このページには、Cloud Logging でログベースの指標を使用する際の一般的なシナリオのトラブルシューティング情報を掲載しています。
指標を表示または作成できない
ログベースの指標は、単一の Google Cloud プロジェクトまたは Google Cloud プロジェクト内の Logging バケットにのみ適用されます。請求先アカウントや組織などの他の Google Cloudリソースには、ログベースの指標を作成できません。ログベースの指標は、指標が受信された Google Cloud プロジェクトまたはバケットのログに対してのみ計算されます。
指標を作成するには、適切な Identity and Access Management 権限が必要です。詳細については、IAM によるアクセス制御: ログベースの指標をご覧ください。
指標のログデータがない
ログベースの指標のデータが欠落している理由として、いくつかの可能性が考えられます。
新しいログエントリが指標のフィルタと一致していない。ログベースの指標は、指標が作成された後に受信した、一致するログエントリからデータを取得します。Logging では、以前のログエントリからの指標はバックフィルされません。
新しいログエントリに正しいフィールドが含まれていないか、データが適切な形式で分布指標から抽出されないことがあります。フィールド名と正規表現が正しいことを確認してください。
指標のカウントが遅れている。カウントできるログエントリがログ エクスプローラに表示されている場合でも、Cloud Monitoring でログベースの指標が更新されるまでに最大 10 分を要する場合があります。
タイムスタンプの時間との差が大きすぎるため、表示されているログエントリのカウントが遅れているか、まったくカウントされていない可能性があります。ログエントリが過去 24 時間を超える期間または未来に 10 分を超える期間ずれて Cloud Logging に受信された場合、ログエントリはログベースの指標にカウントされません。
遅れて到着するエントリの数は、ログベースの指標
logging.googleapis.com/logs_based_metrics_error_countに記録されます。例: ログベースの指標に一致するログエントリが遅れて到着したとします。それは、
timestampが 2020 年 2 月 20 日午後 2 時 30 分で、receivedTimestampが 2020 年 2 月 21 日午後 2 時 45 分です。このエントリはログベースの指標にカウントされません。ログベースの指標が、指標がカウントする可能性があるログエントリの到着後に作成されました。ログベースの指標は、ログバケットに保存されているログエントリを評価します。これらの指標は、Logging に保存されているログエントリを評価しません。
ログベースの指標にデータのギャップがあります。ログベースの指標データを処理するシステムでは、すべての指標データポイントの永続性が保証されないため、データのギャップが予想されます。ギャップが発生することは通常はまれで、短時間です。ただし、ログベースの指標をモニタリングするアラート ポリシーがある場合、データのギャップにより誤った通知が発生する可能性があります。アラート ポリシーで使用する設定によって、この可能性を低減できます。
例: 「ハートビート」ログエントリは 5 分ごとに書き込まれ、ログベースの指標は「ハートビート」ログエントリの数をカウントします。アラート ポリシーは、5 分間の間隔でカウントを合計し、合計が 1 未満の場合に通知します。時系列にデータポイントがない場合は、アラート ポリシーが合成値を挿入します。この値は最新のサンプルの重複であり、ほとんどの場合 0 になります。その後、条件が評価されます。したがって、1 つのデータポイントが欠落しているだけで、合計値がゼロになり、このアラート ポリシーによって通知が送信される可能性があります。
誤検出のリスクを軽減するには、1 つではなく複数の「ハートビート」ログエントリをカウントするようにポリシーを構成します。
Cloud Monitoring でリソースタイプが「未定義」です
一部の Cloud Logging モニタリング対象リソースのタイプは、Cloud Monitoring モニタリング対象リソースのタイプに直接マッピングされません。たとえば、ログベースの指標からアラート ポリシーまたはグラフのいずれかを初めて作成する際、リソースタイプが「未定義」になる場合があります。
