このページでは、セカンダリ クラスタを作成して操作し、AlloyDB for PostgreSQL クロスリージョン レプリケーションを使用する方法について説明します。
クロスリージョン レプリケーションのコンセプトの概要については、クロスリージョン レプリケーションの概要をご覧ください。
始める前に
- 使用している Google Cloud プロジェクトで AlloyDB へのアクセスが有効になっている必要があります。
- 使用している Google Cloud プロジェクトで、次のいずれかの IAM ロールが必要です。
roles/alloydb.admin(AlloyDB 管理者の IAM 事前定義ロール)roles/owner(オーナーの IAM 基本ロール)roles/editor(編集者の IAM 基本ロール)
これらのロールが付与されていない場合は、アクセス権を付与するよう組織管理者に依頼してください。
セカンダリ クラスタを作成する
セカンダリ クラスタを作成すると、AlloyDB はポイントインタイム リカバリ(PITR)やバックアップ構成など、プライマリ クラスタ構成の一部をコピーしてセカンダリ クラスタに適用します。プライマリ クラスタに読み取りプール インスタンスがいくつ存在していても、AlloyDB がセカンダリ クラスタの作成後に読み取りプール インスタンスを追加することはありません。
セカンダリ クラスタの作成後にプライマリ クラスタの構成を更新しても、その変更はセカンダリ クラスタで使用されません。ただし、セカンダリ クラスタに手動で更新して、プライマリ クラスタの最新の構成を利用することは可能です。
プライマリ クラスタには最大 5 つのセカンダリ クラスタを作成できます。すべてのセカンダリ クラスタは、単一のプライマリ インスタンスから複製されます。セカンダリ クラスタをプロモートすると、そのセカンダリ クラスタは独立したプライマリ クラスタになります。
次の図は、us-east4 で cluster-2 というセカンダリ クラスタをプロモートする方法を示しています。
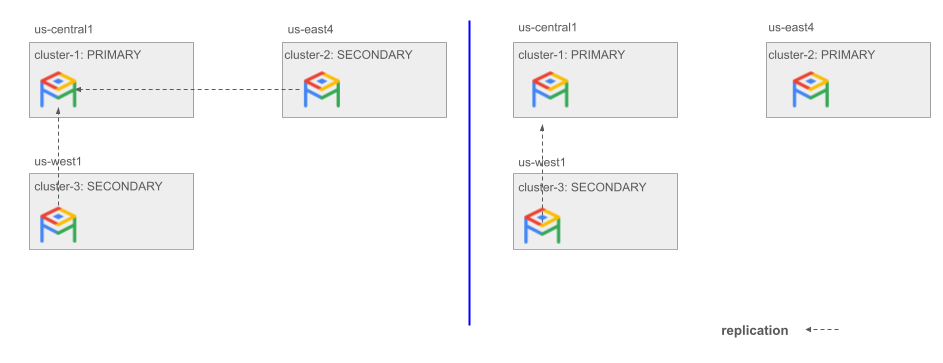
図 1.セカンダリ クラスタのプロモートの例。
AlloyDB セカンダリ クラスタとセカンダリ インスタンスを作成する手順は次のとおりです。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列でクラスタをクリックします。
[概要] ページで、[セカンダリ クラスタを作成] をクリックします。
セカンダリ クラスタを構成します。
- [クラスタ ID] フィールドに、セカンダリ クラスタのリソース ID を入力します。
- セカンダリ クラスタに、プライマリ クラスタとは異なるリージョンを選択します。
- セカンダリ クラスタを暗号化する方法として、デフォルトの Google 管理の暗号化か、顧客管理の暗号鍵(CMEK)を選択します。
このクラスタを CMEK 鍵で暗号化する場合は、次の操作を行います。
- [詳細暗号化オプション] をクリックします。
- [顧客管理の暗号鍵(CMEK)] を選択します。
表示されたメニューから顧客管理の暗号鍵を選択します。
Google Cloud コンソールでは、新しいクラスタと同じGoogle Cloud プロジェクトとリージョンにある鍵のみがリストに表示されます。
リストにない鍵を使用するには、次の操作を行います。
- [鍵が表示されない場合は、鍵のリソース名を入力してください] をクリックします。
- [鍵のリソース名] フィールドにリソース名を入力します。
- [保存] をクリックします。
- [続行] をクリックします。
AlloyDB で CMEK を使用するには、追加の設定が必要です。詳細については、CMEK を使用するをご覧ください。
関連付けられたプライマリ インスタンスが CMEK で暗号化されている場合は、セカンダリ クラスタも CMEK で暗号化する必要があります。
セカンダリ インスタンスを構成します。
- [インスタンス ID] フィールドに、セカンダリ インスタンスのリソース ID を入力します。リソース ID はクラスタ内で一意である必要があります。
[クラスタを作成] をクリックします。
