Tingkat Standar Memorystore for Redis memberikan kemampuan untuk menskalakan kueri baca aplikasi Anda menggunakan replika baca. Halaman ini mengasumsikan Anda sudah memahami berbagai kemampuan paket Redis Memorystore.
Replika baca memungkinkan Anda menskalakan beban kerja baca dengan membuat kueri replika. Endpoint baca disediakan untuk memudahkan aplikasi mendistribusikan kueri di seluruh replika. Untuk mengetahui informasi selengkapnya, lihat Menskalakan pembacaan dengan endpoint baca.
Untuk mengetahui petunjuk tentang cara mengelola instance Redis dengan replika baca, lihat Mengelola replika baca.
Kasus penggunaan untuk replika baca
Penyimpanan sesi, papan peringkat, mesin pemberi rekomendasi, dan kasus penggunaan lainnya memerlukan instance dengan ketersediaan tinggi. Untuk kasus penggunaan ini, ada lebih banyak operasi baca daripada tulis, dan kasus penggunaan ini umumnya dapat mentoleransi beberapa operasi baca yang tidak aktual. Dalam kasus seperti ini, sebaiknya manfaatkan replika baca untuk meningkatkan ketersediaan dan skalabilitas instance.
Perilaku replika baca
- Replika baca tidak diaktifkan di instance Tingkat Standar secara default.
- Setelah replika baca diaktifkan pada instance, replika baca tidak dapat lagi dinonaktifkan untuk instance tersebut.
- Instance Tingkat Standar dapat memiliki 1 hingga 5 replika baca.
- Endpoint baca menyediakan satu endpoint untuk mendistribusikan kueri di seluruh node replika.
- Replika baca dikelola menggunakan replikasi asinkron Redis.
Peringatan dan batasan
- Replika baca hanya didukung untuk ukuran instance dengan node >= 5 GB.
- Replika baca hanya dapat diaktifkan pada instance yang menggunakan Redis versi 5.0 atau yang lebih tinggi.
- Jika Anda menetapkan zona dan zona alternatif untuk penyediaan node, Memorystore akan menggunakan zona tersebut untuk node pertama dan kedua dalam instance. Setelah itu, Memorystore akan memilih zona untuk semua node yang tersisa yang disediakan untuk instance.
- Anda harus menyediakan instance dengan rentang alamat IP CIDR sebesar
/28atau lebih besar. Ukuran rentang yang lebih besar seperti/27dan/26valid. Rentang yang lebih kecil seperti/29tidak didukung untuk fitur ini.
