このページでは、Dataflow パイプラインまたはジョブで問題が発生した場合に表示されるエラー メッセージと、各エラーの修正方法に関するヒントについて説明します。
ログタイプ dataflow.googleapis.com/worker-startup、dataflow.googleapis.com/harness-startup、dataflow.googleapis.com/kubelet のエラーは、ジョブ構成の問題を示します。また、通常のロギングパスが機能しない状態であることを示している場合もあります。
データの処理中にパイプラインによって例外がスローされることがあります。これらのエラーのいくつかは一過性です。たとえば、外部サービスに一時的にアクセスできない場合などです。これらのエラーには、破損したか解析不能な入力データや計算中の null ポインタを原因とするエラーなど、永続的なものもあります。
バンドル内のいずれかの要素についてエラーがスローされた場合、Dataflow はそのバンドル内の要素を処理し、バンドル全体を再試行します。バッチモードで実行している場合、失敗した項目を含むバンドルは 4 回再試行されます。1 つのバンドルが 4 回失敗すると、パイプラインが完全に失敗します。ストリーミング モードで実行している場合、失敗した項目を含むバンドルは無期限に再試行され、パイプラインが恒久的に滞るおそれがあります。
ユーザーコード(DoFn インスタンスなど)における例外が Dataflow モニタリング インターフェースで報告されます。パイプラインを BlockingDataflowPipelineRunner で実行すると、コンソールまたはターミナル ウィンドウにもエラー メッセージが表示されます。
例外ハンドラを追加することでコード内のエラーから保護することを検討してください。たとえば、ParDo で実行されたいくつかのカスタム入力検証が失敗する要素を削除する場合は、ParDo 内で try / catch ブロックを使用して、例外とログを処理し、要素を削除します。本番環境ワークロードには、未処理のメッセージ パターンを実装します。エラー数を追跡するには、集計変換を使用します。
ログファイルがない
ジョブのログが表示されない場合は、すべての Cloud Logging ログルーター シンクから resource.type="dataflow_step" を含む除外フィルタを削除します。
ログの除外フィルタの削除については、除外の削除ガイドをご覧ください。
出力内の重複
Dataflow ジョブを実行すると、重複するレコードが出力に含まれます。
この問題は、Dataflow ジョブで「1 回以上」パイプライン ストリーミング モードが使用されている場合に発生することがあります。このモードでは、レコードが少なくとも 1 回処理されます。ただし、このモードでは重複するレコードが発生する可能性があります。
ワークフローで重複レコードを許容できない場合は、ストリーミング モードを「1 回限り」に設定します。このモードでは、データがパイプラインを移動する際にレコードの削除や重複が発生しません。
ジョブで使用しているストリーミング モードを確認するには、ジョブのストリーミング モードを表示するをご覧ください。
ストリーミング モードの詳細については、パイプライン ストリーミング モードを設定するをご覧ください。
パイプライン エラー
以降のセクションでは、発生する可能性のある一般的なパイプライン エラーと、エラーを解決またはトラブルシューティングする手順について説明します。
いくつかの Cloud APIs を有効にする必要がある
Dataflow ジョブを実行しようとすると、次のエラーが発生します。
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
この問題は、プロジェクトで必要な API が有効になっていないために発生します。
この問題を解決して Dataflow ジョブを実行するには、プロジェクトで次のGoogle Cloud API を有効にします。
- Compute Engine API(Compute Engine)
- Cloud Logging API
- Cloud Storage
- Cloud Storage JSON API
- BigQuery API
- Pub/Sub
- Datastore API
詳しい手順については、 Google Cloud API の有効化に関するスタートガイド セクションをご覧ください。
「@*」と「@N」は予約されたシャーディング仕様
ジョブを実行しようとすると、ログファイルに次のエラーが表示され、ジョブが失敗します。
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
このエラーは、一時ファイル(tempLocation または temp_location)の Cloud Storage パスのファイル名にアットマーク(@)があり、その後に数字またはアスタリスク(*)が続く場合に発生します。
この問題を解決するには、アットマークの後にサポートされている文字が続くようにファイル名を変更します。
不正なリクエスト
Dataflow ジョブを実行すると、Cloud Monitoring ログに次のような一連の警告が表示されます。
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
処理遅延のためにワーカーの状態情報が古くなっているか非同期状態になったことが原因で、不正なリクエストという警告が表示されます。不正なリクエストという警告が表示されても、多くの場合、Dataflow ジョブは成功します。その場合は、警告を無視してください。
異なるロケーションでの読み取りと書き込みができない
Dataflow ジョブを実行すると、ログファイルに次のエラーが記録されることがあります。
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
このエラーは、送信元と宛先のリージョンが異なる場合に発生します。また、ステージング ロケーションと宛先が異なるリージョンに存在する場合にも発生することがあります。たとえば、ジョブが Pub/Sub から読み取り、BigQuery テーブルに書き込む前に Cloud Storage temp バケットに書き込む場合、Cloud Storage temp バケットと BigQuery テーブルは同じリージョンに存在する必要があります。
シングル ロケーションがマルチリージョン ロケーションのスコープ内であっても、シングル リージョンのロケーションとは異なるとみなされます。たとえば、us (multiple regions in the United States) と us-central1 は別々のリージョンです。
この問題を解決するには、宛先、ソース、ステージングのロケーションを同じリージョンに配置します。Cloud Storage バケットのロケーションは変更できないため、正しいリージョンに新しい Cloud Storage バケットを作成しなければならない場合があります。
接続がタイムアウトになった
Dataflow ジョブを実行すると、ログファイルに次のエラーが記録されることがあります。
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
この問題は、Dataflow ワーカーがデータソースまたは宛先との接続を確立または維持できない場合に発生します。
この問題を解決する方法は次のとおりです。
- データソースが実行されていることを確認します。
- 宛先が実行されていることを確認します。
- Dataflow パイプライン構成で使用されている接続パラメータを確認します。
- パフォーマンスの問題がソースや宛先に影響を与えていないことを確認します。
- ファイアウォール ルールで接続がブロックされていないことを確認します。
オブジェクトなし
Dataflow ジョブを実行すると、ログファイルに次のエラーが記録されることがあります。
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
通常、これらのエラーは、実行中の一部の Dataflow ジョブが同じ temp_location を使用して、パイプラインの実行時に生成された一時ジョブファイルをステージングすると発生します。複数の同時実行ジョブが同じ temp_location を共有している場合、これらのジョブが互いに一時データを実行し、競合状態が発生する可能性があります。この問題を回避するには、ジョブごとに一意の temp_location を使用することをおすすめします。
Dataflow がバックログを特定できない
Pub/Sub からストリーミング パイプラインを実行すると、次の警告が発生します。
Dataflow is unable to determine the backlog for Pub/Sub subscription
Dataflow パイプラインが Pub/Sub からデータを pull するときに、Dataflow は Pub/Sub からの情報を繰り返しリクエストする必要があります。この情報には、サブスクリプションのバックログの量と、最も古い未確認メッセージの経過時間が含まれます。内部システムの問題により、Dataflow が Pub/Sub からこの情報を取得できないことがあります。このため、バックログが一時的に蓄積する可能性があります。
詳細については、Cloud Pub/Sub を使用したストリーミングをご覧ください。
DEADLINE_EXCEEDED またはサーバー応答なし
ジョブを実行すると、RPC タイムアウト例外または次のいずれかのエラーが発生することがあります。
DEADLINE_EXCEEDED
または
Server Unresponsive
通常、次のいずれかの原因が考えられます。
ジョブで使用される Virtual Private Cloud(VPC)ネットワークにファイアウォール ルールが欠落している可能性があります。ファイアウォール ルールでは、パイプライン オプションで指定した VPC ネットワーク内の VM 間ですべての TCP トラフィックを有効にする必要があります。詳細については、Dataflow のファイアウォール ルールをご覧ください。
場合によっては、ワーカーが相互に通信できないこともあります。Dataflow Shuffle や Streaming Engine を使用しない Dataflow ジョブを実行する場合、ワーカーは VPC ネットワーク内の TCP ポート
12345と12346を使用して相互に通信する必要があります。このシナリオでは、ワーカー ハーネス名とブロックされている TCP ポートがエラーに表示されます。このエラーは、以下のいずれかの例のようになります。DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)この問題を解決するには、
