In den folgenden Beispielen wird ein Dataproc-Cluster mit Kerberos-aktivierten Dataproc-Clustern mit Ranger- und Solr-Komponenten erstellt und verwendet, um den Zugriff von Nutzern auf Hadoop-, YARN- und HIVE-Ressourcen zu steuern.
Hinweise:
Auf die Ranger-Web-UI kann über das Component Gateway zugegriffen werden.
In einem Ranger mit Kerberos-Cluster ordnet Dataproc dem Systemnutzer einen Kerberos-Nutzer zu. Dazu entfernt er den Bereich des Kerberos-Nutzers und die Instanz. Der Kerberos-Prinzipal
user1/cluster-m@MY.REALMist beispielsweise dem Systemuser1zugeordnet und Ranger-Richtlinien sind so definiert, dass Berechtigungen füruser1zugelassen oder verweigert werden.
Erstellen Sie den Cluster.
- Der folgende
gcloud-Befehl kann in einem lokalen Terminalfenster oder in der Cloud Shell eines Projekts ausgeführt werden.gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- Der folgende
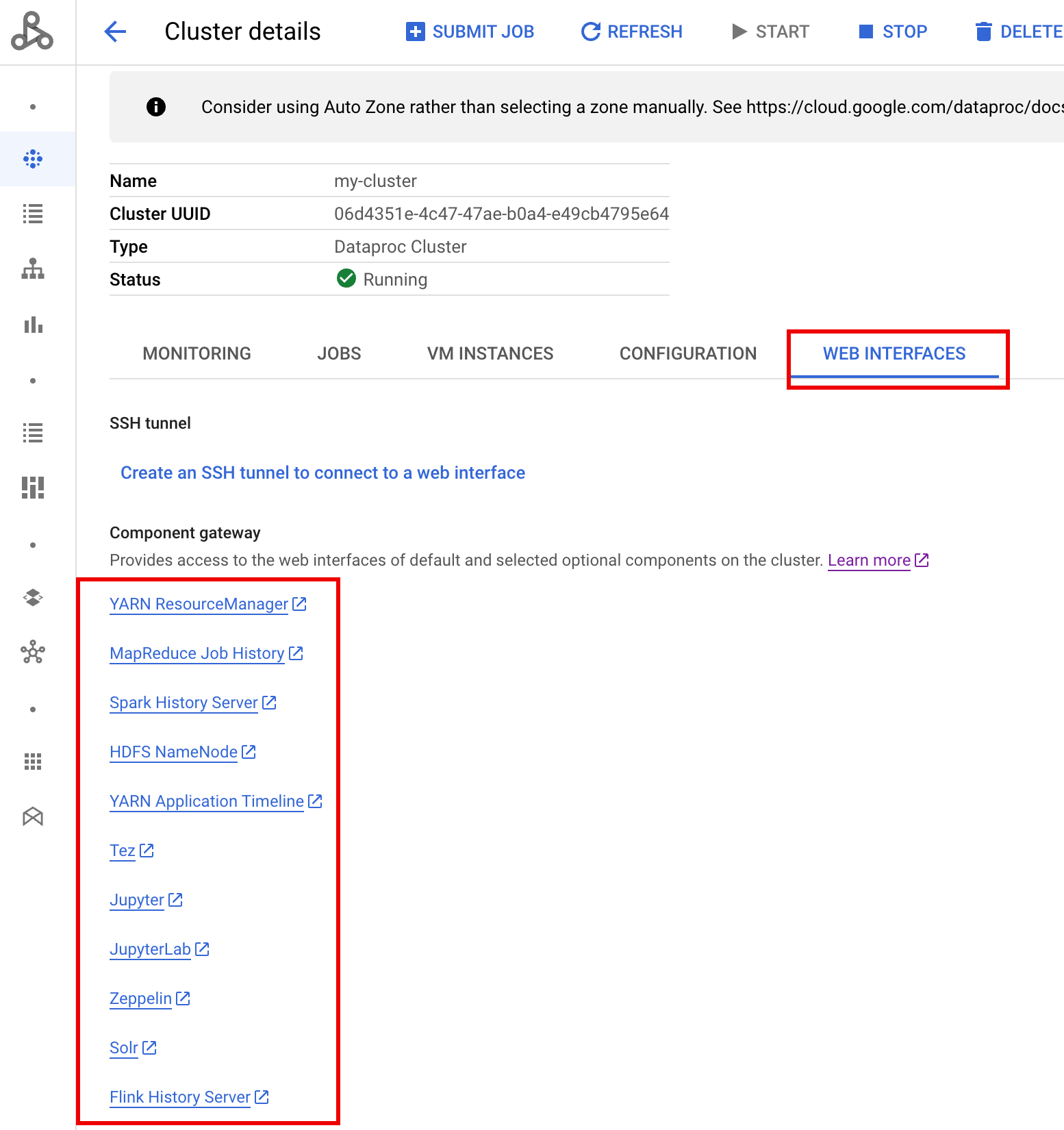
Nachdem der Cluster ausgeführt wurde, rufen Sie in der Google Cloud Console die Dataproc-Seite Cluster auf und wählen Sie den Namen des Clusters aus, um die Seite Clusterdetails zu öffnen. Klicken Sie auf den Tab Weboberflächen, um eine Liste der Component Gateway-Links zu den Weboberflächen der im Cluster installierten Standardkomponenten und optionalen Komponenten zu öffnen. Klicken Sie auf den Ranger-Link.
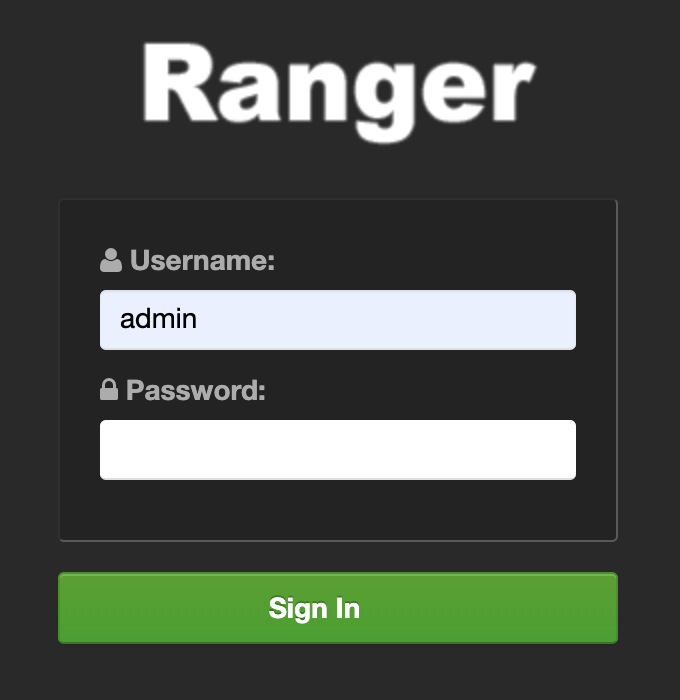
Melden Sie sich bei Ranger an, indem Sie den "Administrator"-Nutzernamen und das Ranger-Administratorpasswort eingeben.
