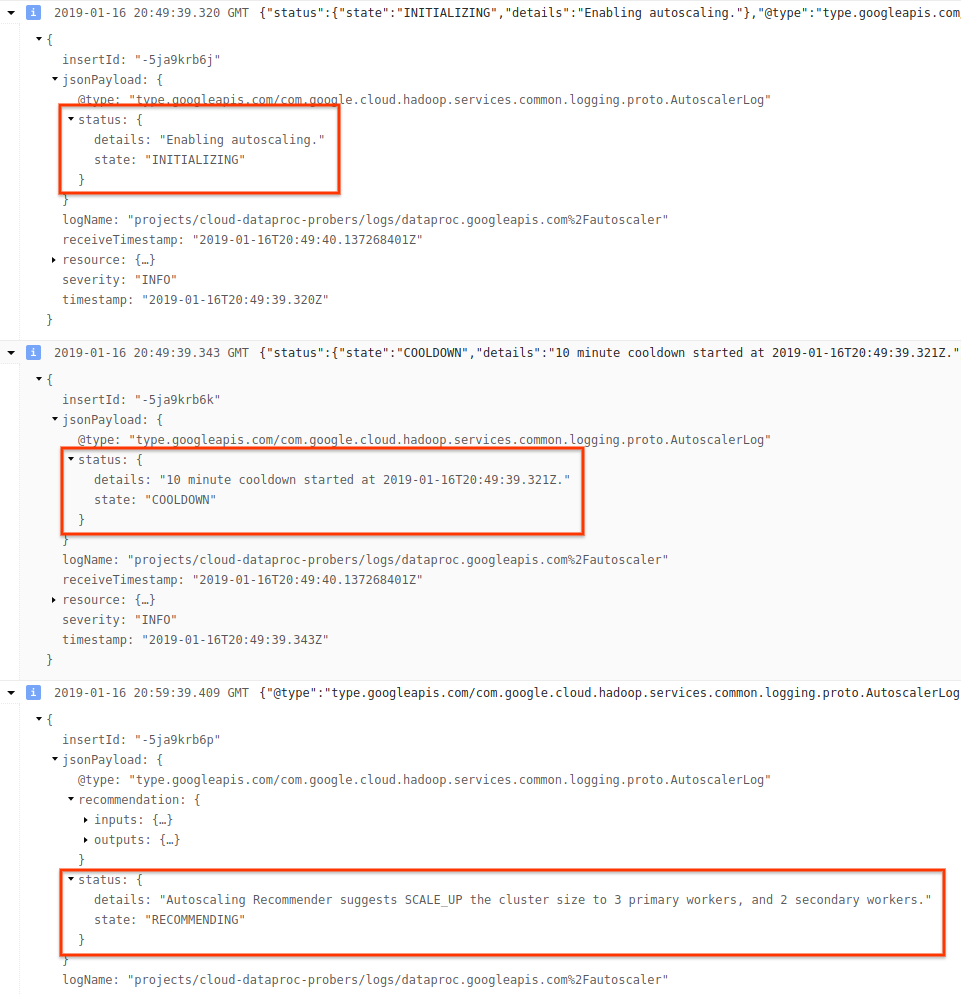
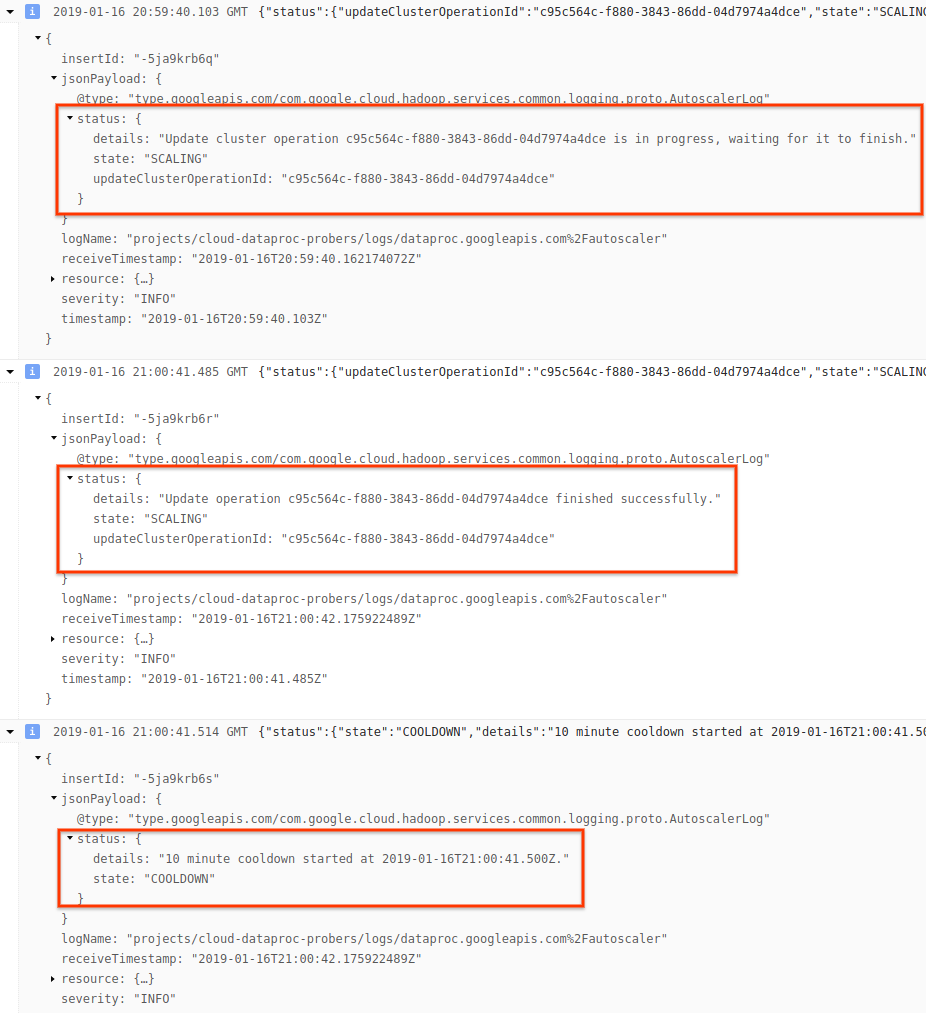
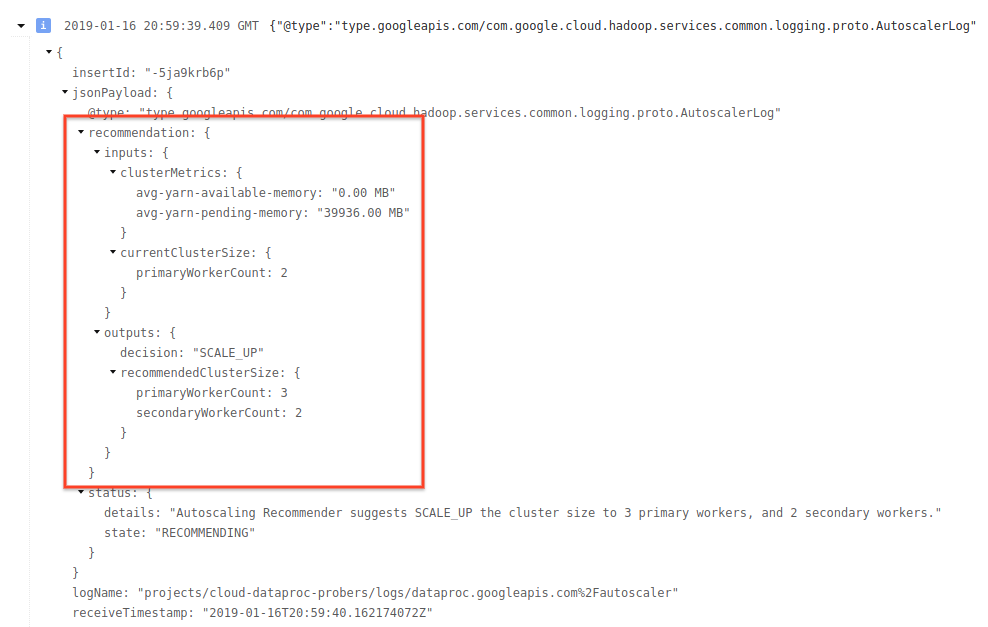
4) 展开日志消息以查看扩缩建议、用于制订扩缩决策的指标、原始集群大小和新目标集群的大小。
背景:使用 Apache Hadoop 和 Apache Spark 进行自动扩缩
以下部分介绍了自动扩缩如何与 Hadoop YARN 和 Hadoop Mapreduce、与 Apache Spark、Spark Streaming 和 Spark 结构化流进行(或不进行)互操作。
Hadoop YARN 指标
自动扩缩功能以下列 Hadoop YARN 指标为中心:
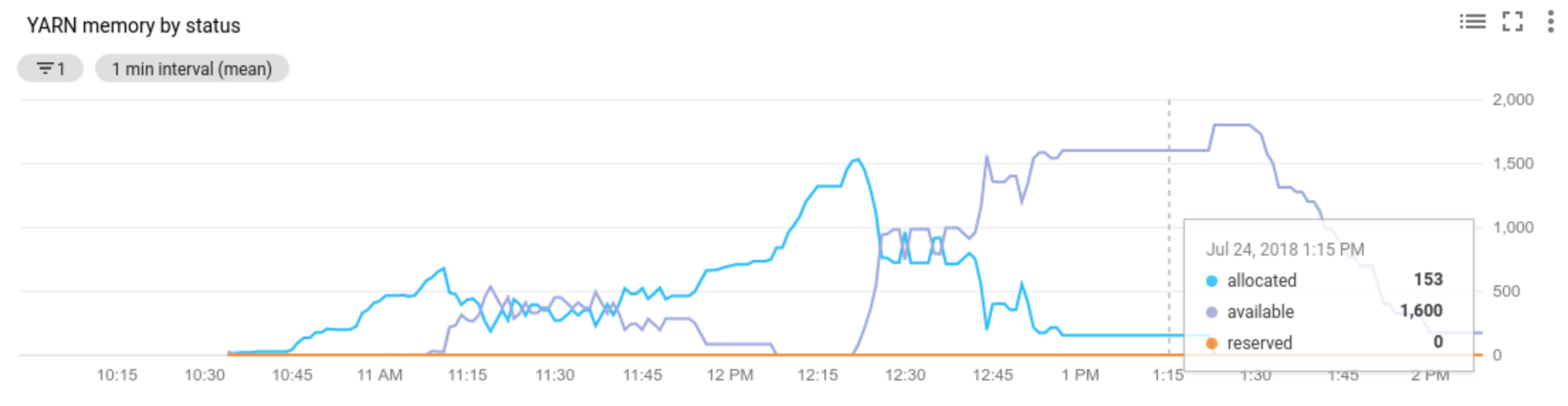
Allocated resource是指整个集群中正在运行的容器所占用的 YARN 资源总数。如果有 6 个正在运行的容器,最多可使用 1 个资源单元,则表示已分配 6 个资源。Available resource是集群中未被分配的容器使用的 YARN 资源。如果所有节点管理器中有 10 个资源单元,其中 6 个已分配,则有 4 个可用资源。如果集群中有可用(未使用)的资源,则自动扩缩可能会从集群中移除工作器。Pending resource是待处理容器的 YARN 资源请求的总和。待处理容器正在等待在 YARN 中运行空间。仅当可用资源为零或太小而无法分配给下一个容器时,待处理资源才不为零。如果存在待处理容器,则自动扩缩功能可能会将工作器添加到集群中。
您可以在 Cloud Monitoring 中查看这些指标。 默认情况下,YARN 内存将为 0.8 * 集群的总内存,而剩余的内存保留给其他守护进程和操作系统使用,例如页面缓存。您可以使用“yarn.nodemanager.resource.memory-mb” YARN 配置设置替换默认值(请参阅 Apache Hadoop YARN、HDFS、Spark 和相关属性)。