gcloud compute firewall-rules createrules フラグを使用して、ポート12345と12346へのネットワーク トラフィックを許可します。次の例は、Google Cloud CLI コマンドを示しています。gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346次のように置き換えます。
FIREWALL_RULE_NAME: ファイアウォール ルールの名前NETWORK: ネットワークの名前
ジョブがシャッフルバインドされている
この問題を解決するには、次の変更を行います(複数可)。
Java
- ジョブがサービスベースのシャッフルを使用していない場合は、
--experiments=shuffle_mode=serviceを設定して、サービスベースの Dataflow Shuffle を使用するように切り替えます。詳細と可用性については、Dataflow Shuffle をご覧ください。 - 他のワーカーを追加します。パイプラインの実行時に、より大きな値の
--numWorkersを設定してみます。 - ワーカーに接続されたディスクのサイズを増やします。パイプラインの実行時に、より大きな値の
--diskSizeGbを設定してみます。 - SSD を使用する永続ディスクを使用します。パイプラインの実行時に、
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"を設定してみます。
Python
- ジョブがサービスベースのシャッフルを使用していない場合は、
--experiments=shuffle_mode=serviceを設定して、サービスベースの Dataflow Shuffle を使用するように切り替えます。詳細と可用性については、Dataflow Shuffle をご覧ください。 - 他のワーカーを追加します。パイプラインの実行時に、より大きな値の
--num_workersを設定してみます。 - ワーカーに接続されたディスクのサイズを増やします。パイプラインの実行時に、より大きな値の
--disk_size_gbを設定してみます。 - SSD を使用する永続ディスクを使用します。パイプラインの実行時に、
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"を設定してみます。
Go
- ジョブがサービスベースのシャッフルを使用していない場合は、
--experiments=shuffle_mode=serviceを設定して、サービスベースの Dataflow Shuffle を使用するように切り替えます。詳細と可用性については、Dataflow Shuffle をご覧ください。 - 他のワーカーを追加します。パイプラインの実行時に、より大きな値の
--num_workersを設定してみます。 - ワーカーに接続されたディスクのサイズを増やします。パイプラインの実行時に、より大きな値の
--disk_size_gbを設定してみます。 - SSD を使用する永続ディスクを使用します。パイプラインの実行時に、
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"を設定してみます。
- ジョブがサービスベースのシャッフルを使用していない場合は、
ユーザーコードのエンコード エラー、IOException、または予期しない動作
Apache Beam SDK と Dataflow ワーカーは共通のサードパーティ コンポーネントに依存しています。これらのコンポーネントで追加の依存関係がインポートされます。バージョンが競合すると、サービスで予期しない動作が発生することがあります。また、一部のライブラリには上位互換性がありません。リストに記載されているバージョンに固定し、実行時にその範囲内に収まるようにしなければなりません。依存関係と必要なバージョンについては、SDK とワーカーの依存関係をご覧ください。
LookupEffectiveGuestPolicies の実行中にエラーが発生した
Dataflow ジョブを実行すると、ログファイルに次のエラーが記録されることがあります。
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
このエラーは、プロジェクト全体で OS Configuration Management が有効になっている場合に発生します。
この問題を解決するには、プロジェクト全体に適用される VM Manager ポリシーを無効にします。プロジェクト全体で VM Manager ポリシーを無効にすることができない場合は、このエラーを無視して、ログ モニタリング ツールから除外できます。
Java Runtime Environment で致命的なエラーが検出された
ワーカーの起動時に次のエラーが発生します。
A fatal error has been detected by the Java Runtime Environment
このエラーは、パイプラインが Java Native Interface(JNI)を使用して Java 以外のコードを実行し、そのコードまたは JNI バインディングにエラーが含まれている場合に発生します。
googclient_deliveryattempt 属性キーのエラー
Dataflow ジョブが次のいずれかのエラーで失敗します。
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
または
Invalid extensions name: googclient_deliveryattempt
このエラーは、Dataflow ジョブに次の特性がある場合に発生します。
- Dataflow ジョブが Streaming Engine を使用している。
- パイプラインに Pub/Sub シンクがある。
- パイプラインが pull サブスクリプションを使用している。
- このパイプラインは、組み込みの Pub/Sub I/O シンクを使用する代わりに、Pub/Sub サービス API の 1 つを使用してメッセージをパブリッシュします。
- Pub/Sub が Java または C# のクライアント ライブラリを使用している。
- Pub/Sub サブスクリプションにデッドレター トピックがある。
このエラーは、Pub/Sub Java または C# クライアント ライブラリを使用し、サブスクリプションのデッドレター トピックが有効になっているときに、配信試行が delivery_attempt フィールドではなく googclient_deliveryattempt メッセージ属性にあると発生します。詳しくは、「メッセージ エラーの処理」ページの配信試行を追跡するをご覧ください。
この問題を回避するには、次の変更を行います(複数可)。
- Streaming Engine を無効にします。
- Pub/Sub サービス API の代わりに、組み込みの Apache Beam
PubSubIOコネクタを使用します。 - 別のタイプの Pub/Sub サブスクリプションを使用します。
- デッドレター トピックを削除します。
- Pub/Sub の pull サブスクリプションで Java または C# クライアント ライブラリを使用しないようにします。他のオプションについては、クライアント ライブラリのコードサンプルをご覧ください。
- パイプライン コードで属性キーが
googで始まる場合は、メッセージを公開する前にメッセージ属性を消去します。
ホットキーが検出された
次のエラーが発生します。
A hot key HOT_KEY_NAME was detected in...
このエラーは、データにホットキーが含まれている場合に発生します。ホットキーは、パイプラインのパフォーマンスに悪影響を与える数の要素が含まれるキーです。これらのキーにより、Dataflow が要素を並列に処理するため、実行時間が長くなります。
パイプラインでホットキーが検出された場合に、人が読める形式のキーをログに出力するには、ホットキー パイプライン オプションを使用します。
この問題を解決するには、データが均等に分散されていることを確認します。キーの値が多すぎる場合は、次の一連のアクションを検討してください。
- データを再入力します。
ParDo変換を適用して、新しい Key-Value ペアを出力します。 - Java ジョブでは、
Combine.PerKey.withHotKeyFanout変換を使用します。 - Python ジョブでは、
CombinePerKey.with_hot_key_fanout変換を使用します。 - Dataflow Shuffle を有効にします。
Dataflow モニタリング インターフェースでホットキーを表示するには、バッチジョブのストラグラーのトラブルシューティングをご覧ください。
Data Catalog での無効なテーブル指定
Dataflow SQL を使用して Dataflow SQL ジョブを作成すると、ログファイルに次のエラーが表示され、ジョブが失敗する可能性があります。
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
このエラーは、Dataflow サービス アカウントが Data Catalog API にアクセスできない場合に発生します。
この問題を解決するには、クエリの作成と実行に使用している Google Cloudプロジェクトで Data Catalog API を有効にします。
Dataflow サービス アカウントに roles/datacatalog.viewer ロールを割り当てます。
ジョブグラフが大きすぎる
ジョブが次のエラーで失敗する場合があります。
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
このエラーは、ジョブのグラフサイズが 10 MB を超えている場合に発生します。パイプライン内の条件によっては、ジョブグラフが上限を超えることがあります。こうした条件のうち一般的なものは次のとおりです。
- 大量のメモリ内データを含む
Create変換。 - リモート ワーカーへの送信のためにシリアル化される大きな
DoFnインスタンス。 - シリアル化する大量のデータを(通常は誤って)pull する匿名内部クラス インスタンスとしての
DoFn。 - 大規模なリストを列挙するプログラム ループの一部として有向非巡回グラフ(DAG)が使用されています。
これらの状況を回避するには、パイプラインを再構築することを検討してください。
キーの commit が大きすぎる
ストリーミング ジョブを実行すると、ワーカー ログ ファイルに次のエラーが表示されます
KeyCommitTooLargeException
このエラーは、ストリーミング シナリオで Combine 変換を使用せずに大量のデータがグループ化されている場合、または単一の入力要素から大量のデータが生成される場合に発生します。
このエラーが発生する可能性を減らすには、次の方法を使用してください。
- 単一の要素を処理しても、出力または状態の変更が制限を超えないようにします。
- 複数の要素がキーでグループ化されている場合は、キースペースを大きくして、キーごとにグループ化される要素を削減することを検討します。