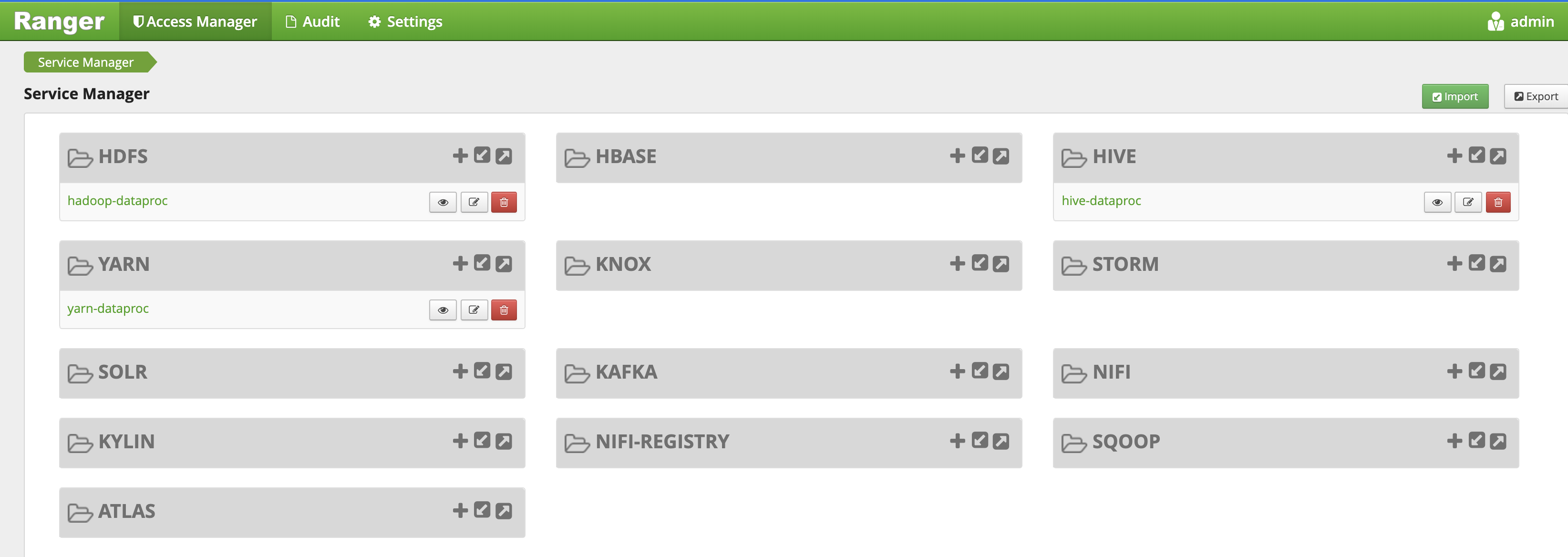
Die Ranger Admin-Benutzeroberfläche wird in einem lokalen Browser geöffnet.
YARN-Zugriffsrichtlinie
In diesem Beispiel wird eine Ranger-Richtlinie erstellt, um den Nutzerzugriff auf die YARN root.default-Warteschlange zuzulassen bzw. zu verweigern.
Wählen Sie in der Ranger Admin-Benutzeroberfläche
yarn-dataprocaus.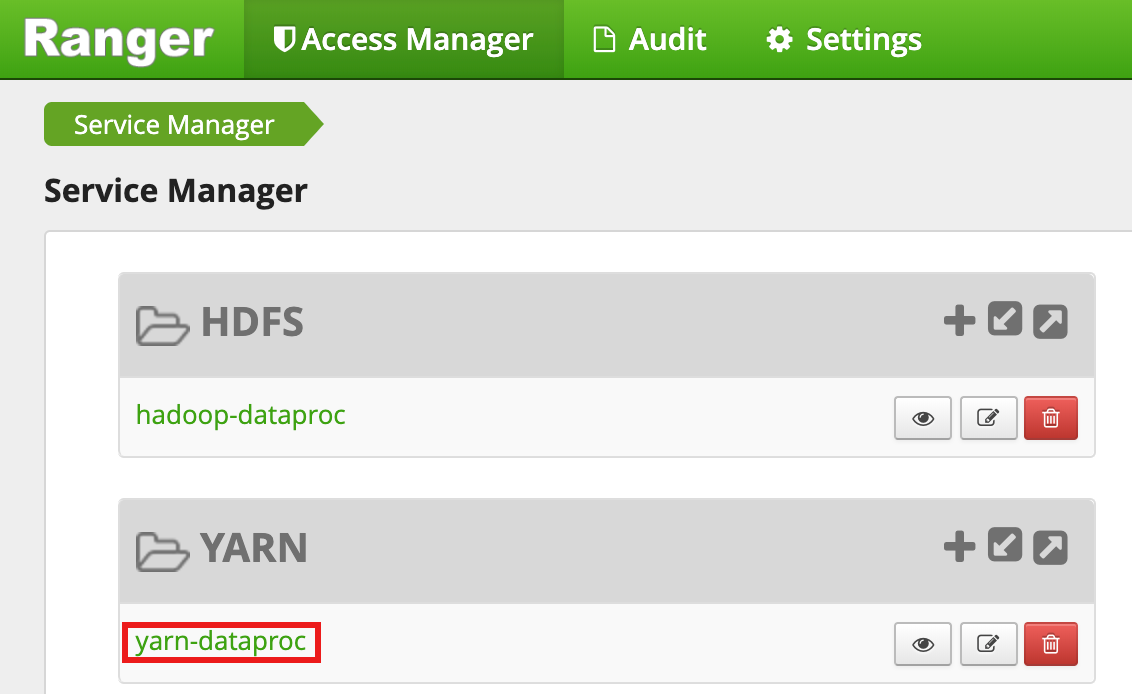
Klicken Sie auf der Seite yarn-dataproc Policies auf Neue Richtlinie hinzufügen. Auf der Seite Richtlinie erstellen werden die folgenden Felder eingegeben oder ausgewählt:
