Les clusters Dataproc sont construits à partir d'instances Compute Engine. Les types de machines définissent les ressources matérielles virtualisées disponibles pour une instance. Compute Engine propose à la fois des types de machines prédéfinis et des types de machines personnalisés. Les clusters Dataproc peuvent utiliser aussi bien des types prédéfinis que des types personnalisés, et ce, pour le nœud maître et les nœuds de calcul.
Les clusters Dataproc sont compatibles avec les types de machines Compute Engine prédéfinis suivants (la disponibilité des types de machines varie selon la région) :
- Types de machines à usage général, y compris les types de machines N1, N2, N2D, E2, C3, C4 et N4 (Dataproc est également compatible avec les types de machines personnalisés N1, N2, N2D, E2, C3, C4 et N4).
Limites :
- Type de machine n1-standard-1 non compatible pour les images 2.0+ (le type de machine n1-standard-1 n'est pas recommandé pour les images antérieures à 2.0 : utilisez plutôt un type de machine avec une mémoire plus élevée).
- Les types de machines à cœur partagé ne sont pas compatibles. Voici les types de machines non compatibles :
- Types de machines à cœur partagé E2 : e2-micro, e2-small et e2-medium
- Types de machines à cœur partagé N1 : f1-micro et g1-small
- Dataproc sélectionne
hyperdisk-balancedcomme type de disque de démarrage si le type de machine est C4 ou N4.
- Types de machines optimisés pour le calcul, y compris les types de machines C2 et C2D
- Types de machines à mémoire optimisée, y compris les types de machines M1 et M2
- Types de machines ARM, y compris les types de machines C4A.
Types de machines personnalisés
Dataproc est compatible avec les types de machines personnalisés de la série N1.
Les types de machines personnalisés conviennent parfaitement aux charges de travail suivantes :
- Les charges de travail qui ne conviennent pas aux types de machines prédéfinis
- Charges de travail qui nécessitent davantage de puissance de traitement ou de mémoire, sans pour autant nécessiter toutes les mises à niveau fournies par le type de machine de niveau supérieur
Par exemple, supposons que votre charge de travail nécessite plus de puissance de traitement que celle fournie par une instance n1-standard-4, mais que l'instance de niveau immédiatement supérieur, n1-standard-8, fournisse une capacité trop importante. Avec les types de machines personnalisés, vous pouvez créer des clusters Dataproc avec des nœuds maîtres et/ou des nœuds de calcul entre ces deux niveaux, avec 6 processeurs virtuels et 25 Go de mémoire.
Spécifier un type de machine personnalisé
Les types de machines personnalisés utilisent une spécification machine type spéciale et sont soumis à des limitations. Par exemple, la spécification de type de machine personnalisé pour une VM personnalisée avec six processeurs virtuels et 22,5 Go de mémoire est custom-6-23040.
Dans la spécification de type de machine, les nombres correspondent au nombre de processeurs virtuels dans la machine (6) et à la quantité de mémoire (23040). Celle-ci est calculée. en multipliant la quantité de mémoire en gigaoctets par 1024. (Pour plus d'informations, consultez la section Exprimer la mémoire en Go ou Mo.) Dans cet exemple, 22,5 (Go) est multiplié par 1 024 : 22.5 * 1024 = 23040.
Vous pouvez utiliser la syntaxe ci-dessus pour spécifier le type de machine personnalisé de vos clusters. Lorsque vous créez un cluster, vous pouvez définir le type de machine pour le nœud maître et/ou pour les nœuds de calcul. Le nœud maître peut utiliser un type de machine personnalisé différent de celui utilisé par les nœuds de calcul. Le type de machine utilisé par tous les nœuds de calcul secondaires est identique à celui des nœuds de calcul primaires et ne peut pas être défini séparément. (Pour plus d'informations, consultez la page Nœuds de calcul secondaires : VM préemptives et non préemptives).
Tarifs des types de machines personnalisés
La tarification des types de machines personnalisés est basée sur les ressources utilisées dans la machine personnalisée. Les tarifs de Dataproc sont ajoutés au coût des ressources de calcul et sont basés sur le nombre total de processeurs virtuels utilisés dans le cluster.
Créer un cluster Dataproc avec un type de machine spécifié
Console
Dans le panneau Configurer des nœuds de la page Dataproc Créer un cluster dans la console Google Cloud , sélectionnez la famille de machines, la série et le type des nœuds maîtres et de calcul du cluster.
