Qué es el ajuste de escala automático
Es difícil calcular la cantidad “adecuada” trabajadores (nodos) del clúster de una carga de trabajo, un tamaño único del clúster para toda la canalización no suele ser lo ideal. El Escalamiento de clústeres iniciado por parte del usuario aborda de forma parcial este desafío, pero requiere la supervisión del uso y la intervención manual del clúster.
La API de AutoscalingPolicies de Dataproc proporciona un mecanismo para automatizar la administración de recursos del clúster y habilitar el ajuste de escala automático de la VM de trabajador del clúster. Una Autoscaling Policy es una configuración reutilizable que describe cómo se deben escalar los trabajadores del clúster que usan la política de ajuste de escala automático. Define los límites de escalamiento, frecuencia y agresividad para proporcionar un control detallado sobre los recursos de los clústeres a lo largo de su ciclo de vida.
Cuándo usar el ajuste de escala automático
Usa el ajuste de escala automático:
en clústeres que almacenan datos en servicios externos, como Cloud Storage o BigQuery
en clústeres que procesan muchos trabajos
para escalar clústeres de un solo trabajo
con el modo de flexibilidad mejorada para los trabajos por lotes de Spark
El ajuste de escala automático no se recomienda para o con:
HDFS: El ajuste de escala automático no se diseñó para escalar HDFS en el clúster:
- El uso de HDFS no es un indicador para el ajuste de escala automático.
- Los datos HDFS solo se alojan en trabajadores principales. La cantidad de trabajadores principales debe ser suficiente para alojar todos los datos de HDFS.
- El retiro de DataNodes de HDFS puede retrasar la eliminación de trabajadores. Los nodos de datos copian los bloques de HDFS a otros nodos de datos antes de que se quite un trabajador. Según el tamaño de los datos y el factor de replicación, este proceso puede tomar horas.
Etiquetas de nodos de YARN: El ajuste de escala automático no es compatible con las etiquetas de nodos de YARN ni con la propiedad
dataproc:am.primary_onlydebido a YARN-9088. YARN informa de manera incorrecta las métricas del clúster cuando se usan etiquetas de nodo.Spark Structured Streaming: El ajuste de escala automático no es compatible con Spark Structured Streaming (consulta Ajuste de escala automático y Spark Structured Streaming).
Clústeres inactivos: No se recomienda el ajuste de escala automático para reducir el tamaño de un clúster al tamaño mínimo cuando este está inactivo. Dado que la creación de un clúster nuevo es tan rápida como cambiar el tamaño de uno, considera borrar los clústeres inactivos y volver a crearlos. Las siguientes herramientas son compatibles con este modelo “efímero”:
Usa los flujos de trabajo de Dataproc para programar un conjunto de trabajos en un clúster dedicado y, luego, borra el clúster cuando finalicen los trabajos. Para una organización más avanzada, usa Cloud Composer, que se basa en Apache Airflow.
Para clústeres que procesan consultas ad hoc o cargas de trabajo programadas externamente, usa la eliminación programada de clústeres para borrar el clúster después de un período o duración de inactividad que se especificó, o en un momento en particular.
Cargas de trabajo de diferentes tamaños: Cuando se ejecutan trabajos pequeños y grandes en un clúster, el escalamiento descendente de la baja gradual esperará a que finalicen los trabajos grandes. El resultado es que un trabajo de larga duración retrasará el ajuste de escala automático de los recursos para los trabajos más pequeños que se ejecutan en el clúster hasta que finalice el trabajo de larga duración. Para evitar este resultado, agrupa los trabajos más pequeños de tamaño similar en un clúster y aísla cada trabajo de larga duración en un clúster independiente.
Habilitar ajuste de escala automático
Para habilitar el ajuste de escala automático en un clúster, haz lo siguiente:
Realiza una de las siguientes acciones:
Crea una política de ajuste de escala automático
gcloud CLI
Puedes usar el comando gcloud dataproc autoscaling-policies import para crear una política de ajuste de escala automático. Lee un archivo local YAML que define una política de ajuste de escala automático. El formato y el contenido del archivo deben coincidir con los objetos de configuración y los campos que define la API de REST autoscalingPolicies.
En el siguiente ejemplo de YAML, se define una política para los clústeres estándar de Dataproc con todos los campos obligatorios. También proporciona los valores de minInstances y maxInstances para los trabajadores principales, el valor de maxInstances para los trabajadores secundarios (interrumpibles) y especifica un cooldownPeriod de 4 minutos (el valor predeterminado es de 2 minutos). workerConfig configura los trabajadores principales. En este ejemplo, minInstances y maxInstances se configuran con el mismo valor para evitar escalar los trabajadores principales.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
En el siguiente ejemplo de YAML, se define una política para los clústeres estándar de Dataproc, con todos los campos obligatorios y opcionales de la política de ajuste de escala automático.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
En el siguiente ejemplo de YAML, se define una política para los clústeres de escalamiento a cero.
En el caso de los clústeres con reducción de escala a cero, no incluyasworkerConfig.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Ejecuta el siguiente comando de gcloud desde una terminal local o en Cloud Shell para crear la política de ajuste de escala automático. Proporciona un nombre para la política. Este nombre se convertirá en el id de la política, que puedes usar en comandos de gcloud posteriores para hacer referencia a la política. Usa la marca --source para especificar la ruta de acceso local y el nombre de archivo del archivo YAML de la política de ajuste de escala automático que se importará.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
API de REST
Para crear una política de ajuste de escala automático, define una AutoscalingPolicy como parte de una solicitud autoscalingPolicies.create.
Console
Para crear una política de ajuste de escala automático, selecciona CREAR POLÍTICA en la página Políticas de ajuste de escala automático de Dataproc con la Google Cloud consola. En la página Crear política, puedes seleccionar un panel de recomendación de política para propagar los campos de la política de ajuste de escala automático para un tipo de trabajo o un objetivo de escalamiento específicos.
