Bevor Sie eine SAP HANA-Datenbank schützen können, müssen Sie die Compute Engine-Instanz einbinden.
SAP HANA-Datenbankanwendung erkennen und schützen
- LVM-Sicherungen schlagen bei jeder Backint-Einrichtung für Drittanbieter-Sicherungen fehl
- Die Wiederherstellung ist aufgrund einer Unterbrechung der Wiederherstellungskette beeinträchtigt
- Bei einer vollständigen und inkrementellen Sicherung kann es zu verwaisten inkrementellen Sicherungen kommen, die Probleme bei der Wiederherstellung verursachen.
Folgen Sie der Anleitung unten, um SAP HANA-Instanzen mit horizontaler Skalierung zu erkennen und zu schützen:
Wählen Sie in der Managementkonsole auf der Seite App Manager > Applications (Anwendungsmanager> Anwendungen) die Option Add Application (Anwendung hinzufügen) aus.
Wählen Sie im Assistenten Anwendung hinzufügen die Option SAP HANA aus.
Folgen Sie dem Assistenten:
Wählen Sie im Bereich Auswählen die zu verwaltende Datenbank aus.
Wenden Sie die Richtlinienvorlage und das Ressourcenprofil im Abschnitt Verwalten an. Sie haben sie in Richtlinienvorlagen und Ressourcenprofile definieren erstellt.
Klicken Sie im Bereich Konfigurieren auf Anwendungseinstellungen.
Wählen Sie im Fenster Anwendungseinstellungen die Sicherungsmethode aus. Die Methode basiert auf Ihren Anforderungen und den Informationen unter SAP-Produktionsumgebung vor Datenverlust, Fehlern und Beschädigung schützen.
Auf dem Tab Anwendungseinstellungen können Sie anwendungsspezifische Einstellungen ändern. Achten Sie darauf, dass Sie Folgendes berücksichtigen:
HANA-DB-Userstore-Schlüssel: Dies ist der SAP HANA-hdbuserstore-Schlüssel für die zuvor erstellte Systemdatenbank. Dieses Feld muss ausgefüllt werden.
Prozentsatz des reservierten Speicherplatzes in der Volume-Gruppe: Dieser Wert ist für die Sicherung auf Volume-Ebene erforderlich, um die erforderliche Menge an temporärem freien Speicherplatz in der LVM-Volume-Gruppe für Snapshots zu ermitteln. Der empfohlene Wert ist 20%.
Methode zum Erstellen von Back-ups:
Persistent Disk-Snapshot verwenden: Dies ist der standardmäßige Persistent Disk-Snapshot, der von Compute Engine verwendet wird. Wählen Sie diese Option für HANA-Datenbanken aus, die in einer Compute Engine-Instanz ausgeführt werden. Wenn Sie diese Methode verwenden können, lesen Sie den Abschnitt .
Sicherung auf Volume-Ebene verwenden: Verwenden Sie LVM-Snapshots auf Volume-Ebene mit CBT unter Linux auf einer blockbasierten Staging-Festplatte. Bei dieser Option wird die SAP HANA-Savepoint-API verwendet, damit Sie Sicherungen erstellen können, die immer inkrementell sind. Dazu müssen das Daten- und das Logvolumen der HANA-Datenbank LVM-verwaltet sein. Wenn Sie Staging-Laufwerke mit dem NFS-Protokoll verwenden, können Sie keine Sicherungen auf Volume-Ebene verwenden.
Vollständige und inkrementelle Sicherung verwenden: Dies ist die ältere dateibasierte Sicherung und Wiederherstellung. Mit dieser Methode zum „Dateiexport“ können keine virtuellen Datenbanken erstellt werden. Sie können diese Option für Block- und NFS-Staging-Laufwerke auswählen. Diese Methode unterstützt nur ältere Backint-Sicherungen und die physische Wiederherstellung.
Aufbewahrung von Produktions-DB-Logs in Stunden: Am Ende jeder Logsicherung wird die Logbereinigung ausgeführt und alle Logs gelöscht, die älter als die hier angegebene Anzahl von Stunden sind. Wenn beispielsweise 4 Stunden angegeben sind, werden alle Logs gelöscht, die älter als ((Startzeit der Logsicherung) – (4 Stunden)) sind. Der Standardwert ist 2 Stunden.
Aufbewahrung des Produktionskatalogs in Tagen: Dies ist die Aufbewahrung von Katalogmetadaten in Tagen. Die HANA-Katalogmetadaten (Tabelle „m_backup_catalog“) werden von Logs bereinigt, die älter als die angegebene Anzahl von Tagen sind. Wenn beispielsweise 14 Tage angegeben sind, werden Daten aus dem HANA-Katalog gelöscht, die älter als ((der aktuelle Tag) – (14 Tage)) sind. Der Standardwert ist 7 Tage.
Klicken Sie auf Speichern > Weiter und dann auf Fertigstellen.
Die Datenbank wird in der Liste App Manager Applications mit einem grünen Schild angezeigt, das darauf hinweist, dass der Sicherungsplan angewendet wurde.
HANA 1+n- und HANA-Datenbanken mit horizontaler Skalierung sichern
Dieser Abschnitt enthält Informationen zum Schutz von HANA 1+n und HANA Scale-Out.
HANA 1+n schützen
Wenn Sie einen HANA-Cluster mit 1+n-Replikation als einzelne Anwendung schützen möchten, hat die Anwendung nach der Anwendungserkennung den Clusterhost als SID name_cluster. Wenn sr1 beispielsweise die HANA-Instanz ist, lautet der Anwendungsname sr1 und der Hostname sr1_cluster in der Liste App Manager Applications.
Das Ziel für die HANA-Logsicherung muss für zwei Knoten freigegeben sein. Bei einem Failover werden die Datenbank- und Logsicherung automatisch auf den aktuellen primären Knoten übertragen. Logsicherungen werden vom aktuellen primären Knoten aus durchgeführt. Dabei werden die letzten Logs vom alten primären Knoten sowie neue Logs vom neuen primären Knoten erfasst. Führen Sie die Vorbereitungsschritte unter SAP HANA-Datenbanken für den Schutz vorbereiten aus.
HANA 1+n wird immer als Clusteranwendung mit allen Knotendetails in den Metadaten erkannt. Nach der Anwendungserkennung hat die Anwendung den Cluster-Host als (HANA-SID-Name)cluster(Site-ID)_(HANA-Hardware-ID). Wenn sr1 beispielsweise die HANA-Instanz ist, lautet der Anwendungsname sr1 und der Hostname sr1cluster<…> in der Liste „Anwendungen“ im App Manager.
Es empfiehlt sich, nach jeder Änderung der Konfiguration von Clusternknoten eine erzwungene Erkennung auszuführen, z. B. nach dem Hinzufügen oder Löschen eines Knotens aus dem Cluster. Wenn ein Knoten nach der Erkennung und dem Schutz entfernt oder hinzugefügt wird, wird die Konfiguration nicht automatisch in den Backup and DR-Metadaten aktualisiert. Dies kann zu Problemen bei der Sicherung führen.
Voraussetzungen für den Schutz von SAP HANA-Instanzen und ‑Datenbanken (1+n)
Bevor Sie SAP HANA-Instanzen schützen, müssen Sie Folgendes sicherstellen:
- Alle SAP HANA-Server oder Compute Engine-Instanzen des SAP HANA-Clusters müssen in den Backup- und DR-Dienst aufgenommen worden sein.
- Auf allen SAP HANA-Servern oder Compute Engine-Instanzen des SAP HANA-Clusters muss der Backup and DR-Agent installiert sein.
Auf allen SAP HANA-Servern oder Compute Engine-Instanzen des SAP HANA-Clusters muss ein Secret unter App Manage > Manage > Host > Backup and DR Agent Settings > Secret angewendet werden.
Wenn für Hosts virtuelle IP-Adressen konfiguriert sind, fügen Sie bei der Erkennung nur die virtuelle IP-Adresse und den Hostnamen des Hosts hinzu.
Der Backup and DR-Agent muss auf allen Knoten installiert sein.
Auf den Hosts müssen Ports geöffnet werden, damit die Kommunikation über Port 5106 möglich ist. Dazu ist eine Firewallregel für eingehenden Traffic erforderlich, bei der die Sicherungs-/Wiederherstellungs-Appliance die Quelle, der Host, auf dem der Agent ausgeführt wird, das Ziel und der Zielport 5106 ist. Port 5106 muss der für die Appliance erstellten Standard-Ingress-Regel nicht hinzugefügt werden, da die Appliance als Ziel angegeben ist.
Der Speicherort für HANA-Logsicherungen muss auf „shared“ (freigegeben) – NFS festgelegt sein.
HANA-System mit horizontaler Skalierung schützen
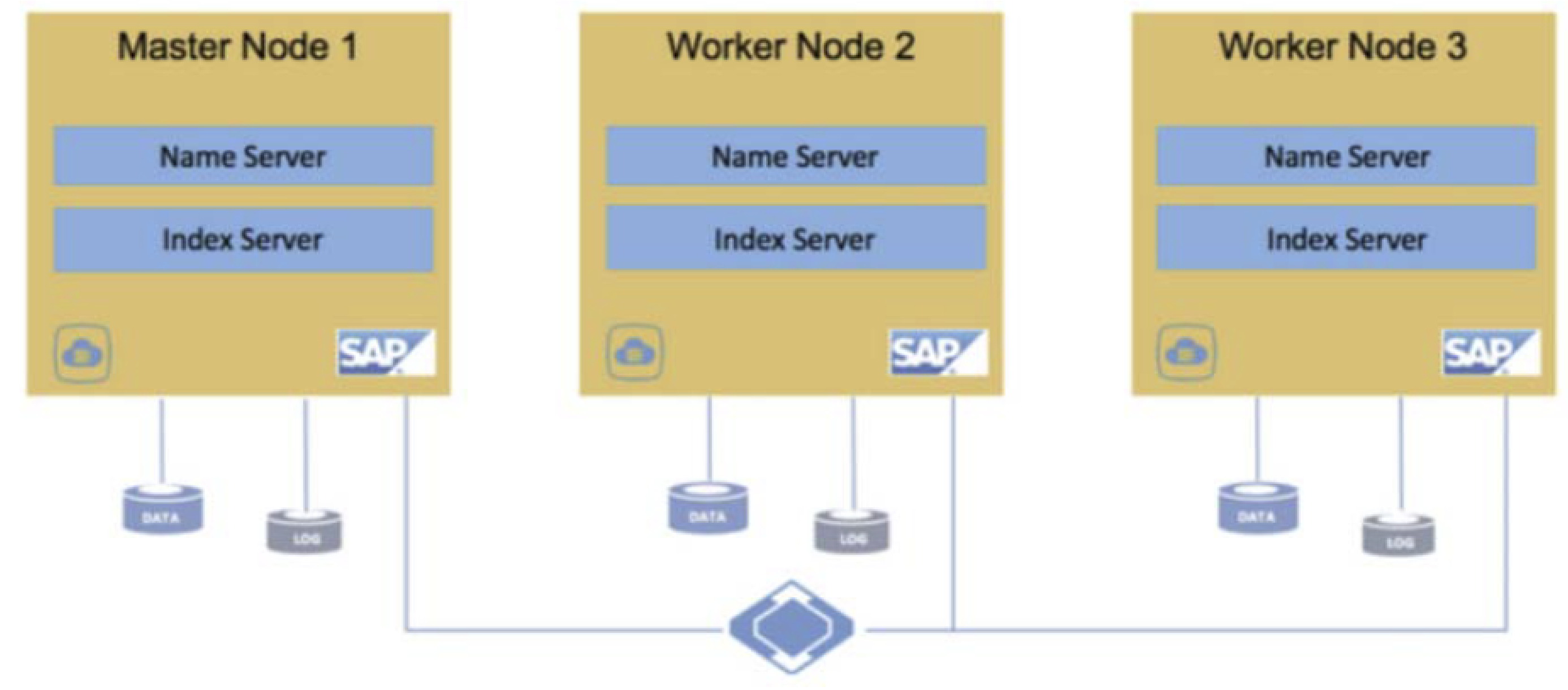
Voraussetzungen für den Schutz von SAP HANA-Systemen mit horizontaler Skalierung
Bevor Sie SAP HANA-Systeme mit horizontaler Skalierung schützen, müssen Sie Folgendes ausführen:
- Wenn für Hosts virtuelle IP-Adressen konfiguriert sind, fügen Sie bei der Erkennung nur die virtuelle IP-Adresse und den zugehörigen Hostnamen des Hosts hinzu.
- Der Backup and DR-Agent muss auf allen Knoten installiert sein.
- Auf den Hosts müssen Ports geöffnet werden, damit die Kommunikation über Port 5106 möglich ist. Dazu ist eine Firewallregel für eingehenden Traffic erforderlich, bei der die Sicherungs-/Wiederherstellungs-Appliance die Quelle, der Host, auf dem der Agent ausgeführt wird, das Ziel und der Zielport 5106 ist. Außerdem muss Port 5106 nicht der standardmäßigen Ingress-Regel hinzugefügt werden, die für die Appliance erstellt wurde, da die Appliance als Ziel angegeben ist.
- Für die Backint-Datei-basierte Sicherung (Vollständig + Inkrementell) muss der HANA-Protokollsicherungsort auf „Freigegeben“ (NFS) festgelegt werden. Weitere Informationen finden Sie unter Host in der Verwaltungskonsole hinzufügen.
Schutz von Speichersnapshots
- Daten- und Logvolumen werden nicht auf alle Knoten verteilt.
- Daten- und Log-Volumes werden vom Logical Volume Manager verwaltet.
- Prüfen Sie, ob die Verzeichnisse mnt000* auf den lokalen Mount-Punkten vorhanden sind, um die primären und sekundären Knoten zu identifizieren.
Folgen Sie der Anleitung unter SAP HANA-Datenbanken für den Schutz vorbereiten.
Backup and DR Service-Dokumentation für SAP HANA-Systeme mit horizontaler Skalierung
Diese Seite ist eine von mehreren Seiten, die sich speziell mit dem Schutz und der Wiederherstellung von SAP HANA-Instanzen mit horizontaler Skalierung mit dem Backup- und DR-Dienst befassen. Weitere Informationen finden Sie auf den folgenden Seiten:
- Backup and DR für SAP HANA-Systeme mit horizontaler Skalierung
- SAP HANA-Scale-out-Instanzen für die Sicherung vorbereiten
- SAP HANA-Host mit horizontaler Skalierung hinzufügen und seine Datenbanken erkennen und schützen
- Staging-Laufwerkformat und Sicherungsmethode für SAP HANA-Scale-out konfigurieren
- Anwendungsdetails und -einstellungen für SAP HANA-Scale-out-Instanzen festlegen
- HANA 1+n- und HANA-Datenbanken mit horizontaler Skalierung sichern
- SAP HANA-Instanzen mit horizontaler Skalierung wiederherstellen
- SAP HANA-Backup mit horizontaler Skalierung als Standardmount bereitstellen
- SAP HANA-Sicherung mit horizontaler Skalierung als virtuelle Datenbank einbinden
- SAP HANA-Scale-out-Sicherung für die sofortige Wiederherstellung auf einem beliebigen Ziel bereitstellen und migrieren