TPU v6e
Questo documento descrive l'architettura e le configurazioni supportate di Cloud TPU v6e (Trillium).
Trillium è l'acceleratore AI di ultima generazione di Cloud TPU. Su tutte le superfici tecniche, come l'API e i log, e in tutto questo documento, Trillium verrà indicato come v6e.
Con un footprint di 256 chip per pod, v6e condivide molte somiglianze con v5e. Questo sistema è ottimizzato per essere il prodotto di maggior valore per l'addestramento, il perfezionamento e la gestione di transformer, modelli di sintesi di immagini a partire da testo e reti neurali convoluzionali (CNN).
Architettura di sistema
Ogni chip v6e contiene un TensorCore. Ogni Tensor Core ha due unità di moltiplicazione a matrice (MXU), un'unità vettoriale e un'unità scalare. La seguente tabella mostra le specifiche chiave e i relativi valori per la TPU v6e rispetto alla TPU v5e.
| Specifica | v5e | v6e |
|---|---|---|
| Rendimento/costo totale di proprietà (TCO) (previsto) | 0,65x | 1 |
| Picco di calcolo per chip (bf16) | 197 TFLOP | 918 TFLOP |
| Picco di calcolo per chip (Int8) | 393 TOPS | 1836 TOP |
| Capacità HBM per chip | 16 GB | 32 GB |
| Larghezza di banda HBM per chip | 800 GBps | 1600 GBps |
| Larghezza di banda dell'interconnessione inter-chip (ICI) | 1600 Gbps | 3200 Gbps |
| Porte ICI per chip | 4 | 4 |
| DRAM per host | 512 GiB | 1536 GiB |
| Chip per host | 8 | 8 |
| Dimensioni pod di TPU | 256 chip | 256 chip |
| Topologia di interconnessione | Toro 2D | Toro 2D |
| Picco di calcolo BF16 per pod | 50,63 PFLOP | 234,9 PFLOP |
| Larghezza di banda di riduzione totale per pod | 51,2 TB/s | 102,4 TB/s |
| Larghezza di banda bisezionale per pod | 1,6 TB/s | 3,2 TB/s |
| Configurazione NIC per host | NIC 2 x 100 Gbps | NIC 4 x 200 Gbps |
| Larghezza di banda della rete del data center per pod | 6,4 Tbps | 25,6 Tbps |
| Funzionalità speciali | - | SparseCore |
Configurazioni supportate
La tabella seguente mostra le forme delle sezioni 2D supportate per v6e:
| Topologia | Chip TPU | Hosting | VM | Tipo di acceleratore (API TPU) | Tipo di macchina (API GKE) | Ambito |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Sub-host |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Sub-host |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Host singolo |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Host singolo |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Multi-host |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Multi-host |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Multi-host |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Multi-host |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Multi-host |
Gli slice con 8 chip (v6e-8) collegati a una singola VM sono ottimizzati per
l'inferenza, consentendo l'utilizzo di tutti gli 8 chip in un singolo carico di lavoro di serving. Puoi
eseguire l'inferenza multihost utilizzando Pathways on Cloud. Per ulteriori informazioni, vedi
Eseguire l'inferenza multihost utilizzando Pathways.
Per informazioni sul numero di VM per ogni topologia, consulta Tipi di VM.
Tipi di VM
Ogni VM TPU v6e può contenere 1, 4 o 8 chip. Le sezioni da 4 chip e più piccole hanno lo stesso nodo NUMA (accesso alla memoria non uniforme). Per saperne di più sui nodi NUMA, consulta Non-uniform memory access su Wikipedia.
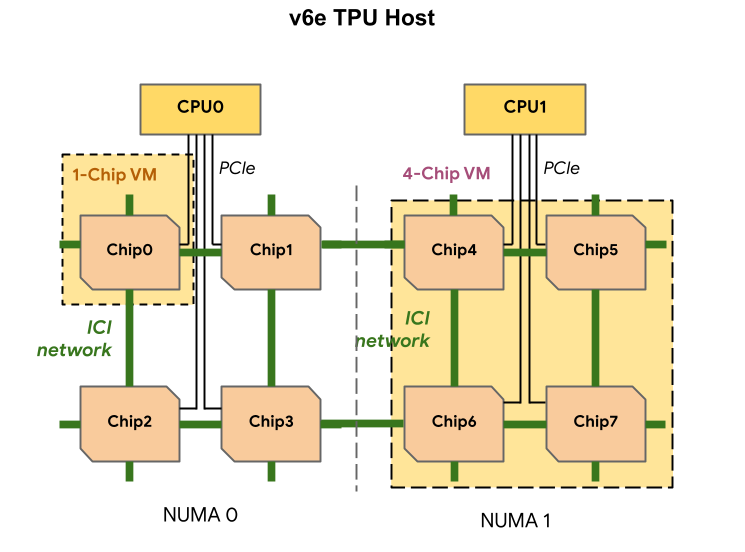
Le sezioni v6e vengono create utilizzando VM half-host, ciascuna con 4 chip TPU. Esistono due eccezioni a questa regola:
v6e-1: Una VM con un solo chip, principalmente destinata ai testv6e-8: una VM full-host ottimizzata per un caso d'uso di inferenza con tutti gli 8 chip collegati a una singola VM.
La tabella seguente mostra un confronto tra i tipi di VM TPU v6e:
| Tipo di VM | Numero di vCPU per VM | RAM (GB) per VM | Numero di nodi NUMA per VM |
|---|---|---|---|
| VM con 1 chip | 44 | 176 | 1 |
| VM a 4 chip | 180 | 720 | 1 |
| VM a 8 chip | 180 | 1440 | 2 |
Specifica la configurazione v6e
Quando allochi una sezione TPU v6e utilizzando l'API TPU, ne specifichi le dimensioni e
la forma utilizzando il parametro AcceleratorType.
Se utilizzi GKE, utilizza il flag --machine-type per specificare un
tipo di macchina che supporti la TPU che vuoi utilizzare. Per maggiori informazioni, consulta la sezione Pianificare le TPU in GKE nella documentazione di GKE.
Utilizza AcceleratorType
Quando allochi risorse TPU, utilizzi AcceleratorType per specificare il numero
di TensorCore in una sezione. Il valore specificato per
AcceleratorType è una stringa con il formato: v$VERSION-$TENSORCORE_COUNT.
Ad esempio, v6e-8 specifica una sezione TPU v6e con 8 TensorCore.
L'esempio seguente mostra come creare uno slice TPU v6e con 32 TensorCore
utilizzando AcceleratorType:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Console
Nella console Google Cloud , vai alla pagina TPU:
Fai clic su Crea TPU.
Nel campo Nome, inserisci un nome per la TPU.
Nella casella Zona, seleziona la zona in cui vuoi creare la TPU.
Nella casella Tipo di TPU, seleziona
v6e-32.Nella casella Versione software TPU, seleziona
v2-alpha-tpuv6e. Quando crei una VM Cloud TPU, la versione del software TPU specifica la versione del runtime TPU da installare. Per saperne di più, consulta Immagini VM TPU.Fai clic sul pulsante di attivazione/disattivazione Attiva la messa in coda.
Nel campo Nome risorsa in coda, inserisci un nome per la richiesta di risorsa in coda.
Fai clic su Crea.