Policy Name: "yarn-policy-1"Queue: "root.default"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All", um alle Berechtigungen zu erteilen
Deny Conditions:Select User: "usertwo"Permissions: "Select all", um alle Berechtigungen zu verweigern
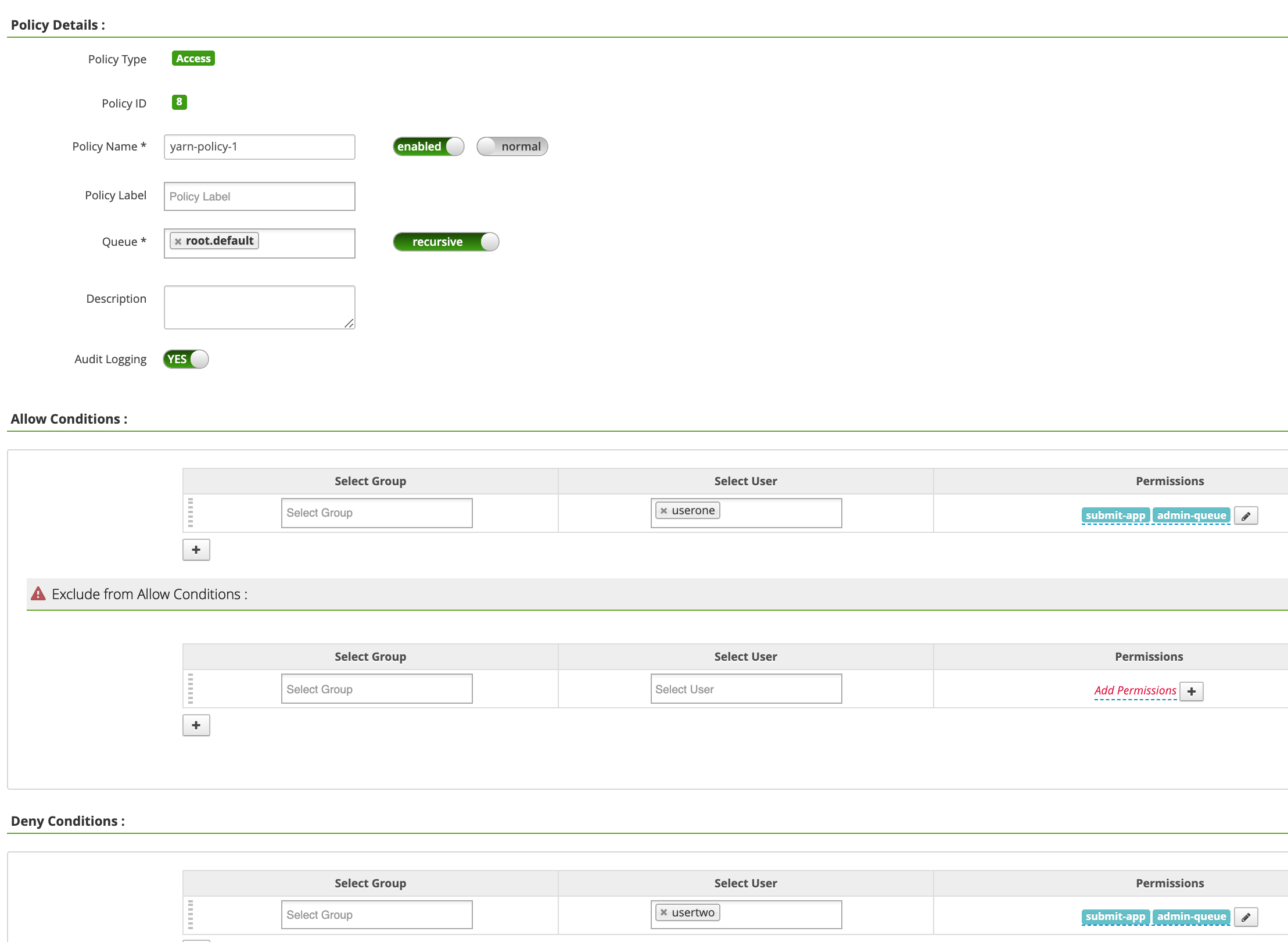
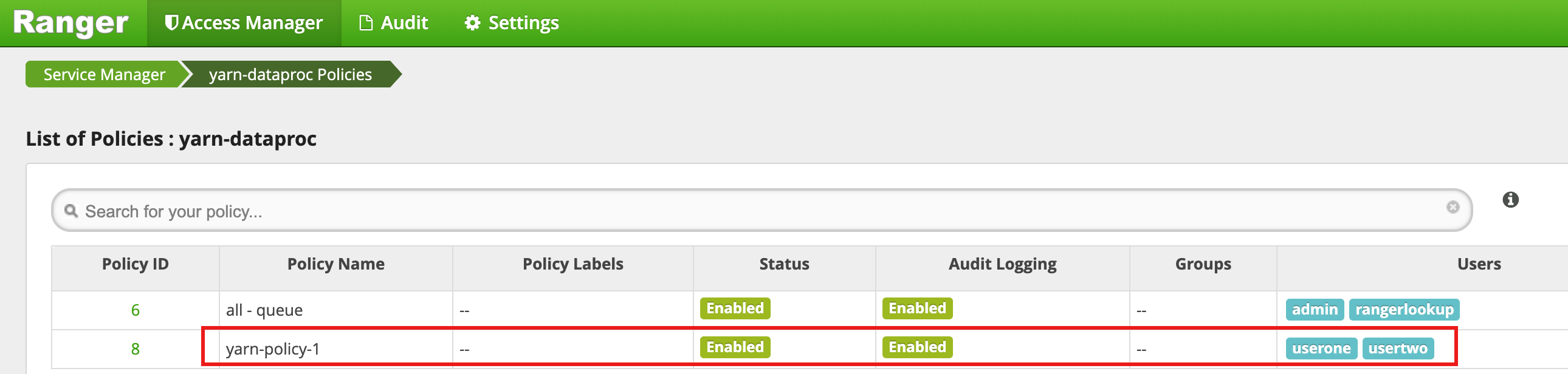
Klicken Sie auf Hinzufügen, um die Richtlinie zu speichern. Die Richtlinie wird auf der Seite yarn-dataproc Policies aufgeführt:
Führen Sie einen Hadoop MapReduce-Job im SSH-Sitzungsfenster des Masters als userone aus:
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Die Ranger-Benutzeroberfläche zeigt, dass
useroneden Auftrag einreichen durfte.
