Questo documento descrive come configurare un ambiente che combina i collector di cui è stato eseguito il deployment autonomo con i collector gestiti in diversi progetti e cluster.Google Cloud
Ti consigliamo vivamente di utilizzare la raccolta gestita per tutti gli ambienti Kubernetes. In questo modo elimini praticamente il sovraccarico di esecuzione dei collezionisti Prometheus all'interno del cluster. Puoi eseguire raccoglitori gestiti e con deployment autonomo nello stesso cluster. Ti consigliamo di utilizzare un approccio coerente al monitoraggio, ma puoi scegliere di combinare i metodi di implementazione per alcuni casi d'uso specifici, come l'hosting di un gateway push, come illustrato in questo documento.
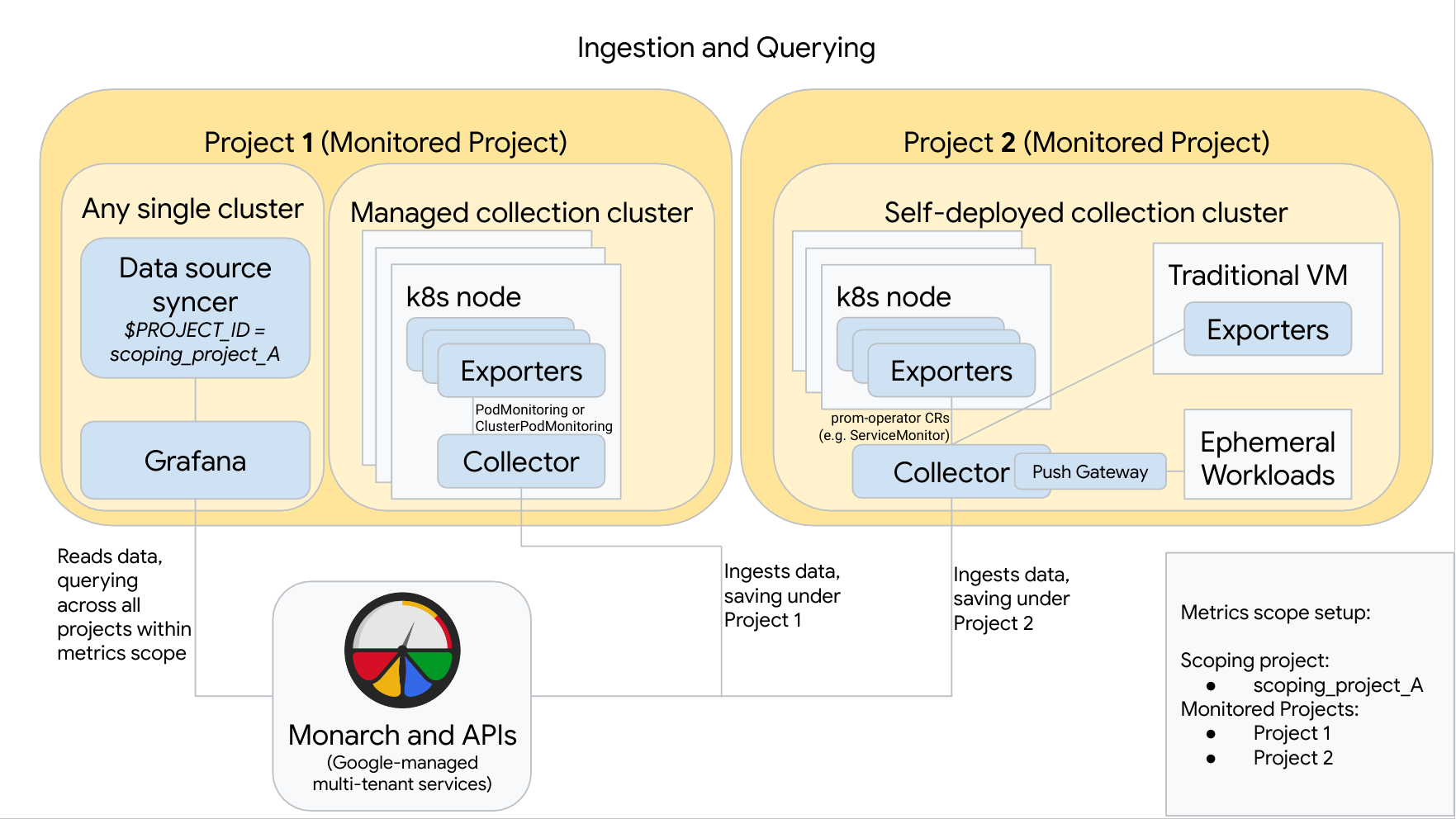
Il seguente diagramma illustra una configurazione che utilizza due progettiGoogle Cloud , tre cluster e combina collezioni gestite e di autodeployment. Se utilizzi solo raccolte gestite o di cui hai eseguito il deployment autonomo, il diagramma è comunque applicabile; ignora lo stile di raccolta che non utilizzi:
Per configurare e utilizzare una configurazione come quella nel diagramma, tieni presente quanto segue:
Devi installare eventuali esportatori necessari nei tuoi cluster. Google Cloud Managed Service per Prometheus non installa esportatori per tuo conto.
Il progetto 1 ha un cluster che esegue la raccolta gestita, che viene eseguita come agente del nodo. I raccoglitori sono configurati con le risorse PodMonitoring per eseguire lo scraping dei target all'interno di uno spazio dei nomi e con le risorse ClusterPodMonitoring per eseguire lo scraping dei target in un cluster. I PodMonitoring devono essere applicati in ogni spazio dei nomi in cui vuoi raccogliere le metriche. I controlli ClusterPodMonitoring vengono applicati una volta per cluster.
Tutti i dati raccolti nel Progetto 1 vengono salvati in Monarch nella sezione Progetto 1. Questi dati vengono archiviati per impostazione predefinita nella Google Cloud regione da cui sono stati emessi.
