La transcription vocale vous permet de convertir vos données audio en streaming en texte transcrit en temps réel. L'Aide pour les agents fait des suggestions basées sur du texte. Les données audio doivent donc être converties avant de pouvoir être utilisées. Vous pouvez également utiliser l'audio en streaming transcrit avec Conversational Insights pour collecter des données en temps réel sur les conversations des agents (par exemple, la modélisation des thèmes).
Il existe deux façons de transcrire l'audio en streaming pour l'utiliser avec Agent Assist : en utilisant la fonctionnalité SIPREC ou en effectuant des appels gRPC avec des données audio comme charge utile. Cette page décrit le processus de transcription des données audio en streaming à l'aide d'appels gRPC.
La transcription vocale fonctionne à l'aide de la reconnaissance vocale en streaming Speech-to-Text. Speech-to-Text propose plusieurs modèles de reconnaissance, standards et améliorés. La transcription vocale n'est prise en charge au niveau de la disponibilité générale que lorsqu'elle est utilisée avec le modèle telephony.
Prérequis
- Créez un projet dansGoogle Cloud.
- Activez l'API Dialogflow.
- Contactez votre représentant Google pour vous assurer que votre compte a accès aux modèles améliorés de Speech-to-Text.
Créer un profil de conversation
Pour créer un profil de conversation, utilisez la console Agent Assist ou appelez directement la méthode create sur la ressource ConversationProfile.
Pour la transcription vocale, nous vous recommandons de configurer ConversationProfile.stt_config comme InputAudioConfig par défaut lorsque vous envoyez des données audio dans une conversation.
![]()
Obtenir des transcriptions lors de l'exécution de la conversation
Pour obtenir des transcriptions lors de l'exécution d'une conversation, vous devez créer des participants pour la conversation et envoyer des données audio pour chacun d'eux.
Créer des participants
Il existe trois types de participants.
Pour en savoir plus sur leurs rôles, consultez la documentation de référence. Appelez la méthode create sur participant et spécifiez role. Seuls les participants END_USER ou HUMAN_AGENT peuvent appeler StreamingAnalyzeContent, ce qui est nécessaire pour obtenir une transcription.
Envoyer des données audio et obtenir une transcription
Vous pouvez utiliser StreamingAnalyzeContent pour envoyer l'audio d'un participant à Google et obtenir une transcription, avec les paramètres suivants :
La première requête du flux doit être
InputAudioConfig. (Les champs configurés ici remplacent les paramètres correspondants dansConversationProfile.stt_config.) N'envoyez aucune entrée audio avant la deuxième requête.audioEncodingdoit être défini surAUDIO_ENCODING_LINEAR_16ouAUDIO_ENCODING_MULAW.model: modèle Speech-to-Text que vous souhaitez utiliser pour transcrire votre contenu audio. Définissez ce champ surtelephony. La variante n'a pas d'incidence sur la qualité de la transcription. Vous pouvez donc laisser le champ Variante du modèle vocal non spécifié ou choisir Utiliser la meilleure variante disponible.singleUtterancedoit être défini surfalsepour une qualité de transcription optimale. Vous ne devez pas vous attendre àEND_OF_SINGLE_UTTERANCEsisingleUtteranceestfalse, mais vous pouvez compter surisFinal==trueà l'intérieur deStreamingAnalyzeContentResponse.recognition_resultpour fermer le flux à moitié.- Paramètres supplémentaires facultatifs : les paramètres suivants sont facultatifs. Pour accéder à ces paramètres, contactez votre représentant Google.
languageCode:language_codede l'audio. La valeur par défaut esten-US.alternativeLanguageCodes: il s'agit d'une fonctionnalité en version Preview. Autres langues susceptibles d'être détectées dans l'audio. L'Assistance pour les agents utilise le champlanguage_codepour détecter automatiquement la langue au début de l'audio et la définir par défaut pour tous les tours de conversation suivants. Le champalternativeLanguageCodesvous permet de spécifier plus d'options parmi lesquelles l'assistance de l'agent peut choisir.phraseSets: nom de ressourcephraseSetde l'adaptation du modèle Speech-to-Text. Pour utiliser l'adaptation de modèle avec la transcription vocale, vous devez d'abord créerphraseSetà l'aide de l'API Speech-to-Text et spécifier le nom de la ressource ici.
Après avoir envoyé la deuxième requête avec la charge utile audio, vous devriez commencer à recevoir des
StreamingAnalyzeContentResponsesdu flux.- Vous pouvez fermer à moitié le flux (ou arrêter l'envoi dans certaines langues comme Python) lorsque vous voyez
is_finaldéfini surtruedansStreamingAnalyzeContentResponse.recognition_result. - Une fois le flux à moitié fermé, le serveur renvoie la réponse contenant la transcription finale, ainsi que d'éventuelles suggestions Dialogflow ou Agent Assist.