- Die Ranger-Benutzeroberfläche zeigt, dass
Führen Sie den Hadoop-mapreduce-Job aus dem VM-Master-SSH-Sitzungsfenster als
usertwoaus:usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Die Ranger-Benutzeroberfläche zeigt an, dass
usertwoder Zugriff zum Senden des Jobs verweigert wurde.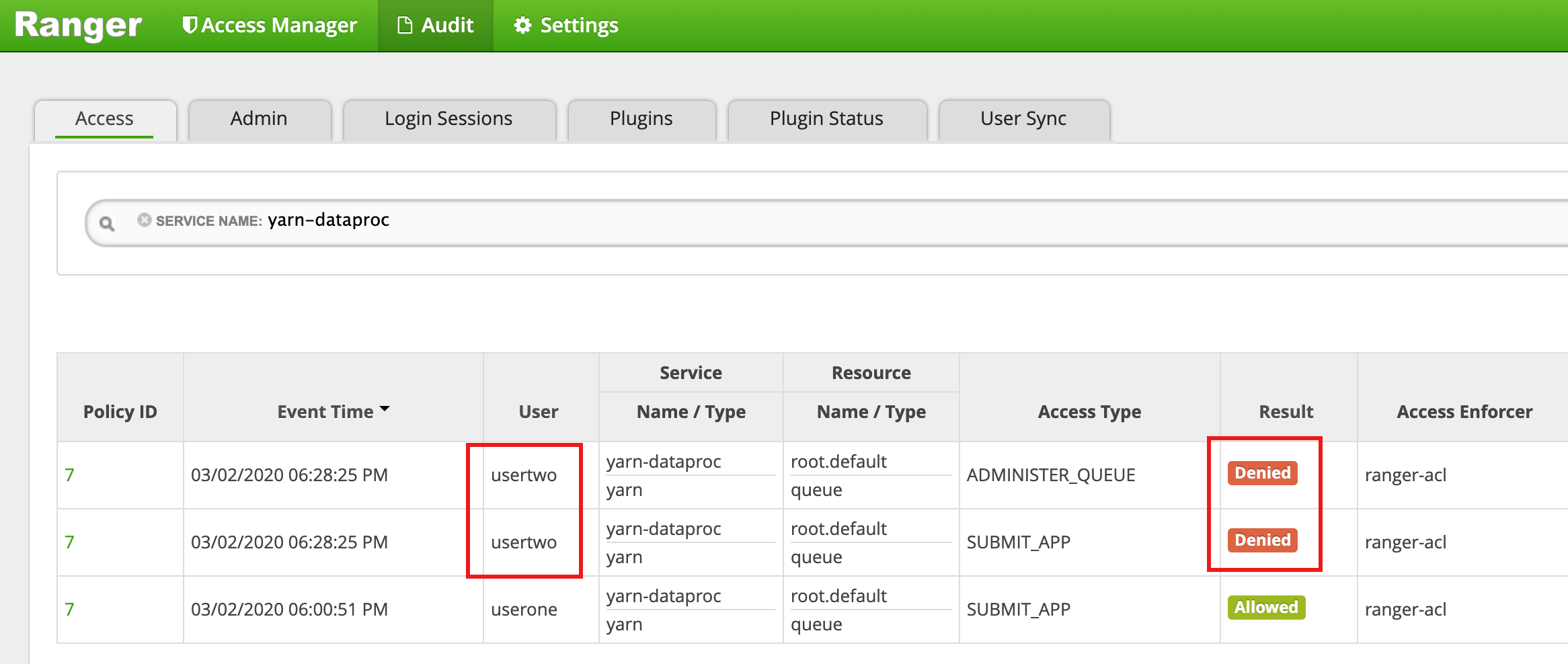
- Die Ranger-Benutzeroberfläche zeigt an, dass
HDFS-Zugriffsrichtlinie
In diesem Beispiel wird eine Ranger-Richtlinie erstellt, um dem Nutzerzugriff auf das HDFS-Verzeichnis /tmp zu erlauben oder zu verweigern.
Wählen Sie in der Ranger Admin-Benutzeroberfläche
hadoop-dataprocaus.
Klicken Sie auf der Seite hadoop-dataproc-Richtlinien auf Neue Richtlinie hinzufügen. Auf der Seite Richtlinie erstellen werden die folgenden Felder eingegeben oder ausgewählt:
Policy Name: "hadoop-policy-1"Resource Path: "/tmp"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All", um alle Berechtigungen zu erteilen
Deny Conditions:Select User: "usertwo"Permissions: "Select all", um alle Berechtigungen zu verweigern
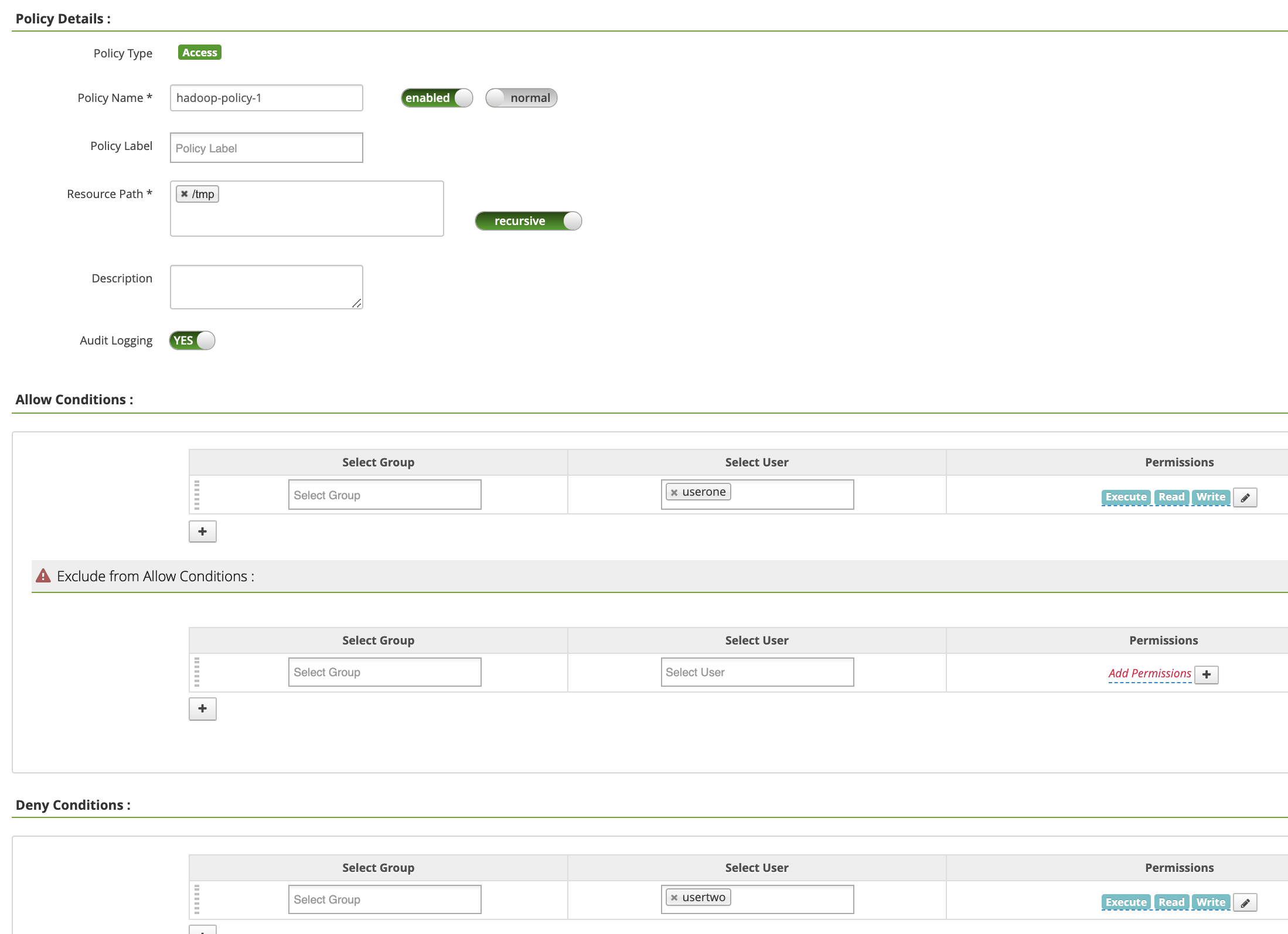
