Dans l'interface de surveillance Dataflow, le panneau Informations sur l'étape affiche des informations sur les étapes individuelles d'un job. Une étape représente une seule transformation dans votre pipeline. Les transformations composites contiennent des sous-étapes.
Le panneau Informations sur l'étape affiche les informations suivantes :
- Métriques de l'étape.
- Informations sur les collections d'entrée et de sortie de l'étape.
- Étapes auxquelles correspond cette étape.
- Métriques des entrées secondaires
Utilisez le panneau Infos sur l'étape pour comprendre les performances de votre job à chaque étape et identifier les étapes qui peuvent potentiellement être optimisées.
Afficher les informations sur les étapes
Pour afficher des informations sur une étape, procédez comme suit :
Dans la console Google Cloud , accédez à Dataflow > Tâches.
Sélectionnez une tâche.
Cliquez sur l'onglet Job graph (Graphique de la tâche) pour afficher le graphique de la tâche. Sur le graphique de job, chaque étape du pipeline est représentée sous la forme d'une case.
Cliquez sur une étape. Des informations sur l'étape s'affichent dans le panneau Informations sur l'étape.
Pour afficher les sous-étapes d'une transformation composite, cliquez sur la flèche Développer le nœud.
Métriques d'étape
Le panneau Infos sur l'étape affiche les métriques suivantes pour l'étape.
Filigrane et retard du système
Le filigrane système correspond au dernier code temporel pour lequel tous les codes temporels des événements ont été entièrement traités. Le temps de latence du filigrane système correspond à la durée maximale pendant laquelle un élément de données a été en attente de traitement.
Marque de données et latence
Le filigrane de données correspond au code temporel qui marque la fin estimée de la saisie des données à cette étape. Le décalage du filigrane de données correspond à la différence entre l'heure du dernier événement d'entrée et le filigrane de données.
Durée d'exécution
Cette métrique fournit une approximation du temps total passé sur l'ensemble des threads dans tous les nœuds de calcul pour les actions suivantes :
- Initialisation de l'étape
- Traitement des données
- Mélange des données
- Clôture de l'étape
Pour les étapes composites, il s'agit de la durée cumulée des étapes des composants.
Le temps écoulé peut vous aider à identifier les étapes particulièrement lentes et à déterminer quelles parties de votre pipeline prennent plus de temps qu'elles ne le devraient.
État du goulot d'étranglement
Si Dataflow détecte un goulot d'étranglement, une alerte s'affiche, ainsi que la cause, si elle est connue. Pour en savoir plus, consultez Résoudre les problèmes de goulots d'étranglement.
Latence maximale des opérations
La latence maximale des opérations correspond au temps maximal consacré dans cette étape au traitement des messages entrants ou des expirations de fenêtre. Cette métrique est mesurée de manière globale pour toutes les étapes (fusionnées en une étape unique). La valeur est donc représentative de l'ensemble de cette étape.
Parallélisme de clés
Le parallélisme des clés correspond au nombre approximatif de clés utilisées pour le traitement des données à cette étape.
Collections d'entrée/de sortie
Le panneau Step info (Informations sur l'étape) affiche les informations suivantes sur chacune des collections d'entrée et de sortie de l'étape :
Graphique du débit. Ce graphique indique le débit de la collection. Vous pouvez afficher le graphique en éléments par seconde ou en octets par seconde. Pour en savoir plus sur cette métrique, consultez Débit.
Nombre d'éléments ajoutés à la collection.
Taille estimée de la collection, en octets.
Étapes optimisées
Une étape représente une seule unité de travail effectuée par Dataflow. Lorsque vous sélectionnez une étape dans le graphique de la tâche, le panneau Step info (Informations sur l'étape) affiche les noms des étapes qui exécutent cette étape, ainsi que l'état actuel (en cours d'exécution, arrêté ou terminé, par exemple).
Pour afficher plus d'informations sur les étapes de votre job, utilisez l'onglet Détails de l'exécution.