gcloud
gcloud CLI を使用するには、Google Cloud CLI をインストールして初期化するか、Cloud Shell を使用します。
gcloud alloydb clusters create-secondary コマンドを次のように使用します。
gcloud alloydb clusters create-secondary SECONDARY_CLUSTER_ID \ --region=REGION_ID \ --primary-cluster=projects/PROJECT_ID/locations/LOCATION_ID/clusters/ PRIMARY_CLUSTER_IDgcloud alloydb instances create-secondary SECONDARY_INSTANCE_ID \ --cluster=SECONDARY_CLUSTER_ID \ --region=REGION_ID
次のように置き換えます。
SECONDARY_CLUSTER_ID: 作成するセカンダリ クラスタの ID。SECONDARY_INSTANCE_ID: 作成するセカンダリ インスタンスの ID。REGION_ID: セカンダリ クラスタのリージョンの ID。例:us-central1PROJECT_ID: セカンダリ クラスタのプロジェクトの ID。LOCATION_ID: プライマリ クラスタが配置されているロケーション。例:us-central1PRIMARY_CLUSTER_ID: セカンダリ クラスタが関連付けられているプライマリ クラスタの ID。SECONDARY_CLUSTER_ID: セカンダリ インスタンスが関連付けられているセカンダリ クラスタの ID。ALLOWED_PSC_PROJECTS(省略可): インスタンスへのアクセスを許可するプロジェクト ID またはプロジェクト番号のカンマ区切りリスト(例:my-project-1、12345、my-project-n)。インスタンスへの接続にクラスタで Private Service Connect が使用されている場合は、許可するプロジェクトまたは番号のリストを設定する必要があります。--no-enable-automated-backup(省略可): セカンダリ クラスタでの自動バックアップの作成を無効にします。
Private Service Connect が有効なセカンダリ インスタンスを作成するには、allowed-psc-projects フラグを追加して、インスタンスへのアクセスを許可するプロジェクト ID またはプロジェクト番号のカンマ区切りリストを設定します(例: my-project-1、12345、my-project-n)。
gcloud alloydb clusters create-secondary SECONDARY_CLUSTER_ID \ --region=REGION_ID \ --primary-cluster=projects/PROJECT_ID/locations/LOCATION_ID/clusters/ PRIMARY_CLUSTER_ID \gcloud alloydb instances create-secondary SECONDARY_INSTANCE_ID \ --cluster=SECONDARY_CLUSTER_ID \ --region=REGION_ID \ --allowed-psc-projects=ALLOWED_PSC_PROJECTS
次のように置き換えます。
ALLOWED_PSC_PROJECTS(省略可): インスタンスへのアクセスを許可するプロジェクト ID またはプロジェクト番号のカンマ区切りリスト(例:my-project-1、12345、my-project-n)。インスタンスへの接続にクラスタで Private Service Connect が使用されている場合は、許可するプロジェクトまたは番号のリストを設定する必要があります。
パブリック IP が有効なクラスタにセカンダリ インスタンスを作成するには、--assign-inbound-public-ip=ASSIGN_IPV4 パラメータを追加します。
