Esta página fornece dicas de solução de problemas e estratégias de depuração que podem ser úteis, caso você tenha problemas para criar ou executar um pipeline do Dataflow. Essas informações podem ajudar a detectar uma falha em um pipeline, determinar o motivo por trás da falha e sugerir algumas ações recomendadas para corrigir o problema.
O diagrama a seguir mostra o fluxo de trabalho da solução de problemas do Dataflow descrito nesta página.

O Dataflow fornece feedback em tempo real sobre o job e há uma série de etapas que você pode usar para verificar mensagens de erro, registros e condições, como a paralisação do andamento do job.
Para orientações sobre erros comuns que você pode encontrar ao executar o job do Dataflow, consulte Solução de problemas de erros do Dataflow. Consulte Como monitorar o desempenho do pipeline para mais informações sobre esse processo.
Práticas recomendadas para pipelines
Veja a seguir as práticas recomendadas para pipelines do Java, Python e Go.
Java
Para jobs em lote, recomendamos definir um time to live (TTL) para o local temporário.
Antes de configurar o TTL, como uma prática recomendada geral, verifique se você definiu o local de preparação e o local temporário como locais diferentes.
Não exclua os objetos do local de preparo, porque eles serão reutilizados.
Se um job for concluído ou interrompido e os objetos temporários não forem limpos, remova manualmente esses arquivos do bucket do Cloud Storage usado como um local temporário.
Python
Os locais temporário e de preparo têm um prefixo <job_name>.<time>.
Defina o local de preparo e o temporário como locais diferentes.
Se necessário, exclua os objetos do local de preparo depois que um job for concluído ou interrompido. Além disso, os objetos preparados não são reutilizados em pipelines do Python.
Se um job terminar e os objetos temporários não forem limpos, remova manualmente esses arquivos do bucket do Cloud Storage usado como local temporário.
Para jobs em lote, recomendamos que você defina um time to live (TTL) para os locais temporários e de preparação.
Go
Os locais temporário e de preparo têm um prefixo
<job_name>.<time>.Defina o local de preparo e o temporário como locais diferentes.
Se necessário, exclua os objetos do local de preparo depois que um job for concluído ou interrompido. Além disso, os objetos preparados não são reutilizados em pipelines do Go.
Se um job terminar e os objetos temporários não forem limpos, remova manualmente esses arquivos do bucket do Cloud Storage usado como local temporário.
Para jobs em lote, recomendamos que você defina um time to live (TTL) para os locais temporários e de preparação.
Verifique o status do pipeline
É possível detectar erros em execuções do pipeline usando a Interface de monitoramento do Dataflow.
- Acesse o Console do Google Cloud.
- Selecione seu projeto do Google Cloud na lista de projetos.
- No menu de navegação, em Big Data, clique em Dataflow. No painel do lado direito, será exibida uma lista de jobs em execução.
- Selecione o job de pipeline que quer visualizar. Será possível ver o status dos jobs no campo Status: "Em execução", "Finalizado" ou "Com falha".
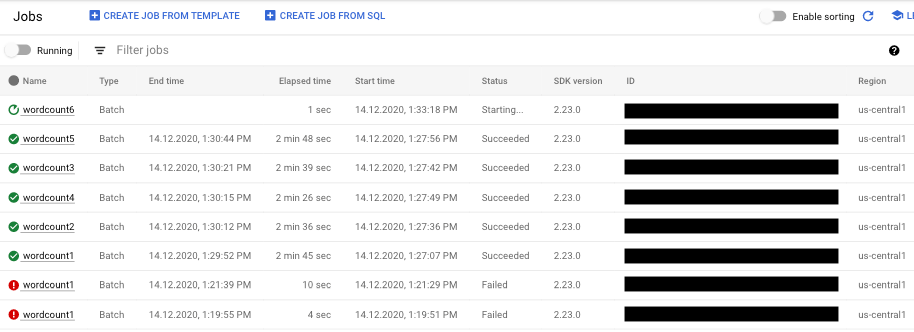
Encontrar informações sobre falhas de pipeline
Caso tenha ocorrido falha em um dos jobs do pipeline, selecione o job para ver informações mais detalhadas sobre os erros e os resultados da execução. Ao selecionar um job, é possível visualizar os principais gráficos do pipeline, o gráfico de execução, os painéis Informações do job e Registros com registro de job e do worker, além das guias Diagnóstico e Recomendações.
