Esta página oferece uma visão geral da replicação entre regiões do AlloyDB para PostgreSQL.
Com a replicação entre regiões do AlloyDB, é possível criar clusters e instâncias secundárias de um cluster principal para disponibilizar os recursos em diferentes regiões, no caso de uma interrupção na região principal. Esses clusters e instâncias secundários funcionam como cópias dos recursos do cluster e da instância principal.
Os principais conceitos desta página incluem:
Cluster principal. Um cluster de leitura/gravação em uma única região.
Cluster secundário. Um cluster somente leitura em uma região diferente da principal, que replica do cluster principal de forma assíncrona. No caso de falha de um cluster principal do AlloyDB, é possível promover um cluster secundário para principal.
É possível criar até cinco clusters secundários para um cluster principal. Todos os clusters secundários replicam de um único cluster principal. Se você promover um cluster secundário, ele se tornará um cluster principal independente.
Instância secundária. Um líder somente leitura de um cluster secundário. Ele é responsável por receber um stream de replicação de um cluster principal. O fluxo de replicação atualiza o volume de armazenamento na região secundária com base no volume de armazenamento na região principal. Se um cluster secundário for promovido a principal, a instância secundária se tornará a instância principal.
Uma instância secundária pode ser básica (zonal) ou de alta disponibilidade (regional).
O diagrama a seguir ilustra como a replicação entre regiões funciona:
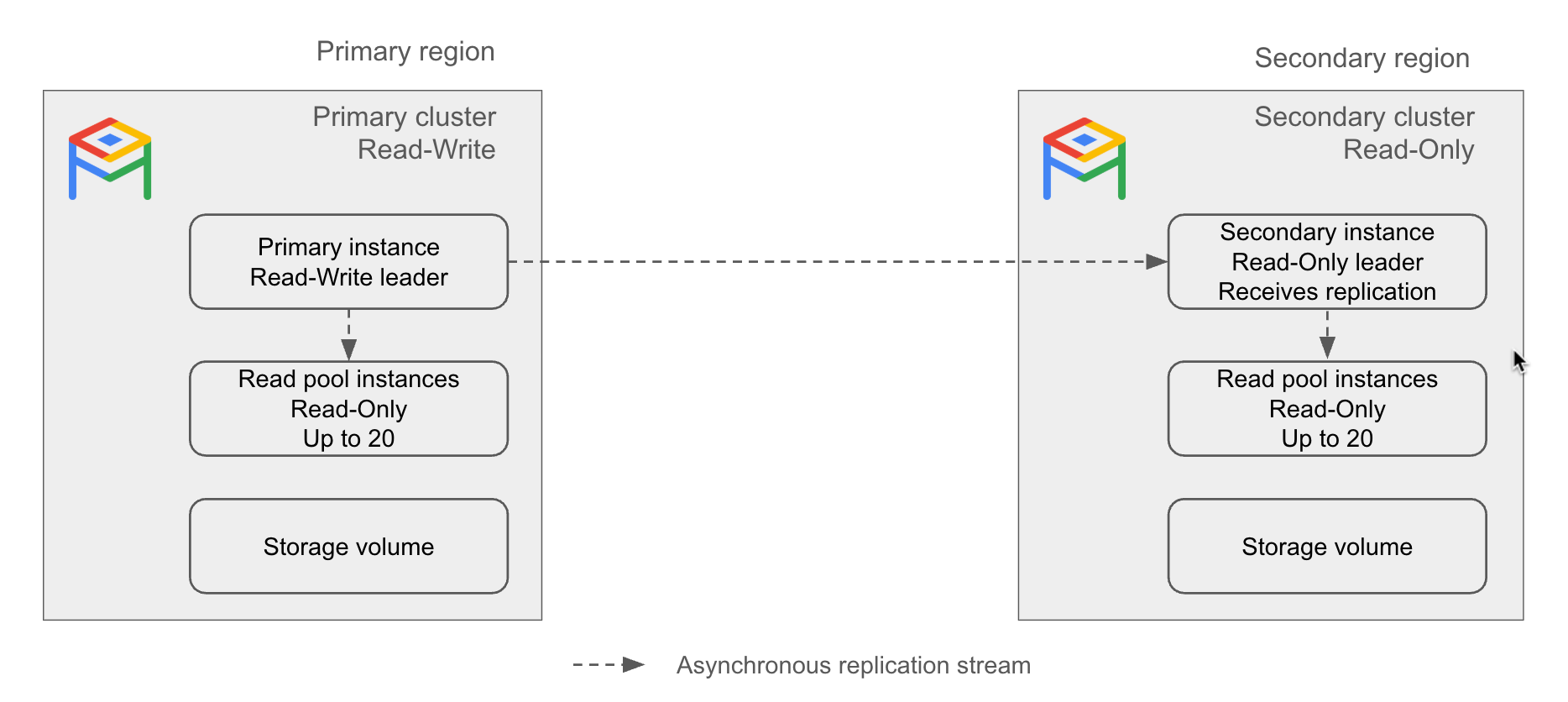
Figura 1. Exemplo de arquitetura de replicação entre regiões do AlloyDB.