- Vous pouvez fermer à moitié le flux (ou arrêter l'envoi dans certaines langues comme Python) lorsque vous voyez
Vous trouverez la transcription finale aux emplacements suivants :
StreamingAnalyzeContentResponse.message.content.- Si vous activez les notifications Pub/Sub, vous pouvez également consulter la transcription dans Pub/Sub.
Démarrez un nouveau flux après la fermeture du précédent.
- Renvoyer l'audio : les données audio générées après le dernier
speech_end_offsetde la réponse avecis_final=trueà la nouvelle heure de début du flux doivent être renvoyées àStreamingAnalyzeContentpour une qualité de transcription optimale.
- Renvoyer l'audio : les données audio générées après le dernier
Le schéma suivant illustre le fonctionnement du flux.
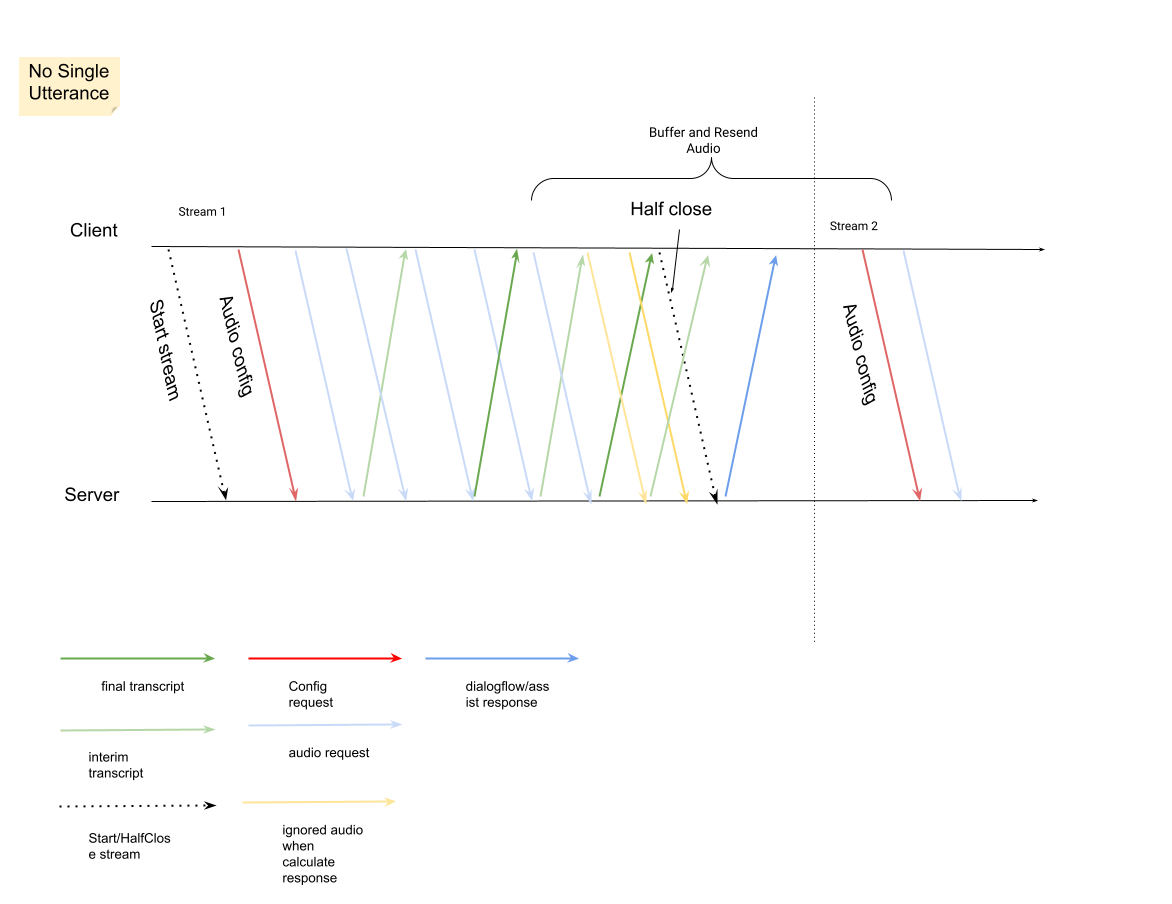
Exemple de code de requête de reconnaissance en streaming
L'exemple de code suivant montre comment envoyer une requête de transcription en flux continu :
Python
Pour vous authentifier auprès d'Agent Assist, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.