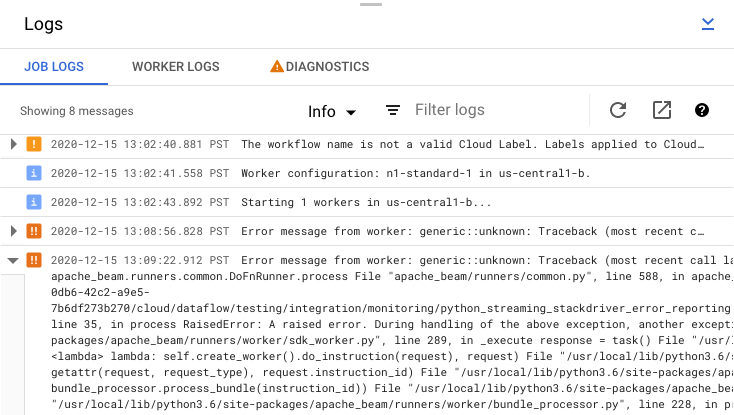
Verificar mensagens de erro do job
Para ver Registros do job gerados pelo código do pipeline e pelo serviço do Dataflow, no painel Registros, clique em segmentMostrar.
É possível filtrar as mensagens que aparecem em Registros do Job clicando em Informaçõesarrow_drop_down e filter_listFiltro. Para exibir apenas mensagens de erro, clique em Informaçõesarrow_drop_down e selecione Erro.
Para expandir uma mensagem de erro, clique na seção expansível arrow_right.
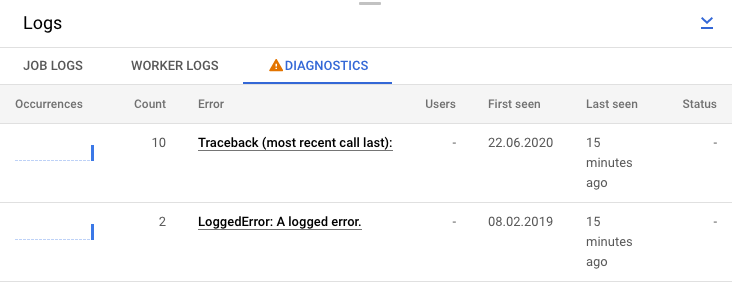
Se preferir, clique na guia Diagnóstico. Nesta guia, você verá onde ocorreram erros ao longo do cronograma escolhido, uma contagem de todos os erros registrados e possíveis recomendações para o pipeline.
Ver registros da etapa do job
Quando você seleciona uma etapa no gráfico do pipeline, o painel de registros alterna da exibição dos Registros de jobs gerados pelo serviço do Dataflow para a opção mostrar registros das instâncias do Compute Engine que executam a etapa do pipeline.
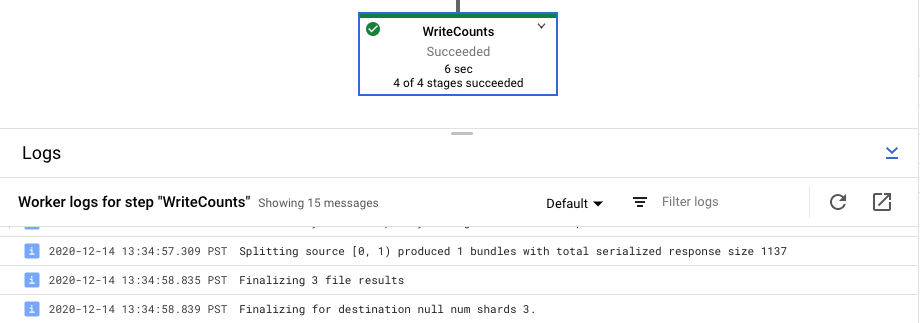
O Cloud Logging combina todos os registros coletados das instâncias do Compute Engine do seu projeto em um único local. Consulte Registro de mensagens do pipeline para mais informações sobre o uso dos diversos recursos de registro do Dataflow.
Gerenciar a rejeição automatizada de pipelines
Em alguns casos, o serviço Dataflow identifica que o pipeline pode acionar problemas conhecidos do SDK. Para evitar que pipelines com probabilidade de encontrar problemas sejam enviados, o Dataflow rejeita automaticamente seu pipeline e exibe a seguinte mensagem:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Depois de ler as advertências nos detalhes de bugs associados, se ainda assim você quiser tentar executar o pipeline, modifique a rejeição automática. Adicione a sinalização --experiments=<override-flag> e envie o pipeline novamente.
Como determinar a causa da falha em um pipeline
Geralmente, a causa da falha em uma execução do pipeline do Apache Beam é atribuída a um dos seguintes casos:
- Erros de construção de gráfico ou pipeline. Esses erros ocorrem quando o Dataflow se depara com um problema na criação do gráfico das etapas que compõem o pipeline, conforme descrito pelo pipeline do Apache Beam.
