Cloud SQL lets you restore your instances from a backup, or by performing point-in-time recovery (PITR). This lets you recover an instance to a specific period or time by either restoring the back to an existing instance, or restoring the backup to a new instance. To restore, you can use the backup of a live or deleted instance. The restore operation takes the source instance's settings, databases, and users, and sets them in the target instance you choose.
When you restore to a new instance, the target instance can be in a different region or project from the source instance. The target instance can also use a different number of cores or amount of memory than the source instance.
Cloud SQL always sets the storage capacity of the target instance to the maximum value of the size of both the configured disk and the backup disk. The backup disk is the size of the disk when the backup is taken.
When performing a restore on an instance, consider the following:
- The restore operation overwrites all data on the target instance.
- The flags from the source instance aren't restored. Any flags previously set on the target instance are retained after the restore.
- The target instance is unavailable for connections during the restore operation; existing connections are lost.
- If you are restoring to an instance with read replicas, then you must delete all replicas and recreate them after the restore operation completes.
- The restore operation restarts the instance.
- After you restore from a backup, the target instance's backup configurations are set to default values. If your source instance had custom backup configurations or was using enhanced backups, then you'll need to update the backup configurations after restore is complete.
Restore using a backup
Cloud SQL lets you restore an instance using a backup. You can use a backup from a live or deleted instance, and use it to restore to a new or existing instance. You can use any available backup to restore the instance. To learn more about how backups work at Cloud SQL, see Backups overview.
When you restore an instance using a backup, you can do the following:
- Restore to a new instance
- Restore to an existing instance
- Restore to an instance in another project or region
In the event of an outage, you can still retrieve a list of backups in a particular project to restore from.
To restore your instance using a backup, see Restore an instance using a backup.
Point-in-time recovery (PITR)
PITR lets you restore your instance to a specific time of the database. For example, if an error causes a loss of data, then you can recover a database to its state before the error occurred. Unlike restore using a backup, PITR always create a new instance. You can't perform a PITR to an existing instance. The new instance inherits the settings of the source instance, similar to when you create a clone.
If you create a Cloud SQL Enterprise Plus edition instance, then PITR is enabled by default. You have to manually disable the feature.
If you create a Cloud SQL Enterprise edition instance in the Google Cloud console, then PITR is enabled by default. If you create a Cloud SQL for MySQL instance with High availability enabled, then PITR is also enabled by default. Otherwise, if you create the instance by using the gcloud CLI, Terraform, or the Cloud SQL Admin API, then PITR is disabled by default. To enable PITR for these instances, you have to manually enable it.
For step-by-step instructions for performing PITR, see Use point-in-time recovery (PITR).
Log storage for PITR
PITR uses binary logging to archive logs. When you restore an existing instance using a backup, these archive logs are deleted and won't be available to perform a PITR. Only new logs generated after the restore is complete can be used for PITR.
On August 11, 2023, we launched storing transaction logs for PITR in Cloud Storage. Since this launch, the following conditions apply:
All Cloud SQL Enterprise Plus edition instances store their binary logs used for PITR in Cloud Storage. Only Cloud SQL Enterprise Plus edition instances that you upgraded from Cloud SQL Enterprise edition before April 1, 2024 and had PITR enabled before August 11, 2023 continue to store their logs for PITR on disk.
Cloud SQL Enterprise edition instances created with PITR enabled before August 11, 2023 continue to store their logs for PITR on disk.
If you upgrade a Cloud SQL Enterprise edition instance after August 11, 2023 that stores transaction logs for PITR on disk to Cloud SQL Enterprise Plus edition, then the upgrade process switches the storage location of the transaction logs used for PITR to Cloud Storage for you. For more information, see Upgrade an instance to Cloud SQL Enterprise Plus edition by using in-place upgrade.
All Cloud SQL Enterprise edition instances that you create with PITR enabled after August 11, 2023 store logs used for PITR in Cloud Storage.
If your instance uses Cloud Storage to store binary logs, then the logs are stored in the same region as the primary instance. These logs are stored for up to 35 days for Cloud SQL Enterprise Plus edition and 7 days for Cloud SQL Enterprise edition and generate no additional cost per instance.
For more information about how to check the storage location of the transaction logs used for PITR, see check where transaction logs are stored for your instance.
For instances that store binary logs only on disk, you can switch the storage location of the transaction logs used for PITR from disk to Cloud Storage by using gcloud CLI or the Cloud SQL Admin API. For more information, see Switch transaction log storage to Cloud Storage.