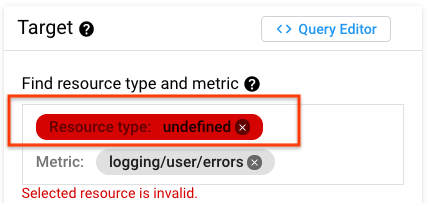
モニタリング対象リソースのタイプは、global または Cloud Monitoring の別のモニタリング対象リソースのタイプのいずれかにマッピングされます。Logging 専用のリソースのマッピングを参照して、どのモニタリング対象リソースのタイプを選択すべきか判断します。
通知のラベルが解決されない
ログベースの指標を作成し、そのログベースの指標をモニタリングするアラート ポリシーを作成します。アラート ポリシーのドキュメント フィールドでは、${log.extracted_label.KEY} という形式の変数を使用して抽出されたラベルを参照します。ここで、KEY は、抽出されたラベルに付与した名前です。通知でラベルが解決されていない。
この問題を解決するには、以下のいずれかを行います。
抽出したラベルの内容をドキュメントから削除する。ログベースの指標をモニタリングするアラート ポリシーは、ログエントリからデータを抽出できません。
ログベースのアラートを作成する。これらのアラート ポリシーは、アラート ポリシーのトリガーとなるログエントリからデータを抽出できます。
インシデントが作成されない、または誤検出である
アラート ポリシーのアライメント期間が短すぎるため、誤検出のインシデントまたは、Monitoring がログベースの指標からインシデントを作成しない状況が発生する可能性があります。次のようなシナリオでは、誤検出が発生する場合があります。
- アラート ポリシーで未満ロジックを使用する場合。
- アラート ポリシーが分布指標のパーセンタイル条件に基づいている場合。
- 指標データにギャップがある場合。
ログエントリが Logging に遅れて送信される可能性があるため、誤検出のインシデントが発生します。たとえば、ログフィールド timestamp と receiveTimestamp には分単位の差分を指定できます。また、Logging がログバケットにログを保存する場合、ログエントリが生成されるときと Logging がログエントリを受け取るときの間に、固有の遅延があります。つまり、ログエントリが生成されてから少し後の時点まで、Logging は特定のログエントリの合計数を持たないことがあります。これが、未満ロジックを使用する、または配布指標のパーセンタイル条件に基づくアラート ポリシーが「まだすべてのログエントリは考慮されていません」の誤検出アラートを生成する理由です。
しかしながら、ログベースの指標と一致するログエントリは、ログの receiveTimestamp よりも大幅に古い、または新しい timestamp で Logging に送信できるため、ログベースの指標は結果整合性を保持します。
つまり、同じタイムスタンプを持つ既存のログエントリが Logging で受信された後、ログベースの指標で古いタイムスタンプを持つログエントリを受信できます。したがって、指標値を更新する必要があります。
オンタイムのデータであっても通知を正確なままにするには、条件のアライメント期間を 10 分以上に設定することをおすすめします。特に、この値は、フィルタに一致する複数のログエントリがカウントされるように十分に大きくする必要があります。たとえば、ログベースの指標で、N 分ごとに発生する「ハートビート」ログエントリをカウントする場合は、アライメント期間を 2N 分または 10 分のどちらか大きい方に設定します。
Google Cloud コンソールを使用する場合は、[ローリング ウィンドウ] メニューを使用して、アライメント期間を設定します。
API を使用している場合は、条件の
aggregations.alignmentPeriodフィールドを使用して、アライメント期間を設定します。
指標の時系列が多すぎる
指標の時系列の数は、ラベル値の異なる組み合わせの数によって異なります。時系列の数は、指標のカーディナリティと呼ばれ、30,000 以下にする必要があります。
ラベル値のすべての組み合わせに対して時系列を生成できるため、値の数が多い 1 つ以上のラベルがあれば、30,000 時系列を超えることはあり得ます。高いカーディナリティの指標は避けます。
指標のカーディナリティが増加すると、指標が抑制され、指標にデータポイントが書き込まれない場合があります。グラフが処理する必要がある時系列が多数あるため、指標が表示されるグラフの読み込みが遅くなることがあります。また、時系列データをクエリする API 呼び出しの費用が発生することもあります。Google Cloud Observability の料金ページの Cloud Monitoring セクションをご覧ください。
カーディナリティの高い指標を作成しないようにするには、次のことを行います。
ラベル フィールドとエクストラクタの正規表現が、限定されたカーディナリティを持つ値と一致することを確認します。
たとえば、サイズ、数、時間はラベルに保存しないでください。また、URL、IP アドレス、一意の ID などのフィールドは保存しないでください。これらのフィールドはすべて、大量の時系列につながる可能性があります。
無制限に変更可能なテキスト メッセージをラベル値として抽出しないようにします。
無制限のカーディナリティを持つ数値を抽出しないようにします。
カーディナリティがわかっているラベルからのみ値を抽出します(たとえば、値の範囲が決まっているステータス コードなど)。
次のシステムログ ベースの指標は、ラベルの追加や削除が指標のカーディナリティに及ぼす影響を測定する際に有用です。
logging.googleapis.com/metric_throttledlogging.googleapis.com/time_series_countlogging.googleapis.com/metric_label_throttledlogging.googleapis.com/metric_label_cardinality
これらの指標を確認すると、指標名で結果を絞り込むことができます。詳細については、指標の選択: フィルタリングをご覧ください。
指標名が無効
カウンタ指標または分布指標を作成するときは、 Google Cloud プロジェクトのログベースの指標で一意の指標名を選択します。
指標名の文字列は 100 文字を超えてはならず、次の文字のみを含めることができます。
A~Za~z0~9特殊文字
_-.,+!*',()%\/.スラッシュ文字(
/)は指標名の部分の階層を示し、名前の先頭の文字にすることはできません。
指標値が正しくない
ログベースの指標で報告される値が、ログ エクスプローラで報告されるログエントリの数と異なる場合があります。
差異を最小限に抑えるには、次の手順を行います。
アプリケーションが重複するログエントリを送信していないことを確認します。ログエントリの
timestampとinsertIdが同じ場合、それらのログエントリは重複と見なされます。ログ エクスプローラでは、重複するログエントリが自動的に除外されます。一方、ログベースの指標は、指標のフィルタに一致する各ログエントリをカウントします。タイムスタンプが過去 24 時間以内または今後の 10 分以内の場合、ログエントリが Cloud Logging に送信されるようにします。タイムスタンプがこれらの範囲内にないログエントリは、ログベースの指標でカウントされません。
ログの重複が発生する可能性を排除することはできません。ログエントリの処理中に内部エラーが発生すると、Cloud Logging によって再試行プロセスが呼び出されます。再試行プロセスにより、ログエントリが重複する可能性があります。重複するログエントリが存在する場合、ログベースの指標の値が大きすぎる可能性があります。これは、これらの指標が、指標のフィルタに一致する各ログエントリをカウントするためです。
ラベル値が切り捨てられる
ユーザー定義のラベルの値は、1,024 バイトを超えることはできません。
カスタムログ指標を削除できない
Google Cloud コンソールを使用してカスタム ログベースの指標を削除しようとしました。削除リクエストが失敗し、削除ダイアログにエラー メッセージ There is an unknown error while executing this operation が表示されます。
この問題を解決するには、次のことを試してください。
Google Cloud コンソールの [ログベースの指標] ページを更新します。内部のタイミングの問題が原因でエラー メッセージが表示されることがあります。
ログベースの指標をモニタリングするアラート ポリシーを特定して削除します。ログベースの指標がアラート ポリシーによってモニタリングされていないことを確認したら、ログベースの指標を削除します。アラート ポリシーによってモニタリングされているログベースの指標は削除できません。