Crea un clúster de ajuste de escala automático
Después de crear una política de ajuste de escala automático, crea un clúster que use esta política. El clúster debe estar en la misma región que la política de ajuste de escala automático.
gcloud CLI
Ejecuta el siguiente comando de gcloud desde una terminal local o en Cloud Shell para crear un clúster de ajuste de escala automático. Proporciona un nombre para el clúster y usa la marca --autoscaling-policy a fin de especificar el policy ID (el nombre de la política que especificaste cuando creaste la política) o la política resource URI (resource name) (consulta los campos id y name de AutoscalingPolicy ).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API de REST
Crea un clúster de ajuste de escala automático mediante la inclusión de AutoscalingConfig como parte de una solicitud clusters.create.
Console
Puedes seleccionar una política de ajuste de escala automático existente para aplicarla a un clúster nuevo en la sección Política de ajuste de escala automático del panel Configurar clúster en la página de Dataproc.Crea un clúster de la Google Cloud consola.
Habilita el ajuste de escala automático en un clúster existente
Después de crear una política de ajuste de escala automático, puedes habilitarla en un clúster existente en la misma región.
gcloud CLI
Ejecuta el siguiente comando de gcloud desde una terminal local o en Cloud Shell a fin de habilitar una política de ajuste de escala automático en un clúster existente. Proporciona el nombre del clúster y usa la marca --autoscaling-policy para especificar el policy ID (el nombre de la política que especificaste cuando creaste la política) o la política resource URI (resource name) (consulta los campos id y name de AutoscalingPolicy).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API de REST
Para habilitar una política de ajuste de escala automático en un clúster existente, configura el AutoscalingConfig.policyUri de la política en el updateMask de una solicitud clusters.patch.
Console
La habilitación de una política de ajuste de escala automático en un clúster existente no se admite en la Google Cloud consola.
Uso de la política en varios clústeres
Una política de ajuste de escala automático define el comportamiento de escalamiento que se puede aplicar a varios clústeres. Una política de ajuste de escala automático se aplica mejor en varios clústeres cuando estos compartan cargas de trabajo similares o ejecuten trabajos con patrones de uso de recursos similares.
Puedes actualizar una política que varios clústeres usan. Las actualizaciones afectan de inmediato el comportamiento del ajuste de escala automático de todos los clústeres que usan la política (consulta autoscalingPolicies.update). Si no deseas que una actualización de la política se aplique a un clúster que usa la política, inhabilita el ajuste de escala automático en el clúster antes de actualizarla.
gcloud CLI
Ejecuta el siguiente comando de gcloud desde una terminal local o en Cloud Shell para inhabilitar el ajuste de escala automático en un clúster.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
API de REST
Para inhabilitar el ajuste de escala automático en un clúster, establece AutoscalingConfig.policyUri en la string vacía y establece update_mask=config.autoscaling_config.policy_uri en una solicitud clusters.patch.
Console
La inhabilitación del ajuste de escala automático en un clúster no es compatible con la Google Cloud consola.
- Una política usada por uno o más clústeres no se puede borrar (consulta autoscalingPolicies.delete).
Cómo funciona el ajuste de escala automático
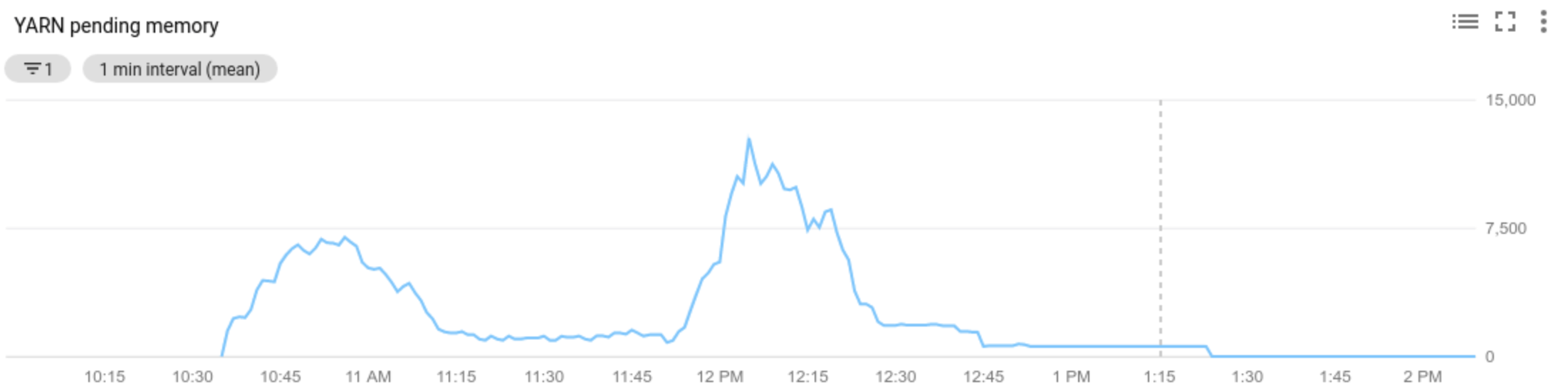
El ajuste de escala automático verifica las métricas de Hadoop YARN del clúster a medida que transcurre el período de enfriamiento para determinar si se debe escalar el clúster y, si es así, la magnitud de la actualización.
El valor de la métrica de recursos pendientes de YARN (memoria pendiente o núcleos pendientes) determina si se debe aumentar o reducir la escala. Un valor superior a
0indica que los trabajos de YARN están esperando recursos y que es posible que se requiera un aumento de la escala. Un valor de0indica que YARN tiene suficientes recursos, por lo que es posible que no se requiera una reducción o algún otro cambio.Si el recurso pendiente es > 0, haz lo siguiente:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Si el recurso pendiente es 0, ocurre lo siguiente:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
De forma predeterminada, a partir de la imagen 2.2 de Dataproc, el autoescalador supervisa la memoria y los núcleos de YARN para que
estimated_worker_countse evalúe por separado para la memoria y los núcleos, y se seleccione el recuento de trabajadores más grande resultante. En el caso de las versiones anteriores de la imagen, el escalador automático supervisa solo la memoria de YARN, a menos que habilites el ajuste de escala automático basado en núcleos.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
Dado el cambio estimado necesario en la cantidad de trabajadores, el ajuste de escala automático usa un
scaleUpFactoroscaleDownFactorpara calcular el cambio real en la cantidad de trabajadores:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
Un scaleUpFactor o scaleDownFactor de 1.0 significa que el ajuste de escala automático escalará de manera que el recurso pendiente o disponible sea 0 (uso perfecto).
