Questa pagina spiega in che modo l'architettura di Memorystore for Valkey supporta e fornisce l'alta affidabilità (HA). Questa pagina spiega anche le configurazioni consigliate che contribuiscono a migliorare le prestazioni e la stabilità dell'istanza.
Alta disponibilità
Memorystore for Valkey è basato su un'architettura a disponibilità elevata in cui i client accedono direttamente ai nodi Memorystore for Valkey gestiti. I client lo fanno connettendosi a singoli endpoint, come descritto in Connettersi a un'istanza Memorystore for Valkey.
Il collegamento diretto agli shard offre i seguenti vantaggi:
La connessione diretta evita gli hop intermedi, il che riduce al minimo il tempo di round trip (latenza del client) tra il client e il nodo Valkey.
Con la modalità cluster abilitata, la connessione diretta evita qualsiasi singolo punto di errore perché ogni shard è progettato per non funzionare in modo indipendente. Ad esempio, se il traffico di più client sovraccarica uno slot (blocco di keyspace), l'errore dello shard limita l'impatto allo shard responsabile della gestione dello slot.
Configurazioni consigliate
Ti consigliamo di creare istanze multizona ad alta disponibilità anziché istanze monozona a causa della maggiore affidabilità che offrono. Tuttavia, se scegli di eseguire il provisioning di un'istanza senza repliche, ti consigliamo di scegliere un'istanza a zona singola. Per saperne di più, vedi Scegliere un'istanza a zona singola se l'istanza non utilizza repliche.
Per abilitare l'alta disponibilità per l'istanza, devi eseguire il provisioning di almeno un nodo di replica per ogni shard. Puoi farlo durante la creazione dell'istanza oppure puoi scalare il conteggio delle repliche ad almeno una replica per shard. Le repliche forniscono il failover automatico durante la manutenzione pianificata e l'errore imprevisto dello shard.
Devi configurare il client in base alle indicazioni riportate nelle best practice per i client. L'utilizzo delle best practice consigliate consente al tuo cliente di gestire automaticamente e senza tempi di inattività i seguenti elementi per la tua istanza:
