Integration with Salesforce Marketing Cloud
This page describes the required configurations to bring data from Salesforce Marketing Cloud (SFMC) as a data source of the marketing workload of Cortex Framework Data Foundation.
SFMC is a digital marketing automation platform offered by Salesforce. It provides businesses with a comprehensive suite of tools to manage and automate various marketing activities across multiple channels. Cortex Framework acts as the data analysis and AI engine that helps you understand the results, identify areas for improvement, and optimize your marketing strategy for better outcomes.
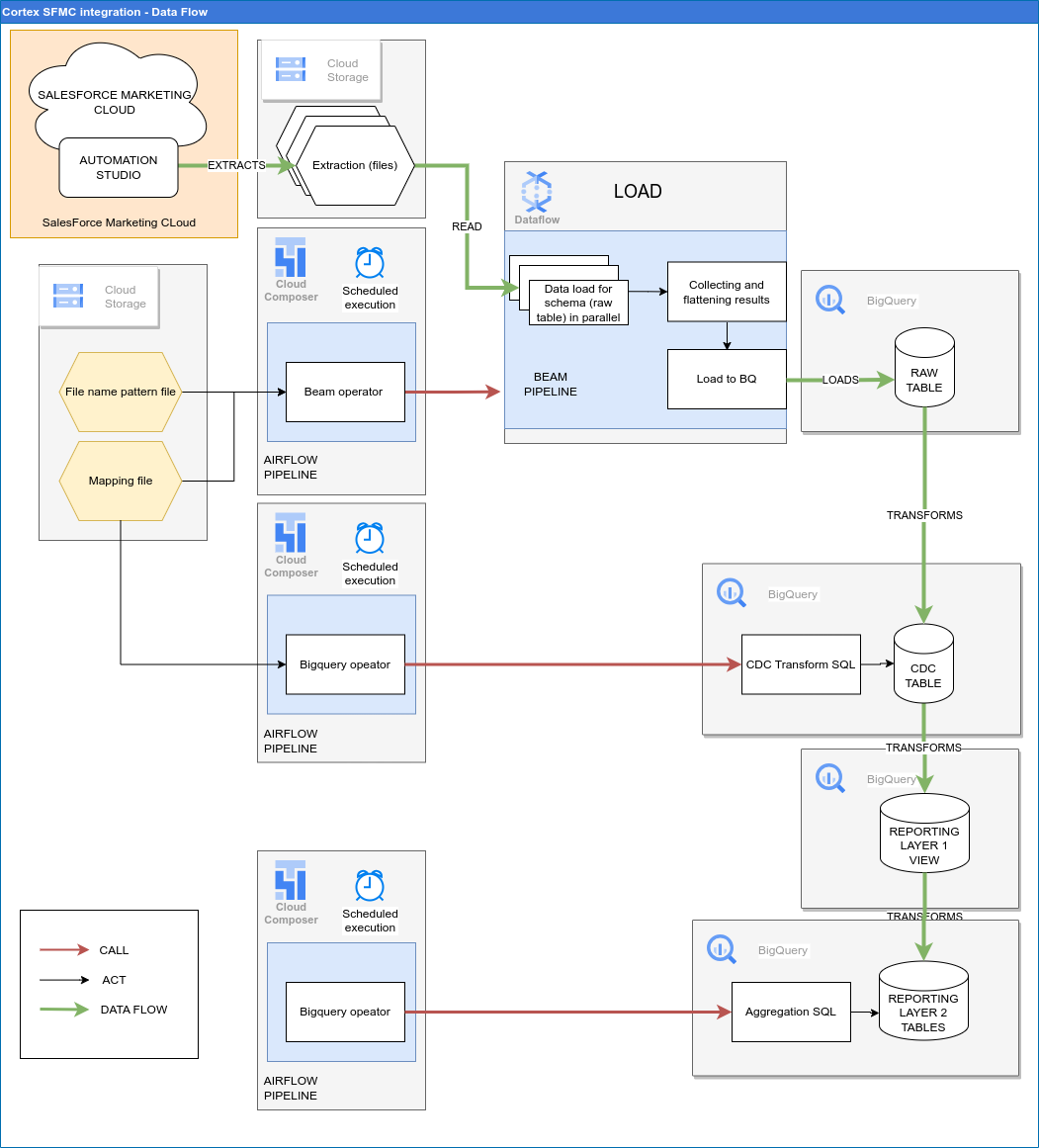
The following diagram describes how SFMC data is available through the marketing workload of Cortex Framework Data Foundation:
Configuration file
The config.json file configures the settings required to connect to data sources for transferring
data from various workloads. This file contains the following parameters for SFMC:
"marketing": {
"deploySFMC": true,
"SFMC": {
"deployCDC": true,
"fileTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFMC"
}
}
}
The following table describes the value for each marketing parameter:
| Parameter | Meaning | Default Value | Description |
marketing.deploySFMC
|
Deploy SFMC | true
|
Execute the deployment for SFMC data source. |
marketing.SFMC.deployCDC
|
Deploy CDC scripts for SFMC | true
|
Generate Salesforce Marketing Cloud (SFMC) CDC processing scripts to run as DAGs in Cloud Composer. |
marketing.SFMC.fileTransferBucket
|
Bucket with Data Extract files | - | Bucket where Salesforce Marketing Cloud (SFMC) Automation Studio Data Extract files are stored. |
marketing.SFMC.datasets.cdc
|
CDC dataset for SFMC | CDC dataset for Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.raw
