CMEK mit Google Cloud Serverless for Apache Spark verwenden
Mit Sammlungen den Überblick behalten
Sie können Inhalte basierend auf Ihren Einstellungen speichern und kategorisieren.
Standardmäßig werden in Google Cloud Serverless for Apache Spark inaktive Kundendaten verschlüsselt. Serverless for Apache Spark übernimmt die Verschlüsselung für Sie. Zusätzliche Maßnahmen Ihrerseits sind nicht erforderlich. Diese Option wird Google-Standardverschlüsselung genannt.
Wenn Sie Ihre Verschlüsselungsschlüssel selbst verwalten möchten, können Sie vom Kunden verwaltete Verschlüsselungsschlüssel (CMEKs, Customer-Managed Encryption Keys) in Cloud KMS mit CMEK-integrierten Diensten wie Serverless for Apache Spark verwenden. Mit Cloud KMS-Schlüsseln haben Sie die Kontrolle über Schutzlevel, Speicherort, Rotationszeitplan, Nutzungs- und Zugriffsberechtigungen sowie über kryptografische Grenzen.
Mit Cloud KMS können Sie außerdem die Schlüsselnutzung im Blick behalten, Audit-Logs aufrufen und den Lebenszyklus von Schlüsseln steuern.
Statt es Google zu überlassen und zu verwalten, das die symmetrischen Schlüsselverschlüsselungsschlüssel (Key Encryption Keys, KEKs) zum Schutz Ihrer Daten enthält, können Sie diese auch über Cloud KMS steuern und verwalten.
Nachdem Sie Ihre Ressourcen mit CMEKs eingerichtet haben, ähnelt der Zugriff auf Ihre Serverless for Apache Spark-Ressourcen der Verwendung der Google-Standardverschlüsselung.
Weitere Informationen zu Ihren Verschlüsselungsoptionen finden Sie unter Vom Kunden verwaltete Verschlüsselungsschlüssel (CMEK).
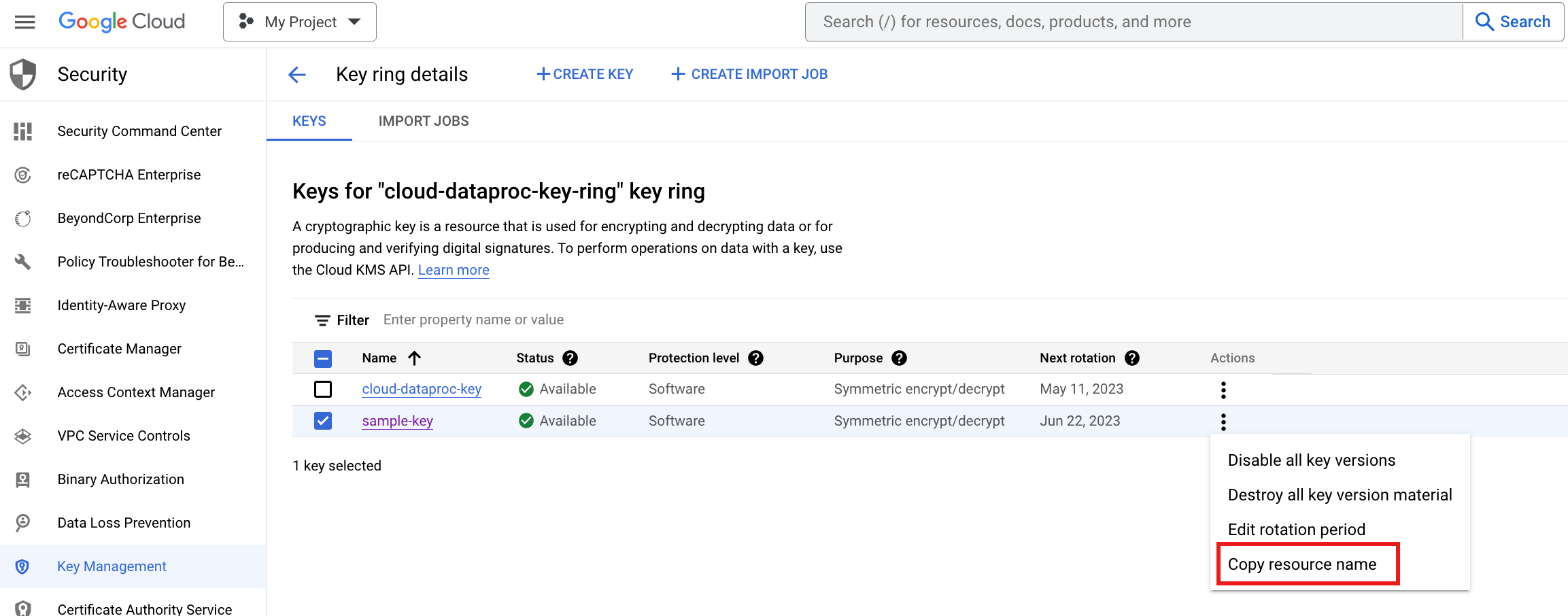
CMEK verwenden
Folgen Sie der Anleitung in diesem Abschnitt, um CMEK zum Verschlüsseln von Daten zu verwenden, die von Google Cloud Serverless für Apache Spark auf den nichtflüchtigen Speicher und in den Dataproc-Staging-Bucket geschrieben werden.
KMS_PROJECT_ID: die ID Ihres Google Cloud -Projekts, in dem Cloud KMS ausgeführt wird. Dieses Projekt kann auch das Projekt sein, in dem Dataproc-Ressourcen ausgeführt werden.
PROJECT_NUMBER: die Projektnummer (nicht die Projekt-ID) Ihres Google Cloud Projekts, in dem Dataproc-Ressourcen ausgeführt werden.
Aktivieren Sie die Cloud KMS API für das Projekt, in dem Serverless for Apache Spark-Ressourcen ausgeführt werden.
Wenn die Dataproc Service Agent-Rolle nicht an das Dataproc Service Agent-Dienstkonto angehängt ist, fügen Sie der benutzerdefinierten Rolle, die an das Dataproc Service Agent-Dienstkonto angehängt ist, die Berechtigung serviceusage.services.use hinzu. Wenn die Rolle „Dataproc Service Agent“ dem Dataproc-Dienst-Agent-Dienstkonto zugewiesen ist, können Sie diesen Schritt überspringen.
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-09-29 (UTC)."],[],[]]