Una vez que se calcula el cambio en la cantidad de trabajadores,
scaleUpMinWorkerFractionyscaleDownMinWorkerFractionactúan como un límite para determinar si el ajuste de escala automático escalará el clúster. Una fracción pequeña significa que el ajuste de escala automático debe escalar incluso si elΔworkerses pequeño. Una fracción mayor significa que el escalamiento solo debe suceder cuando elΔworkerses grande.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Si la cantidad de trabajadores a fin de escalar es bastante grande para activar el escalamiento, el ajuste de escala automático usa los límites
minInstancesymaxInstancesdeworkerConfigysecondaryWorkerConfigyweight(proporción de trabajadores principales a secundarios) a fin de determinar cómo dividir la cantidad de trabajadores en los grupos de instancias de trabajadores principales y secundarios. El resultado de estos cálculos es el cambio de ajuste de escala automático final en el clúster para el período de escalamiento.Las solicitudes de reducción del ajuste de escala automático se cancelarán en los clústeres creados con las versiones de imagen 2.0.57+, 2.1.5+ y posteriores en los siguientes casos:
- Se está realizando un ajuste a la baja con un valor de tiempo de espera de retiro de servicio ordenado distinto de cero.
La cantidad de trabajadores de YARN ACTIVOS ("trabajadores activos") más el cambio en la cantidad total de trabajadores que recomienda el ajustador automático (
Δworkers) es igual o mayor queDECOMMISSIONINGtrabajadores de YARN ("trabajadores en proceso de baja"), como se muestra en la siguiente fórmula:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Para ver un ejemplo de cancelación de reducción vertical de la escala, consulta ¿Cuándo cancela el ajuste de escala automático una operación de reducción vertical de la escala?.
Recomendaciones de configuración del ajuste de escala automático
En esta sección, se incluyen recomendaciones para ayudarte a configurar el ajuste de escala automático.
Evita escalar trabajadores principales
Los trabajadores principales ejecutan nodos de datos de HDFS, mientras que los trabajadores secundarios son solo de procesamiento.
El uso de trabajadores secundarios te permite escalar de manera eficiente los recursos de procesamiento sin necesidad de aprovisionar almacenamiento, lo que genera capacidades de escalamiento más rápidas.
Los Namenodes de HDFS pueden tener varias condiciones de carrera que hacen que HDFS se dañe, de modo que el retiro se detiene indefinidamente. Para evitar este problema, no escale los trabajadores principales. Por ejemplo: none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
Hay algunas modificaciones que se deben realizar en el comando de creación del clúster:
- Configura
--num-workers=10para que coincida con el tamaño del grupo de trabajadores principales de la política de ajuste de escala automático. - Configura
--secondary-worker-type=non-preemptiblepara configurar los trabajadores secundarios a fin de que no sean interrumpibles. A menos que se deseen las VM interrumpibles. - Copia la configuración de hardware de los trabajadores principales a los secundarios. Por ejemplo, configura
--secondary-worker-boot-disk-size=1000GBpara que coincida con--worker-boot-disk-size=1000GB.
Usa el modo de flexibilidad mejorada para los trabajos por lotes de Spark
Usa el modo de flexibilidad mejorada (EFM) con el ajuste de escala automático para hacer lo siguiente:
permite una reducción de escala más rápida del clúster mientras se ejecutan los trabajos
evitar interrupciones en los trabajos en ejecución debido a la reducción de escala del clúster
minimizar las interrupciones en los trabajos en ejecución debido a la interrupción de trabajadores secundarios interrumpibles
Con EFM habilitado, el tiempo de espera del retiro de servicio ordenado de una política de ajuste de escala automático debe establecerse en 0s. La política de ajuste de escala automático solo debe realizar un ajuste de escala automático de trabajadores secundarios.
Elige un tiempo de espera de retiro de servicio ordenado
El ajuste de escala automático admite el retiro de servicio ordenado de YARN cuando se quitan nodos de un clúster. El retiro de servicio ordenado permite que las aplicaciones terminen de reproducir aleatoriamente datos entre etapas para evitar volver a establecer la configuración el progreso del trabajo. El tiempo de espera de retiro de servicio ordenado que se proporciona en una política de ajuste de escala automático es el límite superior de duración que esperará YARN para aplicaciones en ejecución (aplicaciones que se ejecutaban cuando se inició el retiro) antes de quitar los nodos.
Cuando un proceso no se completa dentro del período de espera de baja ordenada especificado, el nodo trabajador se cierra de forma forzada, lo que puede provocar la pérdida de datos o la interrupción del servicio. Para evitar esta posibilidad, establece el tiempo de espera del retiro de servicio ordenado en un valor más largo que el trabajo más largo que procesará el clúster. Por ejemplo, si esperas que tu trabajo más largo se ejecute durante una hora, establece el tiempo de espera en al menos una hora (1h).
Considera migrar trabajos que tarden más de 1 hora en sus propios clústeres efímeros para evitar bloquear el retiro de servicio ordenado.
Configura scaleUpFactor
scaleUpFactor controla la agresividad con la que el escalador automático escala verticalmente un clúster.
Especifica un número entre 0.0 y 1.0 para establecer el valor fraccionario del recurso pendiente de YARN que provoca la adición de nodos.
Por ejemplo, si hay 100 contenedores pendientes que solicitan 512 MB cada uno, hay 50 GB de memoria YARN pendiente. Si scaleUpFactor es 0.5, el escalador automático agregará suficientes nodos para agregar 25 GB de memoria YARN. De forma similar, si es 0.1, el escalador automático agregará suficientes nodos por 5 GB. Ten en cuenta que estos valores corresponden a la memoria YARN, no a la memoria total disponible en una VM.
Un buen punto de partida es 0.05 para los trabajos de MapReduce y los trabajos de Spark con la asignación dinámica habilitada. Para los trabajos de Spark con un recuento de ejecutor fijo y trabajos de Tez, usa 1.0. Un scaleUpFactor de 1.0 significa que el ajuste de escala automático escalará de manera que el recurso pendiente o disponible sea 0 (uso perfecto).
