Na interface de monitoramento do Dataflow, o painel Informações da etapa mostra informações sobre etapas individuais em um job. Uma etapa representa uma única transformação no pipeline. As transformações compostas contêm subetapas.
O painel Informações da etapa mostra as seguintes informações:
- Métricas da etapa.
- Informações sobre as coleções de entrada e saída da etapa.
- Quais estágios correspondem a essa etapa.
- Métricas de entrada secundária
Use o painel Informações da etapa para entender o desempenho do job em cada etapa e encontrar aquelas que podem ser otimizadas.
Conferir informações da etapa
Para conferir as informações da etapa, siga estas etapas:
No Google Cloud console, acesse a página Dataflow > Jobs.
Selecione um job.
Clique na guia Gráfico de jobs para ver o gráfico de jobs. O gráfico do job representa cada etapa do pipeline como uma caixa.
Clique em uma etapa. As informações sobre a etapa aparecem no painel Informações da etapa.
Para ver as subetapas de uma transformação composta, clique na seta Expandir nó.
Métricas da etapa
O painel Informações da etapa mostra as seguintes métricas para a etapa.
Marca d'água e atraso do sistema
A marca-d'água do sistema é o carimbo de data/hora mais recente em que todos os horários de eventos foram totalmente processados. O atraso da marca d'água do sistema é o tempo máximo que um item de dados aguarda o processamento.
Marca d'água e atraso dos dados
A marca d'água de dados é o carimbo de data/hora que marca o tempo estimado de conclusão da entrada de dados para esta etapa. O atraso da marca-d'água de dados é a diferença entre o horário do evento de entrada mais recente e a marca-d'água de dados.
Tempo decorrido
O tempo de espera é o tempo total aproximado gasto em todas as linhas de execução em todos os workers nas seguintes ações:
- Inicialização da etapa
- Processamento dos dados
- Embaralhamento dos dados
- Finalização da etapa
Para etapas compostas, o tempo decorrido é igual à soma do tempo gasto nas etapas do componente.
O tempo decorrido pode ajudar a identificar etapas lentas e diagnosticar qual parte do pipeline está demorando mais tempo do que o necessário.
Status do gargalo
Se o Dataflow detectar um gargalo, um alerta será mostrado, junto com a causa, se ela for conhecida. Para mais informações, consulte Solução de problemas de gargalos.
Latência máxima da operação
A latência máxima da operação é o tempo máximo gasto nesta etapa para processar mensagens recebidas ou expirações de janelas. Essa métrica é medida de forma agregada em etapas combinadas em um único estágio. Portanto, o valor representa todo o estágio.
Paralelismo de chaves
O paralelismo de chaves é o número aproximado de chaves em uso para o processamento de dados nesta etapa.
Coleções de entrada/saída
O painel Informações da etapa mostra as seguintes informações sobre cada uma das coleções de entrada e saída na etapa:
Gráfico de capacidade de processamento. Este gráfico mostra a capacidade de processamento da coleção. É possível ver o gráfico como elementos por segundo ou bytes por segundo. Para mais informações sobre essa métrica, consulte Capacidade de processamento.
Contagem de elementos adicionados à coleção.
Tamanho estimado da coleção, em bytes.
Estágios otimizados
Um estágio representa uma única unidade de trabalho realizada pelo Dataflow. Quando você seleciona uma etapa no gráfico de jobs, o painel Informações da etapa mostra os nomes dos estágios que executam essa etapa, além do status atual, como em execução, parado ou concluído.
Para mais informações sobre as fases do job, use a guia Detalhes da execução.
Métricas de entrada secundária
Uma entrada secundária é uma entrada adicional que uma transformação pode acessar sempre que processa um elemento. Se uma transformação criar ou consumir uma entrada secundária, o painel Informações secundárias vai mostrar métricas para a coleção de entrada secundária.
Se uma transformação composta criar ou consumir uma entrada secundária, expanda a transformação composta até que a subtransformação específica que cria ou consome a entrada secundária esteja visível. Selecione essa subtransformação para conferir as métricas de entrada secundária.
Transformações que criam uma entrada secundária
Se uma transformação criar uma coleção de entrada secundária, a seção Métricas de entrada secundária vai mostrar o nome da coleção, junto com as seguintes métricas:
- Tempo gasto na gravação: o tempo gasto gravando a coleção de entrada secundária.
- Bytes gravados: o número total de bytes gravados na coleção de entrada secundária.
- Tempo de leitura da entrada secundária e bytes lidos: uma tabela que contém outras métricas para todas as transformações que consomem a coleção de entradas secundárias, chamadas de consumidores de entrada secundária.
A tabela Tempo de leitura da entrada secundária e bytes lidos exibe as seguintes informações para cada consumidor de entrada secundária:
- Consumidor de entrada secundária: o nome da transformação do consumidor de entrada secundária.
- Tempo gasto lendo: o tempo que esse consumidor gastou lendo a coleção de entrada secundária.