Klicken Sie auf Hinzufügen, um die Richtlinie zu speichern. Die Richtlinie wird auf der Seite hadoop-dataproc-Richtlinien aufgeführt:
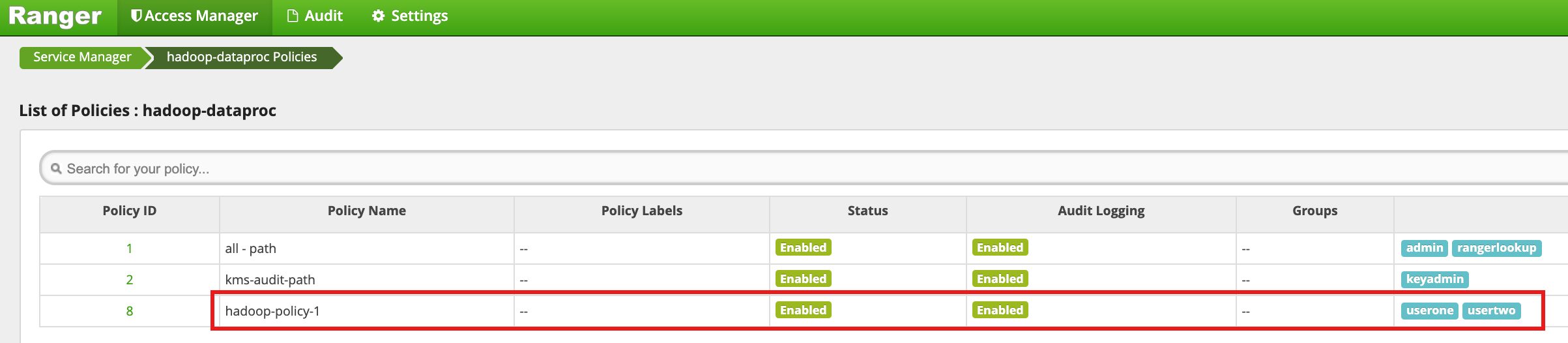
Greifen Sie als userone auf das HDFS-Verzeichnis
/tmpzu:userone@example-cluster-m:~$ hadoop fs -ls /tmp
- Die Ranger-Benutzeroberfläche zeigt an, dass
useroneZugriff auf das HDFS/tmp-Verzeichnis gewährt wurde.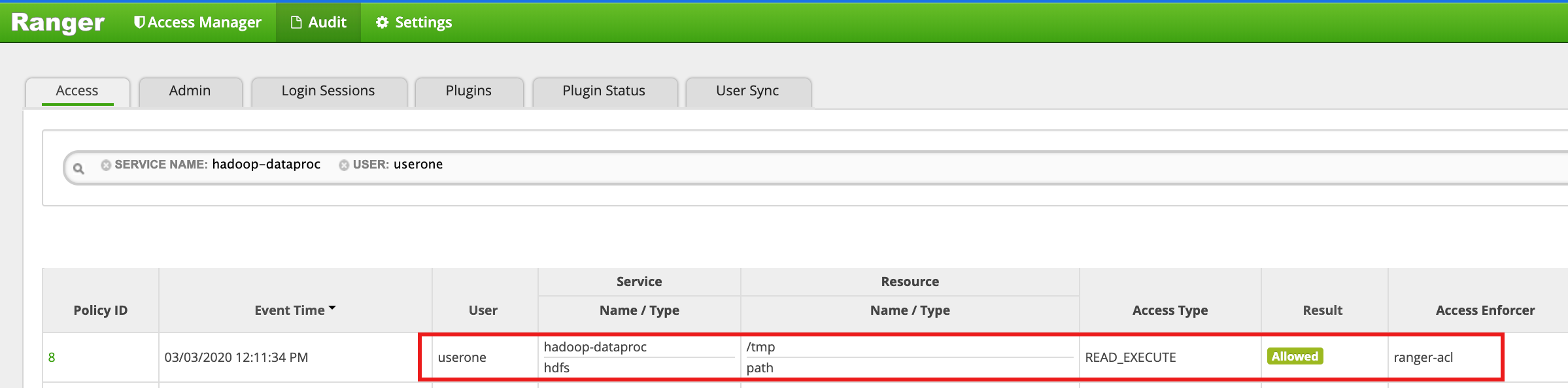
- Die Ranger-Benutzeroberfläche zeigt an, dass
Rufen Sie das HDFS-Verzeichnis
/tmpalsusertwoauf:usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- Die Benutzeroberfläche von Ranger zeigt, dass
usertwoder Zugriff auf das Verzeichnis "HDFS/tmp" verweigert wurde.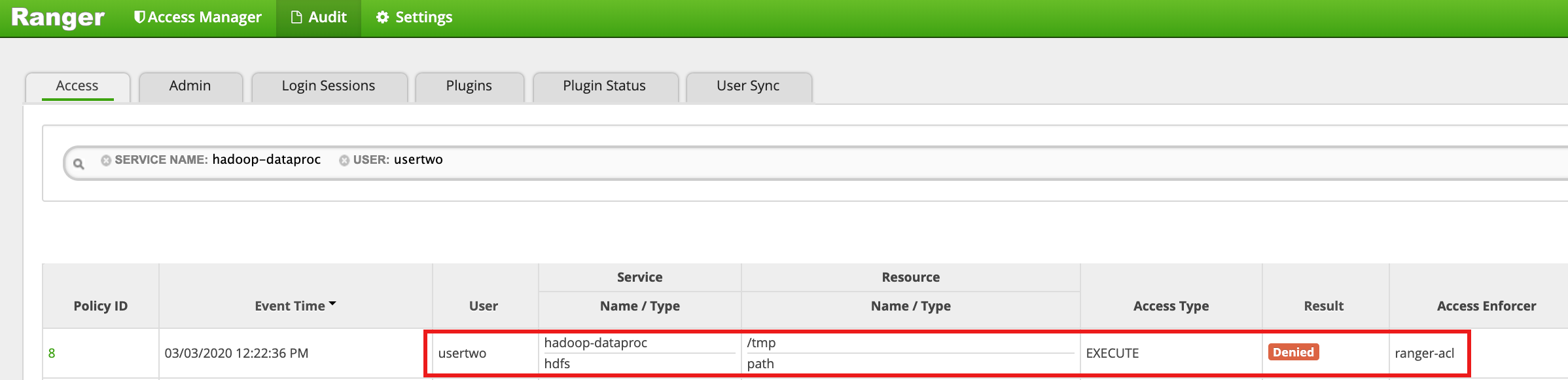
- Die Benutzeroberfläche von Ranger zeigt, dass
Hive-Zugriffsrichtlinie
In diesem Beispiel wird eine Ranger-Richtlinie erstellt, um den Nutzerzugriff auf eine Hive-Tabelle zu erlauben oder zu verweigern.
Erstellen Sie mithilfe der Hive-Befehlszeile auf der Masterinstanz eine kleine
employee-Tabelle.hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Wählen Sie in der Ranger Admin-Benutzeroberfläche
