Questa pagina descrive come utilizzare la dashboard Approfondimenti di sistema di Cloud SQL. La dashboard Insight sul sistema mostra le metriche per le risorse utilizzate dall'istanza e ti aiuta a rilevare e analizzare i problemi di prestazioni del sistema.
Puoi utilizzare l'assistenza di Gemini in Databases per osservare e risolvere i problemi delle risorse Cloud SQL per PostgreSQL. Per saperne di più, consulta Osservare e risolvere i problemi con l'assistenza di Gemini.Visualizzare la dashboard degli insight sul sistema
Per visualizzare la dashboard Approfondimenti di sistema:
-
Nella console Google Cloud , vai alla pagina Istanze Cloud SQL.
- Fai clic sul nome di un'istanza.
Seleziona la scheda Approfondimenti di sistema dal pannello di navigazione SQL a sinistra.
Viene visualizzata la dashboard Approfondimenti di sistema.
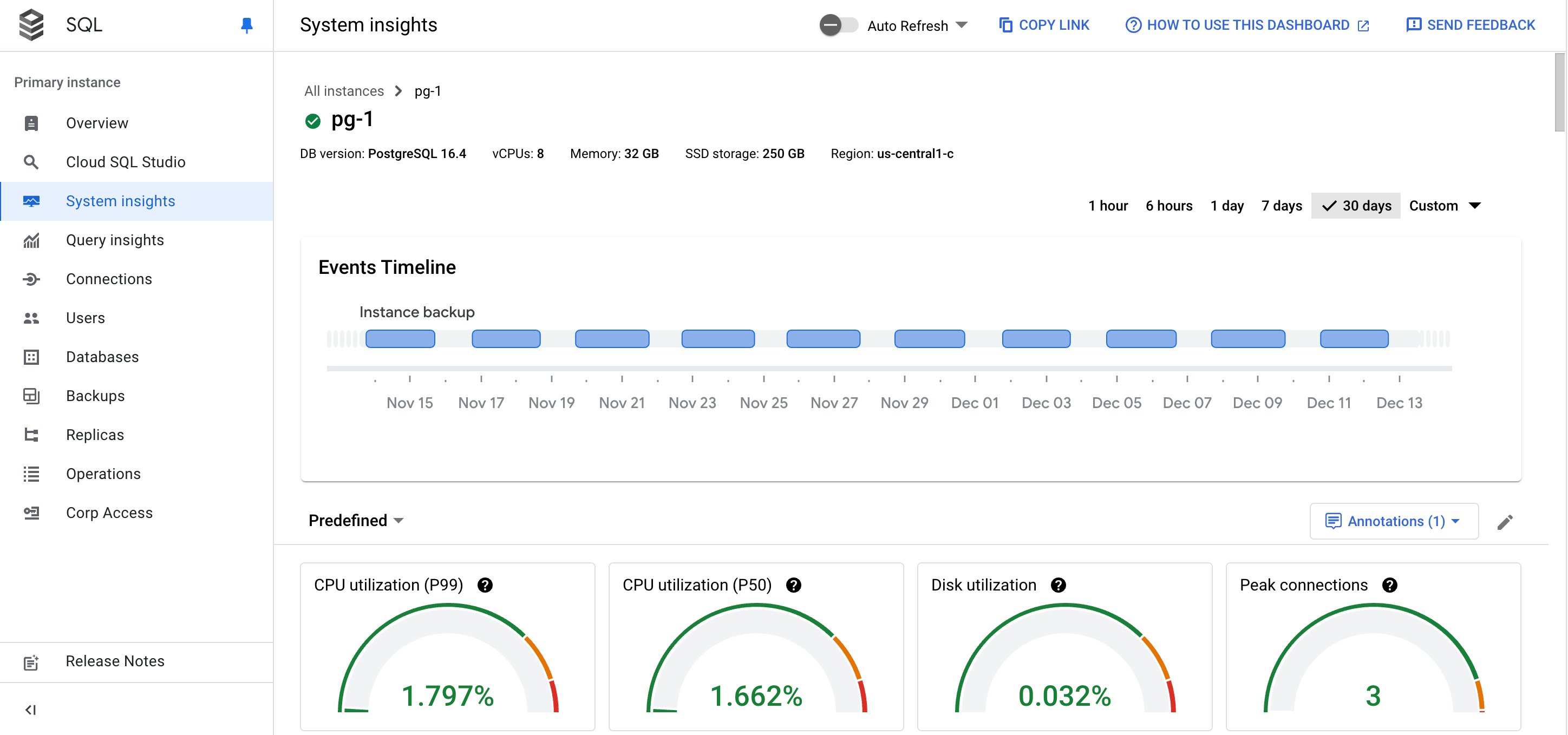
La dashboard Approfondimenti di sistema mostra le seguenti informazioni:
Dettagli dell'istanza
Cronologia eventi: mostra gli eventi di sistema in ordine cronologico. Queste informazioni ti aiutano a valutare l'impatto degli eventi di sistema sull'integrità e sulle prestazioni dell'istanza.