Configura scaleDownFactor
scaleDownFactor controla la agresividad con la que el escalador automático disminuye un clúster. Especifica un número entre 0.0 y 1.0 para establecer el valor fraccionario del recurso disponible de YARN que provoca la eliminación del nodo.
Deja este valor en 1.0 para la mayoría de los clústeres de varios trabajos que necesitan escalar vertical y horizontalmente con frecuencia. Como resultado del retiro de servicio ordenado, las operaciones de reducción de la escala son mucho más lentas que las operaciones de aumento de la escala. Configurar scaleDownFactor=1.0 establece una tasa de reducción de escala agresiva, lo que minimiza la cantidad de operaciones de reducción de escala necesarias para lograr el tamaño de clúster adecuado.
En el caso de los clústeres que necesitan más estabilidad, establece un valor de scaleDownFactor más bajo para una tasa de reducción más lenta.
Establece este valor en 0.0 para evitar reducir la escala verticalmente del clúster, por ejemplo, cuando se usan clústeres efímeros o de un solo trabajo.
Configura scaleUpMinWorkerFraction y scaleDownMinWorkerFraction
scaleUpMinWorkerFraction y scaleDownMinWorkerFraction se usan con scaleUpFactor o scaleDownFactor y tienen valores predeterminados de 0.0. Representan los umbrales en los que el escalador automático aumentará o reducirá la escala del clúster: el aumento o la disminución fraccionaria mínima en el tamaño del clúster necesarios para emitir solicitudes de aumento o reducción de escala.
Ejemplos: El escalador automático no emitirá una solicitud de actualización para agregar 5 trabajadores a un clúster de 100 nodos, a menos que scaleUpMinWorkerFraction sea menor o igual que 0.05 (5%). Si se establece en 0.1, el escalador automático no emitirá la solicitud para escalar verticalmente el clúster.
Del mismo modo, si scaleDownMinWorkerFraction es 0.05, el escalador automático no quitará nodos, a menos que se deban quitar, al menos, 5 nodos.
El valor predeterminado de 0.0 significa que no hay umbral.
Se recomienda enfáticamente establecer un valor de scaleDownMinWorkerFractionthresholds más alto en clústeres grandes (más de 100 nodos) para evitar operaciones de escalamiento pequeñas y innecesarias.
Elige un período de enfriamiento
El parámetro cooldownPeriod establece un período durante el cual el escalador automático no emitirá solicitudes para cambiar el tamaño del clúster. Puedes usarlo para limitar la frecuencia de los cambios del escalador automático en el tamaño del clúster.
El cooldownPeriod mínimo y predeterminado es de dos minutos. Si se configura un cooldownPeriod más corto en una política, los cambios en la carga de trabajo afectarán más rápido el tamaño del clúster, pero los clústeres podrían escalarse verticalmente o reducirse de forma innecesaria. Se recomienda configurar el scaleUpMinWorkerFraction y scaleDownMinWorkerFraction de una política en un valor distinto de cero cuando uses un cooldownPeriod más corto. Esto garantiza que el clúster solo se escale verticalmente hacia arriba o hacia abajo cuando el cambio en el uso de recursos sea suficiente para garantizar una actualización del clúster.
Si tu carga de trabajo es sensible a los cambios en el tamaño del clúster, puedes aumentar el período de recuperación. Por ejemplo, si ejecutas un trabajo de procesamiento por lotes, puedes establecer el período de espera en 10 minutos o más. Experimenta con diferentes períodos de espera para encontrar el valor que mejor se adapte a tu carga de trabajo.
Límites de recuento de trabajadores y pesos de grupo
Cada grupo de trabajadores tiene minInstances y maxInstances que configuran un límite estricto en cuanto al tamaño de cada grupo.
Cada grupo también tiene un parámetro llamado weight que configura el balanceo de destino entre los dos grupos. Ten en cuenta que este parámetro es solo una sugerencia y, si un grupo alcanza su tamaño mínimo o máximo, los nodos solo se agregarán o quitarán del otro grupo. Por lo tanto, weight siempre se puede dejar en el valor predeterminado 1.
Usa el ajuste de escala automático basado en núcleos
En el caso de las aplicaciones que consumen mucha CPU, una práctica recomendada es usar la Calculadora de recursos dominantes para la asignación de recursos. Esta es la configuración predeterminada de YARN a partir de la versión 2.2 de la imagen de Dataproc. Con versiones anteriores de la imagen, Dataproc configura YARN para que use métricas de memoria para la asignación de recursos, a menos que establezcas la siguiente propiedad cuando crees un clúster para configurar YARN para que use la calculadora de recursos dominante:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Ajuste de escala automático de métricas y registros
Los siguientes recursos y herramientas pueden ayudarte a supervisar las operaciones de ajuste de escala automático y su efecto en tu clúster y sus trabajos.
Cloud Monitoring
Usa Cloud Monitoring para hacer lo siguiente:
- Visualizar las métricas que usa el ajuste de escala automático
- ver la cantidad de administradores de nodos en tu clúster
- comprender por qué el ajuste de escala automático escaló o no tu clúster

Cloud Logging
Usa Cloud Logging para ver los registros del escalador automático de Dataproc.
1) Busca registros para tu clúster.
2) Selecciona dataproc.googleapis.com/autoscaler.
3) Expande los mensajes del registro para ver el campo status. Los registros están en JSON, un formato procesable.