自动扩缩和 Hadoop MapReduce
MapReduce 作为单独的 YARN 容器运行每个映射和缩减任务。当作业开始时,MapReduce 会为每个映射任务提交容器请求,从而导致待处理的 YARN 内存出现大量峰值。随着映射任务的完成,待处理内存会减少。
当 mapreduce.job.reduce.slowstart.completedmaps 完成时(Dataproc 的默认设置为 95%),MapReduce 会为所有缩减器将容器请求加入队列,从而导致待处理内存再次增加。
除非您的映射任务和缩减任务需要花费几分钟或更长的时间,否则请勿为自动扩缩 scaleUpFactor 设置较高的值。将工作器添加到集群至少需要 1.5 分钟,因此请确保有足够的待处理工作能够使用新工作器几分钟。良好的起点是将 scaleUpFactor 设置为待处理内存的 0.05 (5%) 或 0.1 (10%)。
自动扩缩和 Spark
Spark 在 YARN 上额外添加了一层计划。具体来说,Spark Core 的动态分配会向 YARN 请求容器运行 Spark 执行程序,然后在这些执行程序的线程上安排 Spark 任务。Dataproc 集群默认启用动态分配,因此系统会根据需要添加和移除执行程序。
Spark 始终向 YARN 请求容器,但不进行动态分配,它仅在作业开始时请求容器。如果进行动态分配,则 Spark 会根据需要移除容器或请求新的容器。
Spark 从少量执行器开始,在自动扩缩集群上执行 2 次,并且在执行积压任务时继续将执行器的数量加倍。这将使待处理的内存(较少的待处理内存峰值)减少。对于 Spark 作业,建议将自动扩缩 scaleUpFactor 设置为较大的数字,例如 1.0 (100%)。
停用 Spark 动态分配
如果您运行的独立 Spark 作业无法从 Spark 动态分配中受益,则可以通过设置 spark.dynamicAllocation.enabled=false 和 spark.executor.instances 停用 Spark 动态分配。
当各个 Spark 作业运行时,您仍然可以使用自动扩缩来扩缩集群。
