The Standard Tier of Memorystore for Redis provides the ability to scale your application's read queries using read replicas. This page assumes you are familiar with the different Memorystore Redis tier capabilities.
Read replicas allow you to scale your read workload by querying the replicas. A read endpoint is provided to make it easier for the applications to distribute queries across replicas. For more information, see Scaling reads with read endpoint.
For instructions on managing a Redis instance with read replicas, see Manage read replicas.
Use cases for read replicas
Session store, leaderboard, recommendation engine, and other use cases require the instance to be highly available. For these use cases there are many more reads than writes, and these use cases are generally able to tolerate some stale reads. In cases such as these, it makes sense to leverage read replicas to increase the availability and scalability of the instance.
Read replica behavior
- Read replicas are not enabled on Standard Tier instances by default.
- Once read replicas are enabled on an instance read replicas can no longer be disabled for that instance.
- Standard Tier instances can have 1 to 5 read replicas.
- The read endpoint provides a single endpoint for distributing queries across replica nodes.
- Read replicas are maintained using Redis asynchronous replication.
Caveats and limitations
- Read replicas are only supported for instance sizes with nodes >= 5 GB.
- Read replicas can only be enabled on instances that use Redis version 5.0 or higher.
- If you designate a zone and alternate zone for provisioning nodes, Memorystore uses those zones for the first and second nodes in the instance. After that, Memorystore selects the zones for all remaining nodes provisioned for the instance.
- You must provision the instance with a CIDR IP address range of
/28or greater. Larger range sizes like/27and/26are valid. Smaller ranges like/29are not supported for this feature.
Architecture
When enabling read replicas, you specify the number of replicas you want in the instance. Memorystore automatically distributes the primary and read replica nodes across available zones in a region.
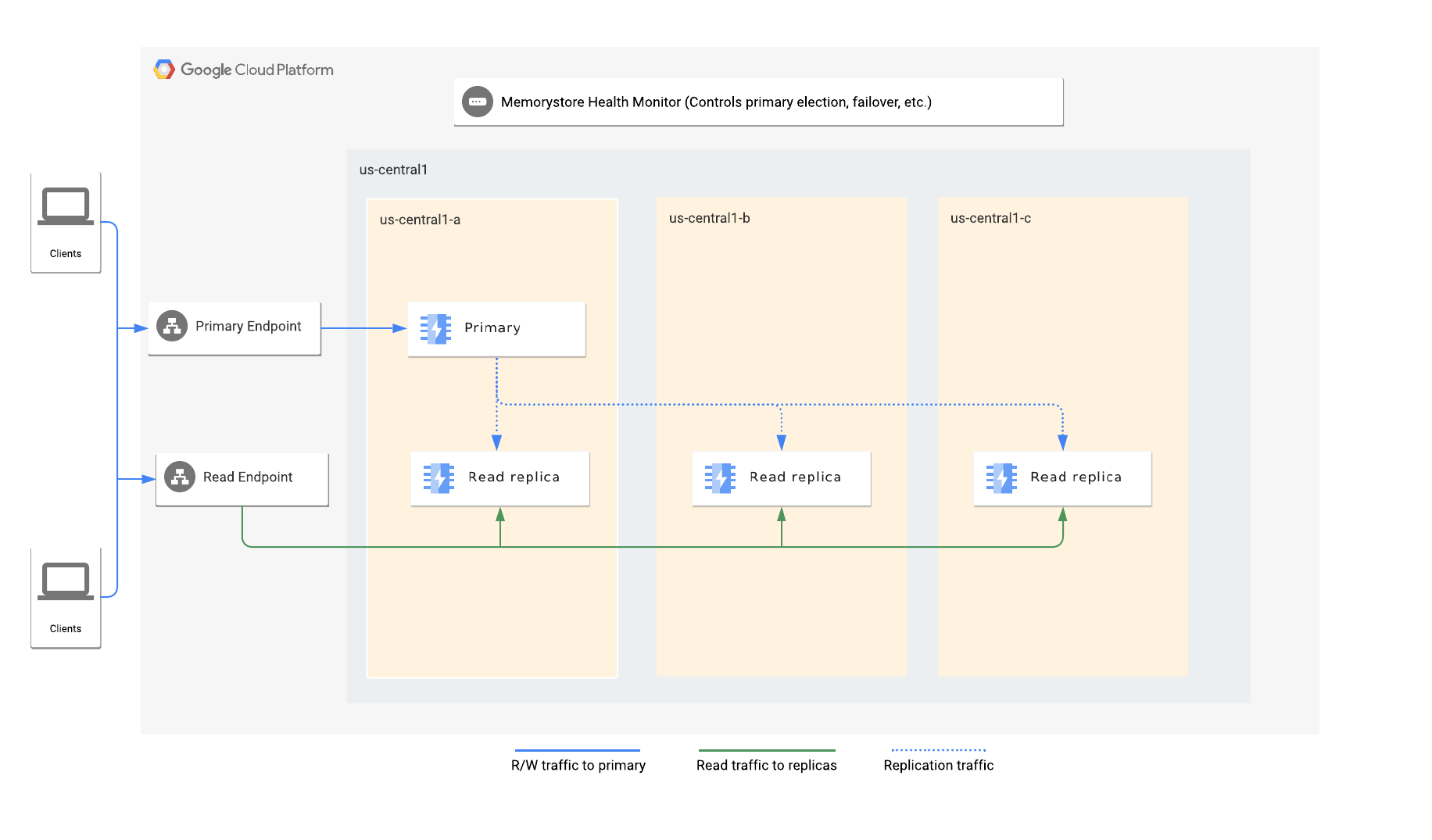
Each instance has a primary endpoint and read endpoint. The primary endpoint always directs traffic to the primary node, while the read endpoint automatically load-balances read queries across available replicas.