Schede di riepilogo: forniscono una panoramica dell'integrità e del rendimento dell'istanza visualizzando i valori più recenti e aggregati per le metriche relative a utilizzo della CPU, utilizzo del disco ed errori nei log.
Grafici delle metriche: mostrano le informazioni sulle metriche del sistema operativo e del database che ti aiutano a ottenere informazioni su diversi problemi, come throughput, latenza e costi.
La dashboard offre le seguenti opzioni di alto livello:
- Per visualizzare uno o due grafici per riga. Fai clic su Personalizza visualizzazione per scegliere come vengono visualizzati questi grafici. Puoi anche utilizzare questa opzione per scegliere le metriche da visualizzare nella dashboard.
Per mantenere aggiornata la dashboard, attiva l'opzione
 Aggiornamento automatico. Quando abiliti l'aggiornamento automatico, i dati della dashboard
vengono aggiornati ogni minuto. Questa funzionalità non è compatibile con i periodi di tempo personalizzati.
Aggiornamento automatico. Quando abiliti l'aggiornamento automatico, i dati della dashboard
vengono aggiornati ogni minuto. Questa funzionalità non è compatibile con i periodi di tempo personalizzati.Il selettore dell'ora mostra
1 dayselezionato per impostazione predefinita. Per modificare il periodo, seleziona uno degli altri periodi predefiniti o fai clic su Personalizzato e definisci un orario di inizio e di fine. I dati sono disponibili per gli ultimi 30 giorni.Per creare un link assoluto alla dashboard, fai clic sul pulsante Copia link. Puoi condividere questo link con altri utenti Cloud SQL che dispongono delle stesse autorizzazioni.
Per creare un avviso per un evento specifico, fai clic su Notifica.
Per visualizzare avvisi specifici, fai clic su Annotazioni.
Schede riepilogative
La tabella seguente descrive le schede riepilogative visualizzate nella parte superiore della dashboard System Insights. Queste schede forniscono una breve panoramica dello stato e del rendimento dell'istanza durante il periodo di tempo scelto.
| Scheda riepilogativa | Descrizione |
|---|---|
| Utilizzo CPU - P99 | P50 | I valori di utilizzo della CPU P99 e P50 nel periodo selezionato. |
| Picco di connessioni | Il rapporto tra le connessioni di picco e le connessioni massime per il periodo selezionato.
Il numero massimo di connessioni potrebbe essere superiore al numero massimo nel caso in cui
il numero massimo sia stato modificato di recente, ad esempio a causa del ridimensionamento dell'istanza o
della modifica manuale dell'impostazione max_connections. |
| Utilizzo ID transazione | L'ultimo valore di utilizzo dell'ID transazione per il periodo selezionato. |
| Utilizzo del disco | Il valore più recente di utilizzo del disco. |
| Errori nei log | Il numero di errori registrati dagli utenti. |
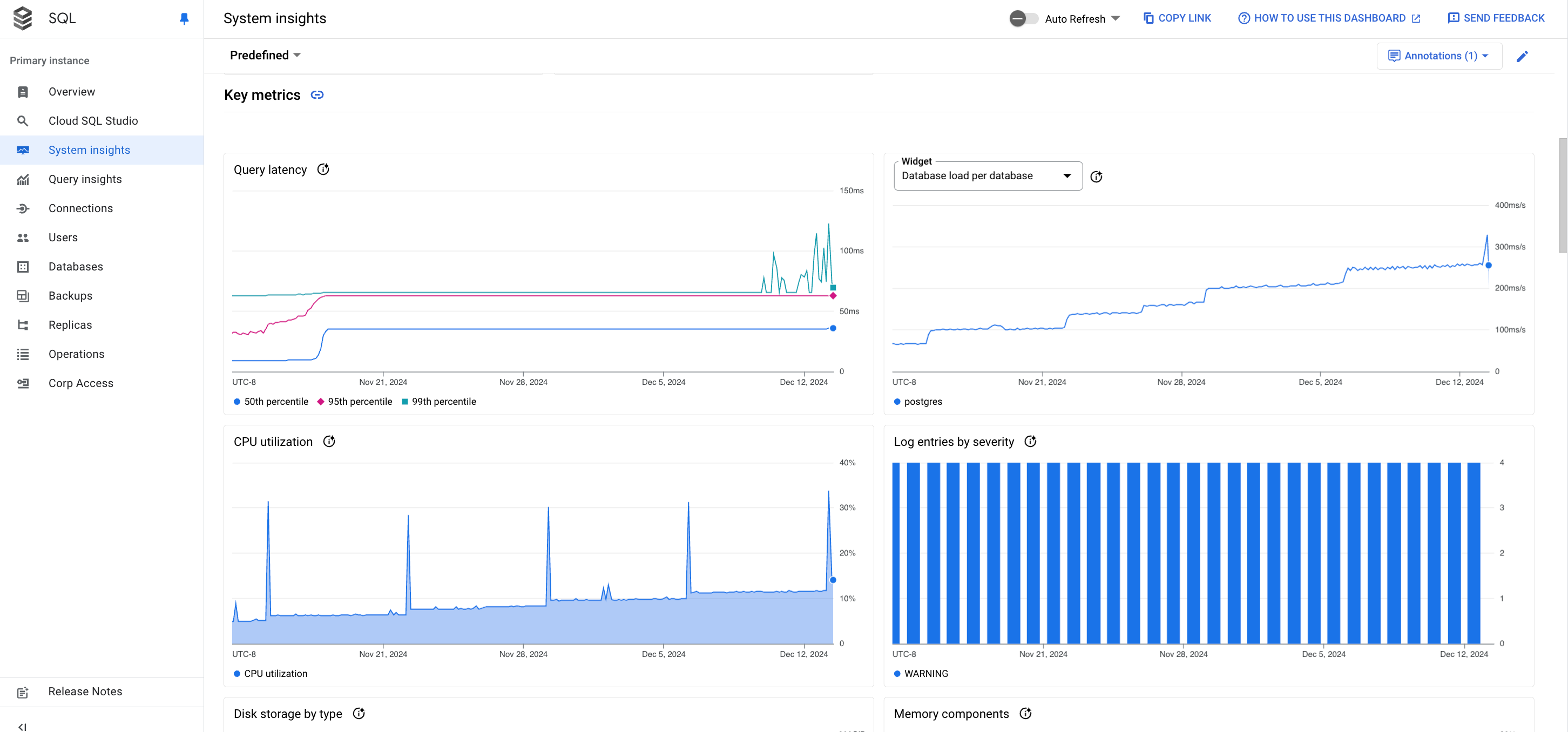
Grafici delle metriche
Una scheda grafico per una metrica di esempio viene visualizzata nel seguente modo.
La barra degli strumenti su ogni scheda del grafico fornisce il seguente insieme di opzioni standard:
Per visualizzare i valori delle metriche per un momento specifico del periodo selezionato, sposta il cursore sul grafico.
Per ingrandire un grafico, fai clic sul grafico e trascina orizzontalmente lungo l'asse X o verticalmente lungo l'asse Y. Per ripristinare l'operazione di zoom, fai clic su Reimposta zoom. In alternativa, fai clic su uno dei periodi di tempo predefiniti nella parte superiore della dashboard. Le operazioni di zoom vengono applicate contemporaneamente a tutti i grafici di una dashboard.
Per visualizzare altre opzioni, fai clic su more_vert Altre opzioni per il grafico. La maggior parte dei grafici offre queste opzioni:
Per visualizzare un grafico in modalità a schermo intero, fai clic su Visualizza a schermo intero. Per uscire dalla modalità a schermo intero, fai clic su Annulla.
Nascondere o comprimere la legenda.
Scarica un file PNG o CSV del grafico.
Visualizza in Esplora metriche. Visualizza la metrica in Esplora metriche. Puoi visualizzare altre metriche Cloud SQL in Metrics Explorer dopo aver selezionato il tipo di risorsa Database Cloud SQL.
Per creare una dashboard personalizzata, fai clic su edit Personalizza dashboard e assegnale un nome. In alternativa, espandi il menu Predefinito e seleziona una dashboard personalizzata esistente.
Per visualizzare in dettaglio i dati di un grafico delle metriche, fai clic su query_stats Esplora dati. Qui puoi filtrare metriche specifiche e scegliere la modalità di visualizzazione del grafico:
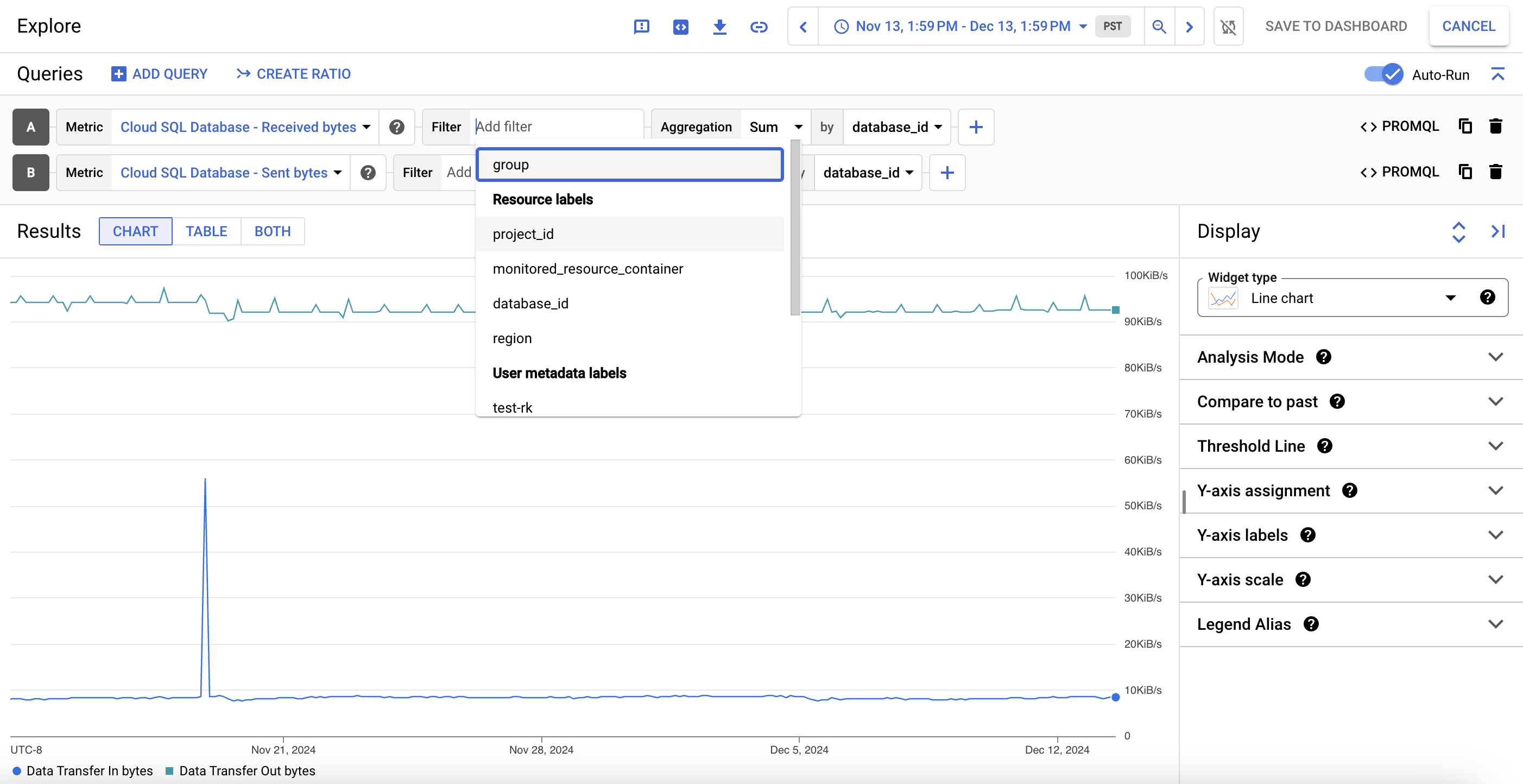
Per salvare questa visualizzazione personalizzata come grafico delle metriche, fai clic su Salva nella dashboard.
Metriche predefinite
La tabella seguente descrive le metriche Cloud SQL visualizzate per impostazione predefinita nella dashboard Approfondimenti di sistema di Cloud SQL.
Le stringhe del tipo di metrica seguono questo prefisso:
cloudsql.googleapis.com/database/.
Per la disponibilità più recente della fase di lancio delle seguenti metriche, consulta le Google Cloud metriche.
| Nome e tipo di metrica | Descrizione |
|---|---|
Nuove connessioni al secondopostgresql/new_connection_count
|
La frequenza del numero di nuove connessioni create nell'istanza Cloud SQL per PostgreSQL, al secondo. Cloud SQL calcola e mostra questa metrica per database. Questa metrica è disponibile per PostgreSQL versione 14 e successive. |
Tipi di eventi di attesa
postgresql/backends_in_wait
|
Il numero di connessioni per ogni tipo di evento di attesa in un'istanza Cloud SQL per PostgreSQL. |
Eventi di attesapostgresql/backends_in_wait
|
Il numero di eventi di attesa in un'istanza Cloud SQL per PostgreSQL. La dashboard mostra questa metrica come nome evento di attesa:tipo di evento di attesa. |
Conteggio transazionipostgresql/transaction_count
|
Numero di transazioni negli stati |
Componenti di memoriamemory/components
|
I componenti di memoria disponibili per il database. Il valore di ogni componente di memoria viene calcolato come percentuale della memoria totale disponibile per il database. |
Ritardo di replica massimo (byte)postgresql/external_sync/max_replica_byte_lag
|
Il ritardo di replica massimo (in byte) tra tutti i database sulla replica del server esterno. |
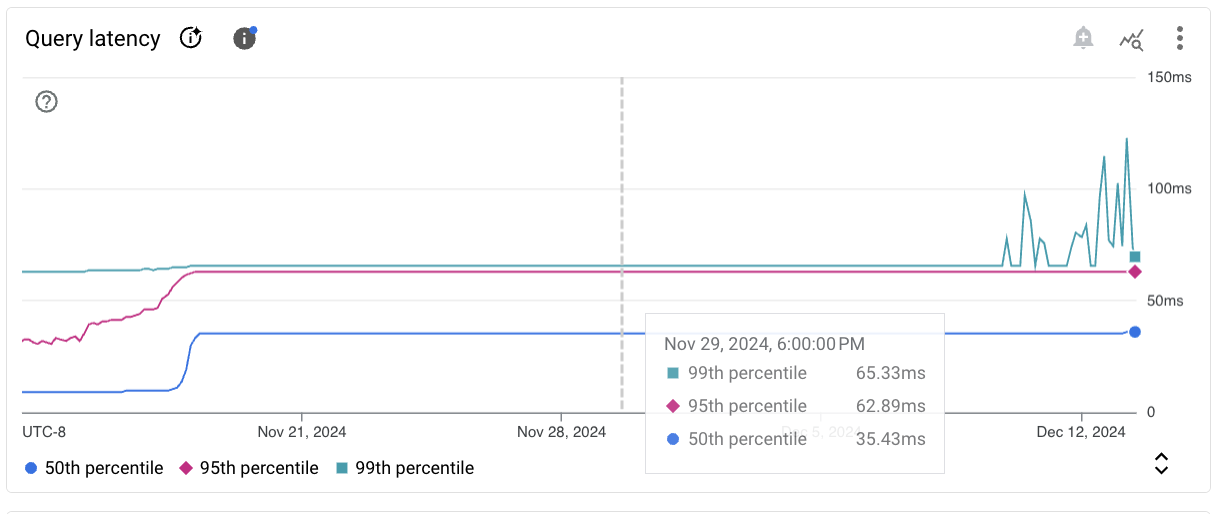
Latenza querypostgresql/insights/aggregate/latencies |
Distribuzione della latenza aggregata delle query in base a P99, P95 e P50 per utente e database. Disponibile solo per le istanze con Query Insights abilitato. |
Carico database per database/utente/indirizzo clientpostgresql/insights/aggregate/execution_time |
Il tempo di esecuzione della query accumulato per database, utente o indirizzo client. È la somma di tempo di CPU, tempo di attesa I/O, tempo di attesa blocco, commutazioni di contesto del processo e pianificazione per tutti i processi coinvolti nell'esecuzione della query. Disponibile solo per le istanze con Query Insights abilitato. |
Utilizzo CPUcpu/utilization |
L'utilizzo attuale della CPU rappresentato come percentuale della CPU prenotata attualmente in uso. |
Archiviazione disco per tipodisk/bytes_used_by_data_type
|
Suddivisione dell'utilizzo del disco di istanza in base ai tipi di dati, tra cui Questa metrica ti aiuta a comprendere i costi di archiviazione. Per ulteriori informazioni sui costi di utilizzo dello spazio di archiviazione, consulta Prezzi di archiviazione e networking. Il recupero point-in-time (PITR) utilizza l'archiviazione dei log write-ahead (WAL). Questi log vengono aggiornati regolarmente e utilizzano spazio di archiviazione. I log write-ahead vengono eliminati automaticamente con il backup automatico associato, il che in genere avviene dopo circa 7 giorni. Se le dimensioni dei log write-ahead causano un problema per la tua istanza, puoi aumentare le dimensioni dello spazio di archiviazione, ma l'aumento delle dimensioni dei log write-ahead nell'utilizzo del disco potrebbe essere temporaneo. Per evitare problemi imprevisti di spazio di archiviazione, Google consiglia di abilitare gli aumenti automatici dello spazio di archiviazione quando utilizzi il recupero point-in-time. Per eliminare i log e recuperare spazio di archiviazione, puoi disattivare il recupero point-in-time. Tieni presente, tuttavia, che la riduzione dello spazio di archiviazione utilizzato non riduce le dimensioni dello spazio di archiviazione di cui è stato eseguito il provisioning per l'istanza. I dati temporanei sono inclusi nella metrica di utilizzo dello spazio di archiviazione. I dati temporanei vengono rimossi nell'ambito della manutenzione e possono aumentare oltre i limiti di capacità definiti dall'utente per evitare un evento di disco pieno, senza costi per l'utente. Un database appena creato utilizza circa 100 MB per le tabelle e i file di sistema. |
Archiviazione disco per tipodisk/bytes_used_by_data_type
|
Suddivisione dell'utilizzo del disco di istanza in base ai tipi di dati, tra cui Questa metrica ti aiuta a comprendere i costi di archiviazione. Per ulteriori informazioni sui costi di utilizzo dello spazio di archiviazione, consulta Prezzi di archiviazione e networking. Il recupero point-in-time utilizza l'archiviazione dei log write-ahead (WAL). Per le nuove istanze Cloud SQL per cui è attivato il ripristino point-in-time o per le istanze esistenti per cui viene attivato il ripristino point-in-time dopo che questa funzionalità per l'archiviazione dei log WAL in Cloud Storage è disponibile, i log non verranno più archiviati su disco, ma in Cloud Storage nella stessa regione delle istanze. Per verificare se i log di un'istanza sono archiviati in Cloud Storage, controlla la metrica bytes_used_by_data_type per l'istanza. Se il
valore per il tipo di dati Tutte le altre istanze esistenti per cui è abilitato il ripristino temporizzato continuano a memorizzare i log sul disco. La modifica all'archiviazione dei log in Cloud Storage verrà resa disponibile in un secondo momento. I log write-ahead utilizzati nel recupero point-in-time vengono eliminati automaticamente con il backup automatico associato, il che in genere avviene dopo che è stato raggiunto il valore impostato per transactionLogRetentionDays. È il numero di giorni di log delle transazioni che Cloud SQL conserva per il recupero point-in-time, da 1 a 7. Per le istanze con log write-ahead archiviati in Cloud Storage, i log vengono archiviati nella stessa regione dell'istanza primaria. Questo spazio di archiviazione dei log (fino a sette giorni, la durata massima per il recupero point-in-time) non genera costi aggiuntivi per istanza. Se il recupero point-in-time è abilitato per l'istanza e se le dimensioni dei log write-ahead sul disco causano un problema per l'istanza, disabilita il recupero point-in-time e riabilitalo per assicurarti che i nuovi log vengano archiviati in Cloud Storage nella stessa regione dell'istanza. In questo modo vengono eliminati i log write-ahead esistenti, quindi non puoi eseguire un ripristino point-in-time precedente al momento in cui hai riattivato il recupero point-in-time. Tuttavia, anche se i log esistenti vengono eliminati, le dimensioni del disco rimangono invariate. Per evitare problemi di spazio di archiviazione imprevisti, ti consigliamo di abilitare gli aumenti automatici dello spazio di archiviazione per tutte le istanze quando utilizzi il ripristino point-in-time. Questo suggerimento si applica solo se il recupero point-in-time è abilitato per la tua istanza e i log sono archiviati su disco. Per eliminare i log e recuperare spazio di archiviazione, puoi disattivare il recupero point-in-time. Tieni presente, tuttavia, che la riduzione dei log write-ahead utilizzati non riduce le dimensioni del disco di cui è stato eseguito il provisioning per l'istanza. I dati temporanei sono inclusi nella metrica di utilizzo dello spazio di archiviazione. I dati temporanei vengono rimossi nell'ambito della manutenzione e possono aumentare oltre i limiti di capacità definiti dall'utente per evitare un evento di disco pieno, senza costi per l'utente. Un database appena creato utilizza circa 100 MB per le tabelle e i file di sistema. |
Operazioni di lettura/scrittura su discodisk/read_ops_count, disk/write_ops_count |
La metrica Numero di letture indica il numero di operazioni di lettura gestite da disco che non provengono dalla cache. Puoi utilizzare questa metrica per capire se la tua istanza è dimensionata correttamente per il tuo ambiente. Se necessario, puoi passare a un tipo di macchina più grande per gestire più richieste dalla cache e ridurre la latenza. La metrica Numero di scritture indica il numero di operazioni di scrittura su disco. L'attività di scrittura viene generata anche se l'applicazione non è attiva perché le istanze Cloud SQL, escluse le repliche, scrivono in una tabella di sistema circa ogni secondo. |
Connessioni per statopostgresql/num_backends_by_state |
Il numero di connessioni raggruppate in base a questi stati: Per informazioni su questi stati,
consulta la riga |
Connessioni per databasepostgresql/num_backends |
Numero di connessioni mantenute dall'istanza di database. |
Byte in entrata/uscitanetwork/received_bytes_count, network/sent_bytes_count |
Traffico di rete in termini di numero di byte in entrata (byte ricevuti) e byte in uscita (byte inviati) rispettivamente da e verso l'istanza. |
Suddivisione dell'attesa I/O per tipopostgresql/insights/aggregate/io_time |
Suddivisione del tempo di attesa I/O per le istruzioni SQL in base ai tipi di lettura e scrittura. Disponibile solo per le istanze con Query Insights abilitato. |
Conteggio deadlock per databasepostgresql/deadlock_count |
Il numero di deadlock per database. |
Conteggio blocchi letturapostgresql/blocks_read_count |
Il numero di blocchi letti al secondo dal disco e dalla cache del buffer. |
Righe elaborate per operazionepostgresql/tuples_processed_count |
Il numero di righe elaborate per operazione al secondo. |
Righe nel database per statopostgresql/tuple_size |
Il numero di righe per ogni stato del database. Cloud SQL segnala questa metrica se il numero di database nell'istanza è inferiore a 50. |
Transazione meno recente in base all'etàpostgresql/vacuum/oldest_transaction_age |
Età della transazione meno recente che blocca l'operazione vacuum. |
Archiviazione WALreplication/log_archive_success_count, replication/log_archive_failure_count |
