La transcripción de voz te permite convertir tus datos de audio en streaming a texto transcrito en tiempo real. Agent Assist hace sugerencias basadas en texto, por lo que los datos de audio deben convertirse antes de poder usarse. También puedes usar audio de streaming transcrito con Estadísticas de conversaciones para recoger datos en tiempo real sobre las conversaciones de los agentes (por ejemplo, Modelado de temas).
Hay dos formas de transcribir audio en streaming para usarlo con Agent Assist: mediante la función SIPREC o haciendo llamadas gRPC con datos de audio como carga útil. En esta página se describe el proceso de transcripción de datos de audio en streaming mediante llamadas gRPC.
La transcripción de voz funciona con el reconocimiento de voz en tiempo real de Speech-to-Text. Speech-to-Text ofrece varios modelos de reconocimiento, tanto estándar como mejorados. La transcripción de voz solo se admite a nivel de GA cuando se usa con el modelo telephony.
Requisitos previos
- Crea un proyecto en Google Cloud.
- Habilita la API de Dialogflow.
- Ponte en contacto con tu representante de Google para asegurarte de que tu cuenta tiene acceso a los modelos mejorados de Speech-to-Text.
Crear un perfil de conversación
Para crear un perfil de conversación, usa la consola Agent Assist o llama al método create en el recurso ConversationProfile directamente.
Para la transcripción de voz, te recomendamos que configures ConversationProfile.stt_config como InputAudioConfig predeterminado al enviar datos de audio en una conversación.
![]()
Obtener transcripciones durante el tiempo de ejecución de la conversación
Para obtener transcripciones durante el tiempo de ejecución de la conversación, debe crear participantes para la conversación y enviar datos de audio de cada participante.
Crear participantes
Hay tres tipos de participantes.
Consulta la documentación de referencia para obtener más información sobre sus roles. Llama al método create en participant y especifica role. Solo un END_USER o un HUMAN_AGENT
participante pueden llamar a StreamingAnalyzeContent, lo cual es necesario para obtener una
transcripción.
Enviar datos de audio y obtener una transcripción
Puedes usar
StreamingAnalyzeContent
para enviar el audio de un participante a Google y obtener la transcripción con los siguientes parámetros:
La primera solicitud de la secuencia debe ser
InputAudioConfig. (Los campos configurados aquí anulan los ajustes correspondientes enConversationProfile.stt_config). No envíes ninguna entrada de audio hasta la segunda solicitud.audioEncodingdebe serAUDIO_ENCODING_LINEAR_16oAUDIO_ENCODING_MULAW.model: es el modelo de voz a texto que quieres usar para transcribir el audio. Asigne el valortelephonya este campo. La variante no influye en la calidad de la transcripción, por lo que puedes dejar Variante del modelo de voz sin especificar o elegir Usar la mejor disponible.singleUtterancedebe tener el valorfalsepara obtener la mejor calidad de transcripción. No deberías esperarEND_OF_SINGLE_UTTERANCEsisingleUtteranceesfalse, pero puedes depender deisFinal==truedentro deStreamingAnalyzeContentResponse.recognition_resultpara cerrar el flujo de forma parcial.- Parámetros adicionales opcionales: los siguientes parámetros son opcionales. Para obtener acceso a estos parámetros, ponte en contacto con tu representante de Google.
languageCode:language_codedel audio. El valor predeterminado esen-US.alternativeLanguageCodes: esta es una función de vista previa. Idiomas adicionales que se pueden detectar en el audio. Asistente usa el campolanguage_codepara detectar automáticamente el idioma al principio del audio y lo establece como predeterminado en todas las interacciones posteriores. El campoalternativeLanguageCodeste permite especificar más opciones para que Agent Assist elija entre ellas.phraseSets: nombre del recurso de adaptación del modelo de Speech-to-TextphraseSet. Para usar la adaptación de modelos con la transcripción de voz, primero debes crear elphraseSetcon la API Speech-to-Text y especificar el nombre del recurso aquí.
Después de enviar la segunda solicitud con la carga útil de audio, deberías empezar a recibir algunos
StreamingAnalyzeContentResponsesde la emisión.- Puedes cerrar el flujo por la mitad (o dejar de enviar en algunos lenguajes, como Python) cuando veas que
is_finalestá configurado comotrueenStreamingAnalyzeContentResponse.recognition_result. - Después de cerrar la emisión a medias, el servidor enviará la respuesta con la transcripción final, junto con posibles sugerencias de Dialogflow o de Asistencia del agente.
