Com a E/S gerenciada, o Dataflow gerencia conectores de E/S específicos usados em pipelines do Apache Beam. A E/S gerenciada simplifica o gerenciamento de pipelines que se integram a origens e coletores compatíveis.
O E/S gerenciado consiste em dois componentes que trabalham juntos:
Uma transformação do Apache Beam que fornece uma API comum para criar conectores de E/S (origens e coletores).
Um serviço do Dataflow que gerencia esses conectores de E/S em seu nome, incluindo a capacidade de fazer upgrade deles independentemente da versão do Apache Beam.
As vantagens da E/S gerenciada incluem:
Upgrades automáticos. O Dataflow faz upgrade automático dos conectores de E/S gerenciados no seu pipeline. Isso significa que seu pipeline recebe correções de segurança, melhorias de desempenho e correções de bugs para esses conectores, sem exigir mudanças no código. Para mais informações, consulte Upgrades automáticos.
API consistente. Tradicionalmente, os conectores de E/S no Apache Beam têm APIs distintas, e cada conector é configurado de uma maneira diferente. O Managed I/O oferece uma única API de configuração que usa propriedades de chave-valor, resultando em um código de pipeline mais simples e consistente. Para mais informações, consulte API de configuração.
Requisitos
Os seguintes SDKs são compatíveis com E/S gerenciada:
- SDK do Apache Beam para Java versão 2.58.0 ou mais recente.
- SDK do Apache Beam para Python versão 2.61.0 ou posterior.
O serviço de back-end requer o Dataflow Runner v2. Se o Runner v2 não estiver ativado, o pipeline ainda será executado, mas não terá os benefícios do serviço gerenciado de E/S.
Upgrades automáticos
Os pipelines do Dataflow com conectores de E/S gerenciados usam automaticamente a versão mais recente e confiável do conector, da seguinte maneira:
Quando você envia um job, o Dataflow usa a versão mais recente do conector que foi testada e funciona bem.
Para jobs de streaming, o Dataflow verifica atualizações sempre que você inicia um job de substituição, e usa automaticamente a versão mais recente conhecida. O Dataflow realiza essa verificação mesmo que você não mude nenhum código no job de substituição.
Não é necessário se preocupar em atualizar manualmente o conector ou a versão do Apache Beam do pipeline.
O diagrama a seguir mostra o processo de upgrade. O usuário cria um pipeline do Apache Beam usando a versão X do SDK. Quando o usuário envia o job, o Dataflow verifica a versão da E/S gerenciada e faz upgrade para a versão Y.
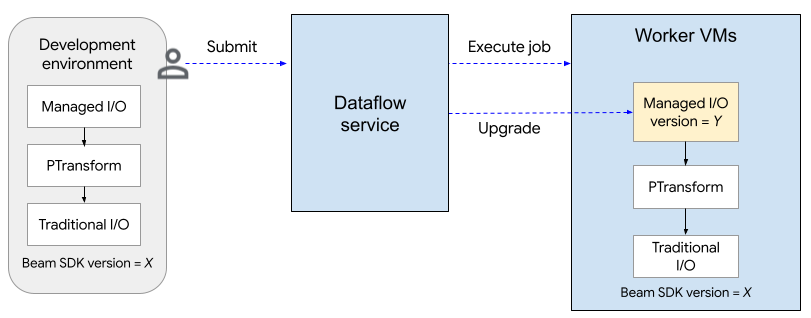
O processo de upgrade adiciona cerca de dois minutos ao tempo de inicialização de um job. Para verificar o status das operações de E/S gerenciadas, procure entradas de registro que incluam a string "Managed Transform(s)".
API de configuração
O Managed I/O é uma transformação pronta para uso do Apache Beam que fornece uma API consistente para configurar origens e coletores.
Java
Para criar qualquer origem ou destino compatível com a E/S gerenciada, use a classe
Managed. Especifique qual origem ou coletor instanciar e transmita um conjunto de parâmetros de configuração, semelhante ao seguinte:
Map config = ImmutableMap.<String, Object>builder()
.put("config1", "abc")
.put("config2", 1);
pipeline.apply(Managed.read(/*Which source to read*/).withConfig(config))
.getSinglePCollection();
Também é possível transmitir parâmetros de configuração como um arquivo YAML. Para conferir um exemplo de código completo, consulte Ler do Apache Iceberg.
Python
Importe o módulo apache_beam.transforms.managed e chame o método managed.Read ou managed.Write. Especifique qual origem ou
coletor instanciar e transmita um conjunto de parâmetros de configuração, semelhante a
este:
pipeline
| beam.managed.Read(
beam.managed.SOURCE, # Example: beam.managed.KAFKA
config={
"config1": "abc",
"config2": 1
}
)
Também é possível transmitir parâmetros de configuração como um arquivo YAML. Para um exemplo de código completo, consulte Ler do Apache Kafka.
Destinos dinâmicos
Para alguns coletores, o conector de E/S gerenciado pode selecionar dinamicamente um destino com base nos valores de campo nos registros recebidos.
Para usar destinos dinâmicos, forneça uma string de modelo para o destino. A string de modelo pode incluir nomes de campos entre chaves, como "tables.{field1}". No ambiente de execução, o conector substitui o valor do
campo por cada registro recebido para determinar o destino dele.
Por exemplo, suponha que seus dados tenham um campo chamado airport. Você pode definir o
destino como "flights.{airport}". Se airport=SFO, o registro será gravado em flights.SFO. Para campos aninhados, use a notação de ponto. Por exemplo:
{top.middle.nested}.
Para ver um exemplo de código que mostra como usar destinos dinâmicos, consulte Gravar com destinos dinâmicos.
Filtragem
Talvez seja útil filtrar alguns campos antes que eles sejam gravados na tabela de destino. Para gravadores que aceitam destinos dinâmicos, use o parâmetro drop, keep ou only. Esses parâmetros permitem incluir metadados de destino nos registros de entrada sem gravar os metadados no destino.
É possível definir no máximo um desses parâmetros para um determinado gravador.
| Parâmetro de configuração | Tipo de dado | Descrição |
|---|---|---|
drop |
lista de strings | Uma lista de nomes de campos a serem descartados antes da gravação no destino. |
keep |
lista de strings | Uma lista de nomes de campos a serem mantidos ao gravar no destino. Outros campos são descartados. |
only |
string | O nome de exatamente um campo a ser usado como o registro de nível superior para gravar ao gravar no destino. Todos os outros campos são descartados. Esse campo precisa ser do tipo "linha". |
Fontes e coletores compatíveis
A E/S gerenciada é compatível com as seguintes origens e coletores.
Para mais informações, consulte Conectores de E/S gerenciados na documentação do Apache Beam.