Métriques des entrées secondaires
Une entrée secondaire est une entrée supplémentaire à laquelle une transformation peut accéder chaque fois qu'elle traite un élément. Si une transformation crée ou consomme une entrée secondaire, le panneau Infos sur le côté affiche les métriques de la collection d'entrée secondaire.
Si une transformation composite crée ou consomme une entrée secondaire, développez la transformation composite jusqu'à voir la sous-transformation spécifique qui crée ou consomme l'entrée secondaire. Sélectionnez cette sous-transformation pour afficher les métriques des entrées secondaires.
Transformations créant une entrée secondaire
Si une transformation crée une collection d'entrée secondaire, la section Side Input Metrics (Métriques des entrées secondaires) affiche le nom de la collection, ainsi que les métriques suivantes :
- Time spent writing (Durée de l'écriture) : temps passé à écrire la collection de l'entrée secondaire.
- Bytes written (Octets écrits) : nombre total d'octets écrits dans la collection de l'entrée secondaire.
- Time & bytes read from side input (Durée de la lecture et octets lus à partir des entrées secondaires) : tableau contenant des métriques supplémentaires pour toutes les transformations absorbant la collection de l'entrée secondaire. Ces transformations sont appelées side input consumers (consommateurs de l'entrée secondaire).
Le tableau Time & bytes read from side input (Durée de la lecture et octets lus à partir des entrées secondaires) contient les informations suivantes pour chaque consommateur de l'entrée secondaire :
- Side input consumer (Consommateur de l'entrée secondaire) : nom de la transformation consommant l'entrée secondaire.
- Time spent reading (Durée de la lecture) : temps passé par ce consommateur à lire la collection de l'entrée secondaire.
- Bytes read (Octets lus) : nombre d'octets lus par ce consommateur à partir de la collection de l'entrée secondaire.
L'image suivante illustre les métriques des entrées secondaires pour une transformation créant une collection d'entrée secondaire :
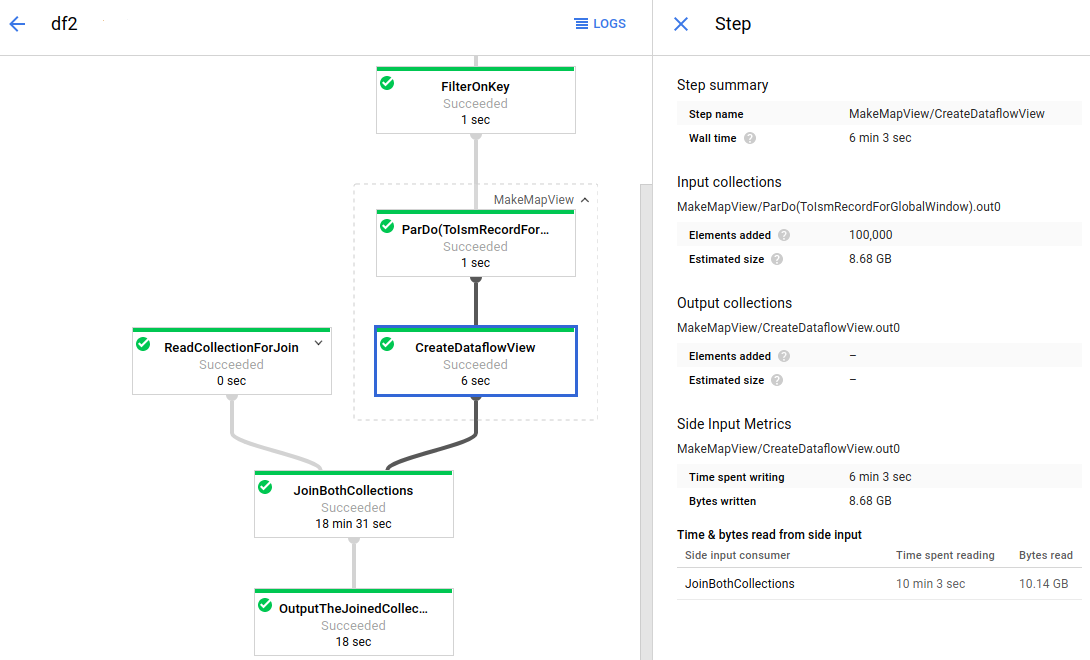
Le graphique de la tâche comporte une transformation composite développée (MakeMapView). La sous-transformation créant l'entrée secondaire (CreateDataflowView) est sélectionnée et les métriques des entrées secondaires sont visibles dans le panneau Informations sur l'étape.