Il progetto 2 ha un cluster che esegue la raccolta con deployment automatico utilizzando prometheus-operator e funziona come servizio autonomo. Questo cluster è configurato per utilizzare PodMonitor o ServiceMonitor di prometheus-operator per eseguire lo scraping degli esportatori su pod o VM.
Il progetto 2 ospita anche un sidecar del gateway push per raccogliere le metriche dai workload temporanei.
Tutti i dati raccolti nel Progetto 2 vengono salvati in Monarch nella sezione Progetto 2. Questi dati vengono archiviati per impostazione predefinita nella Google Cloud regione da cui sono stati emessi.
Il progetto 1 ha anche un cluster su cui sono in esecuzione Grafana e il sincronizzatore delle origini dati. In questo esempio, questi componenti sono ospitati in un cluster autonomo, ma possono essere ospitati in qualsiasi singolo cluster.
Il sincronizzatore delle origini dati è configurato per utilizzare scoping_project_A e il relativo account di servizio sottostante dispone delle autorizzazioni Visualizzatore monitoraggio per scoping_project_A.
Quando un utente esegue query da Grafana, Monarch espande scoping_project_A nei progetti monitorati costituenti e restituisce risultati sia per il progetto 1 sia per il progetto 2 in tutte le regioni Google Cloud . Tutte le metriche mantengono le etichette
project_idelocation(regioneGoogle Cloud ) originali ai fini di raggruppamento e applicazione di filtri.
Se il cluster non è in esecuzione in Google Cloud, devi configurare manualmente le etichette project_id e location. Per informazioni sull'impostazione di questi valori, consulta Eseguire Managed Service per Prometheus al di fuori diGoogle Cloud.
Non eseguire la federazione quando utilizzi Managed Service per Prometheus. Per ridurre la cardinalità e i costi "aggregando" i dati prima di inviarli a Monarch, utilizza l'aggregazione locale. Per ulteriori informazioni, consulta Configurare l'aggregazione locale.