- キーの要素が短期間に高頻度で発行されると、ウィンドウでそのキーのイベントが GB 単位で発生する可能性があります。このようなキーを検出するようにパイプラインを書き直し、キーがそのウィンドウに頻繁に存在することを示す出力のみを生成します。
- 交換演算と連想演算に劣線形空間
Combine変換を使用します。スペースを減らせない場合は、コンバイナを使用しないでください。たとえば、文字列を結合するだけの文字列のコンバイナは、コンバイナを使用しない場合よりも悪くなります。
7,168,000 件以上のメッセージが拒否されている
テンプレートから作成した Dataflow ジョブを実行すると、ジョブが失敗して次のエラーが表示されることがあります。
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
このエラーは、デッドレター キューに書き込まれたメッセージがサイズ上限の 7,168,000 件超えた場合に発生します。回避策として、サイズの上限が高い Streaming Engine を有効にします。Streaming Engine を有効にするには、次のパイプライン オプションを使用します。
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
リクエスト エンティティが大きすぎる
ジョブを送信すると、コンソールまたはターミナル ウィンドウに次のいずれかのエラーが表示されます。
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
ジョブの送信時に JSON ペイロードに関するエラーが発生する場合は、パイプラインの JSON 表現が最大リクエスト サイズ 20 MB を超えます。
ジョブのサイズはパイプラインの JSON 表現に関連付けられています。パイプラインが大きいほど、リクエストが大きくなります。Dataflow はリクエストを 20 MB に制限しています。
パイプラインの JSON リクエストのサイズを見積もるには、次のオプションを指定してパイプラインを実行します。
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go では、JSON としてジョブを出力することはできません。
このコマンドは、ジョブの JSON 表現をファイルに書き込みます。シリアル化されたファイルのサイズは、リクエストのサイズにほぼ相当します。リクエストにはいくつかの追加情報が含まれるため、実際のサイズはわずかに大きくなります。
パイプラインの特定の条件により、JSON 表現が上限を超えることがあります。一般的な条件は次のとおりです。
- 大量のメモリ内データを含む
Create変換。 - リモート ワーカーへの送信のためにシリアル化される大きな
DoFnインスタンス。 - シリアル化する大量のデータを(通常は誤って)pull する匿名内部クラス インスタンスとしての
DoFn。
これらの状況を回避するには、パイプラインを再構築することを検討してください。
SDK パイプライン オプションまたはステージング ファイルのリストがサイズの上限を超えている
パイプラインを実行すると、次のいずれかのエラーが発生します。
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
または
Value for field 'resource.properties.metadata' is too large: maximum size
これらのエラーは、Compute Engine メタデータの上限を超えたため、パイプラインを開始できなかった場合に発生します。これらの上限は変更できません。Dataflow は、Compute Engine メタデータをパイプライン オプションに使用します。上限については、Compute Engine のカスタム メタデータの制限事項をご覧ください。
次のシナリオでは、JSON 表現が上限を超える可能性があります。
- ステージングする JAR ファイルが過剰に多く存在する。
sdkPipelineOptionsリクエスト フィールドのサイズが過剰に大きな状態である。
パイプラインの JSON リクエストのサイズを見積もるには、次のオプションを指定してパイプラインを実行します。
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Go
Go では、JSON としてジョブを出力することはできません。
このコマンドからの出力ファイルのサイズは 256 KB 未満であることが必要です。エラー メッセージの 512 KB は、出力ファイルと Compute Engine VM インスタンスのカスタム メタデータ オプションの合計サイズを示しています。
プロジェクトで Dataflow ジョブを実行することで、VM インスタンスのカスタム メタデータ オプションのおおまかな見積もりを得ることができます。実行中の Dataflow ジョブを選択します。VM インスタンスを取得して、その VM の Compute Engine VM インスタンスの詳細ページに移動し、カスタム メタデータのセクションを確認します。カスタム メタデータとファイルの合計長は 512 KB 未満にしてください。失敗したジョブの VM は起動しないため、失敗したジョブの正確な推定は行えません。
JAR リストが 256 KB の上限に達した場合は、不要な JAR ファイルを削減してください。削減しても過剰にサイズが大きい場合は、Uber JAR を使用して Dataflow ジョブを実行してみてください。Uber JAR を作成して使用する方法を示す例については、Uber JAR をビルドしてデプロイするをご覧ください。
sdkPipelineOptions リクエスト フィールドのサイズが過剰に大きい場合は、パイプラインの実行時に次のオプションを指定します。パイプライン オプションは、Java、Python、Go で同じです。
--experiments=no_display_data_on_gce_metadata
シャッフルキーが大きすぎる
ワーカー ログファイルに次のエラーが表示されます。
Shuffle key too large
このエラーは、対応するコーダーが適用された後に、特定の (Co-)GroupByKey に発行されたシリアル化されたキーが大きすぎる場合に発生します。Dataflow では、シリアル化されたシャッフルキーに対する上限があります。
キーのサイズを小さくするか、スペース効率の良いコーダーを使用することを検討してください。
詳細については、Dataflow の本番環境の制限事項をご覧ください。
BoundedSource オブジェクトの総数が許容される上限を超えている
Java を使用してジョブを実行すると、次のいずれかのエラーが発生することがあります。
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
または
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
このエラーは、非常に多くのファイルを TextIO、AvroIO、BigQueryIO で EXPORT を介して読み取る場合や、他のファイルベース ソースから読み取っている場合に発生することがあります。特定の上限はソースの詳細に依存しますが、単一のパイプラインで数万単位のファイル数を処理できます。たとえば、AvroIO.Read にスキーマを埋め込むことで、使用するファイルが少なくなります。
また、パイプライン用にカスタム データソースを作成し、ソースの splitIntoBundles メソッドが、シリアル化時に 20 MB を超える BoundedSource オブジェクトのリストを返した場合にも、このエラーが発生することがあります。
カスタムソースの splitIntoBundles() オペレーションで生成される BoundedSource オブジェクトの合計サイズの上限は 20 MB です。
この制限を回避するには、次のいずれかの変更を行います。
NameError
Dataflow サービスを使用してパイプラインを実行すると、次のエラーが発生します。
NameError
このエラーは、DirectRunner を使用して実行する場合など、ローカルで実行するときに発生することはありません。
このエラーは、DoFn が、Dataflow ワーカーでは使用できないグローバル名前空間にある値を使用している場合に発生します。
デフォルトでは、メイン セッションで定義されたグローバルなインポート、関数、変数は、Dataflow ジョブのシリアル化時に保存されません。
この問題を解決するには、次のいずれかの方法を使用します。DoFn がメインファイルで定義され、グローバルな名前空間でインポートと関数を参照する場合は、--save_main_session パイプライン オプションを True に設定します。この変更により、グローバル名前空間の状態が pickle 化され、Dataflow ワーカーに読み込まれます。
pickle 化できないグローバル名前空間にオブジェクトが存在する場合は、pickle 化エラーが発生します。エラーが、Python ディストリビューションで使用可能なモジュールに関するものである場合は、オブジェクトが使用されているモジュールをローカルにインポートします。
たとえば、次の操作を行います。
import re … def myfunc(): # use re module
次のコマンドを使用します。
def myfunc(): import re # use re module
または、DoFn が複数のファイルにまたがっている場合は、別の方法でワークフローをパッケージ化して依存関係を管理してください。
オブジェクトはバケットの保持ポリシーの対象です
Cloud Storage バケットに書き込む Dataflow ジョブがあると、ジョブが失敗し、次のエラーが発生します。
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
次のエラーが表示されることもあります。
Unable to rename "gs://BUCKET"
最初のエラーは、Dataflow ジョブが書き込み先の Cloud Storage バケットでオブジェクト保持が有効になっている場合に発生します。詳細については、オブジェクト保持構成の有効化と使用をご覧ください。
この問題を解決するには、次のいずれかの回避策を使用します。
tempフォルダに保持ポリシーがない Cloud Storage バケットに書き込みます。ジョブが書き込むバケットから保持ポリシーを削除します。詳細については、オブジェクトの保持構成を設定するをご覧ください。
2 番目のエラーは、Cloud Storage バケットでオブジェクト保持が有効になっていることを示している場合や、Dataflow ワーカー サービス アカウントに Cloud Storage バケットへの書き込み権限がないことを示す場合があります。