Il ruolo (failover automatici)
L'endpoint (sostituzione del nodo)
Modifiche all'assegnazione degli slot correlate alla modalità cluster abilitata (scalabilità orizzontale e verticale dei consumatori)
Repliche
Un'istanza Memorystore for Valkey ad alta disponibilità è una risorsa di regione. Memorystore for Valkey distribuisce le VM primarie e di replica degli shard in più zone per proteggere da un'interruzione zonale. Memorystore for Valkey supporta istanze con 0-5 repliche per nodo.
Puoi utilizzare le repliche per aumentare la velocità effettiva di lettura a scapito della potenziale obsolescenza dei dati.
- Modalità cluster abilitata:utilizza il comando
READONLYper stabilire una connessione che consenta al client di leggere dalle repliche. - Modalità cluster disattivata:connettiti all'endpoint di lettura per connetterti a una delle repliche disponibili.
Forme di istanze con modalità cluster abilitata
I seguenti diagrammi illustrano le forme per le istanze abilitate in modalità cluster:
Forma dell'istanza con tre shard e zero repliche per nodo
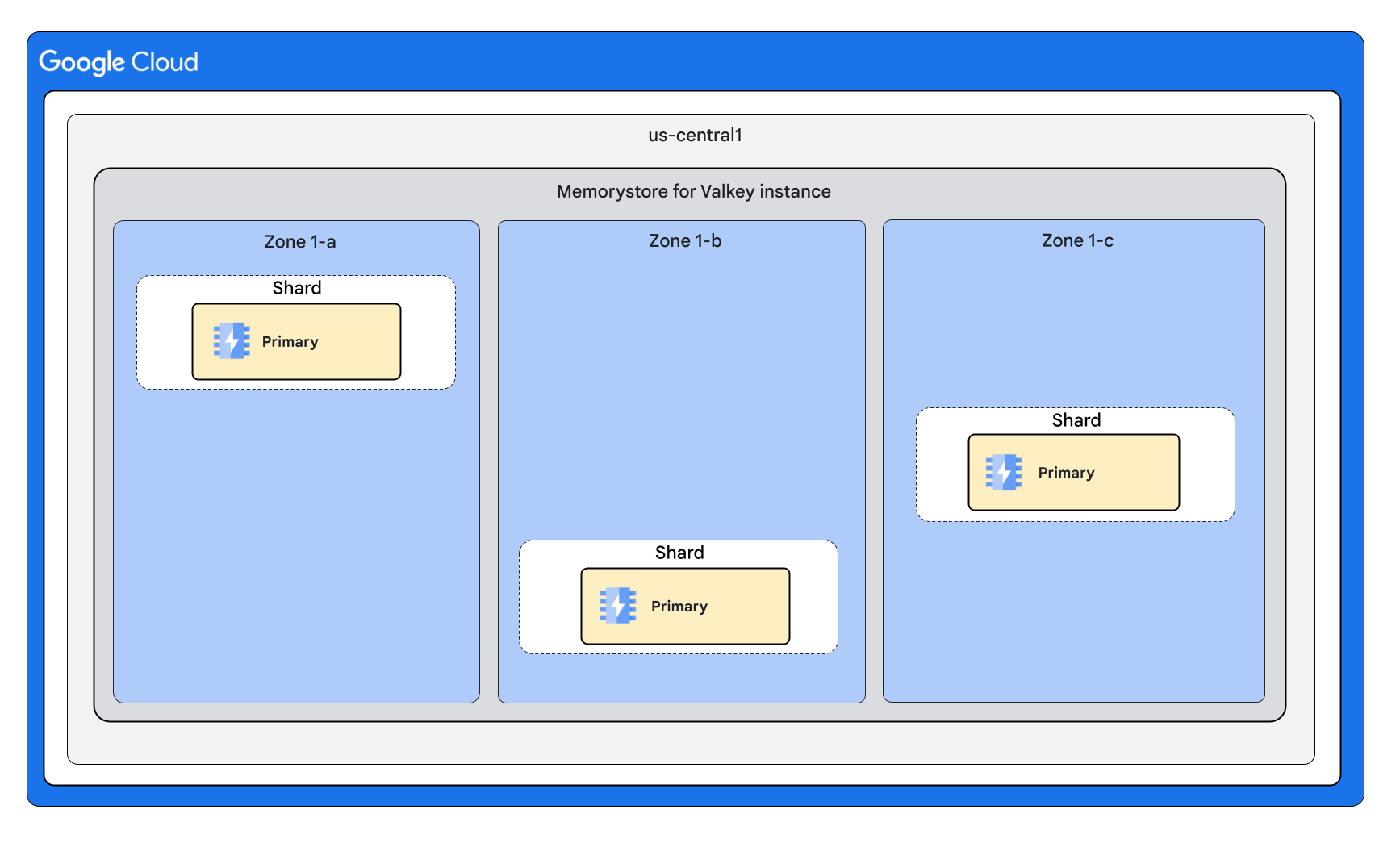
Forma dell'istanza con tre shard e una replica per nodo
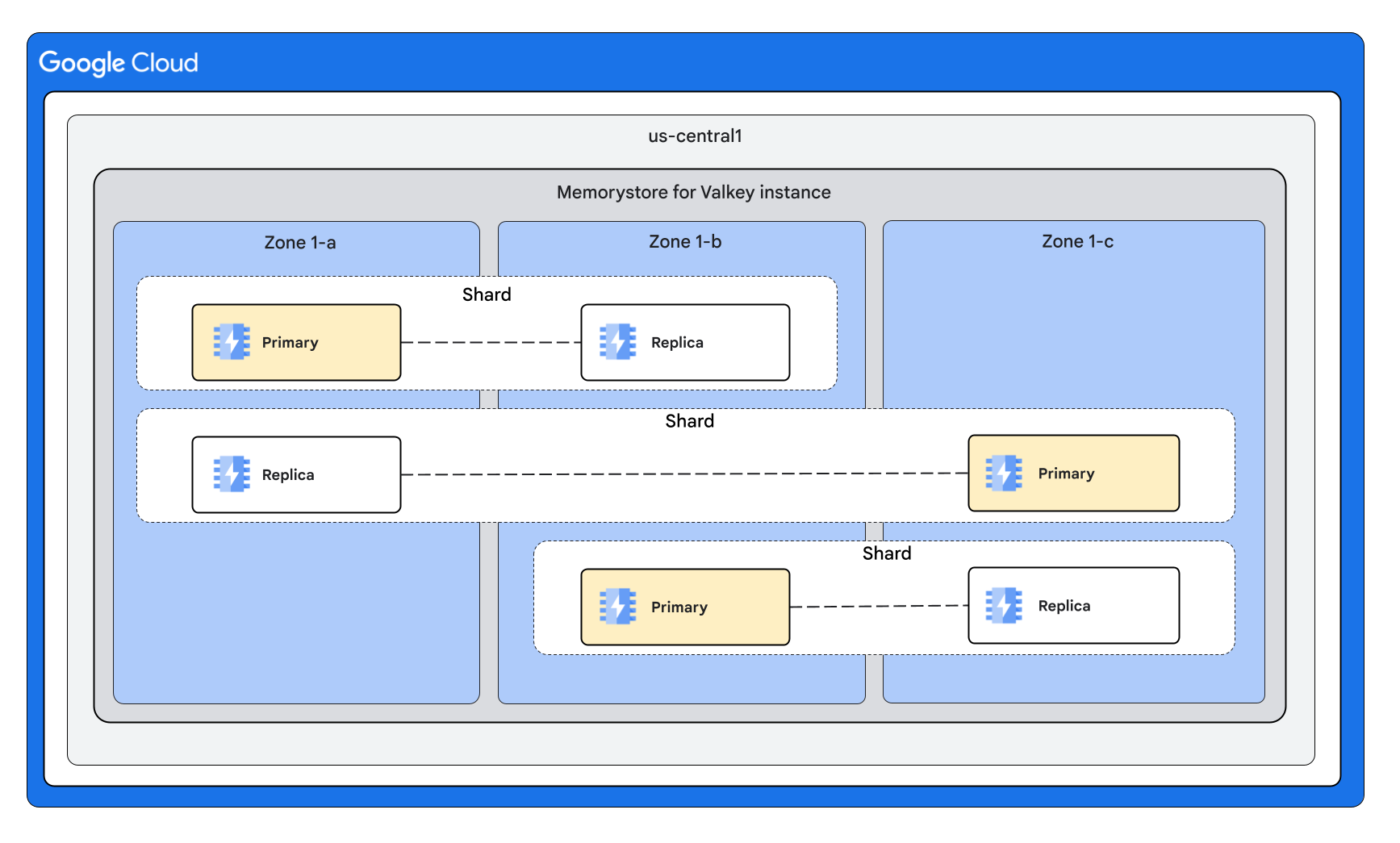
Forma dell'istanza con tre shard e più repliche per nodo
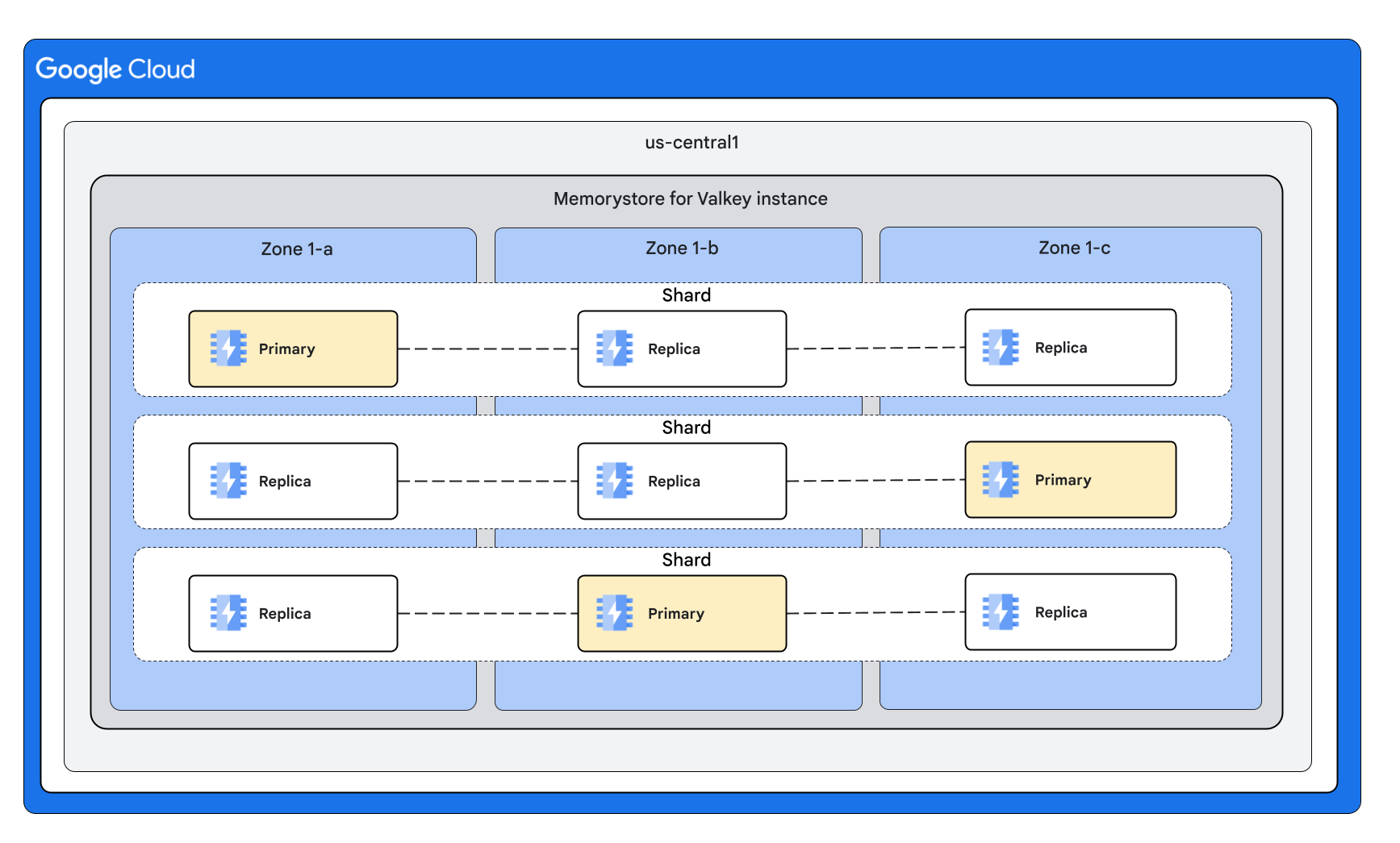
Forme dell'istanza con modalità cluster disabilitata
Il seguente diagramma illustra una forma per le istanze con modalità cluster disattivata:
Forma dell'istanza con più repliche
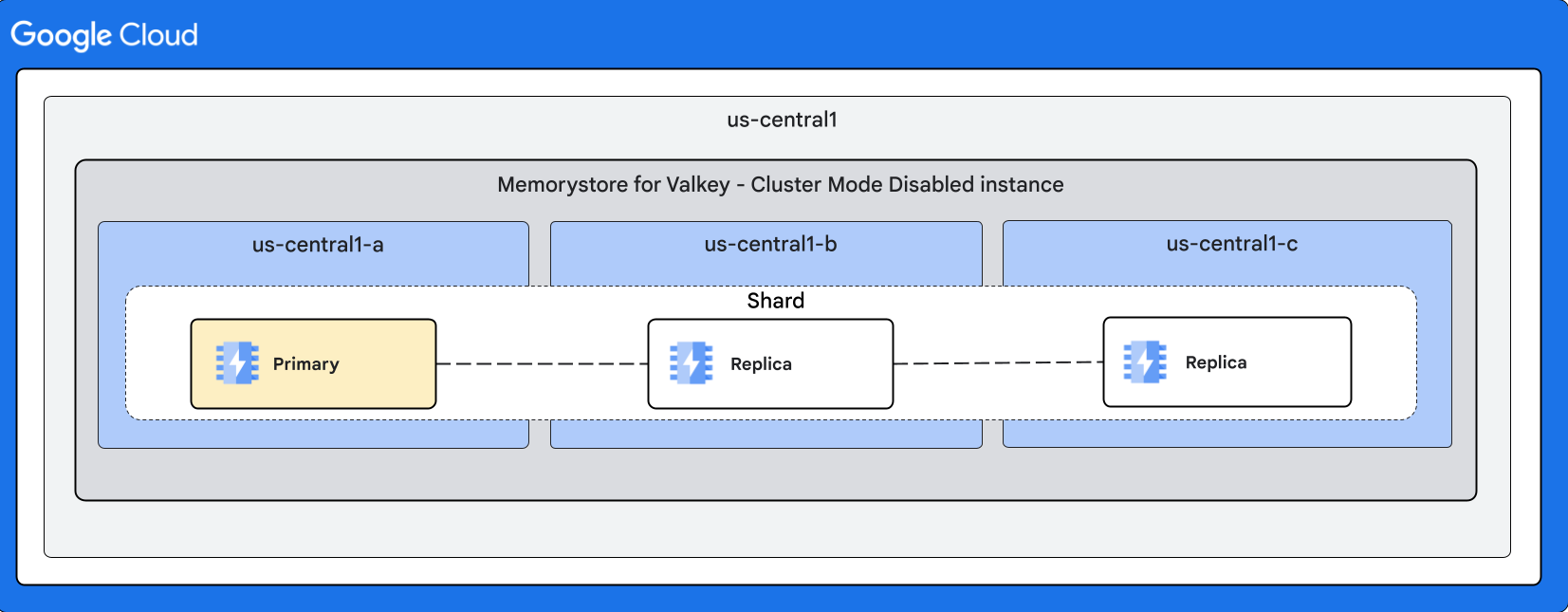
Failover automatico
I failover automatici all'interno di uno shard possono verificarsi a causa di manutenzione o di un errore imprevisto del nodo primario. Durante un failover, una replica viene promossa a principale. Puoi configurare le repliche in modo esplicito. Il servizio può anche eseguire il provisioning temporaneo di repliche aggiuntive durante la manutenzione interna per evitare tempi di inattività.