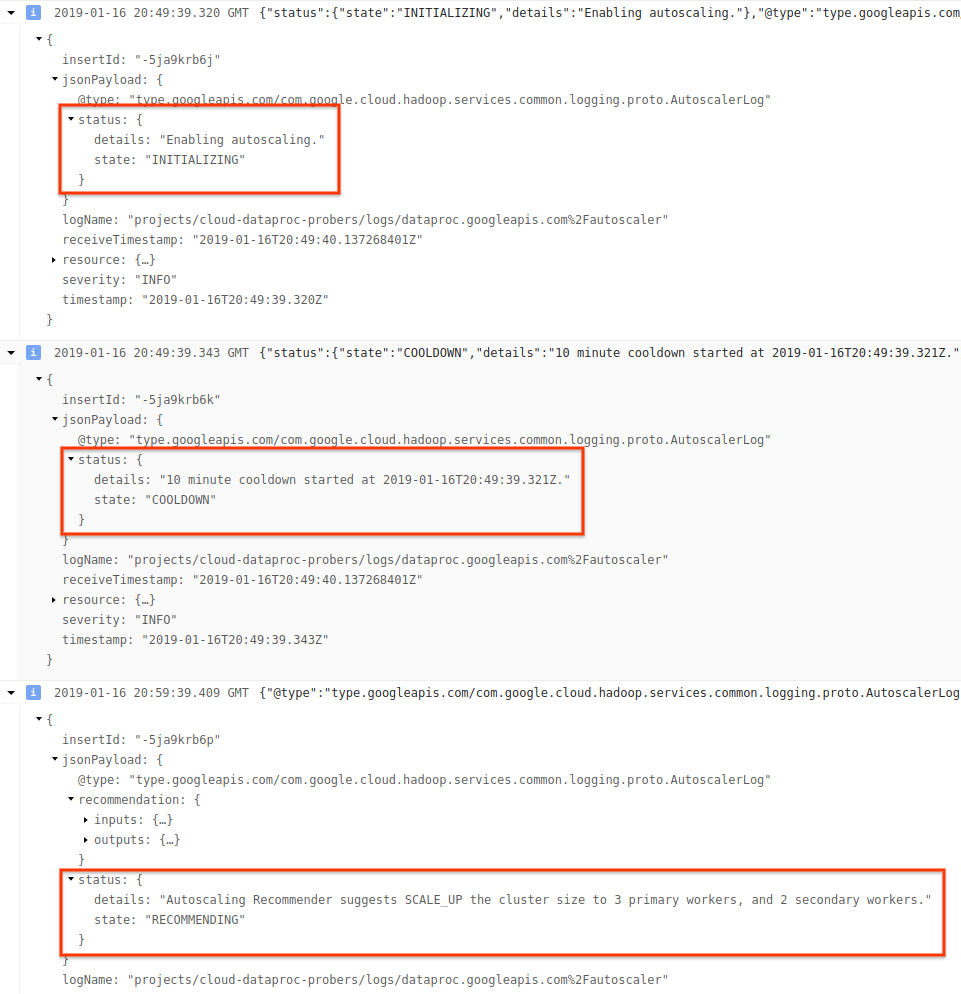
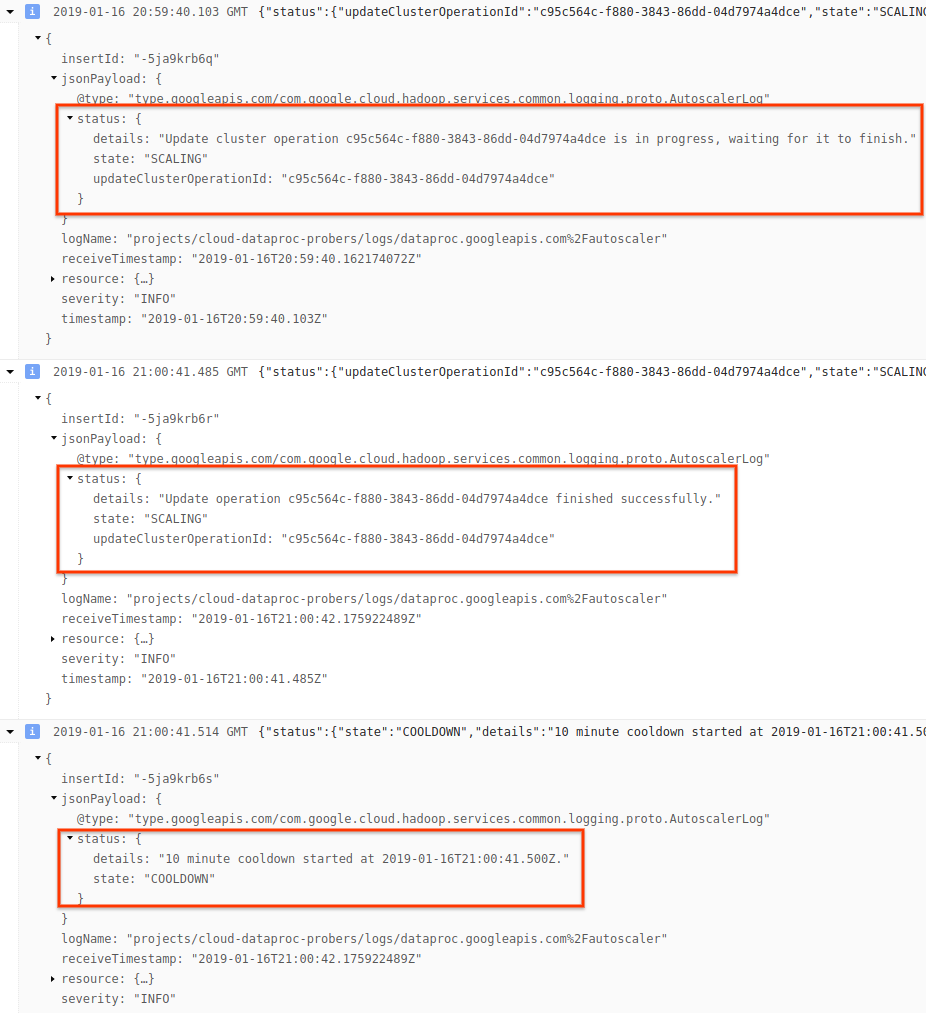
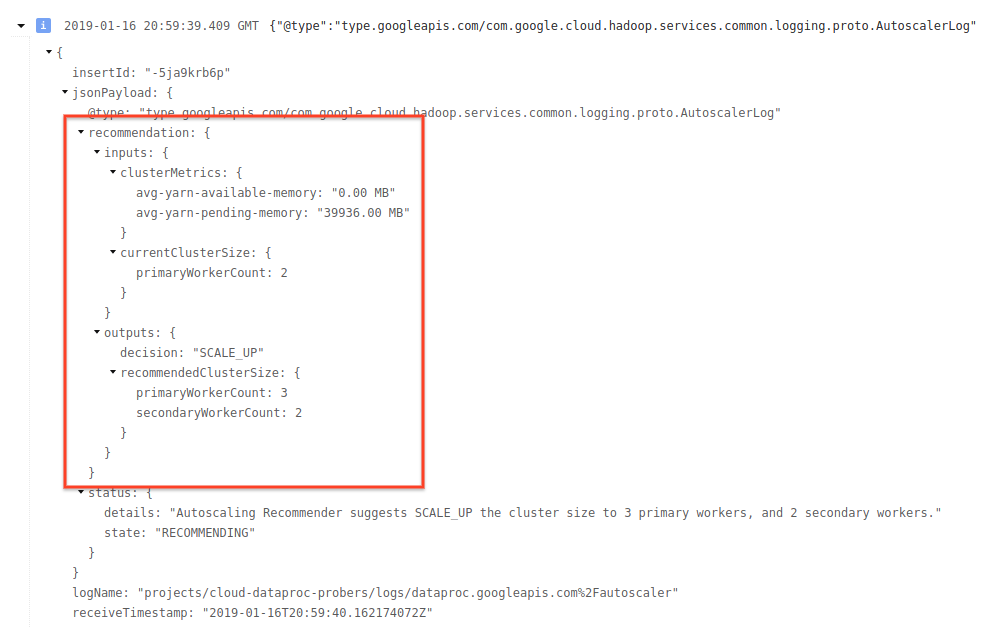
4) Expande el mensaje de registro para ver las recomendaciones de escalamiento, las métricas utilizadas a fin de tomar decisiones de escalamiento, el tamaño original del clúster y el tamaño nuevo del clúster de destino.