2 番目のエラーが表示され、Cloud Storage バケットでオブジェクトの保持が有効になっている場合は、前述の回避策を試してください。Cloud Storage バケットでオブジェクトの保持が有効になっていない場合は、Dataflow ワーカー サービス アカウントに Cloud Storage バケットに対する書き込み権限があるかどうかを確認します。詳細については、Cloud Storage バケットにアクセスするをご覧ください。
処理が停止しているか、オペレーションが進行中
TIME_INTERVAL で指定された時間を超えて Dataflow が DoFn を実行し続け、データを戻さない場合、次のメッセージが表示されます。
Java
バージョンに応じて、次のいずれかのログ メッセージが表示されます。
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Go
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
この動作には次の 2 つの原因が考えられます。
DoFnコードが低速です。または低速な外部オペレーションの完了を待っています。DoFnコードが停止したか、デッドロックが発生したか、実行速度が異常に遅いために処理が完了しません。
どのケースに該当するかを判断するには、Cloud Monitoring ログエントリを展開してスタック トレースを確認します。DoFn コードが停止している、または問題が発生していることを示すメッセージがないか確認します。メッセージが存在しない場合、DoFn コードの実行速度に問題がある可能性があります。Cloud Profiler やその他のツールを使用してコードのパフォーマンスを調査することを検討してください。
パイプラインが Java または Scala を使用して Java VM 上に構築されている場合は、スタックしたコードの原因を調査できます。次の手順に沿って(停止したスレッドだけでなく)JVM 全体の完全なスレッドダンプを取得します。
- ログエントリに含まれるワーカー名をメモします。
- Google Cloud コンソールの Compute Engine セクションで、メモしたワーカー名の Compute Engine インスタンスを見つけます。
- SSH を使用して、その名前のインスタンスに接続します。
次のコマンドを実行します。
curl http://localhost:8081/threadz
バンドルでのオペレーションの進行中
JdbcIO から読み取るパイプラインを実行すると、JdbcIO からのパーティション読み取りが遅くなり、ワーカー ログファイルに次のメッセージが表示されます。
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
この問題を解決するには、パイプラインに次の変更を 1 つ以上行います。
パーティションを使用してジョブの並列処理を増やします。より多くの小さなパーティションで読み取ることで、スケーリングを改善します。
パーティショニング列がインデックス列か、ソースの真のパーティショニング列かを確認します。パフォーマンスを最適にするには、ソース データベースでこの列のインデックスとパーティショニングを有効にします。
lowerBoundパラメータとupperBoundパラメータを使用して、境界の検索をスキップします。
Pub/Sub 割り当てエラー
Pub/Sub からストリーミング パイプラインを実行すると、次のエラーが発生します。
429 (rateLimitExceeded)
または
Request was throttled due to user QPS limit being reached
このエラーは、プロジェクトの Pub/Sub 割り当てが不十分な場合に発生します。
プロジェクトの割り当て量が十分でないかどうかを確認するには、次の手順でクライアント エラーを確認します。
- Google Cloud コンソールに移動します。
- 左側のメニューで、[API とサービス] を選択します。
- 検索ボックスで、Cloud Pub/Sub を検索します。
- [使用状況] タブをクリックします。
- レスポンス コードを確認し、
(4xx)クライアント エラーコードを探します。
リクエストが組織のポリシーで禁止されている
パイプラインを実行すると、次のエラーが発生します。
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
このエラーは、Cloud Storage バケットがサービス境界外にある場合に発生します。
この問題を解決するには、サービス境界外のバケットへのアクセスを許可する下り(外向き)ルールを作成します。
ステージングされたパッケージにアクセスできない
成功したジョブが次のエラーで失敗することがあります。
Staged package...is inaccessible
この問題を解決するには:
- ステージングされたパッケージが削除される原因となる TTL 設定が、ステージングに使われる Cloud Storage バケットに含まれていないことをご確認ください。
Dataflow プロジェクトのワーカー サービス アカウントに、ステージングに使用される Cloud Storage バケットにアクセスする権限があることを確認します。権限のギャップの原因として、次のいずれかが考えられます。
- ステージングに使用される Cloud Storage バケットが別のプロジェクトに存在する。
- ステージングに使用される Cloud Storage バケットが、きめ細かいアクセスから均一なバケットレベルのアクセスに移行された。IAM ポリシーと ACL ポリシーの間に不整合があるため、ステージング バケットを均一なバケットレベルのアクセスに移行すると、Cloud Storage リソースの ACL が許可されなくなります。ACL には、ステージング バケットで Dataflow プロジェクトのワーカー サービス アカウントが保持する権限が含まれます。
詳細については、 Google Cloud プロジェクト間での Cloud Storage バケットへのアクセスをご覧ください。
ワークアイテムが 4 回失敗した
バッチジョブが失敗すると、次のエラーが発生します。
The job failed because a work item has failed 4 times.
このエラーは、バッチジョブの 1 回のオペレーションでワーカーコードが 4 回失敗すると発生します。Dataflow がジョブを失敗し、このメッセージが表示されます。
ストリーミング モードで実行している場合、失敗した項目を含むバンドルは無期限に再試行され、パイプラインが恒久的に滞るおそれがあります。
この失敗しきい値は構成できません。詳しくは、パイプラインのエラーと例外の処理をご覧ください。
この問題を解決するには、ジョブの Cloud Monitoring ログで 4 種類の失敗を調べてください。ワーカーログで、例外またはエラーを示す Error-level または Fatal-level ログエントリを探します。例外またはエラーが 4 回以上記録されているはずです。ログに、MongoDB などの外部リソースへのアクセスに関連する一般的なタイムアウト エラーのみが含まれている場合は、リソースのサブネットワークへのアクセス権限がワーカー サービス アカウントに付与されていることを確認します。
ポーリング結果ファイルのタイムアウト
「ポーリング結果ファイルのタイムアウト」エラーのトラブルシューティングの詳細については、Flex テンプレートのトラブルシューティングをご覧ください。
Write Correct File/Write/WriteImpl/PreFinalize に失敗した
ジョブの実行中に、ジョブが断続的に失敗し、次のエラーが発生します。
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
このエラーは、同時に実行される複数のジョブの一時保存場所として同じサブフォルダが使用されている場合に発生します。
この問題を解決するには、複数のパイプラインで一時保存場所として同じサブフォルダを使用しないようにします。パイプラインごとに、一時保存場所として使用する一意のサブフォルダを指定します。
要素が protobuf メッセージの最大サイズを超えている
Dataflow ジョブを実行し、パイプラインにサイズの大きな要素がある場合、次のようなエラーが表示されることがあります。
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
または
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
次のような警告が表示されることもあります。
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
これらのエラーは、パイプラインにサイズの大きな要素が含まれている場合に発生します。
Python SDK を使用している場合は、Apache Beam バージョン 2.57.0 以降にアップグレードしてみてください。Python SDK バージョン 2.57.0 以降では、サイズの大きな要素の処理が改善され、関連するロギングが追加されています。
アップグレード後もエラーが解決しない場合、または Python SDK を使用していない場合は、ジョブ内でエラーが発生するステップを特定し、そのステップ内の要素のサイズを小さくします。
パイプラインの PCollection オブジェクトにサイズの大きな要素がある場合、パイプラインの RAM 要件が増加します。サイズの大きな要素があると、ランタイム エラーを引き起こす可能性があります(特に、融合ステージの境界を越えた場合)。
パイプラインが大きな iterable を実体化してしまうと、サイズの大きな要素が発生する可能性があります。たとえば、GroupByKey オペレーションの出力を不要な Reshuffle オペレーションに渡すパイプラインでは、リストを単一の要素として実体化します。これらのリストには、キーごとに多くの値が含まれる可能性があります。
副入力を使用するステップでエラーが発生した場合は、副入力の使用で融合の障壁が生じる可能性があります。サイズの大きな要素を生成する変換と、それを使用する変換が同じステージに属しているかどうかを確認します。
パイプラインを構築する際は、次のベスト プラクティスに従ってください。
PCollectionsでは、1 つの大きな要素ではなく、複数の小さな要素を使用します。- 外部ストレージ システムに大きな BLOB を保存します。
PCollectionsを使用してメタデータを渡すか、要素のサイズを小さくするカスタム コーダーを使用します。 - 2 GB を超える PCollection を副入力として渡す必要がある場合は、
AsIterableやAsMultiMapなどの反復可能なビューを使用します。
Dataflow ジョブ内の単一要素の最大サイズは 2 GB に制限されています。詳細については、割り当てと上限をご覧ください。
Dataflow でマネージド変換を処理できない...