- Erros na validação do job. O serviço do Dataflow valida qualquer job de pipeline que você lançar. Erros no processo de validação podem impedir que seu job seja criado ou executado com sucesso. Os erros de validação podem incluir problemas com o bucket do Cloud Storage do seu projeto do Google Cloud ou com as permissões do seu projeto.
- Exceções no código do worker. Ocorrem quando há erros ou bugs no código fornecido pelo usuário que o Dataflow distribui para workers paralelos, como as instâncias
DoFnde uma transformaçãoParDo. - Erros causados por falhas temporárias em outros serviços do Google Cloud. Seu pipeline pode falhar devido a uma interrupção temporária ou outro problema nos serviços do Google Cloud do qual depende o Dataflow, como o Compute Engine ou o Cloud Storage.
Detectar erros de construção de gráfico ou pipeline
Pode ocorrer um erro de construção de gráfico quando o Dataflow cria o gráfico de execução do pipeline com base no código do programa do Dataflow. Durante a construção do gráfico, o Dataflow verifica se há operações ilegais.
Se o Dataflow detectar um erro na construção do gráfico, lembre-se de que nenhum job será criado no serviço do Dataflow. Assim, você não verá o feedback na interface de monitoramento do Dataflow. Em vez disso, uma mensagem de erro semelhante à seguinte aparece no console ou na janela de terminal em que você executou o pipeline do Apache Beam:
Java
Por exemplo, se o pipeline tentar executar uma agregação como
GroupByKey em uma PCollection ilimitada, com janelas globais e
não acionadas, será exibida uma mensagem de erro semelhante a esta:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Por exemplo, se o pipeline usar dicas de tipo e o tipo de argumento em uma das transformações não for o esperado, ocorrerá uma mensagem de erro semelhante a esta:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
Por exemplo, se o pipeline usar um "DoFn" que não recebe nenhuma entrada, ocorre uma mensagem de erro semelhante a esta:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Caso você encontre esse erro, verifique o código do pipeline para garantir que as operações sejam legais.
Detectar erros na validação de jobs do Dataflow
Depois que o Dataflow recebe o gráfico do pipeline, o serviço tenta validar o job. Essa validação inclui o seguinte:
- Verificar se o serviço pode acessar os buckets do Cloud Storage associados ao job para a preparação de arquivos e a saída temporária.
- Verificar as permissões necessárias no seu projeto do Google Cloud.
- Verificar se o serviço pode acessar fontes de entrada e saída, como arquivos.
Se o job falhar no processo de validação, uma mensagem de erro será exibida na interface de monitoramento do Dataflow, bem como no console ou na janela de terminal, se você estiver usando a execução de bloqueio. A mensagem de erro é semelhante a esta:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
No momento, a validação de jobs descrita nesta seção não é compatível com Go. Os erros devido a esses problemas aparecem como exceções do worker.
Detectar uma exceção no código do worker
Durante a execução do job, podem ocorrer erros ou exceções no código do worker. Esses erros geralmente significam que as DoFns no código do pipeline geraram exceções não processadas, o que resulta em tarefas com falha no seu job do Dataflow.
Exceções no código do usuário, como instâncias DoFn, são relatadas na interface de monitoramento do Dataflow.
Se você executar o pipeline com a execução de bloqueio, também serão exibidas mensagens de erro impressas no console ou na janela do terminal, como as seguintes:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Proteja o código contra erros adicionando gerenciadores de exceção. Por exemplo, para descartar elementos que falham em alguma validação de entrada personalizada feita em uma ParDo, gerencie a exceção dentro da sua DoFn e descarte o elemento.
Rastreie elementos com falha de várias maneiras:
- Use o Cloud Logging para registrar os elementos com falha e verificar a saída.
- Verifique os registros de inicialização do worker e do Dataflow em busca de avisos ou erros seguindo as instruções em Como visualizar registros.
- É possível fazer com que a
ParDograve os elementos com falha em uma saída complementar (link em inglês) para uma futura inspeção.
Para rastrear as propriedades de um pipeline em execução, use a classe Metrics, conforme mostrado no exemplo a seguir:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Como solucionar problemas de pipelines de execução lenta ou falta de resultado
Consulte Resolver problemas de jobs lentos e travados.
Erros comuns e ações recomendadas
Quando você souber o erro que causou a falha do pipeline, consulte a página Solução de problemas de erros do Dataflow para ver orientações sobre solução de problemas.