Arsitektur
Saat mengaktifkan replika baca, Anda menentukan jumlah replika yang diinginkan dalam instance. Memorystore secara otomatis mendistribusikan node utama dan replika baca di seluruh zona yang tersedia dalam satu region.
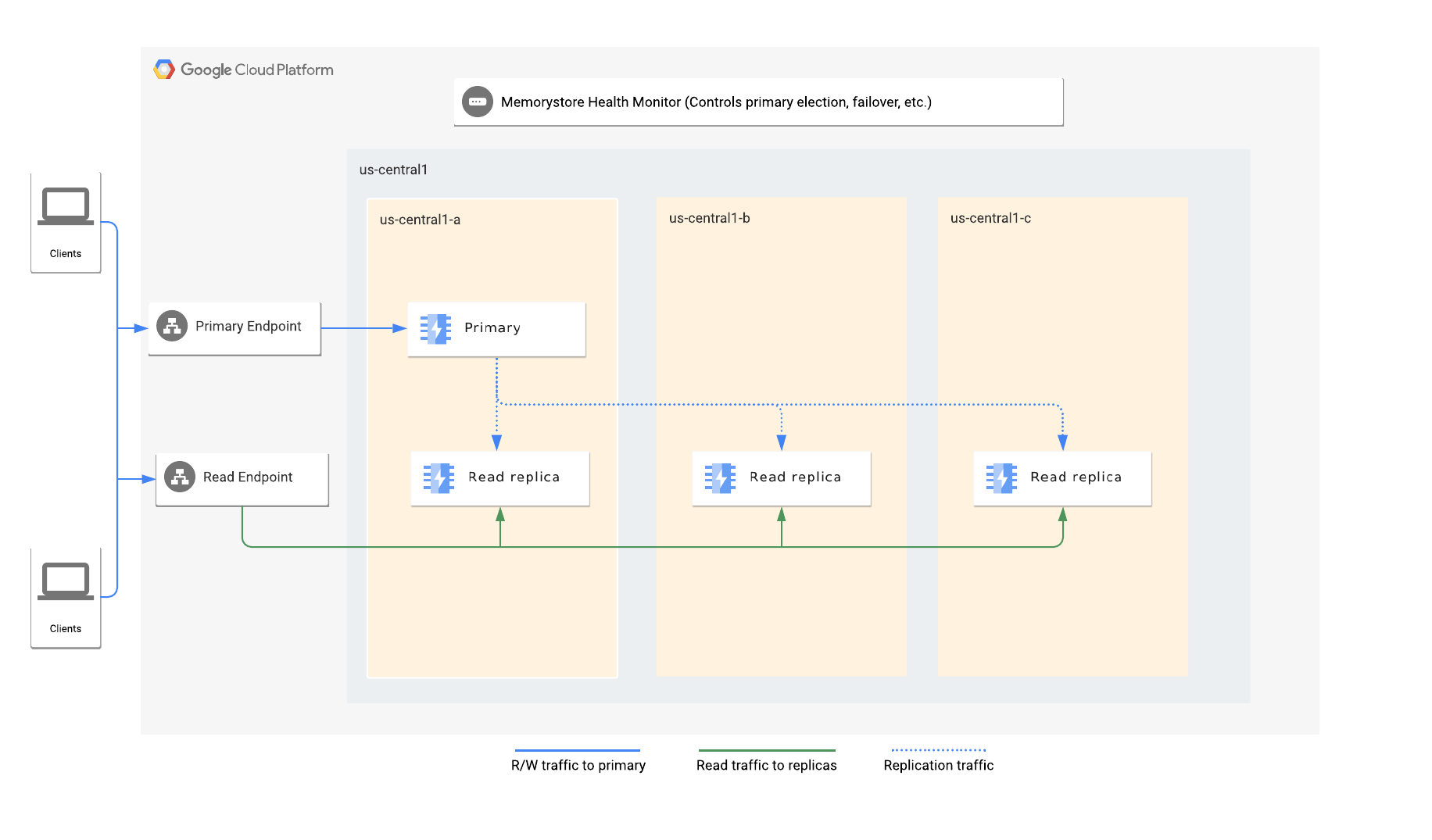
Setiap instance memiliki endpoint utama dan endpoint baca. Endpoint utama selalu mengarahkan traffic ke node utama, sementara endpoint baca secara otomatis menyeimbangkan beban kueri baca di seluruh replika yang tersedia.
Layanan pemantauan kondisi Memorystore for Redis memantau instance dan bertanggung jawab untuk mendeteksi kegagalan node utama, serta memilih replika sebagai node utama baru dan memulai failover otomatis ke node utama baru.
Failover untuk instance dengan replika baca
Jika instance utama gagal, layanan pemantauan kondisi Memorystore akan memulai failover dan instance utama baru akan tersedia untuk operasi baca dan tulis. Pengalihan biasanya selesai dalam waktu kurang dari 30 detik.
Saat terjadi failover, endpoint utama akan otomatis mengalihkan traffic ke endpoint utama yang baru. Namun, semua koneksi klien ke endpoint utama akan terputus selama failover. Aplikasi dengan logika percobaan ulang koneksi akan otomatis terhubung kembali setelah instance utama baru online. Beberapa koneksi klien ke endpoint baca juga mengalami pemutusan koneksi dari replika baca yang dipromosikan menjadi primer selama failover. Koneksi ke replika yang tersisa akan terus ditayangkan selama failover. Saat percobaan ulang, koneksi dialihkan ke replika baru.
Saat terjadi failover, karena sifat replikasi yang asinkron, replika dapat memiliki jeda replikasi yang berbeda. Namun, proses failover berupaya sebaik mungkin untuk melakukan failover ke replika dengan jeda paling kecil. Hal ini membantu meminimalkan jumlah kehilangan data dan penurunan throughput baca selama failover. Primer yang baru dipromosikan dapat berada di zona yang sama atau zona yang berbeda dengan primer sebelumnya. Replika dipilih untuk menjadi instance utama baru jika berada di zona yang sama dengan instance utama sebelumnya dan memiliki latensi paling rendah. Jika tidak, replika dari zona lain dapat menjadi yang utama.
Karena replikasi bersifat asinkron, selalu ada kemungkinan membaca data yang sudah tidak berlaku selama failover. Selain itu, saat primary baru dipromosikan, beberapa penulisan ke instance mungkin hilang. Aplikasi harus dapat menangani perilaku ini.
Redis berusaha semaksimal mungkin untuk menghindari replika lain yang memerlukan sinkronisasi penuh selama failover, tetapi hal ini dapat terjadi dalam skenario yang jarang terjadi. Sinkronisasi penuh dapat memerlukan waktu beberapa menit hingga satu jam, bergantung pada kecepatan penulisan dan ukuran set data yang direplikasi. Selama waktu ini, replika yang sedang melakukan sinkronisasi penuh tidak tersedia untuk pembacaan. Setelah sinkronisasi selesai, replika dapat diakses untuk baca.
Mode kegagalan untuk replika baca
Instance dengan replika baca dapat mengalami berbagai kegagalan dan kondisi tidak sehat yang memengaruhi aplikasi. Perilaku ini bervariasi bergantung pada apakah instance memiliki satu replika, atau dua replika atau lebih. Bagian ini menguraikan beberapa mode kegagalan umum dan menguraikan perilaku instance selama kondisi ini.
Replika tidak tersedia
Jika replika gagal karena alasan apa pun, replika akan ditandai sebagai tidak tersedia dan semua koneksi ke replika akan dihentikan setelah waktu tunggu tertentu. Setelah replika dipulihkan, koneksi baru akan dirutekan ke replika yang dipulihkan. Waktu untuk memulihkan replika bervariasi, bergantung pada mode kegagalan.
Jika terjadi kehabisan stok Compute Engine atau kegagalan zona, replika tidak akan pulih hingga kondisi tersebut teratasi.
Kegagalan zona
Jika zona tempat primer berada gagal, primer akan otomatis melakukan failover ke replika di zona lain. Jika instance hanya memiliki satu replika, endpoint baca tidak akan tersedia selama pemadaman layanan zona. Jika instance memiliki lebih dari satu replika, replika di luar zona yang terpengaruh tersedia untuk operasi baca
Jika zona tempat satu atau beberapa replika berada gagal, replika tersebut tidak tersedia selama durasi kegagalan zona. Jika terjadi kegagalan dua zona dan ada dua atau lebih replika, replika dengan jeda paling kecil di zona yang tersisa akan dipromosikan menjadi replika utama. Replika yang tersisa di zona yang tidak terpengaruh tersedia untuk operasi baca.
Partisi jaringan
Partisi jaringan adalah skenario saat node tetap berjalan, tetapi tidak dapat menjangkau semua klien, zona, atau node peer. Memorystore menggunakan sistem berbasis kuorum untuk mencegah node yang terisolasi melayani penulisan. Jika terjadi partisi jaringan, setiap replika utama dalam partisi minoritas akan melakukan penurunan sendiri. Partisi mayoritas (jika ada) memilih primer baru jika belum memilikinya. Replika yang terisolasi akan terus menayangkan bacaan. Namun, data tersebut dapat menjadi tidak valid jika tidak dapat disinkronkan dari server utama.
Untuk menentukan apakah link rusak, pantau metrik master_link_down_since_seconds
dan offset_diff untuk mengidentifikasi node yang terisolasi.
Kehabisan stok
Terkadang resource Compute Engine yang diperlukan oleh Memorystore tidak tersedia di zona, yang menyebabkan kehabisan stok. Jika terjadi kekurangan stok di region tempat Anda mencoba menyediakan instance, operasi untuk membuat instance akan gagal.
Sinkronisasi penuh
Jika replika terlalu tertinggal dari replika utama, replika akan memicu sinkronisasi penuh yang menyalin seluruh snapshot dari replika utama ke replika. Operasi ini dapat memerlukan waktu mulai dari beberapa menit hingga satu jam dalam kasus terburuk. Sinkronisasi penuh tidak menyebabkan kegagalan instance, tetapi selama waktu ini replika yang sedang menjalani sinkronisasi penuh tidak tersedia untuk pembacaan dan instance utama mengalami penggunaan CPU dan memori yang lebih tinggi.