|
Raw dataset for SFMC | Raw dataset for Salesforce Marketing Cloud (SFMC). | |
marketing.SFMC.datasets.reporting
|
Reporting dataset for SFMC | "REPORTING_SFMC"
|
Reporting dataset for Salesforce Marketing Cloud (SFMC). |
Data Model
This section describes the Salesforce Marketing Cloud (SFMC) Data Model using the Entity Relationship Diagram (ERD).
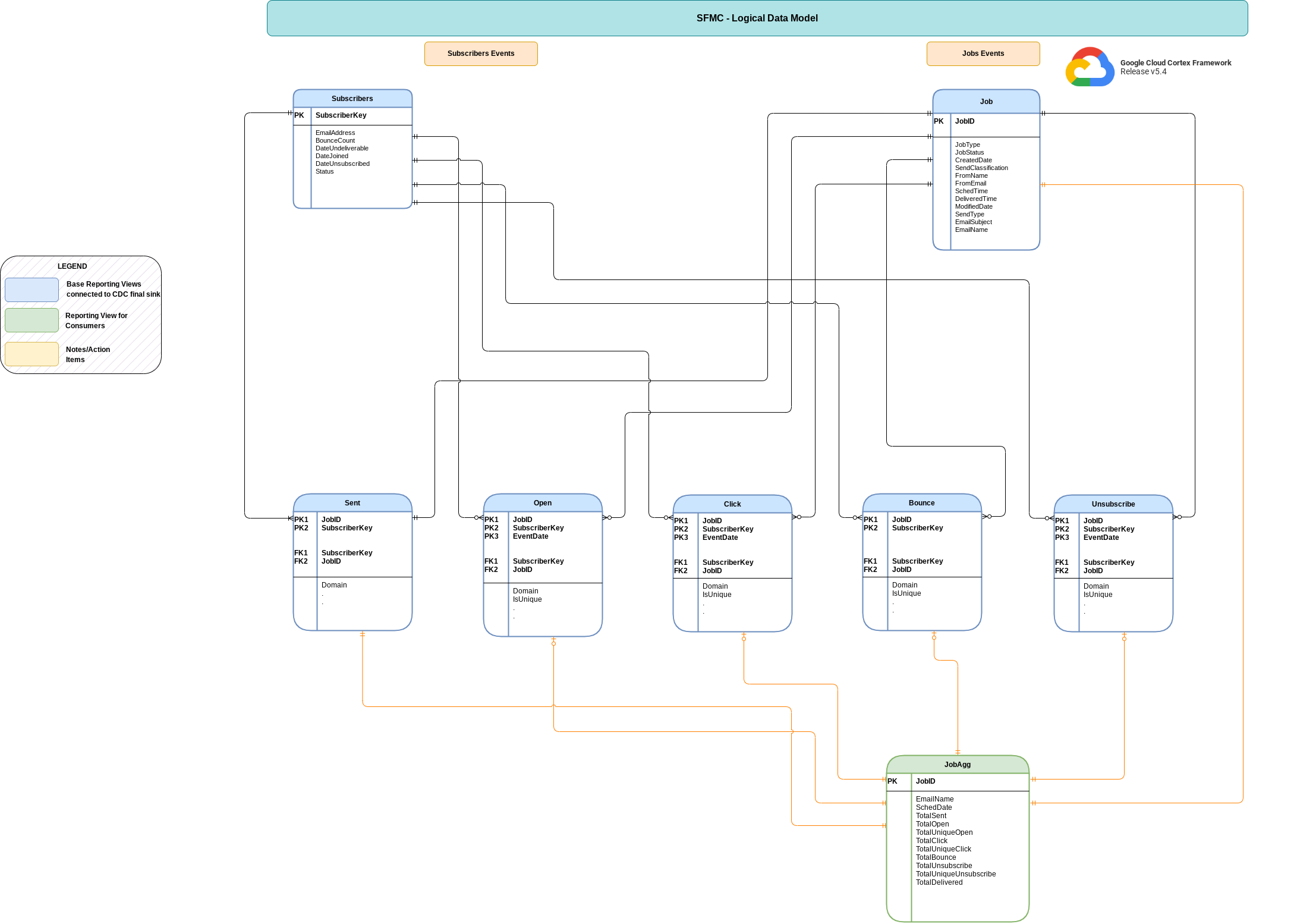
Base views
These are the blue objects in the ERD and are views on CDC tables with
no transforms other than some column name aliases. See scripts in
src/marketing/src/SFMC/src/reporting/ddls.
Reporting views
These are the green objects in the ERD and are reporting views that contain
aggregate metrics. See scripts in
src/marketing/src/SFMC/src/reporting/ddls.
Data Extraction using Automation Studio
SFMC Automation Studio allows consumers of SFMC to export their SFMC data to various storage systems. Cortex Framework Data Foundation looks for a set of files created with Automation Studio in a Cloud Storage bucket. You also need to use SFMC Email Studio in this process.
To set up the data extract and export processes, follow these steps:
- Set up a Cloud Storage bucket. This bucket stores files
exported from SFMC. Name the bucket
marketing.SFMC.fileTransferBucketconfig parameter. See the instructions in the Salesforce documentation. Create data extensions. For each entity you want to extract data for, create a Data Extension in Email Studio. This is needed to identify the data sources from the SFMC internal database.
- List all the fields that are defined in
src/SFMC/config/table_schemafor the entity. If you need to customize this to extract more or less fields, make sure the list of fields are aligned in these steps as well as in the table schema files. For example:
Entity: unsubscribe Fields: AccountID OYBAccountID JobID ListID BatchID SubscriberID SubscriberKey EventDate IsUnique Domain- List all the fields that are defined in
Create SQL query activities. For each entity, create a SQL Query Activity. This activity is connected to its corresponding data extension created earlier. See Salesforce documentation for this step:
- Define SQL query with all the relevant fields. The query needs to select all the fields relevant to the entity that is defined in the data extension in the previous step.
- Select the correct data extension as target.
- Select Overwrite as Data Action.
- See the following example query:
SELECT AccountID, OYBAccountID, JobID, ListID, BatchID, SubscriberID, SubscriberKey, EventDate, IsUnique, Domain FROM _UnsubscribeCreate data extract activities. See Salesforce documentation for creating a Data Extract Activity for each entity. This activity gets the data from the Salesforce Data Extension and extracts it to a csv file. For this step:
- Use the correct naming pattern. It should match the pattern defined in the
settings.
For example, for
Unsubscribeentity, the filename can be something likeunsubscribe_%%Year%%_%%Month%%_%%Day%% %%Hour%%.csv. - Set Extract Type to
Data Extension Extract. - Select Has column Headers and Text Qualified options.
- Use the correct naming pattern. It should match the pattern defined in the
settings.
For example, for
Create file conversion activities to convert format from UTF-16 to UTF-8. By default Salesforce exports CSV files in UTF-16. In this step you convert it to UTF-8 format. For each entity, create another Data Extract Activity, for file conversion. For this step:
- Use the same filename pattern that was used in the previous step of Data Extraction Activity.