マネージド I/O を使用するパイプラインで、Dataflow が I/O 変換をサポートされている最新バージョンに自動的にアップグレードできない場合、このエラーで失敗することがあります。エラーで指定された URN とステップ名には、Dataflow でアップグレードに失敗した変換を正確に指定する必要があります。
このエラーの詳細は、ログ エクスプローラの Dataflow ログ名 managed-transforms-worker と managed-transforms-worker-startup で確認できます。
ログ エクスプローラにエラーのトラブルシューティングに十分な情報がない場合は、Cloud カスタマーケアにお問い合わせください。
アーカイブ ジョブ エラー
以降のセクションでは、API を使用して Dataflow ジョブをアーカイブしようとしたときに発生する可能性のある一般的なエラーについて説明します。
値が指定されていない
API を使用して Dataflow ジョブをアーカイブしようとすると、次のエラーが発生することがあります。
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
このエラーは、次のいずれかの原因で発生します。
updateMaskフィールドに指定されたパスの形式が正しくない。この問題は入力ミスが原因で発生することがあります。JobMetadataが正しく指定されていない。JobMetadataフィールドで、userDisplayPropertiesに Key-Value ペア"archived":"true"を使用します。
このエラーを解決するには、API に渡すコマンドが必要な形式と一致していることを確認します。詳細については、ジョブをアーカイブするをご覧ください。
API が値を認識しない
API を使用して Dataflow ジョブをアーカイブしようとすると、次のエラーが発生することがあります。
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
このエラーは、アーカイブ ジョブの Key-Value ペアで指定された値がサポートされていない場合に発生します。アーカイブ ジョブの Key-Value ペアでサポートされている値は "archived":"true" と "archived":"false" です。
このエラーを解決するには、API に渡すコマンドが必要な形式と一致していることを確認します。詳細については、ジョブをアーカイブするをご覧ください。
状態とマスクの両方は更新できない
API を使用して Dataflow ジョブをアーカイブしようとすると、次のエラーが発生することがあります。
Cannot update both state and mask.
このエラーは、同じ API 呼び出しでジョブの状態とアーカイブ ステータスの両方を更新しようとした場合に発生します。同じ API 呼び出しでジョブの状態と updateMask クエリ パラメータの両方を更新することはできません。
このエラーを解決するには、別の API 呼び出しでジョブの状態を更新します。ジョブのアーカイブ ステータスを更新する前に、ジョブの状態を更新してください。
ワークフローの変更に失敗した
API を使用して Dataflow ジョブをアーカイブしようとすると、次のエラーが発生することがあります。
Workflow modification failed.
このエラーは通常、実行中のジョブをアーカイブしようとした場合に発生します。
このエラーを解決するには、ジョブが完了するまで待ってからアーカイブします。完了したジョブは、次のいずれかのジョブ状態になります。
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
詳細については、Dataflow ジョブの完了を検出するをご覧ください。
コンテナ イメージのエラー
以降のセクションでは、カスタム コンテナの使用時に発生する可能性のある一般的なエラーと、そのエラーを解決またはトラブルシューティングする手順について説明します。エラーの先頭には通常、次のようなメッセージが表示されます。
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
「containeranalysis.occurrences.list」権限が拒否される
ログファイルに次のエラーが表示されます。
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
脆弱性スキャンには Container Analysis API が必要です。
詳細については、Artifact Analysis ドキュメントの OS スキャンの概要とアクセス制御の構成をご覧ください。
ポッドの同期エラーで「StartContainer」に失敗した
ワーカーの起動時に次のエラーが発生します。
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Pod は同じ場所に配置された Docker コンテナのグループで、Dataflow ワーカーで実行されます。このエラーは、Pod 内の Docker コンテナの 1 つを起動できない場合に発生します。障害が回復できない場合、Dataflow ワーカーは起動できず、Dataflow バッチジョブは最終的に次のようなエラーで失敗します。
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
このエラーは通常、起動時にコンテナの一つが継続的にクラッシュする場合に発生します。
根本原因を把握するには、障害の直前にキャプチャされたログを確認します。ログを分析するには、ログ エクスプローラを使用します。 ログ エクスプローラで、ログファイルのエントリをコンテナ起動エラーが発生したワーカーのログエントリに制限します。ログエントリを制限するには、次の手順を行います。
- ログ エクスプローラで、
Error syncing podログエントリを見つけます。 - ログエントリに関連付けられたラベルを表示するには、ログエントリを開きます。
resource_nameに関連付けられたラベルをクリックし、[一致エントリを表示] をクリックします。
![[ログ エクスプローラ] ページで、ログファイルを制限する手順がハイライト表示されている。](https://cloud-dot-devsite-v2-prod.appspot.com/static/dataflow/images/log-explorer-pod-error.png?hl=ja)
ログ エクスプローラでは、Dataflow ログが複数のログストリームに整理されています。Error syncing pod メッセージは、kubelet という名前のログに出力されます。ただし、障害が発生したコンテナのログは別のログストリームになる場合があります。各コンテナには名前があります。次の表を参考にして、障害が発生したコンテナに関連するログが含まれている可能性のあるログストリームを特定してください。
| コンテナ名 | ログ名 |
|---|---|
| sdk、sdk0、sdk1、sdk-0-0 など | docker |
| harness | harness、harness-startup |
| python、java-batch、java-streaming | worker-startup、worker |
| artifact | artifact |
ログ エクスプローラにクエリを実行する場合は、クエリにクエリビルダー ユーザーインターフェースに関連するログ名が含まれているか、クエリにログ名の制限がないことを確認してください。
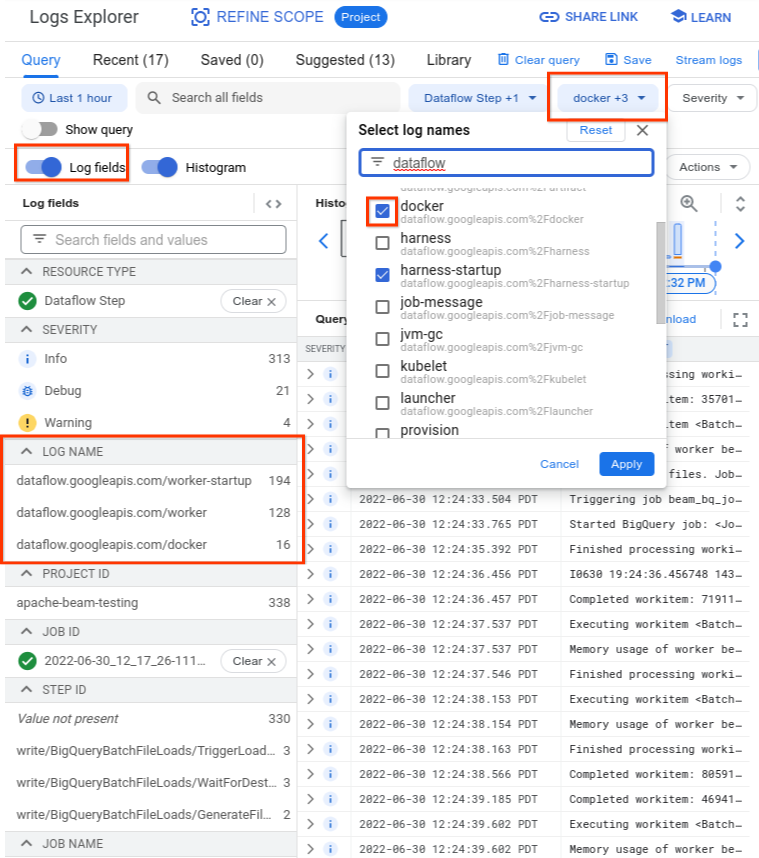
関連するログを選択すると、クエリ結果は次の例のようになります。
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
コンテナ障害の問題を報告するログは INFO として報告される場合があるため、分析に INFO ログを含めます。
コンテナ障害の一般的な原因は次のとおりです。
- Python パイプラインに、実行時にインストールされる追加の依存関係があり、インストールが失敗する。
pip install failed with errorのようなエラーが表示されることがあります。この問題は、要件の競合が原因で発生する可能性があります。また、ネットワーク構成の制限で、Dataflow ワーカーがインターネット経由で公開リポジトリから外部依存関係を pull できないことが原因で発生している可能性もあります。 メモリ不足エラーのため、ワーカーがパイプライン実行の途中で失敗する。以下のいずれかのエラーが表示されることがあります。
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
メモリ不足の問題をデバッグするには、Dataflow のメモリ不足エラーのトラブルシューティングをご覧ください。
Dataflow がコンテナ イメージを pull できない。詳しくは、イメージの pull リクエストがエラーで失敗したをご覧ください。
使用されているコンテナに、ワーカー VM の CPU アーキテクチャとの互換性がない。harness-startup のログに、
exec /opt/apache/beam/boot: exec format errorのようなエラーが記録されていることがあります。コンテナ イメージのアーキテクチャを確認するには、docker image inspect $IMAGE:$TAGを実行してArchitectureキーワードを探します。Error: No such image: $IMAGE:$TAGと表示される場合は、最初にdocker pull $IMAGE:$TAGを実行してイメージを pull する必要があります。マルチアーキテクチャ イメージのビルドについては、マルチアーキテクチャ コンテナ イメージをビルドするをご覧ください。
コンテナ障害の原因となっているエラーを特定したら、エラーを訂正してからパイプラインを再送信します。
イメージの pull リクエストがエラーで失敗した
ワーカーの起動中に、ワーカーログまたはジョブログに次のいずれかのエラーが表示されます。
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
これらのエラーは、ワーカーが Docker コンテナ イメージを pull できず起動できない場合に発生します。この問題は、次のような状況で発生します。
- カスタム SDK コンテナ イメージの URL が間違っている
- ワーカーにリモート イメージの認証情報またはネットワーク アクセス権がない
この問題を解決するには:
- ジョブでカスタム コンテナ イメージを使用している場合は、イメージ URL が正しいことと、有効なタグまたはダイジェストがあることを確認します。Dataflow ワーカーもイメージにアクセスする必要があります。
- 認証されていないマシンから
docker pull $imageを実行して、公開イメージをローカルで pull できることを確認します。
非公開イメージまたは非公開ワーカーの場合:
- Container Registry を使用してコンテナ イメージをホストする場合は、代わりに Artifact Registry を使用することをおすすめします。2023 年 5 月 15 日をもって、Container Registry は非推奨になりました。Container Registry を使用している場合は、Artifact Registry に移行できます。 Google Cloud ジョブの実行に使用しているプロジェクトとは異なるプロジェクトでイメージを使用している場合は、デフォルトの Google Cloud サービス アカウントにアクセス制御を構成してください。
- 共有 Virtual Private Cloud(VPC)を使用する場合は、ワーカーがカスタム コンテナ リポジトリ ホストにアクセスできることを確認します。
sshを使用して、実行中のジョブワーカー VM に接続し、docker pull $imageを実行してワーカーが正しく構成されていることを直接確認します。
このエラーが原因でワーカーが連続して数回失敗し、ジョブで作業が開始している場合、ジョブは次のメッセージに類似したエラーで失敗する可能性があります。
Job appears to be stuck.
