音声文字変換を使用すると、ストリーミング音声データをリアルタイムで文字変換されたテキストに変換できます。エージェント アシストはテキストに基づいて候補を提示するため、音声データを使用する前に変換する必要があります。また、会話分析で文字起こしされたストリーミング音声を使用して、エージェントの会話に関するリアルタイム データを収集することもできます(トピック モデリングなど)。
Agent Assist で使用するストリーミング音声を文字に変換するには、SIPREC 機能を使用する方法と、音声データをペイロードとして gRPC 呼び出しを行う方法の 2 つがあります。このページでは、gRPC 呼び出しを使用してストリーミング音声データを文字変換するプロセスについて説明します。
音声文字変換は、Speech-to-Text のストリーミング音声認識を使用して行われます。Speech-to-Text には、標準と拡張の複数の認識モデルがあります。音声文字変換は、テレフォニー モデルで使用する場合にのみ、GA レベルでサポートされます。
前提条件
- Google Cloudでプロジェクトを作成します。
- Dialogflow API を有効にします。
- アカウントで Speech-to-Text の拡張モデルにアクセスできることを確認するには、Google の担当者にお問い合わせください。
会話プロファイルを作成する
会話プロファイルを作成するには、Agent Assist コンソールを使用するか、ConversationProfile リソースの create メソッドを直接呼び出します。
音声文字変換では、会話で音声データを送信する際に、ConversationProfile.stt_config をデフォルトの InputAudioConfig として構成することをおすすめします。
![]()
会話の実行時に文字起こしを取得する
会話の実行時に文字起こしを取得するには、会話の参加者を作成し、各参加者の音声データを送信する必要があります。
参加者を作成する
参加者には次の 3 種類があります。これらのロールの詳細については、リファレンス ドキュメントをご覧ください。participant で create メソッドを呼び出し、role を指定します。文字起こしを取得するには、END_USER または HUMAN_AGENT の参加者のみが StreamingAnalyzeContent を呼び出すことができます。
音声データを送信して文字起こしを取得する
StreamingAnalyzeContent を使用して、次のパラメータで参加者の音声を Google に送信し、文字起こしを取得できます。
ストリームの最初のリクエストは
InputAudioConfigである必要があります。(ここで構成されたフィールドは、ConversationProfile.stt_configの対応する設定をオーバーライドします)。2 回目のリクエストまで音声入力を送信しないでください。audioEncodingはAUDIO_ENCODING_LINEAR_16またはAUDIO_ENCODING_MULAWに設定する必要があります。model: 音声の文字起こしに使用する Speech-to-Text モデル。このフィールドは、telephonyに設定します。バリアントは文字起こし品質に影響しないため、[音声モデルのバリアント] を指定しないか、[利用可能な最良のモデルを使用する] を選択できます。- 最高の文字起こし品質を得るには、