The Memorystore for Redis health monitoring service monitors the instance and is responsible for detecting any failure of the primary node, and elects a replica as the new primary and initiates an automatic failover to the new primary.
Failovers for instances with read replicas
When a primary fails, the Memorystore health monitoring service initiates the failover and the new primary is made available for both reads and writes. The failover usually completes in under 30 seconds.
When a failover happens the primary endpoint automatically redirects traffic to the new primary, however, all client connections to the primary endpoint are disconnected during a failover. Applications with connection retry logic will automatically reconnect once the new primary is online. Some of the client connections to the read endpoint also undergo disconnects from the read replica that is promoted to primary during failover. Connections to remaining replicas continue to be served during a failover. On retry the connections are redirected to the new replicas.
When a failover occurs, due to the asynchronous nature of replication, replicas can have different replication lag. However, the failover process does a best effort to fail over to the replica with the least lag. This helps minimize the amount of data loss and reduction to read throughput during a failover. The newly promoted primary can be in the same zone or a different zone as the former primary. A replica is selected to be the new primary if it is in the same zone as the former primary and has the least lag. If not, a replica from a different zone can become the new primary.
Since the replication is asynchronous, there is always the possibility of reading stale data during a failover. Also, while the new primary is being promoted, some writes to the instance may be lost. Applications should be able to deal with this behavior.
Redis makes a best effort to avoid the other replicas requiring a full sync during failover, but it can happen in rare scenarios. A full sync can take a few minutes to an hour depending on the write rate and the size of the data set that is being replicated. During this time replicas undergoing a full sync are unavailable for reads. Once the synchronization is complete the replicas can be accessed for reads.
Failure modes for read replicas
Instances with read replicas can run into various failures and unhealthy conditions that impact the application. The behavior varies depending on whether the instance has one replica, or two or more replicas. The section outlines some common failure modes and outlines the behavior of the instance during these conditions.
Replica is unavailable
When a replica fails for any reason, the replica is marked as unavailable and all connections to the replica are terminated after a certain timeout. Once the replica is recovered, new connections are routed to the restored replica. The time to recover a replica varies depending on the failure mode.
If a zone failure occurs, then Memorystore for Redis doesn't recover the replica until the zone becomes available.
Zone failure
If the zone where the primary is located fails, the primary automatically fails over to a replica in another zone. If the instance only has one replica, then the read endpoint is unavailable for the duration of the zone outage. If the instance has more than one replica, replicas outside of the affected zone are available for reads
If the zone where one or more of the replicas is located fails, those replicas are unavailable for the duration of the zone failure. If there is a two zone failure and there are two or more replicas, the replica with the least lag in the remaining zones is promoted to the primary. Any remaining replicas in the unaffected zones are available for reads.
Network partition
A network partition is a scenario where nodes stay running but cannot reach all clients, zones, or peer nodes. Memorystore uses a quorum based system to prevent isolated nodes from serving writes. In case of a network partition, any primary in a minority partition self demotes. The majority partition (if one exists) elects a new primary if it does not already have one. Isolated replicas continue to serve reads. However, they may become stale if they cannot sync from the primary.
To determine if the link is broken, monitor the master_link_down_since_seconds
and offset_diff metrics to identify isolated nodes.
Full sync
When a replica falls too far behind the primary it triggers a full sync which copies an entire snapshot from the primary to a replica. This operation can take anywhere from minutes up to an hour in the worst case. A full sync does not cause an instance failure, however during this time the replica undergoing the full sync is not available for reads and the primary experiences higher CPU and memory utilization.
Primary endpoint returns READONLY
Your writes to the primary endpoint of a Memorystore for Redis instance with
read replicas may unexpectedly receive -READONLY You can't write against a read
only replica. errors. We recommend closing and recreating the connections to
the instance. In most cases, restarting the client application can mitigate the
issue. If these options are not feasible or the behavior persists, please
contact the Google Cloud Support team.