イメージ自体を削除するか、Dataflow ワーカー サービス アカウントの認証情報またはイメージへのインターネット アクセスを取り消すことで、ジョブの実行中にイメージへのアクセス権を削除した場合、Dataflow はエラーのみをログに記録します。Dataflow でジョブが失敗することはありません。また、Dataflow は、長時間実行されるストリーミング パイプラインの失敗を回避し、パイプライン状態が失われないようにします。
他にも、リポジトリの割り当ての問題や停止によってエラーが発生する可能性があります。公開イメージの pull や一般的なサードパーティ リポジトリの停止によって Docker Hub の割り当てを超過する問題が発生した場合は、Artifact Registry をイメージ リポジトリとして使用することを検討してください。
SystemError: 不明なオペコード
ジョブの送信後、Python カスタム コンテナ パイプラインが次のエラーで失敗することがあります。
SystemError: unknown opcode
さらに、スタック トレースには次のようなものがあります。
apache_beam/internal/pickler.py
この問題を解決するには、メジャー バージョンからマイナー バージョンに至るまで、ローカルで使用している Python のバージョンがコンテナ イメージのバージョンと一致していることを確認してください。3.6.7 と 3.6.8 などのパッチ バージョンの違いは互換性の問題を引き起こしませんが、3.6.8 と 3.8.2 などのマイナー バージョンの違いはパイプラインのエラーを引き起こす可能性があります。
ストリーミング パイプラインのアップグレード エラー
並列置換ジョブの実行などの機能を使用してストリーミング パイプラインをアップグレードする際のエラーを解決する方法については、ストリーミング パイプラインのアップグレードのトラブルシューティングをご覧ください。
Runner v2 ハーネスの更新
Runner v2 ジョブのジョブログに次の情報メッセージが表示されます。
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
つまり、ランナー ハーネス プロセスのバージョンは、メッセージの最初に配信されてから 7 日後のある時点で自動的に更新され、その結果として処理が一時的に停止します。この一時的な停止のタイミングを制御する場合は、既存のパイプラインを更新するを参照して、最新バージョンのランナー ハーネスを含む代替ジョブを開始します。
ワーカーエラー
以降のセクションでは、発生する可能性のある一般的なワーカーエラーと、エラーを解決またはトラブルシューティングする手順について説明します。
Java ワーカー ハーネスから Python DoFn への呼び出しがエラーで失敗する
Java ワーカー ハーネスから Python DoFn への呼び出しが失敗すると、関連するエラー メッセージが表示されます。
エラーを調べるには、Cloud Monitoring のエラー ログエントリを展開し、エラー メッセージとトレースバックを確認してください。どのコードが失敗したかがわかるので、必要に応じてコードを修正できます。エラーが Apache Beam または Dataflow のバグであると思われる場合は、バグを報告してください。
EOFError: マーシャル データが短すぎる
ワーカーログに次のエラーが表示されます。
EOFError: marshal data too short
このエラーは、Python パイプライン ワーカーでディスク容量が不足したときに発生することがあります。
この問題を解決するには、デバイスに空き領域がないをご覧ください。
ディスクをアタッチできない
Persistent Disk で C3 VM を使用する Dataflow ジョブを起動しようとすると、次のエラーのいずれかまたは両方でジョブが失敗します。
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
これらのエラーは、サポートされていない Persistent Disk タイプで C3 VM を使用している場合に発生します。詳細については、C3 でサポートされているディスクタイプをご覧ください。
Dataflow ジョブで C3 VM を使用するには、ワーカーのディスクタイプとして pd-ssd を選択してください。詳細については、ワーカーレベルのオプションをご覧ください。
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Go
disk_type=pd-ssd
デバイスに空き領域がない
ジョブのディスク容量が不足すると、ワーカーログに次のエラーが表示されることがあります。
No space left on device
このエラーは、以下のいずれかの理由で発生した可能性があります。
- ワーカー永続ストレージの空き容量が不足している。これは、次のいずれかが原因で発生する可能性があります。
- ジョブが実行時に大規模な依存関係をダウンロードする
- ジョブで大規模なカスタム コンテナを使用する
- ジョブで多数の一時データがローカル ディスクに書き込まれる
- Dataflow Shuffle を使用する場合、Dataflow によりデフォルトのディスクサイズが小さく設定されます。このため、ジョブがワーカーベースのシャッフルから移行するときに、このエラーが発生することがあります。
- 1 秒あたり 50 エントリを超えるログが記録されているため、ワーカーのブートディスクがいっぱいになっている。
この問題を解決する方法は次のとおりです。
単一のワーカーに関連付けられたディスク リソースを確認するには、ジョブに関連付けられているワーカー VM の VM インスタンスの詳細を調べます。ディスク容量の一部は、オペレーティング システム、バイナリ、ログ、コンテナによって消費されます。
永続ディスクまたはブートディスクの容量を増やすには、ディスクサイズ パイプライン オプションを調整します。
Cloud Monitoring を使用して、ワーカー VM インスタンスのディスク使用量を追跡します。これを設定する手順については、Monitoring エージェントからワーカー VM の指標を受信するをご覧ください。
ワーカー VM インスタンスでシリアルポート出力を表示し、次のようなメッセージを探して、ブートディスクの容量の問題がないか確認します。
Failed to open system journal: No space left on device
ワーカー VM インスタンスが多数ある場合は、一度にすべてのインスタンスで gcloud compute instances get-serial-port-output を実行するスクリプトを作成できます。代わりに、その出力を確認することもできます。
ワーカーを 1 時間操作しないと Python パイプラインが失敗する
CPU コア数の多いワーカーマシンで Dataflow Runner V2 と Apache Beam SDK for Python を使用する場合は、Apache Beam SDK 2.35.0 以降を使用します。ジョブでカスタム コンテナを使用する場合は、Apache Beam SDK 2.46.0 以降を使用します。
Python コンテナの事前ビルドを検討してください。この手順により、VM の起動時間と水平自動スケーリングのパフォーマンスを向上させることができます。この機能を試すには、プロジェクトで Cloud Build API を有効にして、次のパラメータを指定してパイプラインを送信します。
‑‑prebuild_sdk_container_engine=cloud_build。
詳細については、Dataflow Runner V2 をご覧ください。
すべての依存関係がプリインストールされたカスタム コンテナ イメージを使用することもできます。
RESOURCE_POOL_EXHAUSTED
Google Cloud リソースを作成すると、次のエラーが発生します。
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
このエラーは、特定のゾーンにある特定のリソースの一時的な在庫切れの場合に発生します。
この問題を解決するには、待機するか、別のゾーンに同じリソースを作成します。
回避策として、ジョブに再試行ループを実装して、在庫切れエラーが発生した場合に、リソースが利用可能になるまでジョブが自動的に再試行されるようにします。再試行ループを作成するには、次のワークフローを実装します。
- Dataflow ジョブを作成し、ジョブ ID を取得します。
- ジョブのステータスが
RUNNINGまたはFAILEDになるまで、ジョブのステータスをポーリングします。- ジョブのステータスが
RUNNINGの場合は、再試行ループを終了します。 - ジョブのステータスが
FAILEDの場合は、Cloud Logging API を使用して、ジョブログで文字列ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILSをクエリします。詳細については、パイプライン ログを操作するをご覧ください。- ログに文字列が含まれていない場合は、再試行ループを終了します。
- ログに文字列が含まれている場合は、Dataflow ジョブを作成してジョブ ID を取得し、再試行ループを再起動します。
- ジョブのステータスが
サービスの停止を回避するには、複数のゾーンとリージョンにリソースを分散することをおすすめします。
ゲスト アクセラレータを使用するインスタンスはライブ マイグレーションをサポートしていない
Dataflow パイプラインがジョブの送信時に失敗し、次のエラーが発生します。
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
このエラーは、ハードウェア アクセラレータを含むワーカー マシンタイプをリクエストしたが、アクセラレータを使用するように Dataflow を構成していない場合に発生することがあります。
--worker_accelerator Dataflow サービス オプションまたは accelerator リソースヒントを使用して、ハードウェア アクセラレータをリクエストします。
Flex テンプレートを使用する場合は、--additionalExperiments オプションを使用して Dataflow サービス オプションを指定できます。正しく設定されている場合、worker_accelerator オプションは、Google Cloud コンソールのジョブの [ジョブ情報パネル] にあります。
プロジェクトの割り当て ... またはアクセス制御ポリシーがオペレーションを妨げている
次のエラーが発生します。
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
このエラーは、次のいずれかの原因で発生します。