hive-dataprocaus.
Klicken Sie auf der Seite hadoop-dataproc-Richtlinien auf Neue Richtlinie hinzufügen. Auf der Seite Richtlinie erstellen werden die folgenden Felder eingegeben oder ausgewählt:
Policy Name: "hive-policy-1"database: "default"table: "employee"Hive Column: "*"Audit Logging: "Yes"Allow Conditions:Select User: "userone"Permissions: "Select All", um alle Berechtigungen zu erteilen
Deny Conditions:Select User: "usertwo"Permissions: "Select all", um alle Berechtigungen zu verweigern
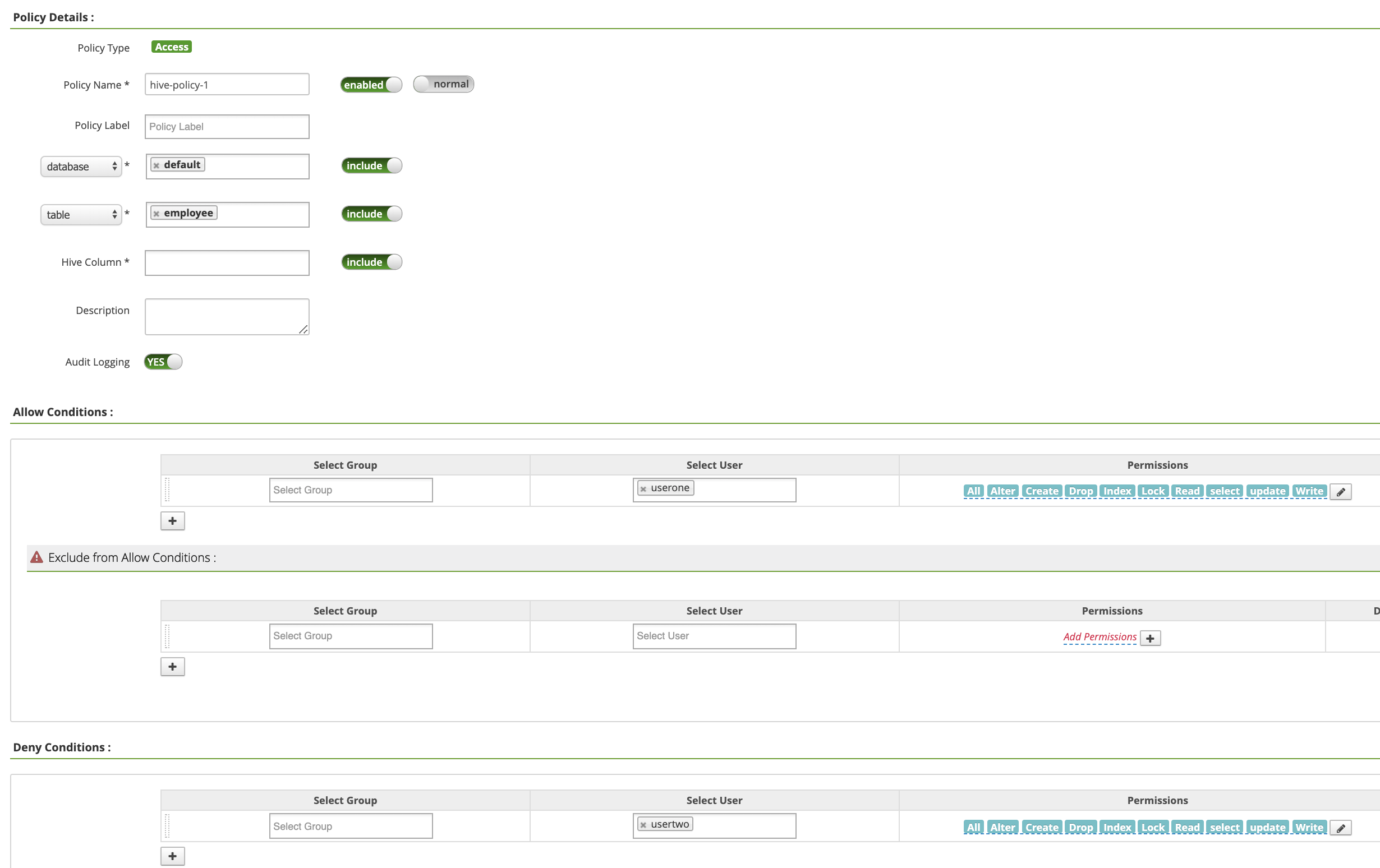
Klicken Sie auf Hinzufügen, um die Richtlinie zu speichern. Die Richtlinie wird auf der Seite hadoop-dataproc-Richtlinien aufgeführt:
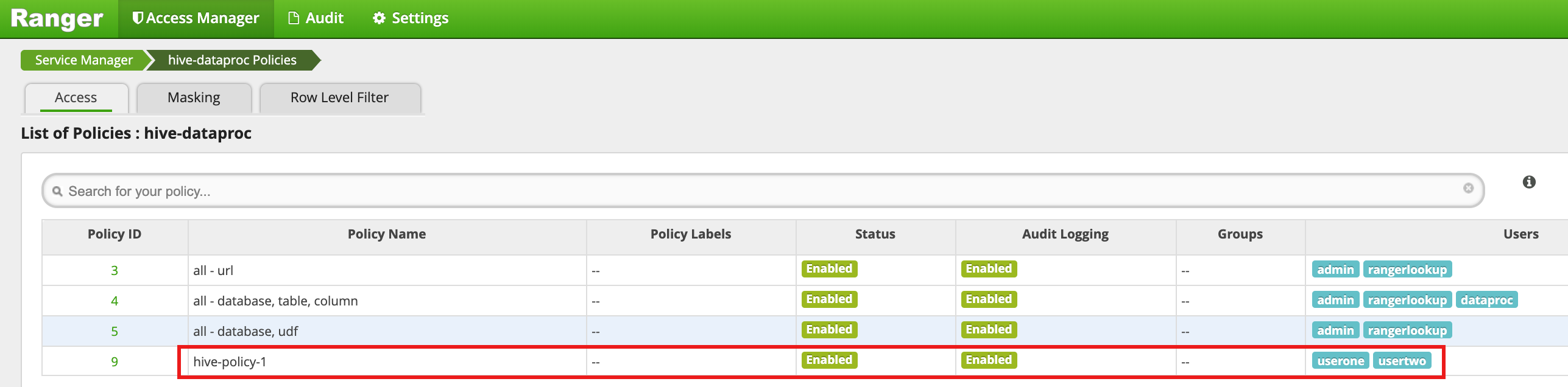
Führen Sie eine Abfrage aus der VM-Master-SSH-Sitzung gegen die Hive-Mitarbeitertabelle als userone aus:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- Die userone-Abfrage ist erfolgreich:
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- Die userone-Abfrage ist erfolgreich:
Führen Sie eine Abfrage aus der VM-Master-SSH-Sitzung gegen die Hive-Mitarbeitertabelle als usertwo aus:
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- "usertwo" hat keinen Zugriff auf die Tabelle:
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- "usertwo" hat keinen Zugriff auf die Tabelle:
Detaillierter Hive-Zugriff
Ranger unterstützt die Maskierung und die Filter auf Zeilenebene in Hive. Dieses Beispiel basiert auf der vorherigen hive-policy-1 und fügt Maskierungs- und Filterrichtlinien hinzu.
Wählen Sie
hive-dataprocauf der Ranger Admin-Benutzeroberfläche aus, wählen Sie den Tab Maskierung aus und klicken Sie auf Neue Richtlinie hinzufügen.
Auf der Seite Richtlinie erstellen werden die folgenden Felder eingegeben oder ausgewählt, um eine Richtlinie zum Maskieren (Annullieren) der Spalte für den Mitarbeiternamen zu erstellen:
Policy Name: "hive-masking-Richtlinie"database: "default"table: "employee"Hive Column: "name"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select", Berechtigungen hinzufügen/bearbeitenSelect Masking Option: "nullify"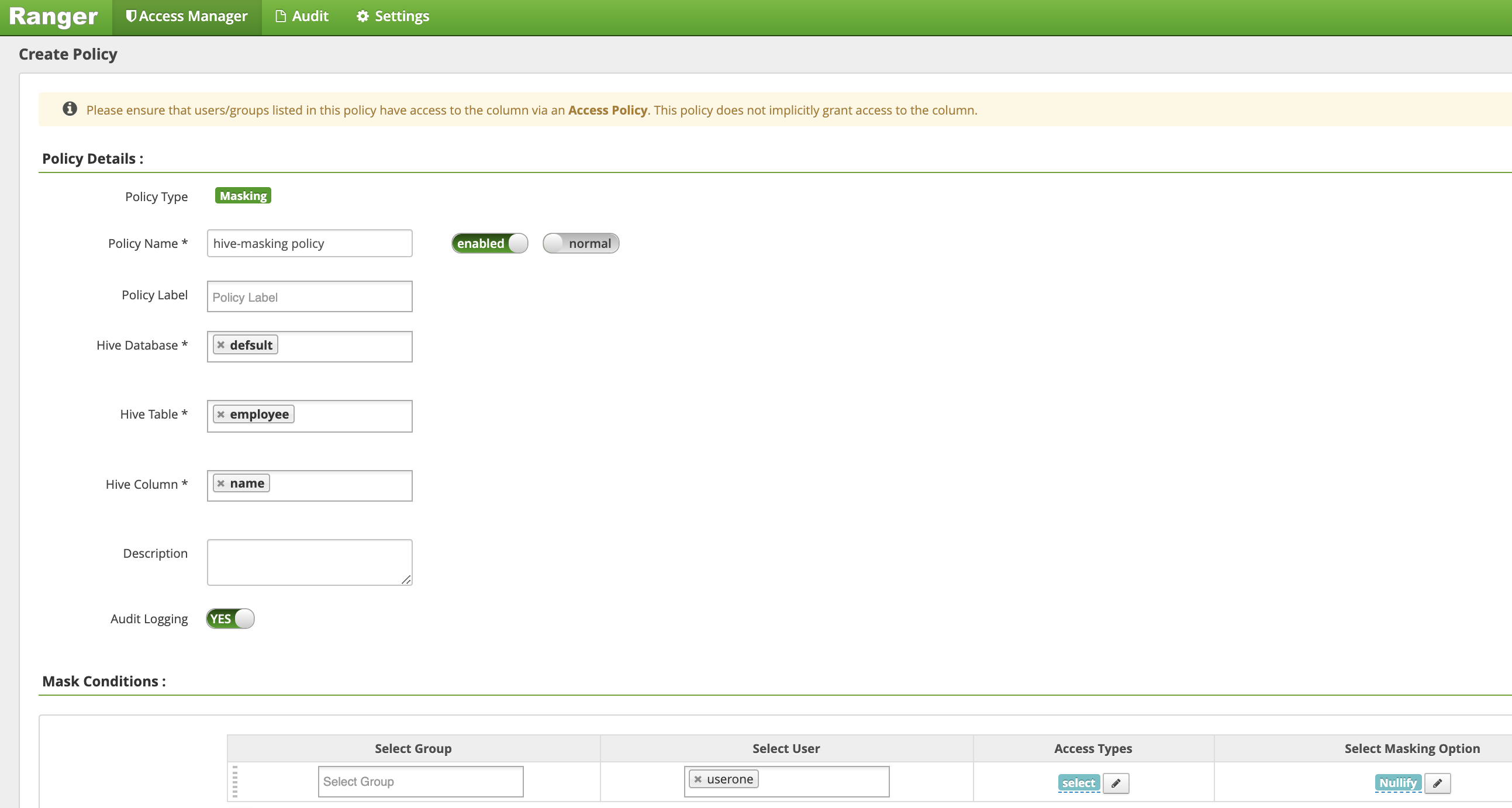
Klicken Sie auf Hinzufügen, um die Richtlinie zu speichern.