To ensure that logs for your instance are stored in Cloud Storage instead of on disk, complete the following actions:
- Check the network architecture of the instance. If the instance is on the old network architecture, then upgrade it to the new network architecture.
If the size of your logs on disk is causing performance issues for your instance, then deactivate PITR and re-enable it. This action ensures that new logs are stored in Cloud Storage instead of on disk.
Log retention period
Cloud SQL retains transaction logs in Cloud Storage for up to the
value set in the
transactionLogRetentionDays
PITR configuration setting. This value can range from 1 to 35 days for
Cloud SQL Enterprise Plus edition and 1 to 7 days for Cloud SQL Enterprise edition. If a value for this parameter
isn't set, then the default transaction log retention period is 14 days for
Cloud SQL Enterprise Plus edition instances and 7 days for Cloud SQL Enterprise edition instances. For more
information on how to set the transaction log retention days,
see Set transaction log retention.
Although an instance stores the binary logs used for
PITR in Cloud Storage, the instance also keeps a smaller number of duplicate
binary logs on disk to allow for replication of the
logs to Cloud Storage. By default, when you create an instance with PITR
enabled, the instance stores its binary logs for PITR
in Cloud Storage. Cloud SQL also sets the value of
the expire_logs_days and binlog_expire_logs_seconds flags to the equivalent
of one day automatically. This translates to one day of logs on disk.
For PITR binary logs that are stored on disk, that are being switched to Cloud Storage, or that are already switched to Cloud Storage, Cloud SQL retains the logs for the minimum value set for one of the following configurations:
- The
transactionLogRetentionDaysbackup configuration setting - The
expire_logs_daysor thebinlog_expire_logs_secondsflag
Cloud SQL doesn't set any values for these flags if the
binary logs are stored on disk, are being switched to
Cloud Storage, or have already been switched
to Cloud Storage. When logs are stored on disk, modifying the values of
these flags can affect the behavior of PITR recovery and how many days
worth of logs are stored on disk. While the log storage location is being
switched to Cloud Storage, you can't modify the flag values.
We also don't recommend that you configure either flag value to 0. For more
information, see
Configure database flags.
transactionLogRetentionDaysconfiguration settingexpire_logs_daysdatabase flagbinlog_expire_logs_secondsdatabase flag
For example, to prevent performance issues, reduce the value of the flags by one day, each day, over several days. As a result, Cloud SQL doesn't purge all of the binary logs simultaneously.
For
customer-managed encryption key (CMEK)-enabled instances,
binary logs are encrypted using the latest version of the
CMEK. To perform a restore, the latest key version is required for all days
retained as part of the retained-transaction-log-days parameter.
Logs and disk usage
Logs are generated regularly and use storage space. The binary
logs are deleted automatically with their associated automatic backup, which
happens after the value that's set for
transactionLogRetentionDays
is met.
To find out how much disk is being used by the binary logs,
check the bytes_used_by_data_type
metric for the instance. The value for the binlog data type returns
the size of the binlogs on the disk. For instances that store transaction logs
used for PITR on disk,
Cloud SQL purges data from the disk daily to meet the
transactionLogRetentionDays PITR setting,
as described in Automatic backup and transaction log retention.
However, if you set the expire_logs_days or binlog_expire_logs_seconds flag
to a value that's lower than transaction log retention days,
then Cloud SQL can purge the binary logs sooner.
If the size of your binary logs are causing an issue for your instance:
- Check whether your instance is storing logs on disk. You can switch the storage location of the logs that Cloud SQL uses for PITR from disk to Cloud Storage without downtime by using gcloud CLI or the Cloud SQL Admin API. If you're using Cloud SQL Enterprise edition, then you can also upgrade to Cloud SQL Enterprise Plus edition to switch the storage location of your PITR logs.
You can increase the instance storage size. However, the binary log size increase in disk usage might be temporary.
We recommend enabling automatic storage increase to avoid unexpected storage issues.
For more information about PITR, see Point-in-time recovery (PITR).
After you complete the
switch of the storage location of transaction logs to Cloud Storage,
you can free up disk space by reducing the values of the
expire_logs_days or binlog_expire_logs_seconds
flags. To check the status of the switch, see
Check the storage location of transaction logs used for PITR.
If you want additional logs to be available
on disk — for example, to browse the binary logs
with the mysqlbinlog utility —
then increase the values of these flags. Cloud SQL retains
binary logs on disk for the minimum of the transaction log
retention days or the values set for the flags. For more information on
how logs for PITR are stored after the switch and how to free up disk space,
see Logs after the switch to Cloud Storage.