Scaling reads with the read endpoint
Read replicas allow applications to scale their reads by reading from the replicas. Applications can connect to read replicas via the read endpoint.
Read endpoint
The read endpoint is an IP address that your application connects to. It evenly load balances connections across the replicas in the instance. Connections to the read replica can send read queries, but not write queries. Every Standard Tier instance that has read replicas enabled has a read endpoint. For instructions on viewing your instance's read endpoint, see View read replica information for your instance.
Behavior of the read endpoint
- The read endpoint automatically distributes connections across all available replicas. Connections are not directed to the primary.
- A replica is considered available as long as it is able to serve client traffic. This does not include times when a replica is undergoing a full-sync with its primary.
- A replica with a high replication lag continues to serve traffic. Applications with high write volume can read stale data from a replica serving high writes.
- In the event a replica node becomes the primary, connections to that node are terminated and new connections are redirected to a new replica node.
- Individual connections to the read endpoint target the same replica for the lifetime of the connection. Different connections from the same client host are not guaranteed to target the same replica node.
Read consistency
Read replicas are maintained using native OSS Redis asynchronous replication. Due to the nature of asynchronous replication it is possible that the replica lags behind the primary. Applications with constant writes that are also reading from the replica should be able to tolerate inconsistent reads.
If the application requires "read your write" consistency, we recommended using the primary endpoint for both writes and reads. Using the primary endpoint ensures that the reads are always directed to the primary. Even in this case it is possible to have stale reads after a failover.
Setting TTLs on the keys on the primary ensures expired keys are not read from either the primary or the replica. This is because Redis ensures an expired key cannot be read from the replica.
Behavior of enabling read replicas on an existing instance
Enabling read replicas is an exclusive operation, meaning you cannot perform other update operation instance modifications as a part of the same operation that enables read replicas.
Enabling read replicas on an existing Redis instance requires you to allocate a valid secondary IP address range for node placement. This must be a Classless Inter-Domain Routing (CIDR) range of size
/28, regardless of the size of the existing IP address range that's allocated to Memorystore for Redis.- You must provide the additional IP range when enabling read replicas for the Redis instance. You can either choose a specific range, or let Memorystore automatically select one for you.
The read/write IP address for your instance does not change when enabling read replicas. The read endpoint IP address is located in the original range allocated for your Memorystore instance, not the additional range you provide when enabling read replicas.
To find the new read endpoint, view read replica information for your instance after the operation to enable read replicas completes.
Scaling an instance
You can scale the number of read replicas for your instance, and you can also the modify the node size:
For instructions on adding and removing nodes, see Add or remove replica nodes from your Redis instance.
For instructions on scaling the size of Redis nodes, see Scale the size of Redis nodes.
We recommend that you scale your instance during a period of low read and write traffic to minimize impact to the application.
Adding a new replica results in additional load on the primary while the replica performs a full sync. When adding nodes, existing connections are not affected or transferred. Once the new replica is available it starts to receive connections from the endpoint and serves reads. Removing a replica closes any active connections routed to that replica. The client application should be configured to automatically reconnect to the read endpoint to reestablish connections to the remaining replicas.
Best practices
Memory management
Redis does not allow client writes to exceed the maxmemory limit
of the instance. However, overhead such as fragmentation, replication buffers,
and expensive commands like EVAL can increase memory utilization past this
limit. In these cases Memorystore fails writes until the memory
pressure is reduced. See Memory management best practices
for more details.
If Memorystore is undergoing a BGSAVE operation due to an export or full sync replication and an OOM condition occurs, the child process is killed. In this case the BGSAVE operation fails and the Redis node server remains available.
To guarantee replication and snapshot creation under all circumstances we advise keeping memory utilization less than 50% during important operations like export, scaling, etc. You can manually trigger export or failover to see the performance impact of these operations.
CPU management
Memorystore provides metrics on CPU usage and the connection count for each node. We recommend that you allocate enough overhead so that the loss of a single availability zone can be tolerated. The ideal target may vary based on the number of replicas and usage patterns but a good starting point is to keep replica CPU usage below 50%.
Individual nodes may experience high usage if client usage patterns are unbalanced, or if failover operations result in an unbalanced connection distribution. In this case, we recommend that you periodically close your connections to allow Memorystore to automatically rebalance connections. Memorystore does not rebalance open connections.
Connection balance management
Anytime a node's connections are closed clients have to reconnect, typically by enabling auto reconnect on the client library of your choice. When the node is reintroduced existing connections are not rerouted, however new connections are routed to the new node. Clients can periodically kill connections to ensure they are balanced across available nodes.
Replication lag management
It is possible for replicas to lag behind especially when the write rate is very high. In such scenarios the replica continues to be available for reads. In this circumstance, reads from the replica can be stale and the application should be able to handle this, or the high write rate should be addressed.
What's next
- Learn how to manage read replicas.
- Learn about exporting data from a Redis instance.
- Learn about high availability for Memorystore for Redis.