Transformations consommant des entrées secondaires
Si une transformation consomme une ou plusieurs entrées secondaires, la section Side Input Metrics (Métriques des entrées secondaires) affiche le tableau Time & bytes read from side input (Durée de la lecture et octets lus à partir des entrées secondaires). Ce tableau contient les informations suivantes pour chaque collection d'entrée secondaire :
- Side input collection (Collection de l'entrée secondaire) : nom de la collection de l'entrée secondaire.
- Time spent reading (Durée de la lecture) : temps passé par la transformation à lire cette collection de l'entrée secondaire.
- Bytes read (Octets lus) : nombre d'octets lus par la transformation dans la collection de l'entrée secondaire.
L'image suivante illustre les métriques des entrées secondaires pour une transformation lisant une collection d'entrée secondaire.
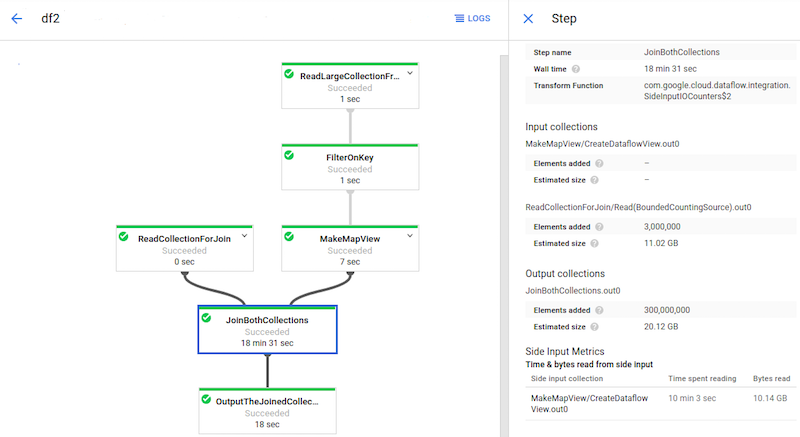
La transformation JoinBothCollections lit une collection d'entrée secondaire.
JoinBothCollections est sélectionnée dans le graphique de tâche, et les métriques des entrées secondaires sont visibles dans le panneau Informations sur l'étape.
Identifier les problèmes de performance des entrées secondaires
Les entrées secondaires peuvent affecter les performances de votre pipeline. Lorsque votre pipeline utilise une entrée secondaire, Dataflow écrit la collection sur une couche persistante (telle qu'un disque), et vos transformations lisent les données à partir de cette collection persistante. Ces lectures et écritures affectent le temps d'exécution de votre tâche.
La réitération est un problème de performances courant lié aux entrées secondaires. Si votre PCollection d'entrée secondaire est trop volumineuse, les nœuds de calcul ne peuvent pas mettre en cache l'intégralité de la collection.
Par conséquent, les nœuds de calcul doivent régulièrement lire les données depuis le stockage persistant de la collection de l'entrée secondaire.
Dans l'image suivante, les métriques des entrées secondaires montrent que le nombre total d'octets lus dans la collection de l'entrée secondaire est bien supérieur à la taille de la collection (nombre total d'octets écrits). La collection de l'entrée secondaire a une taille de 563 Mo, et la somme des octets lus par les transformations consommatrices atteint pratiquement 12 Go.