I failover automatici impediscono la perdita di dati durante gli aggiornamenti di manutenzione. Per informazioni dettagliate sul comportamento del failover automatico durante la manutenzione, vedi Comportamento del failover automatico durante la manutenzione.
Durata del failover e della riparazione dei nodi
I failover automatici possono richiedere decine di secondi per eventi non pianificati, come l'arresto anomalo del processo del nodo primario o un guasto hardware. Durante questo periodo, il sistema rileva l'errore e seleziona una replica come nuovo database primario.
La riparazione del nodo può richiedere alcuni minuti prima che il servizio sostituisca il nodo non funzionante. Questo vale per tutti i nodi primari e di replica. Per le istanze a disponibilità elevata (senza repliche di cui è stato eseguito il provisioning), anche la riparazione di un nodo primario non riuscito richiede tempo, nell'ordine di minuti.
Comportamento del client durante un failover non pianificato
È probabile che le connessioni client vengano reimpostate a seconda della natura dell'errore. Dopo il recupero automatico, i tentativi di connessione devono essere eseguiti con backoff esponenziale per evitare di sovraccaricare i nodi primari e di replica.
I client che utilizzano le repliche per la velocità effettiva di lettura devono prepararsi a un peggioramento temporaneo della capacità fino a quando il nodo non riuscito non viene sostituito automaticamente.
Scritture perse
Durante un failover derivante da un errore imprevisto, le scritture confermate potrebbero essere perse a causa della natura asincrona del protocollo di replica di Valkey.
Le applicazioni client possono sfruttare il comando WAIT di Valkey per migliorare la sicurezza dei dati nel mondo reale.
Impatto dello spazio delle chiavi di un'interruzione di una singola zona
Questa sezione descrive l'impatto di un'interruzione di una singola zona su un'istanza Memorystore for Valkey.
Istanze multizona
Istanze HA:se una zona ha un'interruzione, l'intero spazio delle chiavi è disponibile per le letture e le scritture, ma poiché alcune repliche di lettura non sono disponibili, la capacità di lettura è ridotta. Ti consigliamo vivamente di eseguire il provisioning eccessivo della capacità del cluster in modo che l'istanza abbia una capacità di lettura sufficiente nel raro caso di un'interruzione di una singola zona. Una volta terminato l'interruzione, le repliche nella zona interessata vengono ripristinate e la capacità di lettura del cluster torna al valore configurato. Per saperne di più, consulta Modelli per app scalabili e affidabili.
Istanze non HA (senza repliche): se una zona ha un'interruzione, la parte dello spazio delle chiavi di cui è stato eseguito il provisioning nella zona interessata viene svuotata e non è disponibile per scritture o letture per la durata dell'interruzione. Una volta terminata l'interruzione, i nodi primari nella zona interessata vengono ripristinati e la capacità del cluster torna al valore configurato.
Istanze a zona singola
- Istanze HA e non HA:se la zona in cui viene eseguito il provisioning dell'istanza ha un'interruzione, il cluster non è disponibile e i dati vengono eliminati. Se si verifica un'interruzione in una zona diversa, il cluster continua a gestire le richieste di lettura e scrittura.
Best practice
Questa sezione descrive le best practice per l'alta disponibilità e le repliche.
Aggiungere una replica
L'aggiunta di una replica richiede uno snapshot RDB. Gli snapshot RDB utilizzano un fork del processo e un meccanismo di "copy-on-write" per creare uno snapshot dei dati del nodo. A seconda del pattern di scrittura nei nodi, la memoria utilizzata dei nodi aumenta man mano che le pagine toccate dalle scritture vengono copiate. L'impronta di memoria può essere fino al doppio delle dimensioni dei dati nel nodo.
Per garantire che i nodi abbiano memoria sufficiente per completare lo snapshot, mantieni o
imposta maxmemory all'80% della
capacità del nodo, in modo che il 20% sia riservato all'overhead. Questo overhead di memoria, oltre agli snapshot di monitoraggio, ti aiuta a gestire il carico di lavoro per avere snapshot riusciti. Inoltre, quando aggiungi repliche, riduci il traffico di scrittura il più possibile. Per saperne di più, consulta Monitorare l'utilizzo della memoria per un'istanza.