- Bytes lidos: o número de bytes que este consumidor leu da coleção de entrada secundária.
A imagem a seguir mostra as métricas de entrada secundária de uma transformação que cria uma coleção de entrada secundária:
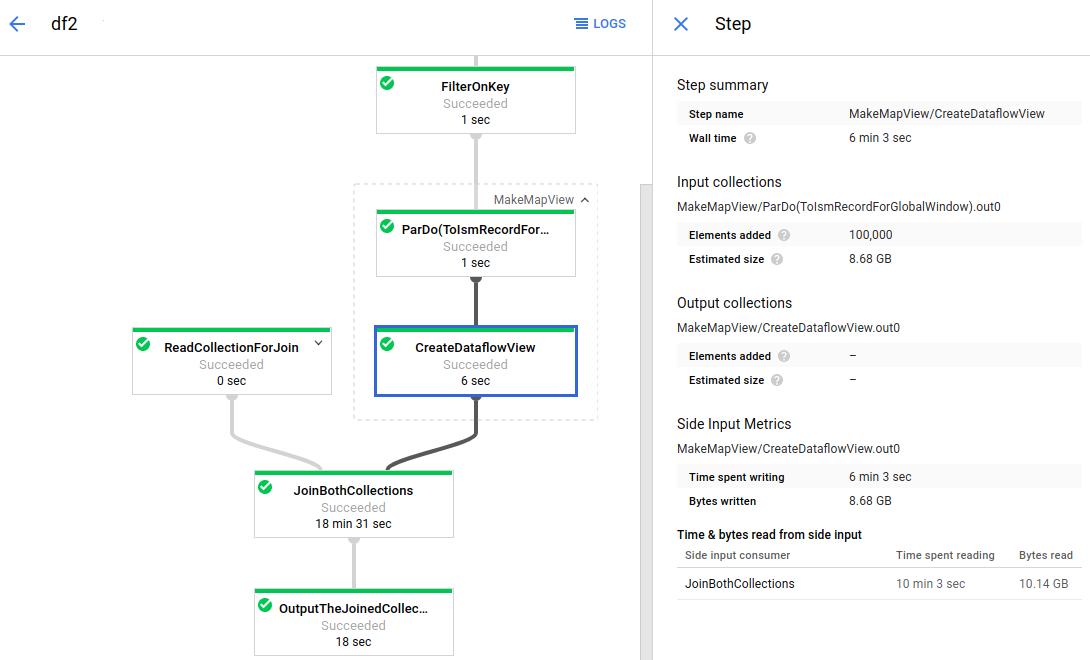
O gráfico do job tem uma transformação composta expandida (MakeMapView). A
subtransformação que cria a entrada secundária (CreateDataflowView) está selecionada, e
as métricas de entrada secundária podem ser vistas no painel Informações da etapa.
Transformações que consomem entradas secundárias
Se uma transformação consumir uma ou mais entradas secundárias, a seção Métricas de entrada secundária vai mostrar a tabela Tempo de leitura da entrada secundária e bytes lidos. Esta tabela contém as seguintes informações para cada coleção de entrada secundária:
- Coleção de entrada secundária: o nome da coleção de entrada secundária.
- Tempo gasto na leitura: o tempo que a transformação gastou lendo a coleção de entrada secundária.
- Bytes lidos: o número de bytes que a transformação leu da coleção de entrada secundária.
A imagem a seguir mostra as métricas de entrada secundária de uma transformação que lê uma coleção de entrada secundária.
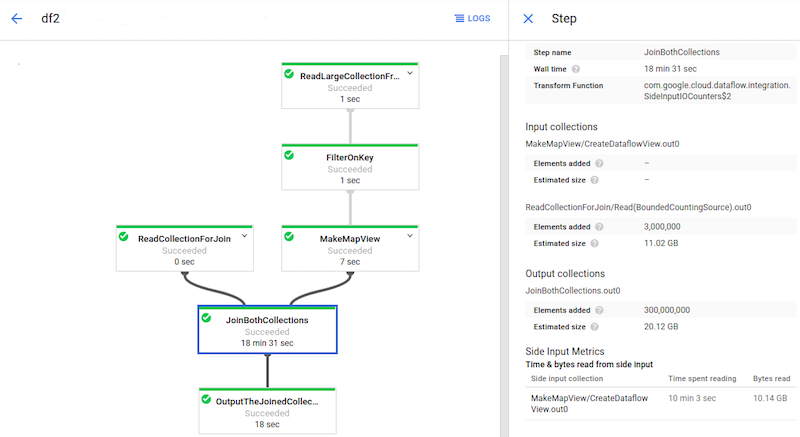
A transformação JoinBothCollections lê de uma coleção de entradas secundárias.
JoinBothCollections está selecionada no gráfico do job, e as métricas de entrada secundária
podem ser vistas no painel Informações da etapa.