Segundo plano: ajuste de escala automático con Apache Hadoop y Apache Spark
En las secciones a continuación, se analiza cómo interopera el ajuste de escala automático (o no) con Hadoop YARN y Hadoop Mapreduce, y con Apache Spark, Spark Streaming y Spark Structured Streaming.
Métricas de Hadoop YARN
El ajuste de escala automático se centra en las siguientes métricas de YARN de Hadoop:
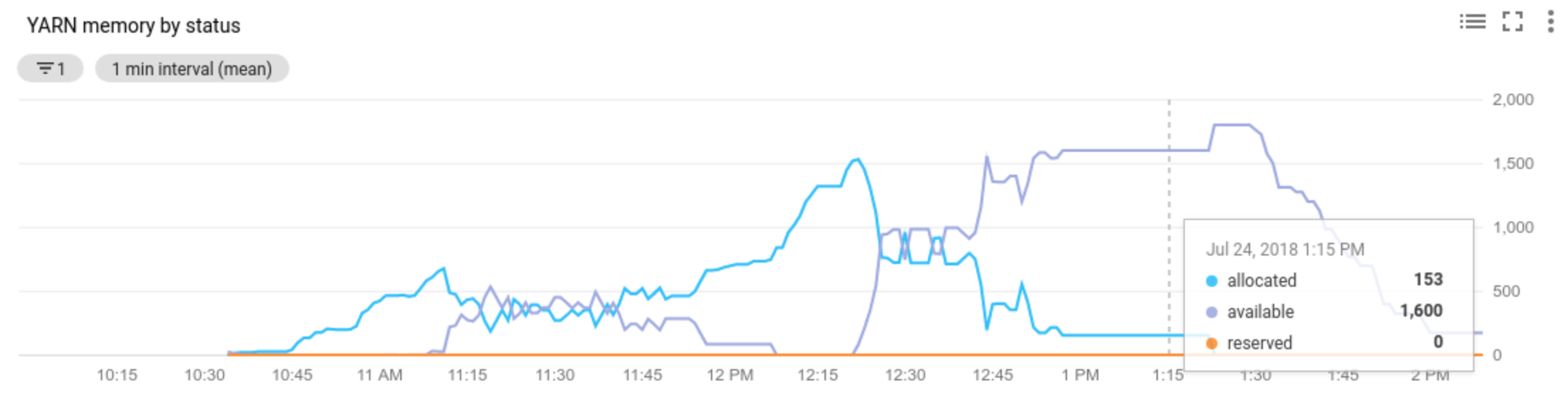
Allocated resourcese refiere al recurso total de YARN que se ocupa mediante la ejecución de contenedores en todo el clúster. Si hay 6 contenedores en ejecución que pueden usar hasta 1 unidad de recurso, hay 6 recursos asignados.Available resourcees el recurso de YARN en el clúster que no usan los contenedores asignados. Si hay 10 unidades de recursos en todos los administradores de nodos y 6 de ellas están asignadas, hay 4 recursos disponibles. Si hay recursos disponibles (sin usar) en el clúster, el ajuste de escala automático puede quitar a los trabajadores del clúster.Pending resourcees la suma de las solicitudes de recursos de YARN para los contenedores pendientes. Los contenedores pendientes esperan a que se ejecute el espacio en YARN. El recurso pendiente no es cero si el recurso disponible es cero o demasiado pequeño para asignar al siguiente contenedor. Si hay contenedores pendientes, el ajuste de escala automático puede agregar trabajadores al clúster.
Puedes ver estas métricas en Cloud Monitoring. Como configuración predeterminada, la memoria YARN será 0.8 * memoria total en el clúster, con memoria restante reservada para otros daemons y uso del sistema operativo, como la caché de la página. Puedes anular el valor predeterminado con la configuración de YARN “yarn.nodemanager.resource.memory-mb” (consulta Apache Hadoop YARN, HDFS, Spark y propiedades relacionadas).
Ajuste de escala automático y MapReduce de Hadoop
MapReduce ejecuta cada asignación y reduce la tarea como un contenedor de YARN independiente. Cuando se inicia un trabajo, MapReduce envía solicitudes de contenedor a cada tarea de asignación, lo que da como resultado un gran aumento en la memoria YARN. A medida que finalizan las tareas de asignación, la memoria pendiente disminuye.
Cuando mapreduce.job.reduce.slowstart.completedmaps se completa (el 95% de forma predeterminada en Dataproc), MapReduce agrega a la cola las solicitudes de contenedor para todos los reductores, lo que da como resultado otro aumento en la memoria pendiente.
A menos que las tareas de reducción y el mapeo tarden varios minutos o más, no establezcas un valor alto para el ajuste de escala automático scaleUpFactor. Agregar trabajadores al clúster tarda al menos 1.5 minutos, así que asegúrate de que haya suficiente trabajo pendiente para usar uno nuevo durante varios minutos. Un buen punto de partida es establecer scaleUpFactor en 0.05 (5%) o 0.1 (10%) de memoria pendiente.