Numero di file di log write-ahead archiviati correttamente o non archiviati al minuto. |
Utilizzo ID transazionepostgresql/transaction_id_utilization |
La percentuale di ID transazione utilizzati nell'istanza. |
Conteggio delle connessioni per nome applicazionepostgresql/num_backends_by_application |
Numero di connessioni all'istanza Cloud SQL, raggruppate per applicazioni. |
Righe recuperate, righe restituite e righe scritte
|
Se la differenza tra le righe restituite e quelle recuperate è così grande che i loro valori non vengono visualizzati nella stessa scala, il valore delle righe recuperate viene visualizzato come 0 perché è trascurabile rispetto al valore delle righe restituite. |
Dimensione dati temporaneipostgresql/temp_bytes_written_count |
La quantità totale di dati (in byte) utilizzati per l'esecuzione di query e algoritmi come join e ordinamento. |
File temporaneipostgresql/temp_files_written_count |
Numero di file temporanei utilizzati per l'esecuzione di query e algoritmi come join e ordinamento. |
Inoltre, la metrica Cloud Logging, Voci di log per gravità (logging.googleapis.com/log_entry_count),
mostra il numero totale di voci di log di errore e avviso.
Vengono estratti
da postgres.log, che è il log del database, e pgaudit.log,
che contiene le informazioni sull'accesso ai dati.
Per ulteriori informazioni, consulta Metriche Cloud SQL.
Cronologia degli eventi
La dashboard fornisce i dettagli dei seguenti eventi:
| Nome evento | Descrizione | Tipo di operazione |
|---|---|---|
Instance restart |
Riavvia l'istanza Cloud SQL | RESTART |
Instance failover |
Avvia un failover manuale di un'istanza principale ad alta disponibilità (HA) a un'istanza in standby, che diventa l'istanza principale. | FAILOVER |
Instance maintenance |
Indica che l'istanza è attualmente in manutenzione. In genere, la manutenzione causa l'indisponibilità dell'istanza per 1-3 minuti. | MAINTENANCE |
Instance backup |
Esegue un backup dell'istanza. | BACKUP_VOLUME |
Instance update |
Aggiorna le impostazioni di un'istanza Cloud SQL. | UPDATE |
Promote replica |
Promuove un'istanza di replica Cloud SQL. | PROMOTE_REPLICA |
Start replica |
Avvia la replica su un'istanza di replica di lettura Cloud SQL. | START_REPLICA |
Stop replica |
Interrompe la replica su un'istanza di replica di lettura Cloud SQL. | STOP_REPLICA |
Recreate replica |
Ricrea le risorse per un'istanza di replica Cloud SQL. | RECREATE_REPLICA |
Create replica |
Crea un'istanza di replica Cloud SQL. | CREATE_REPLICA |
Data import |
Importa i dati in un'istanza Cloud SQL. | IMPORT |
Instance export |
Esporta i dati da un'istanza Cloud SQL a un bucket Cloud Storage. | EXPORT |
Restore backup |
Ripristina un backup di un'istanza Cloud SQL. Questa operazione potrebbe causare il riavvio dell'istanza. | RESTORE_VOLUME |