Endpoint utama menampilkan READONLY
Operasi tulis Anda ke endpoint utama instance Memorystore for Redis dengan replika baca mungkin menerima error -READONLY You can't write against a read
only replica. secara tidak terduga. Sebaiknya tutup dan buat ulang koneksi ke instance. Dalam sebagian besar kasus, memulai ulang aplikasi klien dapat mengurangi masalah. Jika opsi ini tidak memungkinkan atau perilaku tersebut terus berlanjut, hubungi Google Cloud tim Dukungan.
Menskalakan pembacaan dengan endpoint baca
Replika baca memungkinkan aplikasi menskalakan operasi baca dengan membaca dari replika. Aplikasi dapat terhubung ke replika baca melalui endpoint baca.
Membaca endpoint
Endpoint baca adalah alamat IP yang terhubung ke aplikasi Anda. Load balancer ini secara merata menyeimbangkan koneksi di seluruh replika dalam instance. Koneksi ke replika baca dapat mengirim kueri baca, tetapi tidak dapat mengirim kueri tulis. Setiap instance Tingkat Standar yang mengaktifkan replika baca memiliki endpoint baca. Untuk mengetahui petunjuk tentang cara melihat endpoint baca instance, lihat Melihat informasi replika baca untuk instance Anda.
Perilaku endpoint baca
- Endpoint baca otomatis mendistribusikan koneksi ke semua replika yang tersedia. Koneksi tidak diarahkan ke primer.
- Replika dianggap tersedia selama dapat melayani traffic klien. Ini tidak termasuk saat replika sedang melakukan sinkronisasi penuh dengan replika utamanya.
- Replika dengan jeda replikasi yang tinggi terus melayani traffic. Aplikasi dengan volume penulisan yang tinggi dapat membaca data yang tidak terbaru dari replika yang melayani penulisan tinggi.
- Jika node replika menjadi node utama, koneksi ke node tersebut akan dihentikan dan koneksi baru akan dialihkan ke node replika baru.
- Setiap koneksi ke endpoint baca menargetkan replika yang sama selama masa aktif koneksi. Koneksi yang berbeda dari host klien yang sama tidak dijamin menargetkan node replika yang sama.
Konsistensi baca
Replika baca dikelola menggunakan replikasi asinkron OSS Redis native. Karena sifat replikasi asinkron, ada kemungkinan replika tertinggal dari yang utama. Aplikasi dengan operasi tulis yang konstan yang juga membaca dari replika harus dapat mentoleransi pembacaan yang tidak konsisten.
Jika aplikasi memerlukan konsistensi "baca tulisan Anda", sebaiknya gunakan endpoint utama untuk penulisan dan pembacaan. Menggunakan endpoint utama memastikan bahwa pembacaan selalu diarahkan ke yang utama. Bahkan dalam kasus ini, pembacaan yang sudah tidak berlaku dapat terjadi setelah failover.
Menetapkan TTL pada kunci di primer memastikan kunci yang sudah habis masa berlakunya tidak dibaca dari primer atau replika. Hal ini karena Redis memastikan kunci yang sudah habis masa berlakunya tidak dapat dibaca dari replika.
Perilaku mengaktifkan replika baca pada instance yang ada
Mengaktifkan replika baca adalah operasi eksklusif, yang berarti Anda tidak dapat melakukan modifikasi instance operasi update lainnya sebagai bagian dari operasi yang sama yang mengaktifkan replika baca.
Mengaktifkan replika baca pada instance Redis yang ada mengharuskan Anda mengalokasikan rentang alamat IP sekunder yang valid untuk penempatan node. Rentang ini harus berupa rentang Classless Inter-Domain Routing (CIDR) berukuran
/28, terlepas dari ukuran rentang alamat IP yang ada yang dialokasikan ke Memorystore for Redis.- Anda harus memberikan rentang IP tambahan saat mengaktifkan replika baca untuk instance Redis. Anda dapat memilih rentang tertentu, atau membiarkan Memorystore memilihnya secara otomatis untuk Anda.
Alamat IP baca/tulis untuk instance Anda tidak berubah saat mengaktifkan replika baca. Alamat IP endpoint baca berada dalam rentang asli yang dialokasikan untuk instance Memorystore Anda, bukan rentang tambahan yang Anda berikan saat mengaktifkan replika baca.