- Puedes cerrar el flujo por la mitad (o dejar de enviar en algunos lenguajes, como Python) cuando veas que
Puedes encontrar la transcripción final en las siguientes ubicaciones:
StreamingAnalyzeContentResponse.message.content.- Si habilitas las notificaciones de Pub/Sub, también puedes ver la transcripción en Pub/Sub.
Inicia una nueva emisión después de que se haya cerrado la anterior.
- Reenvío de audio: los datos de audio generados después de los últimos
speech_end_offsetde la respuesta conis_final=truea la nueva hora de inicio de la emisión deben reenviarse aStreamingAnalyzeContentpara obtener la mejor calidad de transcripción.
- Reenvío de audio: los datos de audio generados después de los últimos
En el diagrama se muestra cómo funciona el flujo.
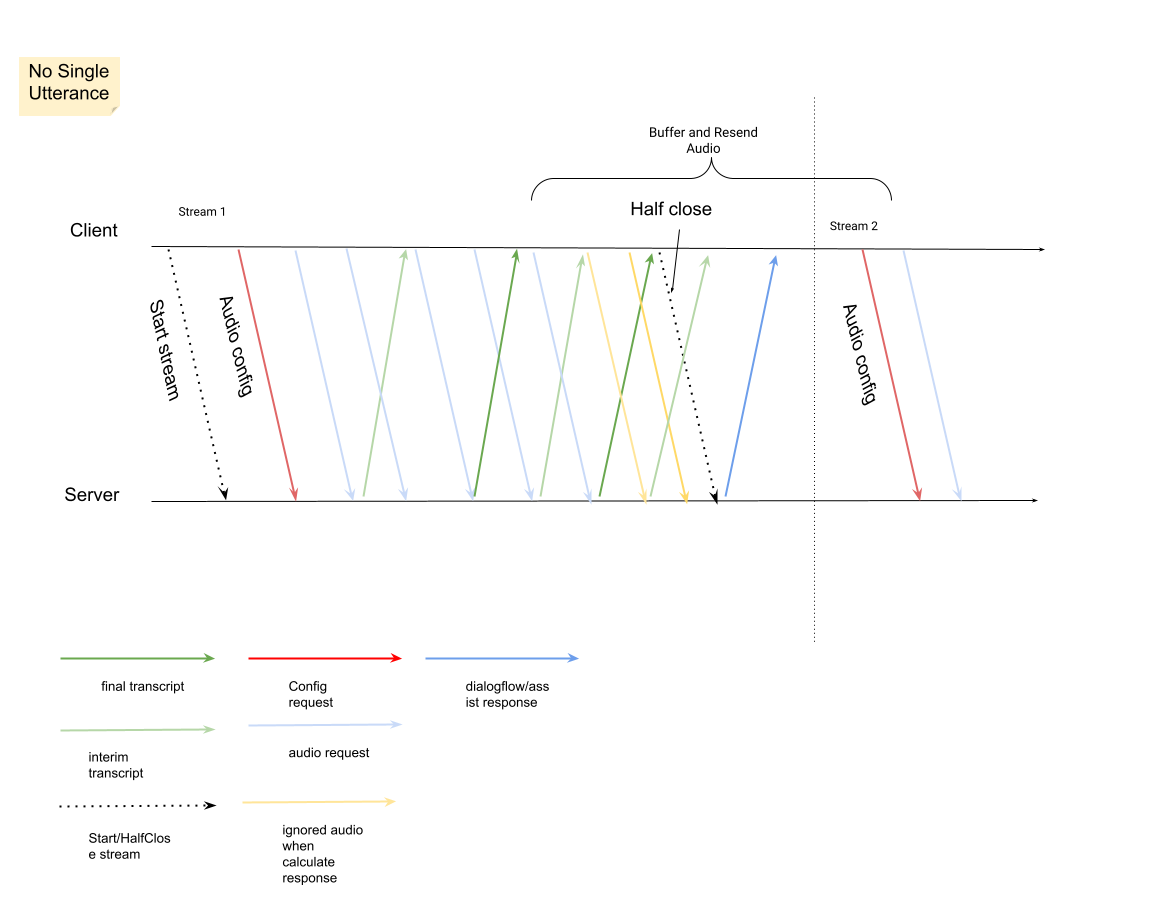
Código de ejemplo de solicitud de reconocimiento por streaming
En el siguiente ejemplo de código se muestra cómo enviar una solicitud de transcripción en streaming:
Python
Para autenticarte en Agent Assist, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.