Ce document explique comment Cloud Logging achemine les entrées de journal reçues par Google Cloud. Il existe plusieurs types de destinations de routage. Par exemple, vous pouvez acheminer les entrées de journal vers une destination telle qu'un bucket de journaux, qui stocke les entrées de journal. Si vous souhaitez exporter vos données de journaux vers une destination tierce, vous pouvez acheminer les entrées de journaux vers Pub/Sub. De plus, une entrée de journal peut être acheminée vers plusieurs destinations.
De manière générale, voici comment Cloud Logging achemine et stocke les entrées de journal :
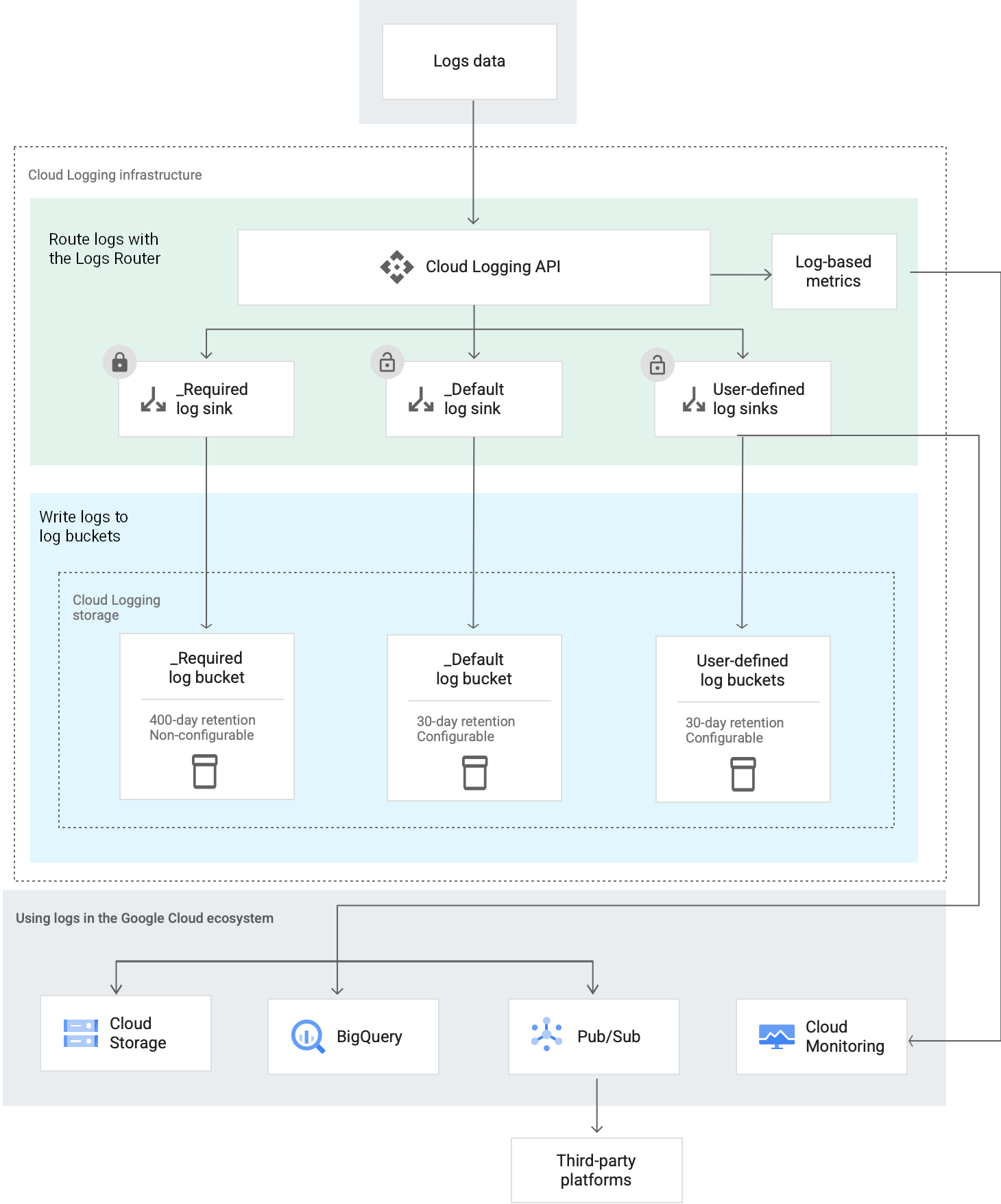
À propos des routeurs de journaux
Chaque projet Google Cloud , compte de facturation, dossier et organisation dispose d'un routeur de journaux qui gère le flux des entrées de journal via les récepteurs au niveau des ressources. Un routeur de journaux gère également le flux d'une entrée de journal via les récepteurs qui se trouvent dans la hiérarchie des ressources de l'entrée. Les récepteurs contrôlent la manière dont les entrées de journal sont acheminées vers les destinations.
Un routeur de journaux stocke temporairement une entrée de journal. Ce comportement permet de se prémunir contre les perturbations et les pannes temporaires qui peuvent survenir lorsqu'une entrée de journal transite par des récepteurs. Le stockage temporaire ne protège pas contre les erreurs de configuration.
Le stockage temporaire du routeur de journaux est différent du stockage à long terme fourni par les buckets Logging.
Les entrées de journal entrantes dont l'horodatage est antérieur à la période de conservation des journaux ou situé plus de 24 heures dans le futur sont supprimées.
À propos des récepteurs de journaux
Lorsqu'un récepteur de journaux reçoit une entrée de journal, il détermine s'il doit l'ignorer ou l'acheminer. Cette décision est prise en comparant l'entrée de journal aux filtres du récepteur de journaux. Lorsque l'entrée de journal est acheminée, le récepteur de journaux l'envoie à la destination spécifiée par le récepteur de journaux. Cette destination peut être un projet, un emplacement de stockage ou un service.
Les récepteurs de journaux appartiennent à une ressource Google Cloud donnée : Google Cloud projets, comptes de facturation, dossiers et organisations. Ces ressources contiennent également plusieurs récepteurs de journaux. Lorsqu'une ressource reçoit une entrée de journal, chaque récepteur de journaux de cette ressource évalue l'entrée de journal de manière indépendante. Par conséquent, plusieurs récepteurs de journaux peuvent acheminer la même entrée de journal.
Par défaut, les données de journaux sont stockées dans le projet dont elles proviennent. Toutefois, vous pouvez modifier cette configuration pour plusieurs raisons :
- Pour centraliser le stockage de vos données de journaux.
- Pour associer vos données de journaux à d'autres données d'entreprise.
- Pour organiser vos données de journaux de manière à ce qu'elles vous soient utiles.
- Diffuser vos journaux vers d'autres applications, d'autres dépôts, ainsi que vers des organisations tierces. Par exemple, vous pouvez exporter vos journaux depuis Google Cloud pour les afficher sur une plate-forme tierce. Pour exporter vos entrées de journal, créez un récepteur de journaux qui les achemine vers Pub/Sub.
Un récepteur de journaux mal configuré n'achemine pas les entrées de journal. Lorsqu'un récepteur est mal configuré, des entrées de journal détaillant l'erreur sont écrites. Un e-mail est également envoyé aux contacts essentiels de la ressource. Pour en savoir plus, consultez Dépannage : afficher les erreurs.
Les récepteurs de journaux ne peuvent pas acheminer les entrées de journal de manière rétroactive. En d'autres termes, un récepteur de journaux ne peut pas acheminer une entrée de journal reçue avant sa création. De même, si un récepteur est mal configuré, il ne route que les entrées de journal qui arrivent après la résolution de l'erreur de configuration. Toutefois, vous pouvez copier rétroactivement les données de journaux d'un bucket de journaux vers Cloud Storage. Pour en savoir plus, consultez Copier les journaux.