Wählen Sie
hive-dataprocin der Ranger Admin-Benutzeroberfläche aus. Wählen Sie dann den Tab Zeilenebenenfilter aus und klicken Sie auf Neue Richtlinie hinzufügen.
Auf der Seite Richtlinie erstellen werden die folgenden Felder eingegeben oder ausgewählt, um eine Richtlinie zum Filtern (Zurückgeben) von Zeilen zu erstellen, in denen
eidnicht gleich1ist:Policy Name: "hive-filter-Richtlinie"Hive Database: "default"Hive Table: "employee"Audit Logging: "Yes"Mask Conditions:Select User: "userone"Access Types: "select", Berechtigungen hinzufügen/bearbeitenRow Level Filter: FIlterausdruck "eid!= 1"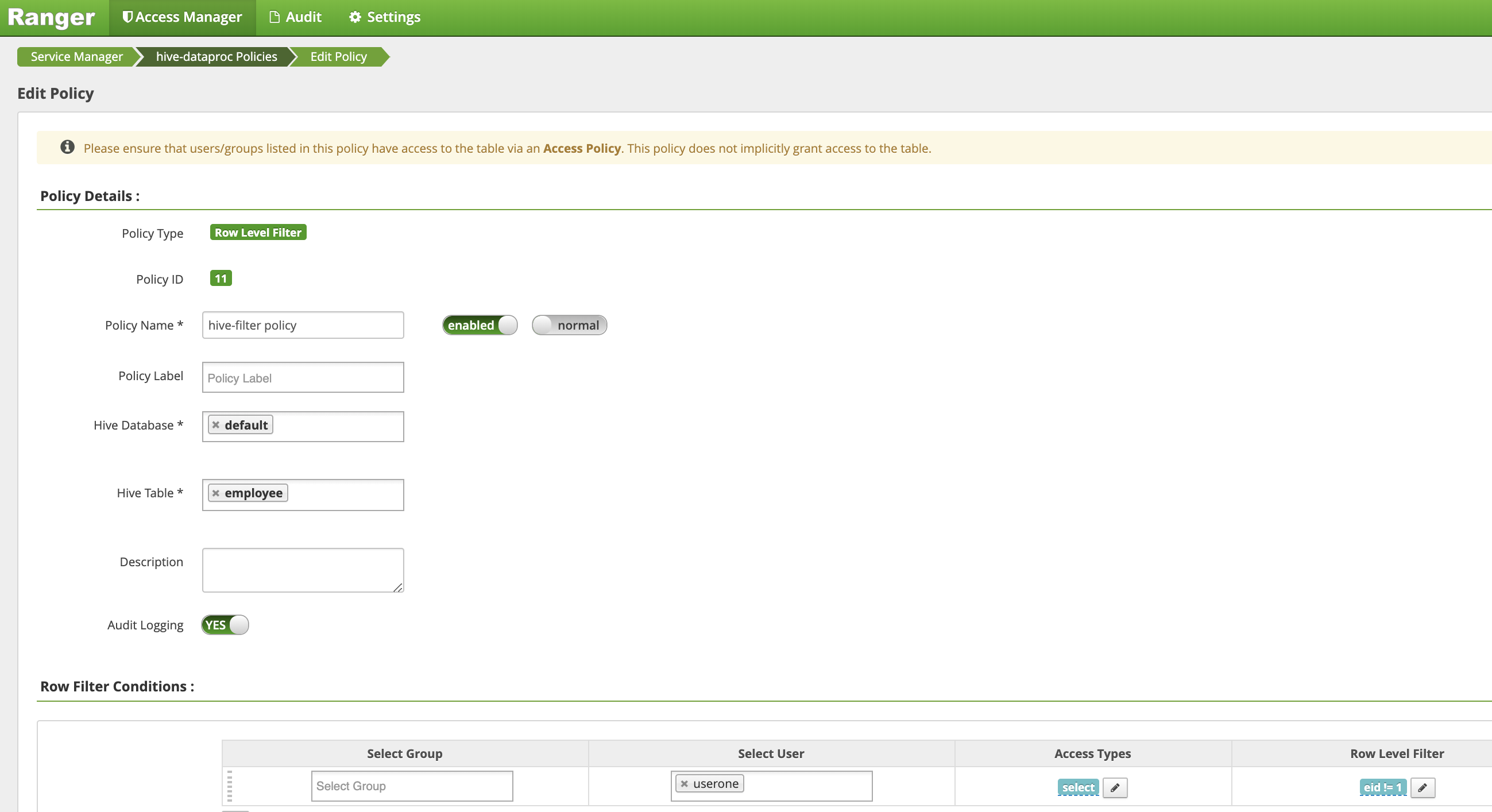
Klicken Sie auf Hinzufügen, um die Richtlinie zu speichern.
Wiederholen Sie die vorherige Abfrage aus der VM-Master-SSH-Sitzung gegen die Hive-Mitarbeitertabelle als userone:
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- Die Abfrage wird mit ausgeblendeter Namensspalte und gefiltertem Robert (eid=1) aus den Ergebnissen zurückgegeben:
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- Die Abfrage wird mit ausgeblendeter Namensspalte und gefiltertem Robert (eid=1) aus den Ergebnissen zurückgegeben: