Monitor Cloud TPU VMs
This guide explains how to use Google Cloud Monitoring to monitor your Cloud TPU VMs. Google Cloud Monitoring automatically collects metrics and logs from your Cloud TPU and its host Compute Engine. These data can be used to monitor the health of your Cloud TPU and Compute Engine.
Metrics enable you to track a numerical quantity over time, for example, CPU utilization, network usage, or TensorCore idle duration. Logs capture events at a specific point in time. Log entries are written by your own code, Google Cloud services, third-party applications, and the Google Cloud infrastructure. You can also generate metrics from the data present in a log entry by creating a log-based metric. You can also set alert policies based on metric values or log entries.
This guide discusses Google Cloud Monitoring and shows you how to:
- View Cloud TPU metrics
- Set up Cloud TPU metrics alert policies
- Query Cloud TPU logs
- Create log-based metrics for setting up alerts and visualizing dashboards
To monitor TPUs, you can also use Capacity Planner (Preview). With Capacity Planner, you can view TPU usage and forecast data for your project, folder, or organization. This data updates every 24 hours, and you can use it to analyze usage trends and plan for future capacity needs. For more information, see Capacity Planner overview.
This document assumes some basic knowledge of Google Cloud Monitoring. You must have a Compute Engine VM and Cloud TPU resources created before you can begin generating and working with Google Cloud Monitoring. See the Cloud TPU Quickstart for more details.
Metrics
Google Cloud metrics are automatically generated by Compute Engine VMs and the Cloud TPU runtime. The following metrics are generated by Cloud TPU VMs:
memory/usagenetwork/received_bytes_countnetwork/sent_bytes_countcpu/utilizationtpu/tensorcore/idle_durationaccelerator/tensorcore_utilizationaccelerator/memory_bandwidth_utilizationaccelerator/duty_cycleaccelerator/memory_totalaccelerator/memory_used
It can take up to 180 seconds between the time a metric value is generated and when it's displayed in the Metrics explorer.
For a complete list of metrics generated by Cloud TPU, see Google Cloud Cloud TPU metrics.
Memory usage
The memory/usage metric is generated for the TPU Worker resource and tracks
the memory used by the TPU VM in bytes. This metric is sampled every 60 seconds.
Network received bytes count
The network/received_bytes_count metric is generated for the TPU Worker
resource and tracks the number of cumulative bytes of data the TPU VM received
over the network at a point in time.
Network sent bytes count
The network/sent_bytes_count metric is generated for the TPU Worker resource
and tracks the number of cumulative bytes the TPU VM sent over the network at a
point in time.
CPU utilization
The cpu/utilization metric is generated for the TPU Worker resource and
tracks the current CPU utilization on the TPU worker, represented as a percentage,
sampled once a minute. Values are typically between 0.0 and 100.0, but might
exceed 100.0.
TensorCore idle duration
The tpu/tensorcore/idle_duration metric is generated for the TPU Worker
resource and tracks the number of seconds each TPU chip's TensorCore has been
idle. This metric is available for each chip on all TPUs in use. If a TensorCore
is in use, the idle duration value is reset to zero. When the TensorCore is no
longer in use, the idle duration value starts to increase.
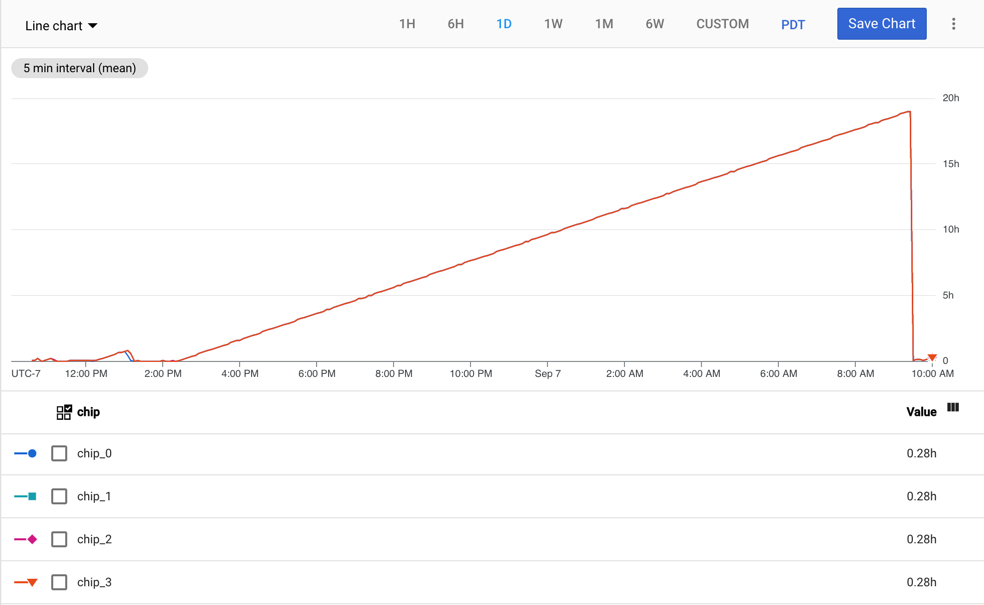
The following graph shows the tpu/tensorcore/idle_duration metric for a v2-8
TPU VM, which has one worker. Each worker has four chips. In this example, all
four chips have the same values for tpu/tensorcore/idle_duration, so the
graphs are superimposed on each other.
TensorCore Utilization
The accelerator/tensorcore_utilization metric is generated for the GCE TPU
Worker resource and tracks the current percentage of the TensorCore that is
utilized. This metric is computed by dividing the number of TensorCore
operations performed over a sample period by the maximum number of operations
that can be performed over the same sample period. A larger value means better
utilization. The TensorCore utilization metric is supported by v4 and newer TPU
generations.
Memory Bandwidth Utilization
The accelerator/memory_bandwidth_utilization metric is generated for the
GCE TPU Worker resource and tracks the current percentage of the accelerator
memory bandwidth that is being used. This metric is computed by dividing the
memory bandwidth used over a sample period by the maximum supported bandwidth
over the same sample period. A larger value means better utilization. The Memory
Bandwidth Utilization metric is supported by v4 and newer TPU generations.
Accelerator Duty Cycle
The accelerator/duty_cycle metric is generated for the GCE TPU Worker
resource and tracks the percentage of time over the sample period during which
the accelerator TensorCore was actively processing. Values are in the range of 0
to 100. A larger value means better TensorCore utilization. This metric is
reported when a machine learning workload is running on the TPU VM. The
Accelerator Duty Cycle metric is supported for JAX
0.4.14 and later,
PyTorch
2.1 and later, and
TensorFlow
2.14.0 and
later.
Accelerator Memory Total
The accelerator/memory_total metric is generated for the GCE TPU Worker
resource and tracks the total accelerator memory allocated in bytes.
This metric is reported when a machine learning workload is running on the TPU
VM. The Accelerator Memory Total metric is supported for JAX
0.4.14 and later,
PyTorch
2.1 and later, and
TensorFlow
2.14.0 and
later.
Accelerator Memory Used
The accelerator/memory_used metric is generated for the GCE TPU Worker
resource and tracks the total accelerator memory used in bytes. This metric is
reported when a machine learning workload is running on the TPU VM. The
Accelerator Memory Used metric is supported for JAX
0.4.14 and later,
PyTorch
2.1 and later, and
TensorFlow
2.14.0 and
later.
Viewing metrics
You can view metrics using the Metrics explorer in the Google Cloud console.
In the Metrics explorer, click Select a metric and search for TPU Worker
or GCE TPU Worker depending upon the metric in which you are interested.
Select a resource to display all available metrics for that resource.
If Active is enabled, only metrics with time series data in the last 25
hours are listed. Disable Active to list all metrics.
Creating alerts
You can create alert policies that tell Cloud Monitoring to send an alert when a condition is met.
The steps in this section show an example of how to add an alert policy for the TensorCore Idle Duration metric. Whenever this metric exceeds 24 hours, Cloud Monitoring sends an email to the registered email address.
- Go to the Monitoring console.
- In the navigation pane, click Alerting.
- Click Edit notification channels.
- Under Email, click Add new. Type an email address, a display name, and click Save.
- On the Alerting page, click Create policy.
- Click Select a metric and then select Tensorcore Idle Duration and click Apply.
- Click Next and then Threshold.
- For Alert trigger, select Any time series violates.
- For Threshold position, select Above threshold.
- For Threshold value, type
86400000. - Click Next.
- Under Notification channels, select your email notification channel and click OK.
- Type a name for the alert policy.
- Click Next and then Create policy.
When the TensorCore Idle Duration exceeds 24 hours, an email is sent to the email address you specified.
Logging
Log entries are written by Google Cloud services, third party services, ML frameworks or your code. You can view logs using the Logs Explorer or Logs API. For more information about Google Cloud logging, see Google Cloud Logging.
TPU Worker logs contain information about a specific
Cloud TPU worker in a specific zone, for example, the amount of memory
available on the Cloud TPU worker (system_available_memory_GiB).