Identificar problemas de desempenho em entradas secundárias
As entradas secundárias podem afetar a performance do pipeline. Quando o pipeline usa uma entrada secundária, o Dataflow grava a coleção em uma camada permanente, como um disco, e as transformações são lidas nessa coleção permanente. Essas leituras e gravações afetam o tempo de execução do job.
A reiteração é um problema comum de desempenho da entrada secundária. Se a entrada secundária PCollection for muito grande, os workers não poderão armazenar em cache a coleção inteira na memória.
Como resultado, os workers leem repetidamente a coleção de entrada secundária permanente.
Na imagem a seguir, as métricas de entrada secundária mostram que o total de bytes lidos da coleção de entrada secundária é muito maior que o tamanho da coleção, que é mostrado como total de bytes gravados. A coleção de entradas secundárias é de 563 MB e a soma dos bytes lidos por transformações de consumo é de quase 12 GB.
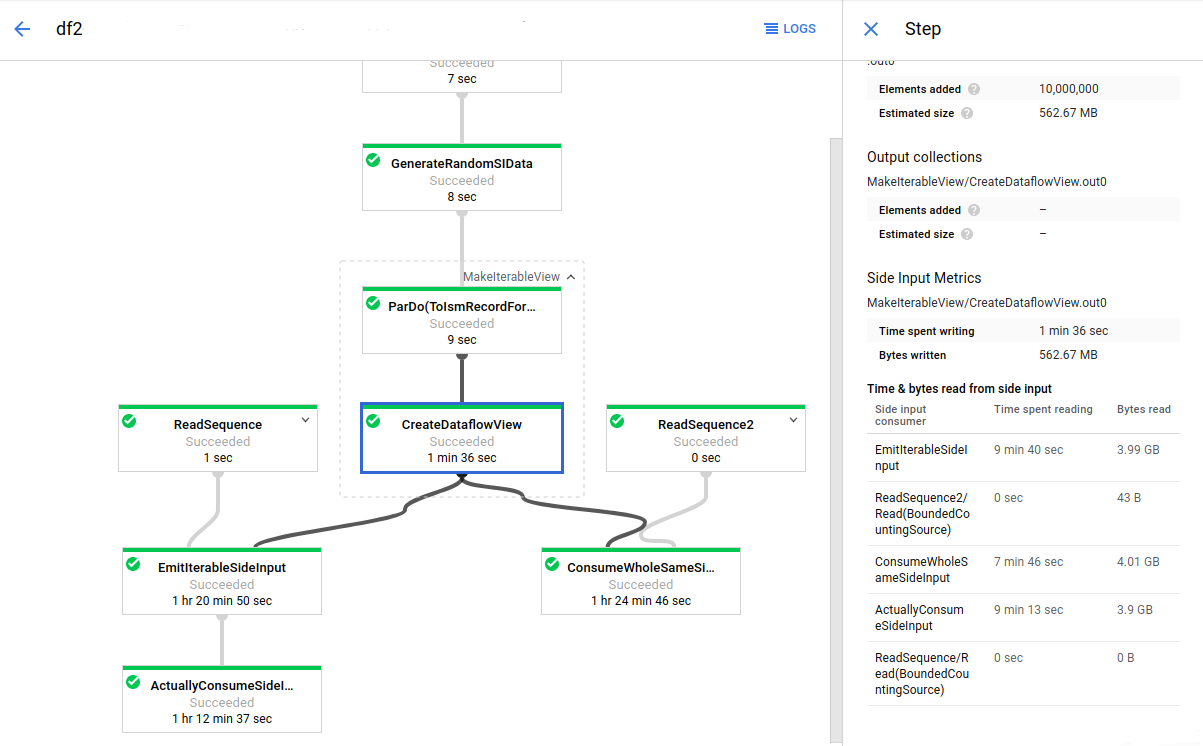
Para melhorar o desempenho desse pipeline, recrie o algoritmo para evitar iterar ou refazer os dados de entrada secundária. Neste exemplo, o pipeline cria o produto cartesiano de duas coleções. O algoritmo itera toda a coleção de entrada secundária para cada elemento da coleção principal. Você pode melhorar o padrão de acesso do pipeline ao agrupar vários elementos da coleção principal. Essa alteração reduz o número de vezes que os workers releem a coleção de entrada secundária.
Outro problema comum de desempenho pode ocorrer se o pipeline executar uma mesclagem aplicando uma ParDo com uma ou mais entradas secundárias grandes. Nesse caso, os workers
dedicam uma grande porcentagem do tempo de processamento para a operação de junção que leem
as coleções de entrada secundárias.
A imagem a seguir mostra métricas de entrada secundária para esse problema:
A transformação JoinBothCollections tem um tempo de processamento total de mais de 18 minutos. Os workers passam a maior parte do tempo de processamento (10 minutos) lendo a coleção de entrada secundária de 10 GB. Para melhorar o desempenho desse
pipeline, use
CoGroupByKey
em vez de entradas secundárias.