Dataflow モニタリング インターフェースでは、ストリーミング ジョブの自動スケーリングのモニタリング グラフを表示できます。これらのグラフには、パイプライン ジョブの期間中の指標が表示され、次の情報が含まれます。
- 任意の時点においてジョブで使用されるワーカー インスタンスの数
- 自動スケーリング ログファイル
- 推定バックログの推移
- 平均 CPU 使用率の推移
バックログと CPU 使用率の指標をワーカーのスケーリング イベントに関連付けることができるように、グラフは垂直方向に配置されます。
Dataflow の自動スケーリングの決定方法について詳しくは、自動チューニング機能のドキュメントをご覧ください。Dataflow のモニタリングと指標の詳細については、Dataflow モニタリング インターフェースを使用するをご覧ください。
自動スケーリングのモニタリング グラフにアクセスする
Google Cloud consoleを使用すると、Dataflow モニタリング インターフェースにアクセスできます。[自動スケーリング] 指標タブにアクセスするには、次の操作を行います。
- Google Cloud コンソールにログインします。
- Google Cloud プロジェクトを選択します。
- ナビゲーション メニューを開きます。
- [分析] で、[Dataflow] をクリックします。Dataflow ジョブのリストとそれぞれのステータスが表示されます。
- モニタリングするジョブをクリックし、[自動スケーリング] タブをクリックします。
自動スケーリング指標をモニタリングする
Dataflow サービスは、自動スケーリングのジョブを実行するために必要なワーカー インスタンスの数を自動的に選択します。ワーカー インスタンスの数は、ジョブの要件に応じて時間とともに変化する可能性があります。
自動スケーリング指標は、Dataflow インターフェースの [自動スケーリング] タブで確認できます。各指標は、次のダッシュボードにまとめられています。
自動スケーリングのアクションバーには、現在の自動スケーリングのステータスとワーカー数が表示されます。
自動スケーリング
[自動スケーリング] グラフには、現在のワーカー数、目標ワーカー数、ワーカーの最小数と最大数の時系列グラフが表示されます。

自動スケーリング ログを表示するには、[Show autoscaling logs] をクリックします。
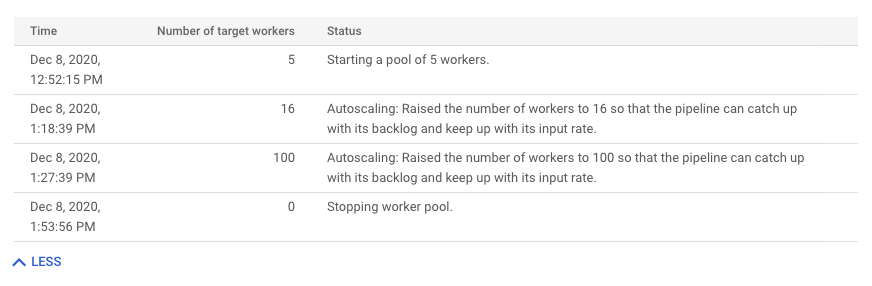
自動スケーリングの変更履歴を表示するには、[その他の履歴] をクリックします。パイプラインのワーカーの履歴情報のテーブルが表示されます。この履歴には、ワーカー数が最小ワーカー数または最大ワーカー数に達したかなどの自動スケーリング イベントが含まれます。
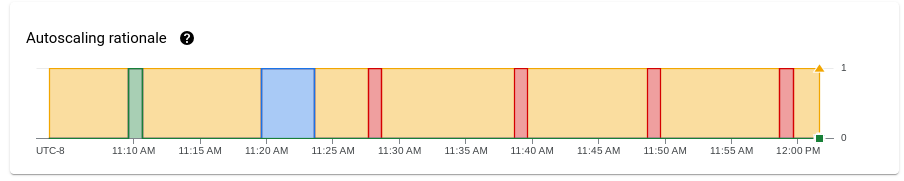
自動スケーリングの理由(Streaming Engine のみ)
[自動スケーリングの理由] グラフには、指定した期間にスケールアップまたはスケールダウンが行われた理由や、何もアクションを起こさなかった理由が表示されます。
特定の時点の理由の説明を表示するには、グラフの上にポインタを置きます。
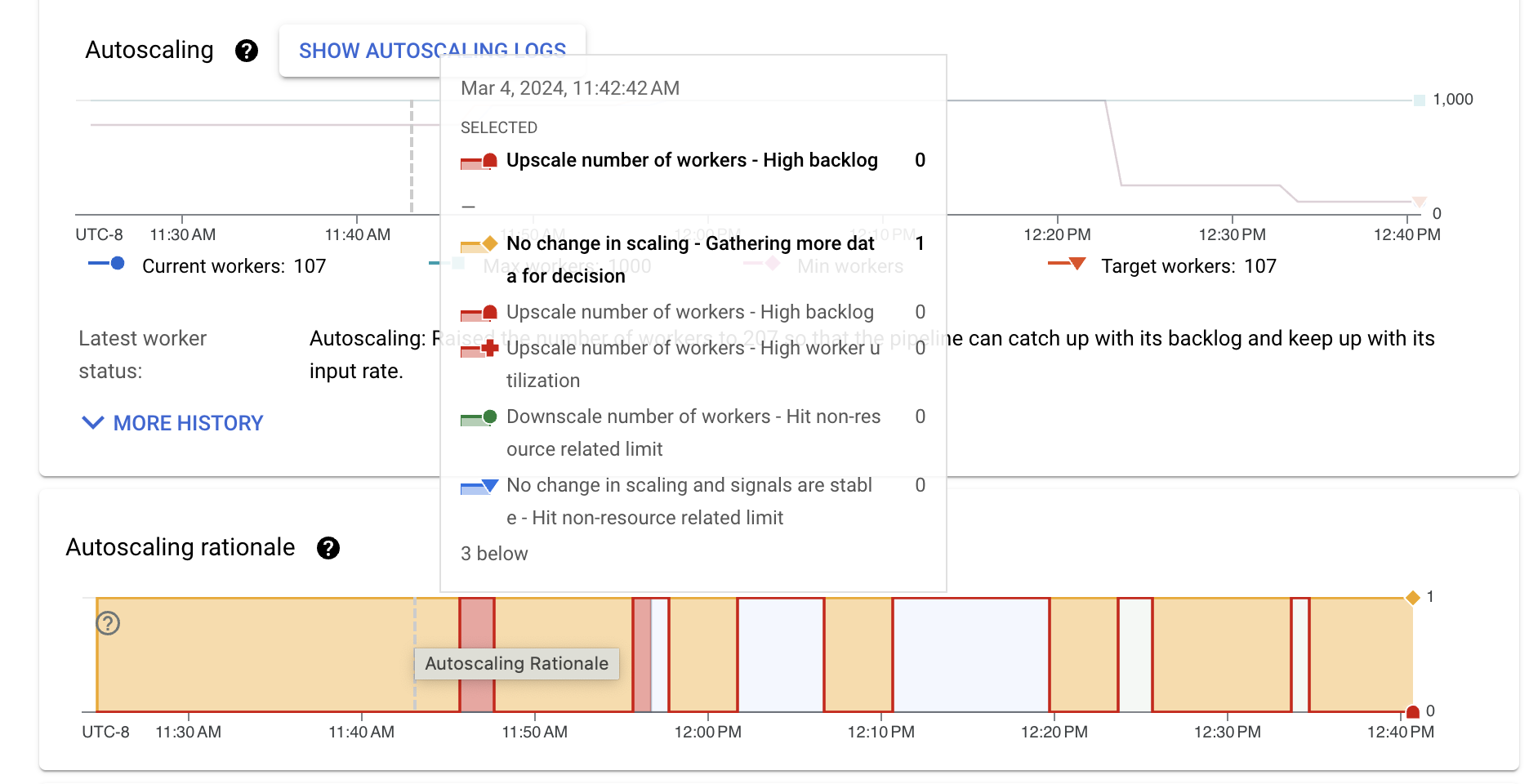
次の表に、スケーリング アクションと考えられる理由を示します。
| スケーリング アクション | 理由 | 説明 |
|---|---|---|
| スケーリングに変化なし | 判断のためにさらにデータを収集 | オートスケーラーで、スケールアップまたはスケールダウンするための十分なシグナルがありません。たとえば、ワーカープールのステータスが最近変更された場合や、バックログまたは使用率の指標が変動している場合などです。 |
| スケーリングに変化はなく、シグナルは安定 | リソースに関連しない上限に到達 | スケーリングは、キーの並列処理や、構成された最小ワーカー数と最大ワーカー数などの制限によって制約されます。 |
| バックログが少なく、ワーカーの使用率が高い | パイプラインの自動スケーリングは、現在のトラフィックと構成により安定した値に収束しています。スケーリングの変更は必要ありません。 | |
| スケールアップ | バックログが多い | バックログを減らすためにスケールアップします。 |
| ワーカーの使用率が高い | 目標 CPU 使用率を達成するためにスケールアップします。 | |
| リソースに関係のない上限に到達 | ワーカーの最小数が更新され、現在のワーカー数は構成された最小数を下回っています。 | |
| スケールダウン | ワーカーの使用率が低い | スケールダウンして、目標 CPU 使用率を達成します。 |
| リソースに関係のない上限に到達 | ワーカーの最大数が更新され、現在のワーカー数は構成された最大数を上回っています。 |
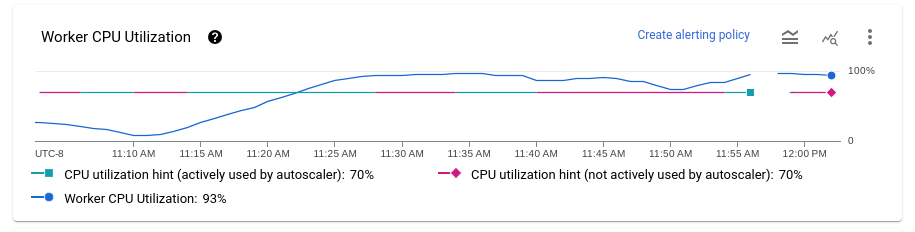
ワーカー CPU 使用率
CPU 使用率は、使用されている CPU の量を処理可能な CPU の量で割ったものです。平均 CPU 使用率グラフには、すべてのワーカーの平均 CPU 使用率の推移、ワーカー使用率のヒント、Dataflow がヒントをターゲットとして積極的に使用したかどうかが表示されます。