Ajuste de escala automático y Spark
Spark agrega una capa adicional de programación sobre YARN. En particular, la asignación dinámica de Spark Core realiza solicitudes a YARN para contenedores que ejecuten los ejecutores de Spark y, luego, programa las tareas de Spark en los subprocesos de esos ejecutores. Los clústeres de Dataproc habilitan la asignación dinámica de forma predeterminada, por lo que los ejecutores se agregan y quitan según sea necesario.
Spark siempre solicita YARN para contenedores, pero sin la asignación dinámica, solo requiere contenedores al comienzo del trabajo. Con la asignación dinámica, quitará contenedores o solicitará nuevos, según sea necesario.
Spark comienza desde una pequeña cantidad de ejecutores (2 en clústeres de ajuste de escala automático) y continúa duplicando la cantidad de ejecutores mientras hay tareas pendientes.
Esto reduce la memoria pendiente (menos aumentos repentinos de memoria pendiente). Se recomienda configurar el ajuste de escala automático scaleUpFactor en un número mayor, como 1.0 (100%), para los trabajos de Spark.
Inhabilita la asignación dinámica de Spark
Si ejecutas trabajos de Spark independientes que no se benefician de la asignación dinámica de Spark, puedes inhabilitar spark.dynamicAllocation.enabled=false y configurar spark.executor.instances.
Aún puedes usar el ajuste de escala automático para aumentar o reducir el escalamiento de los clústeres mientras se ejecutan los trabajos de Spark independientes.
Trabajos de Spark con datos almacenados en caché
Configura spark.dynamicAllocation.cachedExecutorIdleTimeout o los conjuntos de datos que no están almacenados en caché cuando ya no sean necesarios. De forma predeterminada, Spark no quita los ejecutores que tienen datos almacenados en caché, lo que evitaría disminuir la escala del clúster.
Ajuste de escala automático y transmisión de Spark
Dado que Spark Streaming tiene su propia versión de asignación dinámica que usa señales específicas de transmisión para agregar y quitar ejecutores, debes configurar
spark.streaming.dynamicAllocation.enabled=truee inhabilitar la asignación dinámica de Spark Core configurandospark.dynamicAllocation.enabled=false.No uses el retiro de servicio ordenado (ajuste de escala automático de
gracefulDecommissionTimeout) con trabajos de Spark Streaming. En su lugar, para quitar trabajadores de forma segura con el ajuste de escala automático, configura el punto de control para obtener la tolerancia a errores.
Como alternativa, para usar Spark Streaming sin ajuste de escala automático, haz lo siguiente:
- Inhabilita la asignación dinámica de Spark Core (
spark.dynamicAllocation.enabled=false) - Configura la cantidad de ejecutores (
spark.executor.instances) de tu trabajo. Consulta Propiedades del clúster.
Ajuste de escala automático y Spark Structured Streaming
El ajuste de escala automático no es compatible con Spark Structured Streaming porque este no admite la asignación dinámica (consulta SPARK-24815: Structured Streaming debe admitir la asignación dinámica).
Controla el ajuste de escala automático a través de particiones y paralelismo
Si bien el paralelismo suele establecerse o determinarse en función de los recursos del clúster (por ejemplo, la cantidad de bloques de HDFS controla la cantidad de tareas), con el ajuste de escala automático sucede lo contrario: el ajuste de escala automático establece la cantidad de trabajadores según el paralelismo de trabajo. A continuación, se incluyen lineamientos que te ayudarán a configurar el paralelismo de trabajos:
- Si bien Dataproc establece la cantidad predeterminada de MapReduce, reduce las tareas según el tamaño inicial del clúster de tu clúster, puedes configurar
mapreduce.job.reducespara aumentar el paralelismo de la fase de reducción. - El paralelismo de Spark SQL y Dataframe está determinado por
spark.sql.shuffle.partitions, que se establece de forma predeterminada en 200. - El valor predeterminado de las funciones RDD de Spark es
spark.default.parallelism, que se establece en la cantidad de núcleos en los nodos trabajadores cuando se inicia el trabajo. Sin embargo, todas las funciones de RDD que crean reproducciones aleatorias toman un parámetro para la cantidad de particiones, que anulaspark.default.parallelism.
Debes asegurarte de que tus datos estén particionados de forma uniforme. Si existe una desviación significativa de la clave, una o más tareas pueden tardar mucho más tiempo que otras, lo que genera un uso bajo.
Ajuste de escala automático de la configuración predeterminada de las propiedades de Spark y Hadoop
Los clústeres de ajuste de escala automático tienen valores de propiedad de clúster predeterminados que ayudan a evitar fallas de trabajo cuando se quitan los trabajadores principales o se interrumpen los trabajadores secundarios. Puedes anular estos valores predeterminados cuando creas un clúster con ajuste de escala automático (consulta Propiedades del clúster).
Parámetros predeterminados de configuración para aumentar la cantidad máxima de reintentos de tareas, instancias principales y etapas:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Parámetros predeterminados de configuración para restablecer los contadores de reintentos (útil para trabajos de Spark Streaming de larga duración):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Configuración predeterminada para que el mecanismo de asignación dinámica de inicio lento de Spark comience desde un tamaño pequeño:
spark:spark.executor.instances=2
Preguntas frecuentes
En esta sección, se incluyen preguntas y respuestas frecuentes sobre el ajuste de escala automático.
¿Se puede habilitar el ajuste de escala automático en clústeres de alta disponibilidad y de un solo nodo?
El ajuste de escala automático se puede habilitar en clústeres de alta disponibilidad, pero no en clústeres de un solo nodo (los clústeres de un solo nodo no admiten el cambio de tamaño).
¿Puedes cambiar el tamaño de un clúster de ajuste de escala automático de forma manual?
Sí. Puedes decidir cambiar el tamaño de un clúster de forma manual como una medida de detención cuando se modifica una política de ajuste de escala automático. Sin embargo, estos cambios solo tendrán un efecto temporal, y el ajuste de escala automático escalará el clúster luego.