已缓存数据的 Spark 作业
当不再需要数据集时设置 spark.dynamicAllocation.cachedExecutorIdleTimeout 或释放缓存的数据集。默认情况下,Spark 不会移除已缓存数据的执行程序,这将阻止集群缩减。
自动扩缩和 Spark Streaming
由于 Spark Streaming 有自己的动态分配版本,该版本使用流式传输特有的信号来添加和移除执行器,因此请通过设置
spark.dynamicAllocation.enabled=false来设置spark.streaming.dynamicAllocation.enabled=true并停用 Spark Core 的动态分配。请勿对 Spark Streaming 作业使用安全停用(自动扩缩
gracefulDecommissionTimeout)。而是改为通过自动扩缩安全移除工作器,请配置检查点以实现容错。
或者,要在不使用自动扩缩的情况下使用 Spark Streaming:
- 停用 Spark Core 的动态分配 (
spark.dynamicAllocation.enabled=false),以及 - 设置作业的执行程序数量 (
spark.executor.instances)。请参阅集群属性。
自动扩缩和 Spark 结构化流
自动扩缩与 Spark 结构化流不兼容,因为 Spark 结构化流不支持动态分配(请参阅 SPARK-24815:结构化流应支持动态分配)。
通过分区和并行性来控制自动扩缩
虽然并行性通常由集群资源设置或确定(例如,HDFS 块数由任务数量控制),但在使用自动扩缩时反过来同样适用:即自动扩缩根据作业并行性设置工作器数量。以下指南可帮助您设置作业并行性:
- 虽然 Dataproc 根据集群的初始集群大小设置 MapReduce 缩减任务的默认数量,但您可以设置
mapreduce.job.reduces来提高缩减阶段的并行度。 - Spark SQL 和 Dataframe 并行度由
spark.sql.shuffle.partitions确定,默认值为 200。 - Spark 的 RDD 函数默认为
