This page provides an overview of AlloyDB for PostgreSQL cross-region replication.
AlloyDB cross-region replication lets you create secondary clusters and instances from a primary cluster to make the resources available in different regions, in the event of an outage in the primary region. These secondary clusters and instances function as copies of your primary cluster and instance resources.
Key concepts in this page include the following:
Primary cluster. A read-write cluster in a single region.
Secondary cluster. A read-only cluster in a different region than the primary, that replicates from the primary cluster asynchronously. In the event of a failure of an AlloyDB primary cluster, you can promote a secondary cluster to a primary cluster.
You can create up to five secondary clusters for a primary cluster. All of the secondary clusters replicate from a single primary cluster. If you promote a secondary cluster, that secondary cluster becomes an independent primary cluster.
Secondary instance. A read-only leader of a secondary cluster. It is responsible for receiving a replication stream from a primary cluster. The replication stream updates the storage volume in the secondary region based on the storage volume in the primary region. If a secondary cluster is promoted to a primary cluster, the secondary instance becomes the primary instance.
A secondary instance can be either basic (zonal) or high-availability (regional).
The following diagram illustrates how cross-region replication works:
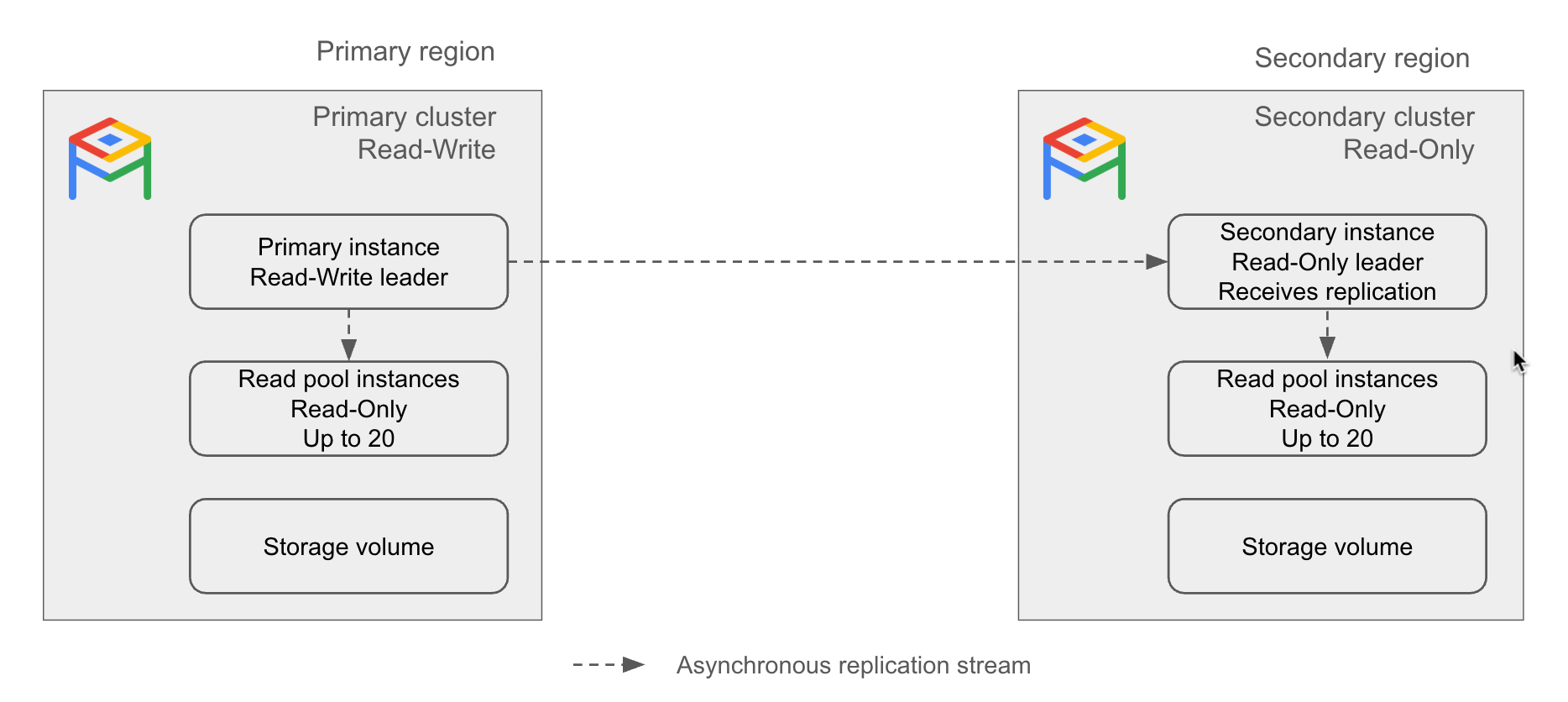
Figure 1. Example of AlloyDB cross-region replication architecture.