- Dataflow ワーカーの作成で必要となる Compute Engine の割り当てのいずれかを超えています。
- VM インスタンスの作成プロセスの一部を禁止する制約が組織で設定されています(使用するアカウントや作成先のゾーンなど)。
この問題を解決する方法は次のとおりです。
VM インスタンスのログを確認する
- Cloud Logging ビューアに移動します。
- [監査対象リソース] プルダウン リストで、[VM インスタンス] を選択します。
- [すべてのログ] プルダウン リストで、[compute.googleapis.com/activity_log] を選択します。
- ログをスキャンして、VM インスタンス作成エラーに関連するエントリがないか確認します。
Compute Engine の割り当ての使用状況を確認する
次のコマンドを実行して、ターゲット ゾーンの Compute Engine リソースの使用量を Dataflow の割り当てと比較します。
gcloud compute regions describe [REGION]次のリソースの結果を確認して、割り当てを超過しているリソースがないか調べます。
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- INSTANCES
- REGIONAL_INSTANCE_GROUP_MANAGERS
必要に応じて、割り当ての変更をリクエストします。
組織のポリシーによる制約を確認する
- [組織のポリシー] ページに移動します。
- 使用しているアカウント(デフォルトでは Dataflow サービス アカウント)またはゾーン内で VM インスタンスの作成を制限する制約がないか確認します。
- 外部 IP アドレスの使用を制限するポリシーがある場合は、このジョブの外部 IP アドレスを無効にします。外部 IP アドレスをオフにする方法については、インターネット アクセスとファイアウォール ルールを構成するをご覧ください。
ワーカーからの更新待機中にタイムアウトした
Dataflow ジョブが失敗すると、次のエラーが発生します。
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
このエラーは、次のような原因で発生する可能性があります。
ワーカーの過負荷
ワーカーがメモリ領域またはスワップ領域を使い切った場合に、タイムアウト エラーが発生することがあります。この問題を解決するには、最初のステップとしてジョブを再度実行してみてください。それでもジョブが失敗し、同じエラーが発生する場合は、より多くのメモリとディスク容量のワーカーを使用してください。たとえば、次のパイプライン起動オプションを追加します。
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
ワーカータイプを変更すると、請求額に影響する可能性があります。詳細については、Dataflow のメモリ不足エラーのトラブルシューティングをご覧ください。
このエラーは、データにホットキーが含まれている場合にも発生することがあります。このシナリオでは、ジョブのほとんどの時間で一部のワーカーの CPU 使用率が高くなっていますが、ワーカー数は最大数に達していません。ホットキーと可能なソリューションの詳細については、スケーラビリティを考慮した Dataflow パイプラインの記述をご覧ください。
この問題に対するその他の解決策については、ホットキーが検出されたをご覧ください。
Python: グローバル インタープリタ ロック(GIL)
Python コードが Python 拡張機能メカニズムを使用して C / C++ コードを呼び出す場合は、計算集約型のコード部分で、Python の状態にアクセスしない拡張機能コードが Python グローバル インタープリタのロック(GIL)を解放するかどうかを確認します。GIL が長時間リリースされないと、「Unable to retrieve status info from SDK harness <...> within allowed time」や「SDK worker appears to be permanently unresponsive. Aborting the SDK」などのエラー メッセージが表示されることがあります。
Cython や PyBind などの拡張機能との連携を容易にするライブラリは、GIL のステータスを制御するためのプリミティブを備えています。Py_BEGIN_ALLOW_THREADS マクロと Py_END_ALLOW_THREADS マクロを使用して GIL を手動で解放し、Python インタープリタに制御を戻す前に再取得することもできます。詳細については、Python ドキュメントのスレッド状態とグローバル インタープリタのロックをご覧ください。
次のように、実行中の Dataflow ワーカーで GIL を保持しているスレッドのスタック トレースを取得できる場合もあります。
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
また、Python パイプラインのデフォルトの構成では、Dataflow はワーカーで実行される各 Python プロセスが 1 つの vCPU コアを効率的に使用することを想定しています。パイプライン コードが GIL の制限をバイパスしている場合(C++ で実装されたライブラリを使用するなど)は、処理要素で複数の vCPU コアのリソースが使用され、ワーカーで十分な CPU リソースを利用できない可能性があります。この問題を回避するには、ワーカーのスレッド数を減らします。
長時間実行 DoFn の設定
Runner v2 を使用していない場合は、DoFn.Setup の長時間実行呼び出しにより、次のエラーが発生する可能性があります。
Timed out waiting for an update from the worker
通常、DoFn.Setup 内で時間のかかるオペレーションは避けてください。
トピックへの一時的なエラーのパブリッシュ
ストリーミング ジョブが 1 回以上ストリーミング モードを使用し、Pub/Sub シンクに公開すると、ジョブのログに次のエラーが表示されます。
There were transient errors publishing to topic
ジョブが正しく実行されている場合、このエラーは無害であり、無視しても問題ありません。Dataflow は、バックオフ遅延で Pub/Sub メッセージの送信を自動的に再試行します。
キーのトークンが一致しないため、データを取得できない
次のエラーは、処理中の作業項目が別のワーカーに再割り当てされたことを意味します。
Unable to fetch data due to token mismatch for key
これは通常、自動スケーリング中に発生しますが、いつでも発生する可能性があります。影響を受ける作業は再試行されます。このエラーは無視してください。
Java の依存関係に関する問題
クラスとライブラリに互換性がない場合、Java の依存関係に関する問題が発生する可能性があります。パイプラインで Java の依存関係に関する問題がある場合は、次のいずれかのエラーが発生する可能性があります。
NoClassDefFoundError: このエラーは、実行時にクラス全体を使用できない場合に発生します。これは、一般的な構成の問題、または Beam の protobuf バージョンとクライアントが生成した proto の非互換性(例: この問題)が原因で発生する可能性があります。NoSuchMethodError: このエラーは、クラスパス内のクラスが正しいメソッドを含まないバージョンを使用している場合や、メソッドの署名が変更された場合に発生します。NoSuchFieldError: このエラーは、クラスパスのクラスが、実行時に必要なフィールドがないバージョンを使用している場合に発生します。FATAL ERROR in native method: このエラーは、組み込み依存関係を正しく読み込めない場合に発生します。uber JAR(シェーディング済み)を使用する場合は、署名を使用するライブラリ(Conscrypt など)を同じ JAR に含まないようにします。
パイプラインにユーザー固有のコードと設定が含まれている場合、そのコードにライブラリの混合バージョンを含めることはできません。依存関係管理ライブラリを使用している場合は、Google Cloud ライブラリ BOM を使用することをおすすめします。
Apache Beam SDK を使用している場合、正しいライブラリ BOM をインポートするには、beam-sdks-java-io-google-cloud-platform-bom を使用します。
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
詳細については、Dataflow でパイプラインの依存関係を管理するをご覧ください。
InaccessibleObjectException(JDK 17 以降)
Java プラットフォームの Standard Edition Development Kit(JDK)バージョン 17 以降でパイプラインを実行すると、ワーカー ログファイルに次のエラーが表示されることがあります。
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Java バージョン 9 以降では、JDK 内部にアクセスするためにオープン モジュールの Java 仮想マシン(JVM)オプションが必要になります。このため、この問題が発生します。Java 16 以降のバージョンでは、JDK 内部にアクセスするために常にオープン モジュールの JVM オプションが必要になります。
この問題を解決するには、Dataflow パイプラインにモジュールを渡して開くときに、jdkAddOpenModules パイプライン オプションで MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)* 形式を使用します。この形式を使用すると、必要なライブラリにアクセスできます。
たとえば、エラーが module java.base does not "opens java.lang" to unnamed module @... の場合は、パイプラインの実行時に次のパイプライン オプションを含めます。
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
詳細については、DataflowPipelineOptions クラスのドキュメントをご覧ください。
Error Reporting ワークアイテムの進行状況
Java パイプラインで Running V2 を使用していない場合は、次のエラーが表示されることがあります。
Error reporting workitem progress update to Dataflow service: ...
