Cortex Framework: integration with CM360
This page describes the required configurations to bring data from Campaign Manager 360 as a data source of the marketing workload of Cortex Data Foundation.
Campaign Manager 360 (CM360) is a web-based advertising management platform offered by Google specifically designed for advertisers and agencies. It functions as a central hub to manage and optimize all your digital advertising campaigns across various channels. Cortex Framework provides the tools and platform to analyze CM360 data, combine it with data from other marketing channels, and use AI to gain deeper insights and optimize your overall marketing strategy. See CM360 Reporting Data Model in the Cortex Data Foundation repository.
{kind=link}
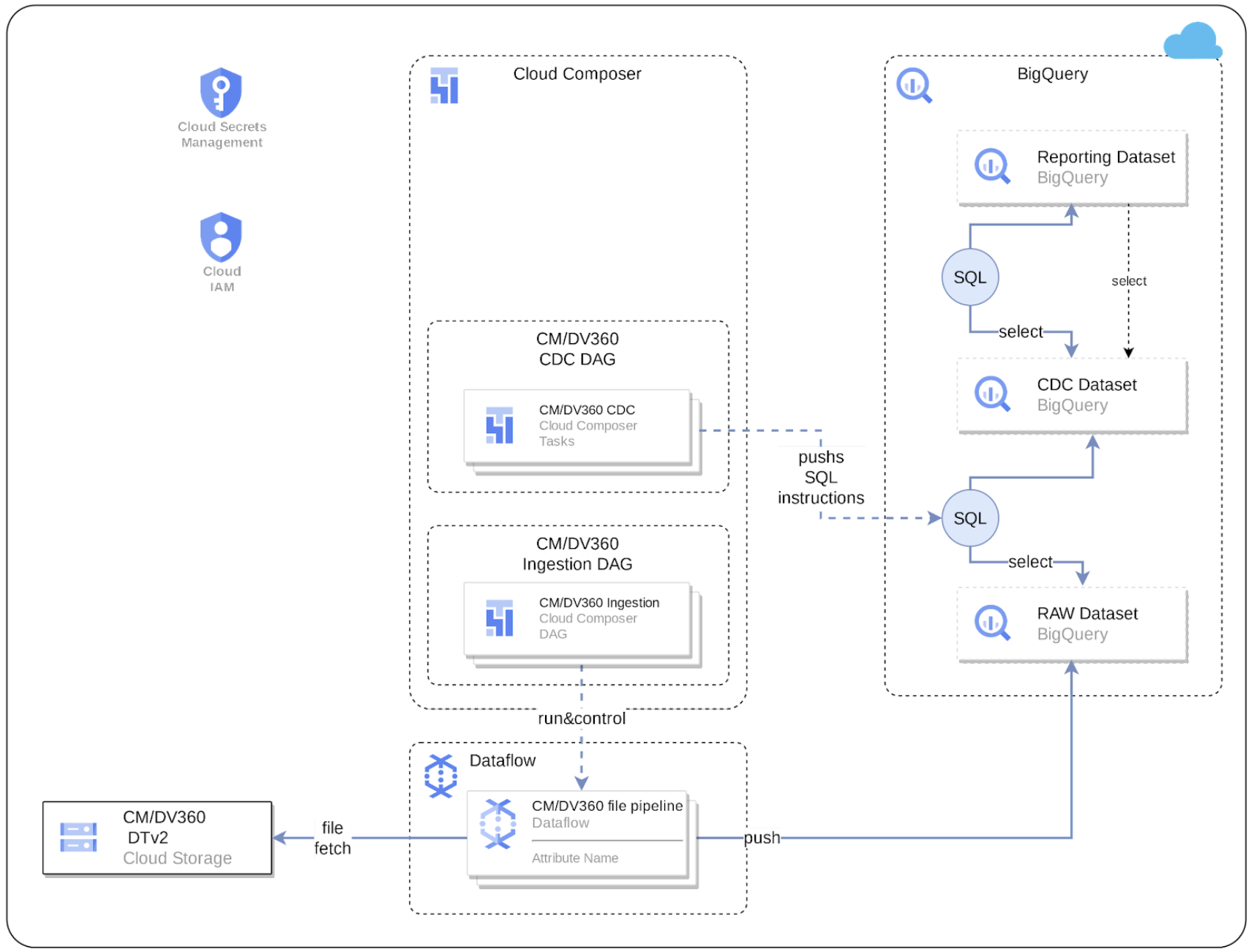
The following diagram describes how CM360 data is available through the marketing workload of Cortex Data Foundation:
Configuration file
The config.json file configures the settings required to connect to data sources for transferring
data from various workloads. This file contains the following parameters for CM360:
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
The following table describes the value for each marketing parameter:
| Parameter | Meaning | Default Value | Description |
marketing.deployCM360
|
Deploy CM360 | true
|
Execute the deployment for CM360 data source. |
marketing.CM360.deployCDC
|
Deploy CDC scripts for CM360 | true
|
Generate CM360 CDC processing scripts to run as DAGs in Cloud Composer. |
marketing.CM360.dataTransferBucket
|
Bucket with Data Transfer Service results | - | Bucket where DTv2 files are stored. |
marketing.CM360.datasets.cdc
|
CDC dataset for CM360 | CDC dataset for CM360. | |
marketing.CM360.datasets.raw
|
Raw dataset for CM360 | Raw dataset for CM360. | |
marketing.CM360.datasets.reporting
|
Reporting dataset for CM360 | "REPORTING_CM360"
|
Reporting dataset for CM360. |
DTv2 Files storage
DTv2 (Data Transfer Version 2) files are a specific format used by CM360 to deliver campaign performance data. Set up the data transfer process by following the Data Transfer V2.0 documentation in order to use CM360 with Cortex Framework.
Create or add a Cloud Storage bucket for storing your DTv2 files from CM360. Ensure the files under the bucket are readable by the service account running DAGs in Cloud Composer. For more information, see Create storage buckets.
Cloud Composer connections
Create the following connections in Cloud Composer. For more details, see the Manage Airflow connections documentation.
| Connection Name | Purpose |
cm360_raw_dataflow
|
For CM360 DTv2 files > BigQuery Raw Dataset |
cm360_cdc_bq
|
For Raw dataset > CDC dataset transfer |
cm360_reporting_bq
|
For CDC dataset > Reporting dataset transfer |
Cloud Composer service account permissions
Grant Dataflow permissions to the service account used in
Cloud Composer (as configured in the cm360_raw_dataflow connection).