En lugar de cambiar el tamaño de un clúster de ajuste de escala automático de forma manual, considera lo siguiente:
Actualiza la política de ajuste de escala automático Cualquier cambio que se realice en la política de ajuste de escala automático afectará a todos los clústeres que usen la política en este momento (consulta Uso de la política en varios clústeres).
Desconecta la política y escala de forma manual el clúster hasta alcanzar el tamaño preferido.
¿En qué se diferencia Dataproc del ajuste de escala automático de Dataflow?
Consulta Ajuste de escala automático horizontal de Dataflow y Ajuste de escala automático vertical de Dataflow Prime.
¿El equipo de desarrollo de Dataproc puede restablecer el estado del clúster de ERROR a RUNNING?
En general, no. Esto requiere un esfuerzo manual para verificar si es seguro restablecer el estado del clúster y, a menudo, un clúster no se puede restablecer sin otros pasos manuales, como reiniciar el NameNode de HDFS.
Dataproc establece el estado de un clúster en ERROR cuando no puede determinar el estado de un clúster después de una operación con errores. Los clústeres en ERROR no tienen ajuste de escala automático. Entre las causas comunes, se incluyen las siguientes:
Errores que se muestran desde la API de Compute Engine, a menudo durante las interrupciones de Compute Engine.
HDFS entra en un estado dañado debido a errores en HDFS fuera de servicio.
Errores de la API de Control de Dataproc, como “Venció la asignación de tiempo de tareas”.
Borra y vuelve a crear los clústeres cuyo estado es ERROR.
¿Cuándo cancela el ajuste de escala automático una operación de reducción de escala?
El siguiente gráfico es una ilustración que muestra cuándo el ajuste de escala automático cancelará una operación de reducción de escala (consulta también Cómo funciona el ajuste de escala automático).
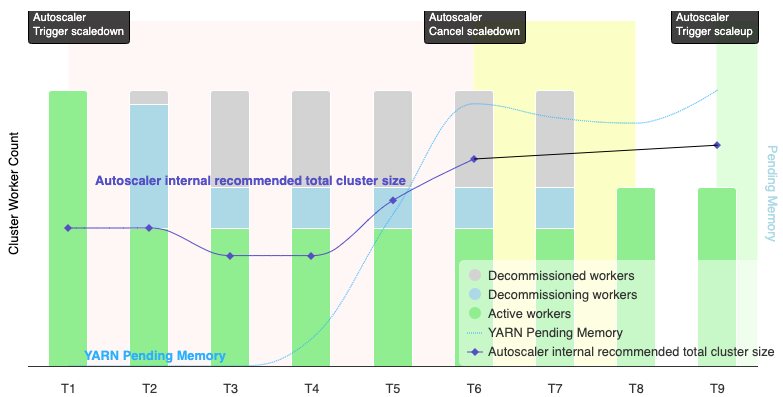
Notas:
- El clúster tiene habilitado el ajuste de escala automático basado solo en las métricas de memoria de YARN (opción predeterminada).
- T1 a T9 representan intervalos de enfriamiento en los que el escalador automático evalúa la cantidad de trabajadores (se simplificó la sincronización de eventos).
- Las barras apiladas representan los recuentos de trabajadores de YARN del clúster activos, en proceso de baja y dados de baja.
- La cantidad recomendada de trabajadores del escalador automático (línea negra) se basa en las métricas de memoria de YARN, el recuento de trabajadores activos de YARN y la configuración de la política de ajuste de escala automático (consulta Cómo funciona el ajuste de escala automático).
- El área de fondo roja indica el período durante el que se ejecuta la operación de reducción.
- El área de fondo amarilla indica el período durante el cual se cancela la operación de reducción.
- El área de fondo verde indica el período de la operación de expansión.
Las siguientes operaciones ocurren en los siguientes momentos:
T1: El escalador automático inicia una operación de reducción de escala de retiro de servicio ordenado para reducir la escala de aproximadamente la mitad de los trabajadores del clúster actuales.
T2: El escalador automático sigue supervisando las métricas del clúster. No cambia su recomendación de reducción y la operación de reducción continúa. Algunos trabajadores se retiraron del servicio y otros se están retirando (Dataproc borrará los trabajadores retirados del servicio).
T3: El escalador automático calcula que la cantidad de trabajadores se puede reducir aún más, posiblemente debido a que hay más memoria de YARN disponible. Sin embargo, dado que la cantidad de trabajadores activos más el cambio recomendado en la cantidad de trabajadores no es igual ni mayor que la cantidad de trabajadores activos más los que se dan de baja, no se cumplen los criterios para cancelar la reducción vertical de la escala, y el escalador automático no cancela la operación de reducción vertical de la escala.
T4: YARN informa un aumento en la memoria pendiente. Sin embargo, el escalador automático no cambia su recomendación de cantidad de trabajadores. Al igual que en T3, no se cumplen los criterios de cancelación de la reducción vertical de la escala, y el escalador automático no cancela la operación de reducción vertical de la escala.
T5: Aumenta la memoria pendiente de YARN y aumenta el cambio en la cantidad de trabajadores que recomienda el ajustador de escala automático. Sin embargo, dado que la cantidad de trabajadores activos más el cambio recomendado en la cantidad de trabajadores es menor que la cantidad de trabajadores activos más los trabajadores que se dan de baja, no se cumplen los criterios de cancelación y no se cancela la operación de reducción.
T6: La memoria pendiente de YARN aumenta aún más. La cantidad de trabajadores activos más el cambio en la cantidad de trabajadores que recomienda el ajustador automático ahora es mayor que la cantidad de trabajadores activos más los trabajadores que se dan de baja. Se cumplen los criterios de cancelación y el escalador automático cancela la operación de reducción de escala.
T7: El escalador automático está esperando que se complete la cancelación de la operación de reducción. Durante este intervalo, el escalador automático no evalúa ni recomienda un cambio en la cantidad de trabajadores.
T8: Se completa la cancelación de la operación de reducción. Los trabajadores dados de baja se agregan al clúster y se activan. El escalador automático detecta la finalización de la cancelación de la operación de reducción de escala y espera el próximo período de evaluación (T9) para calcular la cantidad recomendada de trabajadores.
T9: No hay operaciones activas en el horario de T9. Según la política del escalador automático y las métricas de YARN, el escalador automático recomienda una operación de ajuste de escala vertical.