gcloud alloydb instances create-secondary SECONDARY_INSTANCE_ID \
--cluster=SECONDARY_CLUSTER_ID \
--region=REGION_ID \
--assign-inbound-public-ip=ASSIGN_IPV4必要に応じて、64.233.160.0/16 などの CIDR ブロックのカンマ区切りのリストを --authorized-external-networks パラメータに渡して、インスタンスに承認済みの外部ネットワークを設定します。
セカンダリ クラスタを表示する
AlloyDB セカンダリ クラスタの詳細情報を表示するには、次の操作を行います。
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列でセカンダリ クラスタをクリックします。
[概要] ページで、セカンダリ クラスタの詳細をすべて表示します。
セカンダリ インスタンスを更新する
セカンダリ インスタンスを更新して、データベース フラグの追加、変更、削除を行うことができます。セカンダリ インスタンスのマシンタイプをスケーリングすることもできます。
セカンダリ インスタンスでデータベース フラグを構成する
データベース フラグを追加、変更、削除するには、次の操作を行います。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、変更するセカンダリ クラスタをクリックします。
[概要] ページで [クラスタ内のインスタンス] に移動し、セカンダリ インスタンスを選択して、[セカンダリを編集] をクリックします。
インスタンスに対してデータベース フラグの追加、変更、または削除を行います。
フラグを追加する
- インスタンスにデータベース フラグを追加するには、[フラグを追加] をクリックします。
- [新しいデータベース フラグ] リストからフラグを選択します。
- フラグの値を指定します。
- [完了] をクリックします。
フラグを変更する
- インスタンス内のデータベース フラグを変更するには、データベース フラグを展開し、[データベース フラグの編集] セクションで既存のフラグの値を変更します。
- [完了] をクリックします。
フラグを削除する
- インスタンスからデータベース フラグを削除するには、フラグを選択して削除アイコンをクリックします。
- [完了] をクリックします。
[Update secondary] をクリックします。
gcloud
セカンダリ インスタンスのデータベース フラグを変更するには、gcloud alloydb instances update コマンドを使用します。
gcloud alloydb instances update SECONDARY_INSTANCE_ID \
--database-flags FLAGS_LIST \
--region=REGION_ID \
--cluster=CLUSTER_ID \
--project=PROJECT_ID次のように置き換えます。
SECONDARY_INSTANCE_ID: セカンダリ インスタンスの ID。FLAGS_LIST: データベース フラグ仕様のカンマ区切りリスト。仕様は、フラグの名前、等号(=)、フラグに割り当てる値で構成されます。値を受け取らないデータベース フラグの場合は、フラグ名の後に等号(=)を付けます。REGION_ID: セカンダリ インスタンスが配置されているリージョン。例:us-central1CLUSTER_ID: セカンダリ インスタンスが配置されているクラスタの ID。PROJECT_ID: セカンダリ クラスタが配置されるプロジェクトの ID。
セカンダリ インスタンスのマシンタイプをスケーリングする
セカンダリ インスタンスのマシンタイプをスケーリングするには、次の操作を行います。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、変更するセカンダリ クラスタをクリックします。
[概要] ページで [クラスタ内のインスタンス] セクションに移動し、[セカンダリを編集] をクリックします。
ページでクラスタのステータスが「メンテナンス」となっている場合、この操作は実行できません。[ステータス] が「準備完了」に変わると、操作が再度実行できるようになります。