このエラーは、ソースの分割中など、ワークアイテムの進行状況の更新中に例外が処理されない場合に発生します。ほとんどの場合、Apache Beam ユーザーコードが未処理の例外をスローすると、作業アイテムが失敗し、パイプラインが失敗します。ただし、Source.split の例外は、コードのその部分が作業アイテムの外部にあるため、抑制されます。そのため、エラーログのみが記録されます。
このエラーは、断続的に発生する場合は通常問題ありません。ただし、Source.split コード内で例外を適切に処理することを検討してください。
BigQuery コネクタエラー
以下のセクションでは、発生する可能性のある BigQuery コネクタの一般的なエラーと、そのエラーを解決またはトラブルシューティングする手順について説明します。
quotaExceeded
BigQuery コネクタを使用してストリーミング挿入で BigQuery に書き込みを行うと、書き込みスループットが想定より低くなり、次のエラーが発生する可能性があります。
quotaExceeded
パイプラインが BigQuery ストリーミング挿入の割り当て上限を超えていると、スループットが遅くなる可能性があります。この場合、Dataflow ワーカーログに BigQuery の割り当てに関するエラー メッセージが表示されます(quotaExceeded エラーを探してください)。
quotaExceeded エラーが表示される場合は、この問題を解決してください。
- Apache Beam SDK for Java を使用している場合は、BigQuery シンク オプション
ignoreInsertIds()を設定します。 - Apache Beam SDK for Python を使用している場合は、
ignore_insert_idsオプションを使用します。
これらの設定により、プロジェクトごとに 1 GB/秒の BigQuery ストリーミング挿入スループットが実現します。自動メッセージ重複排除に関する注意点については、BigQuery のドキュメントをご覧ください。BigQuery ストリーミング挿入の割り当てを 1 Gbps 以上に増やす場合は、 Google Cloud コンソールからリクエストを送信してください。
ワーカーログに割り当て関連のエラーがない場合は、デフォルトのバンドルまたは一括処理関連のパラメータが、パイプラインのスケーリングに十分な並列処理を提供していない可能性があります。ストリーミング挿入を使用して BigQuery に書き込みを行う場合、想定されるパフォーマンスを実現するために、いくつかの Dataflow BigQuery コネクタに関連する構成を調整できます。たとえば、Apache Beam SDK for Java の場合は、最大ワーカー数に合わせて numStreamingKeys を調整します。また、insertBundleParallelism を増やして、より多くの並列スレッドを使用して BigQuery への書き込みを行うように BigQuery コネクタを構成します。
Apache Beam SDK for Java で利用可能な構成については、BigQueryPipelineOptions をご覧ください。また、Apache Beam SDK for Python で利用可能な構成については、WriteToBigQuery 変換をご覧ください。
rateLimitExceeded
BigQuery コネクタを使用すると、次のエラーが発生します。
rateLimitExceeded
このエラーは、BigQuery で短時間に送信された API リクエストが多すぎる場合に発生します。BigQuery では、短期間の割り当て上限が適用されます。Dataflow パイプラインが一時的に割り当ての上限を超える可能性があります。この場合、Dataflow パイプラインから BigQuery への API リクエストが失敗することがあり、その場合はワーカーログに rateLimitExceeded エラーが記録されます。
Dataflow が再試行するため、このようなエラーは無視してかまいません。パイプラインが rateLimitExceeded エラーの影響を受けると思われる場合は、Cloud カスタマーケアにお問い合わせください。
その他のエラー
以降のセクションでは、発生する可能性のあるその他のエラーと、エラーを解決またはトラブルシューティングする手順について説明します。
sha384 を割り当てることができない
ジョブは正常に実行されますが、ジョブのログに次のエラーが表示されます。
ima: Can not allocate sha384 (reason: -2)
ジョブが正しく実行されている場合、このエラーは無害であり、無視しても問題ありません。ワーカー VM のベースイメージがこのメッセージを生成する場合があります。Dataflow は、根本的な問題に自動的に応答して対処します。
このメッセージのレベルを WARN から INFO に変更する機能リクエストがあります。詳細については、Dataflow システム起動エラーのログレベルを WARN または INFO に引き下げるをご覧ください。
動的プラグイン プローバーの初期化でエラーが発生する
ジョブは正常に実行されますが、ジョブのログに次のエラーが表示されます。
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
ジョブが正しく実行されている場合、このエラーは無害であり、無視しても問題ありません。このエラーは、Dataflow ジョブが必要な書き込み権限を付与されていない状態でディレクトリの作成を試みて、タスクが失敗した場合に発生します。ジョブが成功した場合は、ディレクトリが不要であった、または Dataflow が根本的な問題に対処したことを示しています。
このメッセージのレベルを WARN から INFO に変更する機能リクエストがあります。詳細については、Dataflow システム起動エラーのログレベルを WARN または INFO に引き下げるをご覧ください。
pipeline.pb のようなオブジェクトが存在しない
JOB_VIEW_ALL オプションを使用してジョブを一覧表示すると、次のエラーが発生します。
No such object: BUCKET_NAME/PATH/pipeline.pb
このエラーは、ジョブのステージング ファイルから pipeline.pb ファイルを削除する場合に発生することがあります。
Pod の同期をスキップする
ジョブは正常に実行されますが、ジョブのログに次のいずれかのエラーが表示されます。
Skipping pod synchronization" err="container runtime status check may not have completed yet"
または
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
ジョブが正常に実行された場合、これらのエラーは無害であり、無視しても問題ありません。メッセージ container runtime status check may not have completed yet は、Kubernetes kubelet がコンテナ ランタイムの初期化を待機しているために Pod の同期をスキップしている場合に生成されます。このシナリオは、コンテナ ランタイムが最近開始された場合や再起動している場合など、さまざまな理由で発生します。
メッセージに PLEG is not healthy: pleg has yet to be successful が含まれている場合、kubelet は Pod Lifecycle Event Generator(PLEG)が正常な状態になるまで待機してから Pod を同期します。PLEG は、kubelet が Pod の状態を追跡するために使用するイベントを生成します。
このメッセージのレベルを WARN から INFO に変更する機能リクエストがあります。詳細については、Dataflow システム起動エラーのログレベルを WARN または INFO に引き下げるをご覧ください。
推奨事項
Dataflow の分析情報によって生成された推奨事項については、分析情報をご覧ください。