Commande gcloud
Exécutez la commande gcloud dataproc clusters create avec les options suivantes pour créer un cluster Dataproc en spécifiant les types de machines du nœud maître et/ou des nœuds de calcul :
- L'option
--master-machine-type machine-typepermet de définir le type de machine prédéfini ou personnalisé utilisé par l'instance de VM maître dans votre cluster (ou les instances maîtres si vous créez un cluster à haute disponibilité). - L'option
--worker-machine-type custom-machine-typepermet de définir le type de machine prédéfini ou personnalisé utilisé par les instances de VM de calcul dans votre cluster.
Exemple :
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other args
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
API REST
Pour créer un cluster avec des types de machines personnalisés, définissez machineTypeUri dans masterConfig et/ou workerConfig InstanceGroupConfig dans la requête API cluster.create.
Exemple :
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
Créer un cluster Dataproc avec un type de machine personnalisé et une extension de mémoire
Dataproc accepte les types de machines personnalisés avec extension de mémoire au-delà de la limite de 6,5 Go par processeur virtuel. (Pour plus d'informations, consultez les tarif des extensions de mémoire).
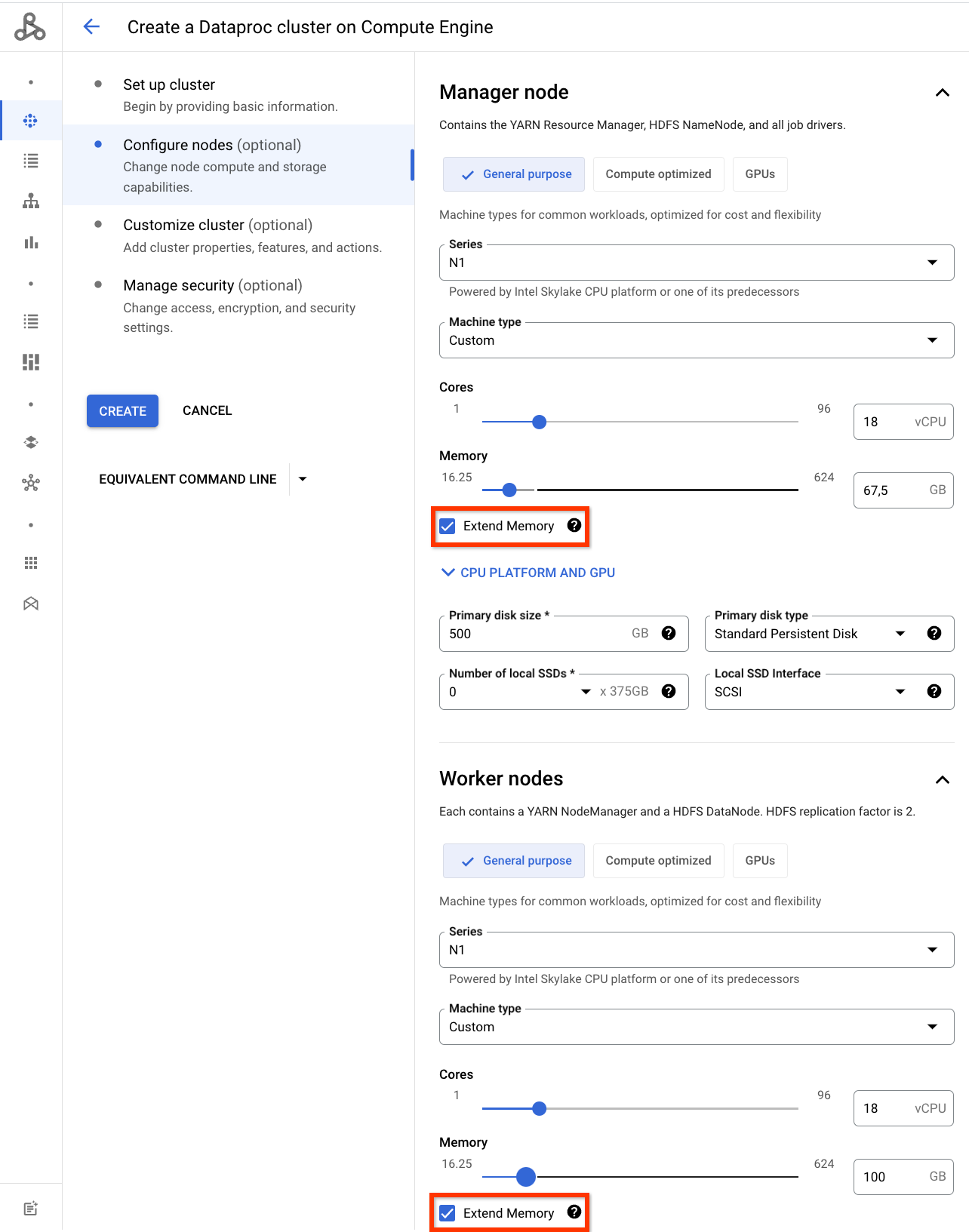
Console
Cliquez sur Plus de mémoire lorsque vous personnalisez la mémoire du type de machine dans la section "Nœud maître" et/ou "Nœuds de calcul" du panneau Configurer des nœuds de la page Dataproc Créer un cluster dans la console Google Cloud .