PITR limitations
The following limitations are associated with your instance having PITR enabled and the size of your transaction logs on disk causing an issue for your instance:
- You can deactivate PITR and re-enable it to ensure that Cloud SQL stores logs in Cloud Storage in the same region as the instance. However, Cloud SQL deletes any existing logs so you can't perform a PITR operation earlier than the time that you re-enabled PITR.
- You can increase the instance storage size, but the transaction log size increase in disk usage might be temporary.
- To avoid unexpected storage issues, we recommend enabling automatic storage increases. This recommendation applies only if your instance has PITR enabled and your logs are stored on disk.
- If you want to delete logs and recover storage, then you can deactivate PITR without re-enabling it. However, decreasing the storage used doesn't shrink the size of the disk provisioned for the instance.
Logs are purged once daily, not continuously. Setting the log retention to two days means that at least two days of logs, and at most three days of logs, are retained. We recommend setting the number of backups to one more than the days of log retention.
For example, if you specify
7for the value of thetransactionLogRetentionDaysparameter, then for thebackupRetentionSettingsparameter, set the number ofretainedBackupsto8.
For step-by-step instructions for performing PITR, see [Use point-in-time recovery (PITR)][perform-pitr].
Restore an unavailable instance
You can use PITR to restore a Cloud SQL instance that isn't available. PITR typically offers a recovery point objective (RPO) of five minutes or less.
If the instance is unavailable, then you can use the API to get the earliest and latest recovery time to which you can restore the instance and perform the recovery to that time. If the zone in which the instance is configured isn't accessible, then you can restore the instance to a different primary or secondary zone by providing values for the preferred zones.
Suppose a Cloud SQL instance becomes unavailable at 4 PM EST. If the latest recovery time is at 3:55 PM EST, then you can recover the instance up to this time.
Restore a deleted instance using PITR
You can use PITR to restore a Cloud SQL instance after deletion. To use this feature, your instance must have PITR and retained backs enabled before the instance is deleted. When enabled, PITR logs are retained after you delete the instance.
After an instance is deleted, the PITR logs continue to follow the retention settings defined by the instance when it was live. The PITR logs expire based on the retention settings on a rolling basis after the instance is deleted. The rolling period is defined based on the PITR retention period set on the instance prior to deletion. For example, if your Cloud SQL Enterprise Plus edition instance has PITR retention set to 14 days, then the latest PITR log will be deleted 14 days after instance deletion. When a PITR log expires, it can't be recovered.
Since instance names can be reused after an instance is deleted in Cloud SQL, retained PITR logs can be identified in Google Cloud with the following fields:
instance_deletion_timelog_retention_days
These fields allow you to identify if a PITR log belongs to a deleted instance.
The PITR recovery window is defined as the earliest and latest recovery times available to restore your instance using PITR. To find your deleted instance's earliest and latest recovery times, see Get the earliest and latest recovery time.
To restore an instance using PITR after instance deletion, see Perform PITR on a deleted instance.
Requirements for restoring to a new instance
When you restore your instance to a new instance, note the following requirements:
If target instance must have the same database version as the instance from which the backup was taken.
The storage capacity of the target instance must be at least as large as the capacity of the instance being backed up. The amount of storage used does not matter. You can see the storage capacity of the instance in the console Cloud SQL instances page.
The target instance must be in the
RUNNABLEstate.
Restore rate limitations
You are allowed a maximum of three restore operations every 30 minutes per instance per region per project. If a restore operation fails, then it isn't counted towards this quota. If you reach the limit, then the operation fails with an error message that tells you when you can run the operation again.
Cloud SQL uses tokens from a bucket to determine how many restore operations are available at any one time. For each backup, there's a bucket for each target project and target region. The target instances from the same project share one bucket if they are in the same region. There's a maximum of three tokens in each bucket that you can use for restore operations. Every 10 minutes, a new token is added to the bucket. If the bucket is full, then the token overflows.
Each time you issue a restore operation, a token is granted from the bucket. If the operation succeeds, the token is removed from the bucket. If it fails, the token is returned to the bucket. The following diagram shows how this works:

For example, in the following figure, Backup1, Backup2, and Backup3 are the backups from the same source instance.