Untuk menemukan endpoint baca baru, lihat informasi replika baca untuk instance Anda setelah operasi untuk mengaktifkan replika baca selesai.
Menskalakan instance
Anda dapat menskalakan jumlah replika baca untuk instance, dan Anda juga dapat mengubah ukuran node:
Untuk mengetahui petunjuk tentang cara menambahkan dan menghapus node, lihat Menambahkan atau menghapus node replika dari instance Redis.
Untuk mengetahui petunjuk tentang cara menskalakan ukuran node Redis, lihat Menskalakan ukuran node Redis.
Sebaiknya Anda menskalakan instance selama periode traffic baca dan tulis rendah untuk meminimalkan dampak pada aplikasi.
Menambahkan replika baru akan menghasilkan beban tambahan pada primer saat replika melakukan sinkronisasi penuh. Saat menambahkan node, koneksi yang ada tidak terpengaruh atau ditransfer. Setelah replika baru tersedia, replika tersebut mulai menerima koneksi dari endpoint dan melayani pembacaan. Menghapus replika akan menutup semua koneksi aktif yang dirutekan ke replika tersebut. Aplikasi klien harus dikonfigurasi untuk otomatis terhubung kembali ke endpoint baca untuk membangun kembali koneksi ke replika yang tersisa.
Praktik terbaik
Pengelolaan memori
Redis tidak mengizinkan penulisan klien melebihi batas maxmemory
instance. Namun, overhead seperti fragmentasi, buffer replikasi, dan perintah mahal seperti EVAL dapat meningkatkan pemanfaatan memori melampaui batas ini. Dalam kasus ini, Memorystore gagal menulis hingga tekanan memori berkurang. Lihat Praktik terbaik pengelolaan memori
untuk mengetahui detail selengkapnya.
Jika Memorystore sedang menjalani operasi BGSAVE karena ekspor atau replikasi sinkronisasi penuh dan kondisi OOM terjadi, proses turunan akan dihentikan. Dalam hal ini, operasi BGSAVE gagal dan server node Redis tetap tersedia.
Untuk menjamin replikasi dan pembuatan snapshot dalam segala situasi, sebaiknya pertahankan pemakaian memori di bawah 50% selama operasi penting seperti ekspor, penskalaan, dll. Anda dapat memicu ekspor atau pengalihan tugas secara manual untuk melihat dampak performa dari operasi ini.
Pengelolaan CPU
Memorystore menyediakan metrik tentang penggunaan CPU dan jumlah koneksi untuk setiap node. Sebaiknya Anda mengalokasikan overhead yang cukup sehingga hilangnya satu zona ketersediaan dapat ditoleransi. Target ideal dapat bervariasi berdasarkan jumlah replika dan pola penggunaan, tetapi titik awal yang baik adalah menjaga penggunaan CPU replika di bawah 50%.
Node individual dapat mengalami penggunaan tinggi jika pola penggunaan klien tidak seimbang, atau jika operasi failover menghasilkan distribusi koneksi yang tidak seimbang. Dalam hal ini, sebaiknya tutup koneksi Anda secara berkala agar Memorystore dapat menyeimbangkan kembali koneksi secara otomatis. Memorystore tidak menyeimbangkan kembali koneksi terbuka.
Pengelolaan saldo koneksi
Setiap kali koneksi node ditutup, klien harus terhubung kembali, biasanya dengan mengaktifkan koneksi ulang otomatis di library klien pilihan Anda. Saat node diperkenalkan kembali, koneksi yang ada tidak dialihkan, tetapi koneksi baru dialihkan ke node baru. Klien dapat menghentikan koneksi secara berkala untuk memastikan koneksi tersebut seimbang di seluruh node yang tersedia.
Pengelolaan jeda replikasi
Replika dapat tertinggal, terutama saat rasio penulisan sangat tinggi. Dalam skenario tersebut, replika akan terus tersedia untuk pembacaan. Dalam situasi ini, pembacaan dari replika dapat menjadi tidak valid dan aplikasi harus dapat menanganinya, atau laju penulisan yang tinggi harus ditangani.
Langkah berikutnya
- Pelajari cara mengelola replika baca.
- Pelajari cara mengekspor data dari instance Redis.
- Pelajari ketersediaan tinggi untuk Memorystore for Redis.