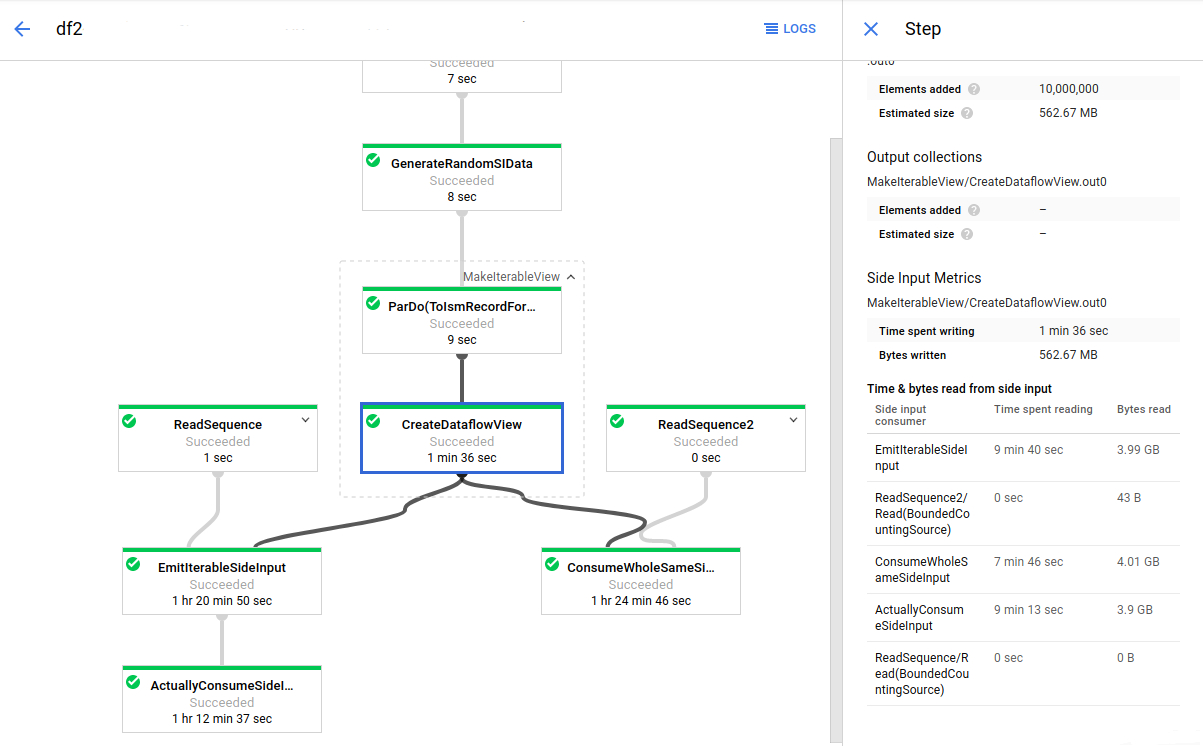
Pour améliorer les performances de ce pipeline, modifiez votre algorithme pour éviter les itérations ou la récupération répétée des données de l'entrée secondaires. Dans cet exemple, le pipeline calcule le produit cartésien de deux collections. Pour chaque élément de la collection principale, l'algorithme parcourt l'ensemble de la collection de l'entrée secondaire. Vous pouvez améliorer le modèle d'accès du pipeline en regroupant plusieurs éléments de la collection principale. Cette modification réduit le nombre de lectures de la collection de l'entrée secondaire requises par les nœuds de calcul.
Un autre problème de performances courant peut survenir si votre pipeline effectue une jointure en appliquant une fonction ParDo sur une ou plusieurs entrées secondaires volumineuses. Dans ce cas, les nœuds de calcul consacrent une large proportion du temps de traitement de la jointure à lire les données des collections d'entrées secondaires.
L'image suivante montre des métriques des entrées secondaires dans ce type de contexte :
Le temps total de traitement de la transformation JoinBothCollections est supérieur à 18 minutes. Les nœuds de calcul passent la majeure partie du temps de traitement (10 minutes) à lire la collection d'entrées secondaires de 10 Go. Pour améliorer les performances de ce pipeline, utilisez CoGroupByKey au lieu des entrées secondaires.