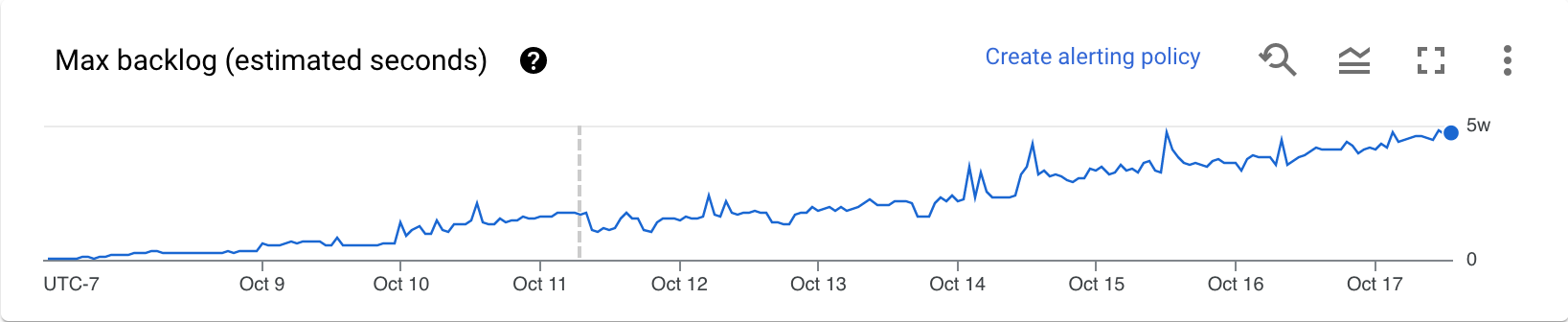
バックログ(Streaming Engine のみ)
最大バックログ グラフは、処理待ちの要素に関する情報を示します。グラフには、新しいデータがなく、スループットに変化がない場合に、現在のバックログを使用するために必要な時間(秒単位)の推定値が表示されます。バックログの推定時間は、スループットと、まだ処理が必要な入力ソースからのバックログ バイト数の両方から計算されます。この指標は、スケールアップまたはスケールダウンを行うタイミングを判断するために、ストリーミング自動スケーリング機能で使用されます。
このグラフのデータは、Streaming Engine を使用するジョブでのみ使用できます。ストリーミング ジョブが Streaming Engine を使用しない場合、グラフは空になります。
推奨事項
ここでは、パイプラインで発生する可能性のある動作と、自動スケーリングを調整する方法について説明します。
過度のダウンスケーリング。目標 CPU 使用率が高すぎると、Dataflow がスケールダウンし、バックログが増加し始め、安定したワーカー数に収束するのではなく Dataflow がスケールアップして補正するというパターンが見られる場合があります。この問題を軽減するには、ワーカー使用率のヒントを低く設定してみてください。バックログが増加し始めた時点の CPU 使用率を確認し、使用率のヒントをその値に設定します。
アップスケーリングが遅すぎる。アップスケーリングが遅すぎると、トラフィックの急増に追いつかず、レイテンシが増加する可能性があります。ワーカー使用率のヒントを減らして、Dataflow がより迅速にスケールアップするようにします。バックログが増加し始めた時点の CPU 使用率を確認し、使用率のヒントをその値に設定します。レイテンシとコストの両方をモニタリングしてください。プロビジョニングするワーカー数を増やすと、ヒント値が小さくなり、パイプラインの総コストが増加する可能性があります。
過剰なアップスケーリング。過剰なスケールアップにより費用が増加している場合は、ワーカー使用率のヒントの増加を検討してください。レイテンシをモニタリングして、シナリオの許容範囲内に収まっていることを確認します。
詳細については、ワーカー使用率のヒントを設定するをご覧ください。新しいワーカー使用率のヒント値を試すときは、調整するたびに、パイプラインが安定するまで数分待ってから確認してください。