マシンタイプを選択します。
[Update secondary] をクリックします。
gcloud
gcloud alloydb instances
update コマンドを使用して、セカンダリ インスタンスのマシンタイプを変更します。
gcloud alloydb instances update SECONDARY_INSTANCE_ID \
--cpu-count=CPU_COUNT \
--region=REGION_ID \
--cluster=CLUSTER_ID \
--project=PROJECT_ID次のように置き換えます。
SECONDARY_INSTANCE_ID: 更新するセカンダリ インスタンスの ID。CPU_COUNT: インスタンスに必要な vCPU の数。有効な値は次のとおりです。2(2 vCPU、16 GB RAM)4(4 vCPU、32 GB RAM)8(8 vCPU、64 GB RAM)16(16 vCPU、128 GB RAM)32(32 vCPU、256 GB RAM)64(64 vCPU、512 GB RAM)
REGION_ID: インスタンスが配置されるリージョン。
CLUSTER_ID: インスタンスが配置されているクラスタの ID。
PROJECT_ID: クラスタが配置されるプロジェクトの ID。
コマンドから「invalid cluster state MAINTENANCE」というフレーズを含むエラー メッセージが返された場合は、クラスタが定期メンテナンス中です。このため、インスタンスの再構成が一時的に禁止されます。クラスタが READY 状態に戻ったら、コマンドをもう一度実行してください。
クラスタのステータスを確認するには、クラスタの詳細を表示するをご覧ください。
読み取りプール インスタンスをセカンダリ クラスタに追加する
セカンダリ クラスタに読み取りプール インスタンスを追加するには、次の操作を行います。
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、読み取りプール インスタンスを追加するセカンダリ クラスタをクリックします。
[概要] ページで [クラスタ内のインスタンス] セクションに移動し、[読み取りプールを追加] をクリックします。
読み取りプール インスタンスを構成します。
- [プール インスタンス ID の読み取り] フィールドに、読み取りプール インスタンスの ID を入力します。
- [ノード数] フィールドにノード数を入力します。読み取りプール インスタンス内のノード数によって、インスタンスの全体的なコンピューティング容量が決まります。クラスタ内のすべての読み取りプール インスタンスに最大 20 個のノードを設定できます。
- マシンタイプを選択します。
省略可: インスタンスにカスタムフラグを設定します。フラグごとに、次の操作を行います。
- [フラグを追加] をクリックします。
- [新しいデータベース フラグ] リストからフラグを選択します。
- フラグの値を指定します。
- [完了] をクリックします。
[読み取りプールを追加] をクリックします。
セカンダリ クラスタをプロモートする
セカンダリ クラスタをプロモートする前に、次の手順で、セカンダリ クラスタがプライマリ クラスタから受け取ったすべてのトランザクションを適用していることを確認します。
- プライマリ クラスタへの書き込みをすべて停止します。
次の手順で、セカンダリ クラスタのレプリケーション ステータスを確認します。
Google Cloud コンソールで、[クラスタ] ページに移動します。
クラスタのリストで、プロモートするセカンダリ クラスタの名前をクリックします。
クラスタの詳細ページで、[モニタリング] をクリックします。
[モニタリング] リストで、セカンダリ インスタンスを選択します。リストには [セカンダリ: INSTANCE_NAME] と表示されます。
指標のリストで、[プライマリ インスタンスからのレプリケーション ラグ] グラフを見つけます。
グラフに最小のラグが表示されていることを確認します。
ラグの値は