Vantagens
Estes são os benefícios da replicação entre regiões no AlloyDB:
Recuperação de desastres. Se a região do cluster principal ficar indisponível, será possível promover recursos do AlloyDB em outra região para atender às solicitações.
Redução da inatividade. O suporte à alta disponibilidade (HA) em clusters secundários reduz o tempo de inatividade durante eventos de manutenção ou falhas não planejadas.
Dados distribuídos geograficamente. Distribuir os dados geograficamente os aproxima de você e diminui a latência de leitura.
Escalonamento de leitura aumentado:cada réplica entre regiões (ou cluster secundário) pode oferecer suporte a até 20 nós de leitura, permitindo que você aumente ainda mais as leituras.
Alternância sem perda de dados. Para configurações de replicação entre regiões, o AlloyDB oferece suporte à alternância entre instâncias principal e secundária sem perda de dados.
Trabalhar com a replicação entre regiões
Trabalhar com a replicação entre regiões do AlloyDB envolve as seguintes tarefas:
Crie um cluster secundário. Um cluster secundário é uma cópia atualizada continuamente do cluster principal do AlloyDB.
Ver um cluster secundário. Depois de criar um cluster secundário, é possível conferir os detalhes dele na página Clusters do Google Cloud console.
Adicione instâncias do pool de leitura. É possível adicionar instâncias de pool de leitura a um cluster secundário. Se você quiser escalonar horizontalmente a capacidade de leitura, adicione até 20 nós de leitura ao cluster secundário.
Promova um cluster secundário. É possível ler os dados de um cluster secundário, mas não gravar neles até que ele seja promovido a um cluster principal independente e completo. Quando você promove um cluster secundário, a instância secundária do cluster também é promovida como uma instância principal com recursos de leitura e gravação.
O principal caso de uso para promover um cluster secundário é a recuperação de desastres. Se ocorrer uma interrupção regional na região do cluster principal, é possível promover o cluster secundário para um cluster principal independente e retomar a veiculação do aplicativo.
Alternância sem perda de dados. A alternância permite reverter os papéis dos clusters principal e secundário sem perda de dados. É possível fazer uma alternância para testar a configuração de recuperação de desastres ou migrar sua carga de trabalho. Quando você concluir a alternância, a direção da replicação será invertida.
Se você tiver vários clusters secundários, o cluster que receber o comando de failover vai se tornar um cluster principal. O cluster principal anterior vai se tornar um cluster secundário, replicando do novo cluster principal. Todos os outros clusters secundários passam a replicar do novo cluster principal.
Há dois cenários comuns para fazer failover do cluster secundário:
- Simulados de recuperação de desastres. É possível executar testes dos processos de recuperação de desastres alternando o aplicativo para outra região sem perda de dados para simular uma interrupção regional.
- Migração regional. Faça uma migração planejada dos recursos do AlloyDB da região principal para outra. A alternância garante que o cluster secundário se torne um cluster principal com objetivo de ponto de recuperação (RPO) zero, garantindo que a migração não perca nenhum dado.
Configure backups automáticos e contínuos. Por padrão, o AlloyDB copia automaticamente as configurações de backup automatizado e contínuo do cluster principal para um cluster secundário recém-criado. Se você quiser usar configurações de backup diferentes para o cluster secundário, modifique a configuração de backup ao criar um cluster secundário.
Se o cluster principal usar a criptografia de chave de criptografia gerenciada pelo cliente (CMEK) para backups, faça uma destas ações ao criar um cluster secundário:
- Forneça as configurações de criptografia da CMEK para os backups do cluster secundário.
- Desative os backups do cluster secundário.
Para mais informações sobre como criptografar seus backups com CMEK, consulte Usar CMEK
É possível modificar as configurações de backup automatizado e contínuo do cluster secundário após a criação dele.