Audited Resource logs contain information about when a
specific Cloud TPU
API was called and who made the call. For example, you can find information
about calls to the CreateNode, UpdateNode, and DeleteNode APIs.
ML frameworks can generate logs to standard output and standard error. These logs are controlled by environment variables and are read by your training script.
Your code can write logs to Google Cloud Logging. For more information, see Write standard logs and Write structured logs.
Serial port logging
Cloud TPU relies on serial port logging for troubleshooting, monitoring, and debugging. The default is to enable serial port logging. If serial port logging is not enabled, the TPU VM creation process fails and generates the following error message.
"Cloud TPU received a bad request. Constraint
`constraints/compute.disableSerialPortLogging` violated. Create TPUs with
serial port logging enabled or remove the Organization Policy Constraint."
This message indicates that the constraint,
constraints/compute.disableSerialPortLogging has been violated.
To prevent this error, you need to ensure serial port logging is permitted for your
TPU projects. The best practice is to override the organization
policy at the project level.
For more information about enabling serial port logging, see Enabling and disabling serial port output logging.
Query Google Cloud logs
When you view logs in the Google Cloud console, the page performs a default query.
You can view the query by selecting the Show query toggle switch. You can
modify the default query or create a new one. For more information, see
Build Queries in the Logs explorer.
Audited resource logs
To view Audited Resource logs:
- Go to the Google Cloud Logs explorer.
- Click the All resources drop-down.
- Click Audited Resource and then Cloud TPU.
- Choose the Cloud TPU API that you're interested in.
- Click Apply. Logs are displayed in the query results.
Click any log entry to expand it. Each log entry has multiple fields, including:
- logName: the name of the log
- protoPayload -> @type: the type of the log
- protoPayload -> resourceName: the name of your Cloud TPU
- protoPayload -> methodName: the name of the method called (audit logs only)
- protoPayload -> request -> @type: the request type
- protoPayload -> request -> node: details about the Cloud TPU node
- protoPayload -> request -> node_id: the name of the TPU
- severity: the severity of the log
TPU Worker logs
To view TPU Worker logs:
- Go to the Google Cloud Logs explorer.
- Click the All resources drop-down.
- Click TPU Worker.
- Select a zone.
- Select the Cloud TPU you're interested in.
- Click Apply. Logs are displayed in the query results.
Click any log entry to expand it. Each log entry has a field called
jsonPayload. Expand jsonPayload to view multiple fields, including:
- accelerator_type: the accelerator type
- consumer_project: the project where the Cloud TPU lives
- evententry_timestamp: the time when the log was generated
- system_available_memory_GiB: the available memory on the Cloud TPU worker (0 ~ 350 GiB)
Creating log-based metrics
This section describes how to create log-based metrics used for setting up monitoring dashboards and alerts. For information about programmatically creating log-based metrics, see Creating log-based metrics programmatically using the Cloud Logging REST API.
The following example uses the system_available_memory_GiB subfield to demonstrate how to create a log-based metric for monitoring Cloud TPU worker available memory.
- Go to the Google Cloud Logs explorer.
In the query box, enter the following query to extract all log entries that have system_available_memory_GiB defined for the primary Cloud TPU worker:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
Click Create metric to display the Metric Editor.
Under Metric Type, choose Distribution.
Type a name, optional description, and unit of measurement for your metric. For this example, type "matrix_unit_utilization_percent" and "MXU utilization" in the Name and Description fields, respectively. The filter is pre-populated with the script that you entered in the Logs Explorer.
Click Create metric.
Click View in Metrics explorer to view your new metric. It might take a few minutes before your metrics are displayed.
Creating log-based metrics with the Cloud Logging REST API
You can also create log-based metrics through the Cloud Logging API. For more information, see Creating a distribution metric.
Creating dashboards and alerts using log-based metrics
Dashboards are useful for visualizing metrics (expect ~2 minute delay); alerts are helpful for sending notifications when errors occur. For more information, see:
Creating dashboards
To create a dashboard in Cloud Monitoring for the Tensorcore idle duration metric:
- Go to the Monitoring console.
- In the navigation pane, click Dashboards.
- Click Create dashboard and then Add widget.
- Choose the chart type that you want to add. For this example, choose Line.
- Type a title for the widget.
- Click the Select a metric drop-down menu and type "Tensorcore idle duration" in the filter field.
- In the list of metrics, select TPU Worker -> Tpu -> Tensorcore idle duration.
- To filter the dashboard contents, click the Filter drop-down menu.
- Under Resource labels, select project_id.
- Choose a comparator and type a value in the Value field.
- Click Apply.