Benefits
The benefits of cross-region replication on AlloyDB include the following:
Disaster recovery. In the event the primary cluster's region becomes unavailable, you can promote AlloyDB resources in another region to serve requests.
Reduced downtime. Support of high availability (HA) on secondary clusters reduces downtime during maintenance events or unplanned outages.
Geographically distributed data. Distributing the data geographically brings the data closer to you and decreases read latency.
Increased read scaling: Each cross-region replica (or secondary cluster) can support up to 20 read nodes, allowing you to scale your reads further.
Switchover with zero data loss. For cross-region replication setups, AlloyDB supports switchover between primary and secondary instance with zero data loss.
Work with cross-region replication
Working with AlloyDB cross-region replication involves the following tasks:
Create a secondary cluster. A secondary cluster is a continuously updated copy of your AlloyDB primary cluster.
View a secondary cluster. After you create a secondary cluster, you can view its details in the Clusters page in the Google Cloud console.
Add read pool instances. You can add read pool instances to a secondary cluster. If you want to scale your read capacity horizontally, you can add up to 20 read nodes to your secondary cluster.
Promote a secondary cluster. You can read the data from a secondary cluster, but you can't write to it until you promote it to a fully-featured, standalone primary cluster. When you promote a secondary cluster, the cluster's secondary instance is also promoted as a primary instance with read and write capabilities.
The primary use case for promoting a secondary cluster is disaster recovery. If a regional outage occurs in your primary cluster's region, you can promote your secondary cluster to a standalone primary cluster, and resume serving your application.
Switchover with zero data loss. Switchover lets you reverse the roles of your primary and secondary cluster with zero data loss. You can perform a switchover for testing your disaster recovery setup or performing migration of your workload. When you complete the switchover, the direction of replication is reversed.
If you have multiple secondary clusters, the secondary cluster that receives the switchover command becomes a primary cluster; the previous primary cluster becomes a secondary cluster, replicating from the new primary cluster. All other secondary clusters switch to replicating from the new primary cluster.
There are two common scenarios for switching over your secondary cluster:
- Disaster recovery drills. You can run tests of your disaster recovery processes by switching your application over to another region with zero data loss to simulate a regional outage.
- Regional migration. Perform a planned migration of the AlloyDB resources from their primary region to another region. Switchover ensures the secondary cluster becomes a primary cluster with 0 Recovery Point Objective (RPO), ensuring that the migration does not lose any data.
Configure automated and continuous backups. By default, AlloyDB automatically copies automated and continuous backup configurations from the primary cluster to a newly created secondary cluster. If you want to use different backup configurations for your secondary cluster, you can modify the backup configuration when you create a secondary cluster.
If your primary cluster uses customer-managed encryption key (CMEK) encryption for backups, do one of the following when you create a secondary cluster:
- Provide CMEK encryption settings for the secondary cluster's backups.
- Disable backups for the secondary cluster.
For more information about encrypting your backups with CMEK, see Use CMEK
You can modify automated and continuous backup settings for the secondary cluster after its creation.