singleUtteranceをfalseに設定する必要があります。singleUtteranceがfalseの場合、END_OF_SINGLE_UTTERANCEは想定されませんが、StreamingAnalyzeContentResponse.recognition_result内のisFinal==trueを使用してストリームをハーフクローズできます。 - オプションの追加パラメータ: 次のパラメータはオプションです。これらのパラメータにアクセスするには、Google の担当者にお問い合わせください。
languageCode: 音声のlanguage_code。デフォルト値はen-USです。alternativeLanguageCodes: これはプレビュー機能です。音声で検出される可能性のある追加の言語。Agent Assist はlanguage_codeフィールドを使用して、音声の冒頭で言語を自動的に検出し、それ以降のすべての会話ターンでデフォルトとして使用します。alternativeLanguageCodesフィールドでは、Agent Assist が選択できるオプションをさらに指定できます。phraseSets: Speech-to-Text モデル適応phraseSetリソース名。音声文字変換でモデル適応を使用するには、まず Speech-to-Text API を使用してphraseSetを作成し、ここでリソース名を指定する必要があります。
音声ペイロードを含む 2 番目のリクエストを送信すると、ストリームから
StreamingAnalyzeContentResponsesが届き始めます。StreamingAnalyzeContentResponse.recognition_resultでis_finalがtrueに設定されている場合は、ストリームを半分閉じることができます(または、Python などの一部の言語では送信を停止できます)。- ストリームをハーフクローズすると、サーバーは最終的な文字起こしを含むレスポンスと、Dialogflow の候補や Agent Assist の候補を返します。
最終的な文字起こしは、次の場所で確認できます。
StreamingAnalyzeContentResponse.message.content。- Pub/Sub 通知を有効にすると、Pub/Sub で文字起こしを確認することもできます。
前のストリームが閉じられたら、新しいストリームを開始します。
- 音声の再送信:
is_final=trueを含むレスポンスの最後のspeech_end_offset以降に生成された音声データは、最適な文字起こし品質を得るために、新しいストリームの開始時間からStreamingAnalyzeContentに再送信する必要があります。
- 音声の再送信:
次の図は、ストリームの仕組みを示しています。
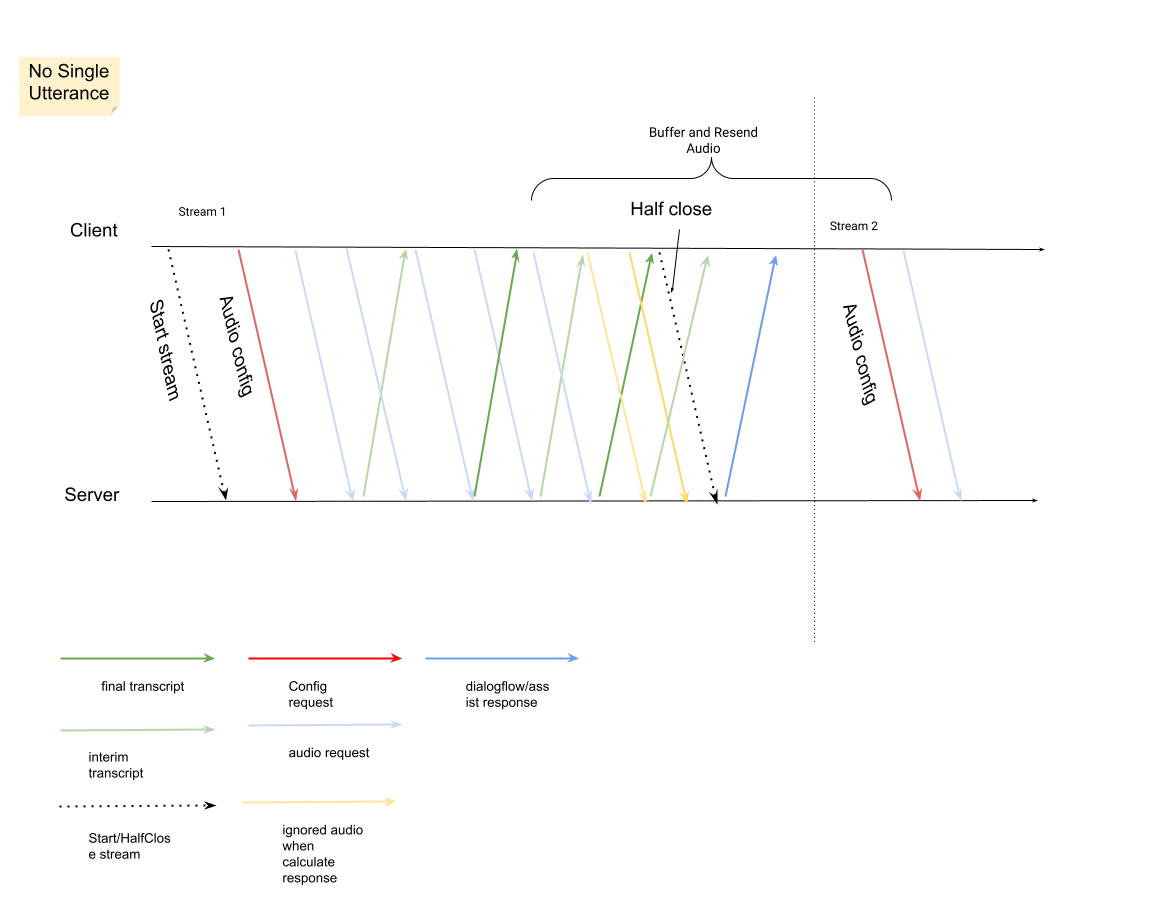
ストリーミング認識リクエストのコードサンプル
次のコードサンプルは、ストリーミング音声文字変換リクエストを送信する方法を示しています。
Python
Agent Assist に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。