This page describes High Availability (HA) for Memorystore for Redis instances in the Standard Tier.
Overview
The Standard Tier protects a Redis instances from common failures by replicating data to one or more replicas, and by providing fast automatic failover to a replica.
The Standard Tier is provisioned with one primary and one or more replicas. A
Standard Tier instance that has the readReplicaMode disabled has
a single non-read replica. A Standard Tier instance that has the
readReplicaMode enabled has one to five read replicas. To determine if
the readReplicaMode is enabled, see View read replica information for your instance.
Memorystore for Redis provides high availability by replicating a Redis primary to one or more replicas. Changes made to the data on the primary are copied to replicas using the Redis asynchronous replication protocol. Due to the asynchronous nature of replication, replicas can lag behind the primary depending on the write rate on the primary.
On failure of the primary, the instance fails over automatically to a replica. For instances configured with more than one replica, the instance automatically fails over to a replica with the least replication lag that is healthy.
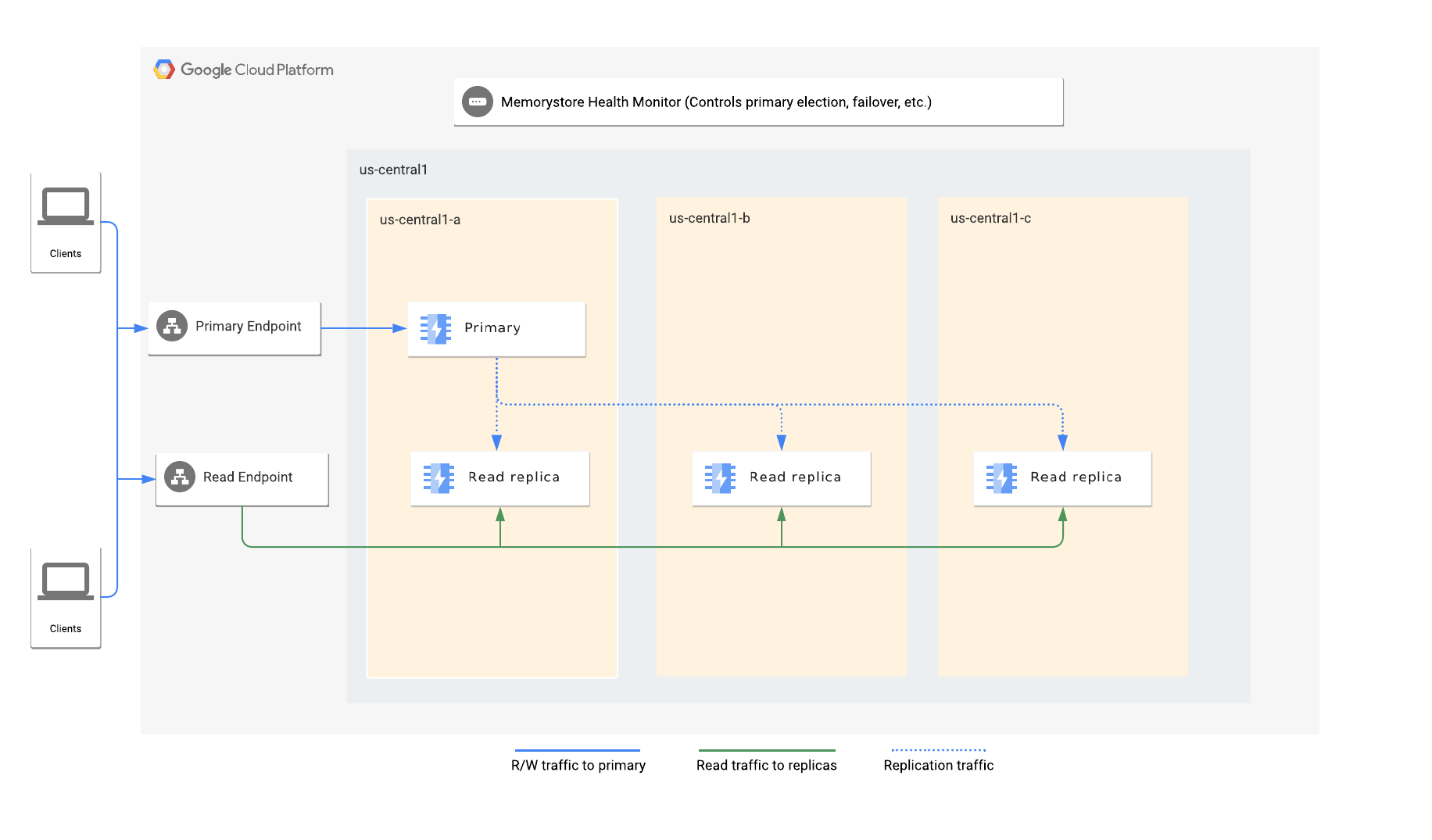
If an instance is configured with only one non-read replica, all application connections are directed to the primary endpoint. If an instance is configured using read replicas, applications can also leverage the read endpoint to distribute read queries across all replicas.
When a failover is triggered
A failover occurs when the Redis primary fails. During a failover, the primary and read endpoint automatically redirect to the new primary and replicas. All connections to the primary endpoint are dropped and read endpoint connections to the read replica that is promoted are also dropped.
How a failover affects your application
When the primary fails over to the replica, existing connections to the primary endpoint of the instance are dropped. The instance will be unavailable for an average of 30 seconds during automated repairs, and 15 seconds for maintenance events. On reconnect, your application is automatically redirected to the new primary using the same connection string or IP address. You don't need to update your application after a failover.
During failover, if there are connections to the read endpoint, the connections to the replica that is being promoted to primary are dropped. The connections to the other replicas continue to be served during the failover. Once the failover is complete and the new replica is available, connections are redirected to the new replica.
Retrying the instance connection after failover
When a failover happens, all connections from the primary endpoint are dropped and depending on the number of replicas some read connections are terminated.
Due to this loss of connection, your application needs to retry in order to reestablish the connection. The retry logic should use exponential backoff to ensure that you don't overload your instance with too many retry requests. In addition to including retry logic, you should test how a failover affects your application by testing with a manual failover.
Most Redis clients have built-in retry capabilities that you should leverage in the event of a connection drop due to failover.
A failover occurs in the following scenarios:
- Scaling your instance
- Upgrading the Redis version of an instance
- Initiating a manual failover
- Maintenance updates
If you implement retry logic in your application to handle connection drops due to failovers, your instance should not see a significant performance impact. Usually, issues only arise as a result of not having retry logic in place.
How you view the status for high availability
You can see high availability metrics for your Redis instance by using Cloud Monitoring. For information about the metrics that Cloud Monitoring provides for Memorystore for Redis, see Monitoring Redis Instances and Monitoring metrics.
For more information, see the Cloud Monitoring documentation.
To see the native replication status that Redis provides, you can issue the Redis INFO command to the Memorystore for Redis instance.