spark.default.parallelism,该值设置为作业启动时工作器节点上的核心数。但是,创建 shuffle 的所有 RDD 函数都采用分区数量的参数,该参数会替换spark.default.parallelism。
您应该确保数据均匀分区。如果存在明显的关键偏差,则可能有一个或多个任务花费的时间明显长于其他任务,从而导致利用率低。
自动扩缩默认的 Spark 和 Hadoop 属性设置
自动扩缩集群具有默认集群属性值,有助于在移除主要工作器或抢占辅助工作器时避免作业失败。创建具有自动扩缩功能的集群时,您可以替换这些默认值(请参阅集群属性)。
默认增加任务、应用主实例和阶段的最大重试次数:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
默认重置重试计数器(适用于长时间运行的 Spark Streaming 作业):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
默认让 Spark 的慢启动动态分配机制从较小的规模开始:
spark:spark.executor.instances=2
常见问题解答 (FAQ)
本部分包含有关自动扩缩的常见问题及解答。
可以在高可用性集群和单节点集群上启用自动扩缩吗?
您可以在高可用性集群上启用自动扩缩,但不能在单节点集群上启用(单节点集群不支持调整大小)。
可以手动调整自动扩缩集群的大小吗?
可以。在调整自动扩缩政策时,您可以决定手动调整集群的大小作为临时方案。但是,这些更改只会产生临时影响,而自动扩缩最终会缩减集群。
不考虑手动调整自动扩缩集群的大小,而是考虑:
更新自动扩缩政策。对自动扩缩政策所做的任何更改都会影响当前使用该政策的所有集群(请参阅多集群政策使用情况)。
分离政策并手动将集群扩缩为首选大小。
Dataproc 与 Dataflow 自动扩缩有何区别?
请参阅 Dataflow 横向自动扩缩和 Dataflow Prime 纵向自动扩缩。
Dataproc 开发团队能否将集群状态从 ERROR 重置回 RUNNING?