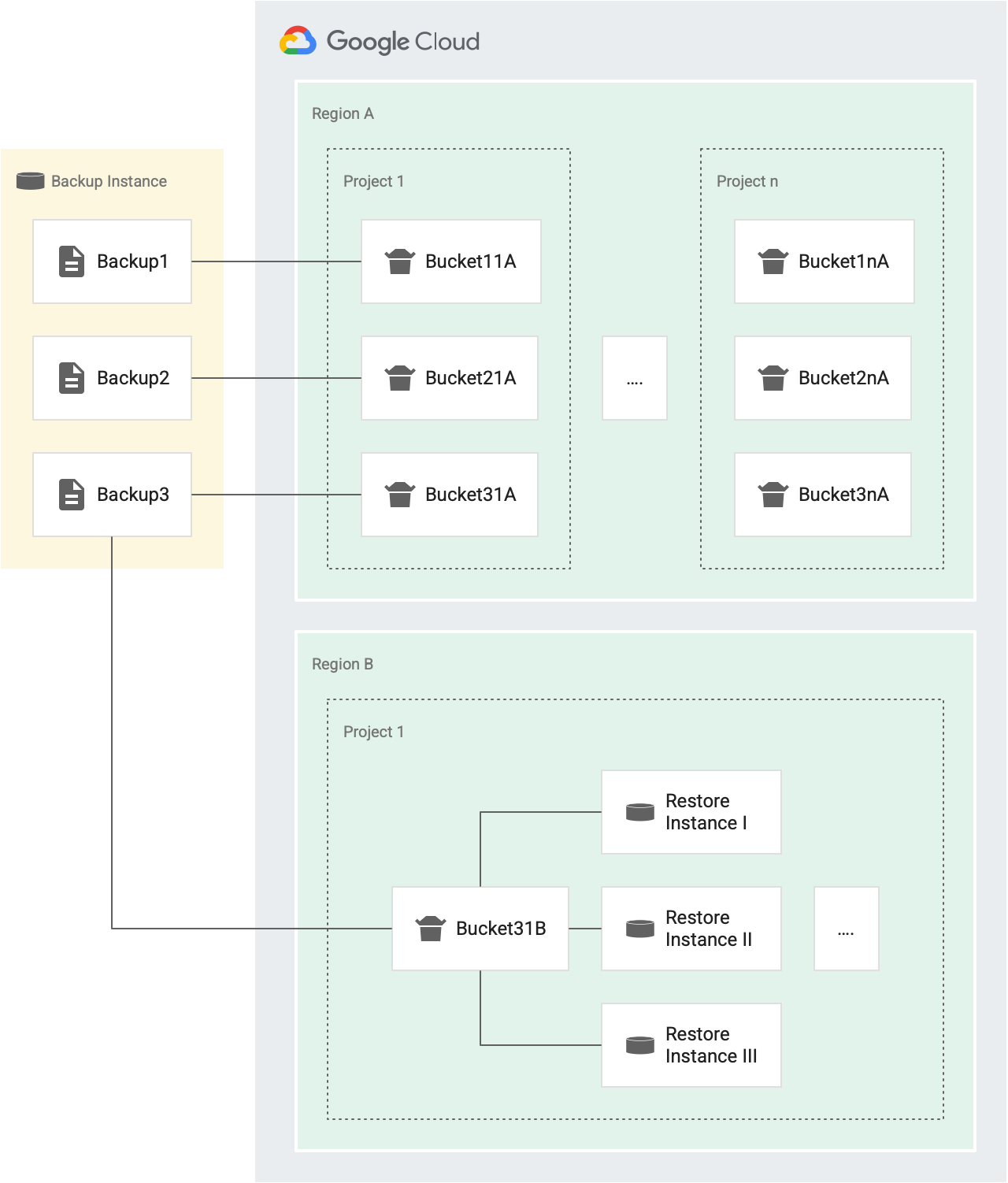
- Each backup (Backup1, Backup2, and Backup3) has its own bucket of tokens for restore operations that target different instances in Project 1 in Region A (Bucket11A, Bucket21A, and Bucket31A). Because each backup has its own bucket, you can restore each backup to the same instance three times every thirty minutes.
- Each backup has a bucket for a separate project and for a separate region.
For example, if there are five projects in a region, there are five
buckets for that backup in that region, one in each project. In the previous
figure, we have two projects in region A: Project 1 and Project n.
- Backup1 has two buckets of tokens for restore operations in Region A. One bucket for Project 1 (Bucket11A), and one bucket for Project n (Bucket1nA).
- Similarly, Backup3 has two buckets for restore operations in Region A. One for Project 1 (Bucket31A) and one for Project n (Bucket3nA).
- Backup3 has one bucket in Region B, for Project1, because all instances in the same target project and the same target region share one bucket.