See instructions in Dataflow documentation.
Ingestion settings
Control Source to Raw and Raw to CDC data pipelines through the settings in
the file src/CM360/config/ingestion_settings.yaml. This section describes the parameters of each data pipeline.
Source to raw tables
This section describes how entries that control which files from DTv2 are processed. Each entry corresponds with files associated with one entity. Based on this configuration, Cortex Framework creates Airflow DAGs that run Dataflow pipelines to process data from the DTv2 files.
The following parameters control the settings for Source to Raw
for each entry:
| Parameter | Description |
base_table
|
Table in Raw dataset where the data for an entity is stored (for example, 'Clicks' data). |
load_frequency
|
How frequently a DAG for this entity runs to populate the CDC table. For more information about possible values, see Airflow documentation. |
file_pattern
|
Based filename patterns that correspond to an entity. |
schema_file
|
Schema file in src/table_schema
directory that maps DTv2 fields to destination table's column names and data types.
|
partition_details
|
Optional: If you want this table to be partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want this table to be clustered for performance considerations. For more information, see Cluster Settings. |
Raw to CDC tables
This section has entries that control how data is moved from raw tables to CDC tables. Each entry corresponds with a raw table (which in turn corresponds with the DTv2 entity as mentioned above.)
The following parameters control the settings for Raw to CDC for each entry:
| Parameter | Description |
base_table
|
Table in CDC dataset where the raw data
after CDC transformation is stored (for example, customer).
|
load_frequency
|
How frequently a DAG for this entity runs to populate the CDC table. For more information about possible values, see Airflow documentation. |
row_identifiers
|
List of columns (separated by comma) that forms a unique record for this table. |
partition_details
|
Optional: If you want this table to be partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want this table to be clustered for performance considerations. For more information, see Cluster Settings. |
Reporting settings
You can configure and control how Cortex Framework generates data
for the CM360 final reporting layer using the reporting settings file (src/CM360/config/reporting_settings.yaml).
This file controls how reporting layer BigQuery objects
(tables, views, functions or stored procedures) are generated.
For more information, see Customizing reporting settings file.
What's next?
- For more information about other data sources and workloads, see Data sources and workloads.
- For more information about the steps for deployment in production environments, see Cortex Data Foundation deployment prerequisites.