一般来说不可以。这样做需要手动操作来验证是否可以安全地重置集群的状态,通常情况下,如果不执行其他手动步骤(例如重启 HDFS NameNode),则可能无法重置集群。
如果 Dataproc 无法确定操作失败后的集群状态,它会将集群的状态设置为 ERROR。ERROR 中的集群不会自动扩缩。出现该消息的常见原因包括:
从 Compute Engine API 返回的错误,通常发生在 Compute Engine 服务中断期间。
HDFS 因 HDFS 停用出现 bug 而进入损坏状态。
Dataproc Control API 错误,例如“任务租用过期”。
删除状态为 ERROR 的集群,然后重新创建这些集群。
自动扩缩何时会取消缩容操作?
下图展示了自动扩缩何时会取消缩容操作(另请参阅自动扩缩的工作原理)。
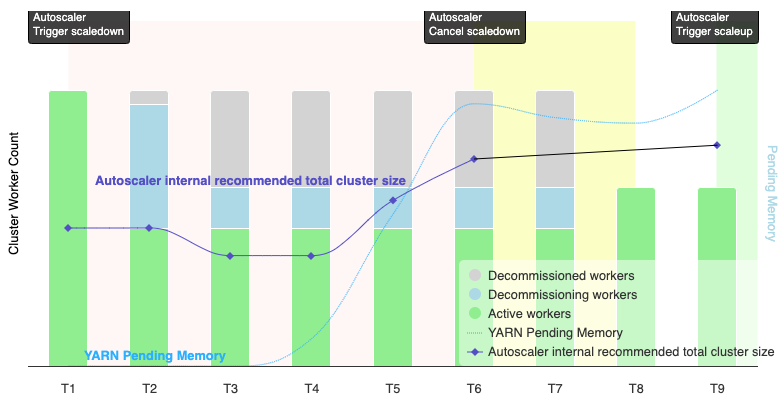
注意:
- 集群仅基于 YARN 内存指标启用了自动扩缩功能(默认情况下)。
- T1-T9 表示自动扩缩器评估工作器数量时的冷却间隔(事件时间已简化)。
- 堆叠的条形图表示活跃、正在停用和已停用的集群 YARN 工作器的数量。
- 自动扩缩器建议的工作器数量(黑线)基于 YARN 内存指标、YARN 活跃工作器数量和自动扩缩政策设置(请参阅自动扩缩的工作原理)。
- 红色背景区域表示缩容操作运行的时间段。
- 黄色背景区域表示缩容操作取消的时间段。
- 绿色背景区域表示扩容操作的期限。
以下操作会在以下时间发生:
T1:自动扩缩器启动安全停用缩容操作,以将当前集群工作器缩容大约一半。
T2:自动扩缩器继续监控集群指标。系统不会更改缩容建议,缩容操作会继续进行。部分工作器已停用,其他工作器正在停用(Dataproc 会删除已停用的工作器)。
T3:自动扩缩器计算工作器数量可以进一步缩减,可能是因为有额外的 YARN 内存可用。但是,由于活跃工作器数量加上建议的工作器数量变化不等于或大于活跃工作器数量加上正在停用的工作器数量,因此不符合缩容取消的条件,自动扩缩器不会取消缩容操作。
T4:YARN 报告待处理内存增加。不过,自动扩缩器不会更改其工作器数量建议。与 T3 一样,缩容取消条件仍未满足,自动扩缩器不会取消缩容操作。
T5:YARN 待处理内存增加,并且自动扩缩器建议的工作器数量变化增加。但是,由于活跃工作器数量加上建议的工作器数量变化小于活跃工作器数量加上正在停用的工作器数量,因此取消条件仍未满足,缩容操作不会取消。
T6:YARN 待处理内存进一步增加。活跃工作器数量加上自动扩缩器建议的工作器数量变化现在大于活跃工作器数量加上正在停用的工作器数量。满足取消条件,自动扩缩器取消缩容操作。
T7:自动扩缩器正在等待缩容操作的取消完成。自动扩缩器不会在此时间间隔内评估并建议工作器数量的变化。
T8:缩容操作的取消完成。正在停用的工作器会添加到集群并变为活跃状态。自动扩缩器检测缩容操作取消的完成,并等待下一个评估周期 (T9) 来计算建议的工作器数量。
T9:T9 时间没有任何活跃操作。根据自动扩缩器政策和 YARN 指标,自动扩缩器会建议执行扩容操作。