0が理想的です。ラグが0より大きい場合でも、セカンダリ クラスタをプロモートできますが、プライマリ クラスタですでに commit されている最近のトランザクションが失われる可能性があります。指標のリストで、[レプリケーションのステータス] グラフを見つけます。
グラフに表示されるすべてのノードの値が
streamingであることを確認します。
セカンダリ クラスタをプライマリ クラスタをプロモートするには、次の操作を行います。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、プライマリ クラスタとしてプロモートするセカンダリ クラスタをクリックします。
[概要] ページで、[クラスタをプロモート] をクリックします。
表示されたダイアログで、セカンダリ クラスタ ID を入力して、クラスタをプロモートすることを確認します。
[プロモート] をクリックします。
クラスタがプロモートされると、[概要] ページの [タイプ: セカンダリ クラスタ(高可用性)] フィールドが [タイプ: 高可用性(読み取りプールあり)] に更新されます。
gcloud
gcloud alloydb clusters promote コマンドを次のように使用します。
gcloud alloydb clusters promote SECONDARY_CLUSTER_ID \
--region=REGION_ID \
--project=PROJECT_ID \次のように置き換えます。
SECONDARY_CLUSTER_ID: プロモートするセカンダリ クラスタの ID。REGION_ID: セカンダリ クラスタのリージョンの ID。例:us-central1PROJECT_ID: セカンダリ クラスタのプロジェクトの ID。
スイッチオーバーを行う
スイッチオーバーを実行する前に、プライマリ インスタンスとセカンダリ インスタンスが属するすべてのリージョンがオンラインであり、インスタンスが正常な状態であることを確認します。詳細については、AlloyDB システム分析情報ダッシュボードでインスタンスをモニタリングするをご覧ください。
複数のセカンダリ クラスタがある場合にスイッチオーバーを行うと、次の変更が行われます。
- スイッチオーバー コマンドを受け取ったセカンダリ クラスタがプライマリ クラスタになります。
- 以前のプライマリ クラスタはセカンダリ クラスタになり、新しいプライマリ クラスタから複製されます。
- 他のすべてのセカンダリ クラスタは、新しいプライマリ クラスタからのレプリケーションに切り替わります。
次の図は、us-central1 の cluster-1 から us-east4 の cluster-2 へのスイッチオーバーを示しています。
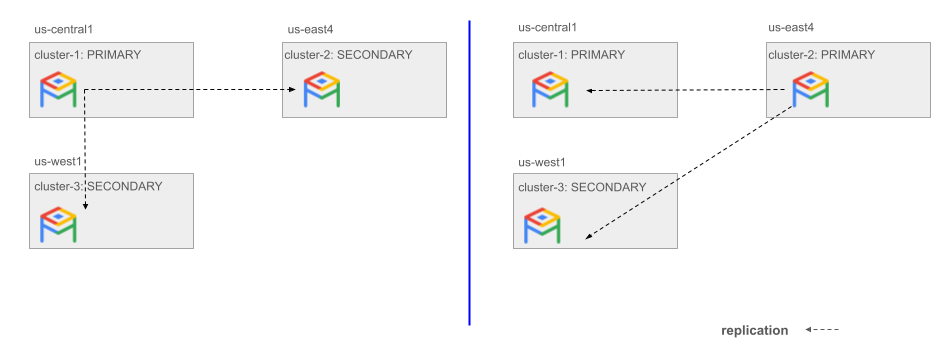
図 2. 2 つのセカンダリ クラスタのいずれかに切り替える例。
スイッチオーバーを行うには、次の操作を行います。
コンソール
Google Cloud コンソールで、[クラスタ] ページに移動します。
[リソース名] 列で、プライマリ クラスタに切り替えるセカンダリ クラスタをクリックします。
[概要] ページで [切り替え] をクリックします。
表示されたダイアログで、セカンダリ クラスタ ID を入力して、クラスタのスイッチオーバーを確定します。
[切り替え] をクリックします。
クラスタが切り替えられると、[概要] ページの [タイプ: セカンダリ クラスタ] フィールドが [クラスタタイプ: プライマリ クラスタ] と [クラスタタイプ: セカンダリ クラスタ] に更新されます。
gcloud
gcloud alloydb clusters switchover コマンドを次のように使用します。
gcloud alloydb clusters switchover SECONDARY_CLUSTER_ID \
--region=REGION_ID \
--project=PROJECT_ID \次のように置き換えます。
SECONDARY_CLUSTER_ID: プロモートするセカンダリ クラスタの ID。REGION_ID: セカンダリ クラスタのリージョンの ID。例:us-central1PROJECT_ID: セカンダリ クラスタのプロジェクトの ID。