- Set Extract Type to
File Convert - Select
UTF8form the drop-down atConvert To.
Create file transfer activities. Create a File Transfer Activity for each entity. These activities move the extracted csv files from the Salesforce Safehouse to Cloud Storage buckets. For this step:
- Use the same filename pattern used in prior steps.
- Select a Cloud Storage bucket that was setted up earlier in the process as destination.
Schedule the execution. After all the activities are complete, set up automated schedules to run them.
Data Freshness and Delay
As a general rule, data freshness for Cortex Framework data sources is limited by what upstream connection allows for, as well as the frequency of your DAG execution. Adjust your DAG execution frequency to align with upstream frequency, resource constraints, and your business needs.
With SFMC Automation Studio, the data freshness delay depends on the scheduling delay when data export is set up.
Cloud Composer connections permissions
Create the following connections in Cloud Composer. See more details in the Manage Airflow connections documentation.
| Connection Name | Purpose |
sfmc_raw_dataflow
|
For SFMC Extracted files > BigQueryRaw dataset. |
sfmc_cdc_bq
|
For Raw dataset > CDC dataset transfer. |
sfmc_reporting_bq
|
For CDC dataset > Reporting dataset transfer. |
Cloud Composer service account permissions
The service account used in Cloud Composer (as configured in the
sfmc_raw_dataflow connection) needs Dataflow related permissions.
See instructions in Dataflow documentation
Ingestion settings
Control Source to Raw and Raw to CDC data pipelines through the settings
in the file src/SFMC/config/ingestion_settings.yaml .
This section describes the parameters of each data pipeline.
Source to raw tables
This section has entries that control how files extracted from Automation Studio are used. Each entry corresponds with one SFMC entity. Based on this config, Cortex Framework creates Airflow DAGs that run Dataflow pipelines to load data from exported files into BigQuery tables in raw dataset.
Directory src/SFMC/config/table_schema contains a schema file for each entity
that is extracted from SFMC. Each file explains how to read the csv files
extracted from Automaton Studio in order to successfully load them into
BigQueryraw dataset.
Each schema file contains three columns:
SourceField: Field name of the csv file.TargetField: Column name in the raw table for this entity.DataType: Data type of each raw table field.
The following parameters control the settings for Source to Raw
for each entry:
| Parameter | Description |
base_table
|
Raw table name in which an SFMC entity extracted data is loaded. |
load_frequency
|
How frequently a DAG for this entity runs to load data from extracted files. For more information about possible values, see Airflow documentation. |
file_pattern
|
Pattern for file for this table that's exported from Automation Studio into Cloud Storage bucket. Change this only if you chose a different name than the ones suggested for extracted files. |
partition_details
|
How the raw table is partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want the raw table to be clustered for performance considerations. For more information, see Cluster Settings. |
Raw to CDC tables
This section describes which entries control how data is moved from raw tables to CDC tables. Each entry corresponds with a raw table.
The following parameters control the settings for Raw to CDC for each entry:
| Parameter | Description |
base_table
|
Table in CDC dataset where the raw data after CDC transformation is stored. |
load_frequency
|
How frequently a DAG for this entity runs to populate the CDC table. For more information about possible values, see Airflow documentation. |
raw_table
|
Source table from raw dataset. |
row_identifiers
|
Columns (separated by comma) that form a unique record for this table. |
partition_details
|
How the CDC table is partitioned for performance considerations. For more information, see Table Partition. |
cluster_details
|
Optional: If you want this table to be clustered for performance considerations. For more information, see Cluster Settings. |
Reporting settings
You can configure and control how Cortex Framework generates data for
the SFMC final reporting layer using the reporting settings file
(src/SFMC/config/reporting_settings.yaml).
This file controls how reporting layer BigQuery objects
(tables, views,functions or stored procedures) are generated.
For more information, see Customizing reporting settings file.
What's next?
- For more information about other data sources and workloads, see Data sources and workloads.
- For more information about the steps for deployment in production environments, see Cortex Framework Data Foundation deployment prerequisites.