Commande gcloud
Pour créer un cluster à partir de la ligne de commande gcloud, qui comporte des processeurs personnalisés avec une extension de mémoire, ajoutez un suffixe -ext aux options ‑‑master-machine-type et/ou ‑‑worker-machine-type.
Exemple
L'exemple de ligne de commande gcloud suivant crée un cluster Dataproc avec un processeur et 50 Go de mémoire (50 * 1 024 = 51 200) pour chaque nœud :
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
API
L'extrait de code JSON <code.instancegroupconfig< code="" dir="ltr" translate="no"></code.instancegroupconfig<> suivant, provenant d'une requête clusters.create de l'API REST Dataproc, spécifie un processeur et 50 Go de mémoire (50 * 1 024 = 51 200) pour chaque nœud :
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
Types de machines ARM
Dataproc permet de créer un cluster avec des nœuds qui utilisent des types de machines ARM, tels que le type de machine C4A.
Conditions requises et limites :
- L'image Dataproc doit être compatible avec le chipset ARM.
Les images Dataproc
2.1-ubuntu20-arm,2.2-ubuntu22-armet2.3-ubuntu22-arm(et les images ultérieures avec le suffixe-arm) sont compatibles avec le chipset ARM. Les images compatibles avec ARM ne sont pas compatibles avec de nombreux composants optionnels et d'actions d'initialisation, comme indiqué sur les pages des versions des images. - Étant donné qu'une image doit être spécifiée pour un cluster, les nœuds maître, de calcul et de calcul secondaire doivent utiliser un type de machine ARM compatible avec l'image ARM Dataproc sélectionnée.
- Les fonctionnalités Dataproc qui ne sont pas compatibles avec les types de machines ARM ne sont pas disponibles (par exemple, les SSD locaux ne sont pas compatibles avec les types de machines C4A).
- Les images ARM ne sont compatibles qu'avec les composants préinstallés et un ensemble limité de composants facultatifs. Les autres composants facultatifs et toutes les actions d'initialisation ne sont pas acceptés.
Créer un cluster Dataproc avec un type de machine ARM
Console
Actuellement, la console Google Cloud ne permet pas de créer un cluster de type de machine ARM Dataproc.
gcloud
Pour créer un cluster Dataproc qui utilise le type de machine ARM c4a-standard-4, exécutez la commande gcloud suivante en local dans une fenêtre de terminal ou dans Cloud Shell.
gcloud dataproc clusters create cluster-name \ --region=REGION \ --image-version=2.1-ubuntu20-arm \ --master-machine-type=c4a-standard-4 \ --worker-machine-type=c4a-standard-4
Remarques :
REGION : région dans laquelle se trouvera le cluster.
Les images ARM sont disponibles à partir de
2.1.18-ubuntu20-arm,2.2.61-ubuntu22-armet2.3.7-ubuntu22-arm.Pour en savoir plus sur les autres indicateurs de ligne de commande que vous pouvez utiliser pour personnaliser votre cluster, consultez la documentation de référence sur gcloud dataproc clusters create.
Les images
*-armne sont compatibles qu'avec les composants préinstallés et les composants optionnels suivants listés dans les versions 2.1.x, 2.2.x et 2.3.x. Les autres composants facultatifs 2.1, 2.2 et 2.3, ainsi que toutes les actions d'initialisation listées, ne sont pas compatibles :- Apache Hive WebHCat
- Docker
- Zeppelin
- Zookeeper (installé dans les clusters à haute disponibilité ; composant facultatif dans les clusters non haute disponibilité)
API
L'exemple de requête clusters.create de l'API REST Dataproc suivant crée un cluster de type de machine ARM.
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "sample-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"softwareConfig": {
"imageVersion": "2.1-ubuntu20-arm"
}
}
}
Étapes suivantes
- En savoir plus sur les VM Arm sur Compute
- Découvrez comment créer une VM avec un type de machine personnalisé.
- Découvrez comment créer et démarrer une instance Compute Engine.