Prise en charge des organisations et des dossiers
Pour vous aider à gérer les données de journaux dans une organisation ou un dossier, vous pouvez effectuer les opérations suivantes :
Vous pouvez créer des récepteurs agrégés, qui acheminent les entrées de journal d'une organisation ou d'un dossier et de leurs enfants vers la destination spécifiée par le récepteur. Il existe deux types de récepteurs agrégés :
- Récepteurs agrégés sans interception
- Récepteurs agrégés d'interception
La différence entre ces deux types de récepteurs est que les récepteurs d'interception à un niveau de la hiérarchie des ressources peuvent affecter le routage des ressources situées plus bas dans la hiérarchie. Les récepteurs sans interception n'affectent pas le routage des autres ressources. Lorsqu'un récepteur d'interception dans une ressource correspond à une entrée de journal, celle-ci n'est pas envoyée aux récepteurs des ressources enfants. Toutefois, l'entrée de journal est toujours envoyée au récepteur de journaux
_Requiredde la ressource dans laquelle elle est générée.Vous pouvez configurer les paramètres de ressources par défaut pour spécifier la configuration du récepteur
_Defaultcréé par le système pour les nouvelles ressources d'une organisation ou d'un dossier. Par exemple, vous pouvez utiliser ces paramètres pour désactiver le récepteur_Defaultou spécifier les filtres dans ce récepteur.
Exemples de routage
Cette section explique comment une entrée de journal provenant d'un projet peut transiter par les récepteurs de sa hiérarchie de ressources.
Exemple : Aucun récepteur agrégé n'existe
Lorsqu'aucun récepteur agrégé n'existe dans la hiérarchie des ressources de l'entrée de journal, celle-ci est envoyée aux récepteurs de journaux du projet dans lequel elle a été créée. Un récepteur au niveau du projet achemine l'entrée de journal vers la destination du récepteur lorsque l'entrée de journal correspond au filtre d'inclusion du récepteur, mais ne correspond à aucun de ses filtres d'exclusion.
Exemple : Un récepteur agrégé sans interception existe
Supposons qu'un récepteur agrégé non interceptant existe dans la hiérarchie des ressources pour une entrée de journal. Une fois que le routeur de journaux a envoyé l'entrée de journal au récepteur agrégé sans interception, les événements suivants se produisent :
Le récepteur agrégé sans interception achemine l'entrée de journal vers la destination du récepteur lorsque l'entrée de journal correspond au filtre d'inclusion, mais ne correspond à aucun filtre d'exclusion.
Le routeur de journaux envoie l'entrée de journal aux récepteurs de journaux du projet dans lequel elle a été générée.
Un récepteur au niveau du projet achemine l'entrée de journal vers la destination du récepteur lorsque l'entrée de journal correspond au filtre d'inclusion du récepteur, mais ne correspond à aucun de ses filtres d'exclusion.
Exemple : Un récepteur agrégé d'interception existe
Supposons qu'un récepteur agrégé d'interception existe dans la hiérarchie des ressources pour une entrée de journal. Une fois que le routeur de journaux a envoyé l'entrée de journal au récepteur agrégé d'interception, l'une des situations suivantes se produit :
L'entrée de journal correspond au filtre d'inclusion, mais pas à un filtre d'exclusion :
- L'entrée de journal est acheminée vers la destination du récepteur agrégé d'interception.
- L'entrée de journal est envoyée au récepteur
_Requireddu projet dans lequel elle a été générée.
L'entrée de journal ne correspond pas au filtre d'inclusion ou correspond à au moins un filtre d'exclusion :
- L'entrée de journal n'est pas acheminée par le récepteur agrégé d'interception.
Le routeur de journaux envoie l'entrée de journal aux récepteurs de journaux du projet dans lequel elle a été générée.
Un récepteur au niveau du projet achemine l'entrée de journal vers la destination du récepteur lorsque l'entrée de journal correspond au filtre d'inclusion du récepteur, mais ne correspond à aucun de ses filtres d'exclusion.
Filtres de récepteur de journaux
Chaque récepteur de journaux contient un filtre d'inclusion et peut contenir plusieurs filtres d'exclusion. Ces filtres déterminent si le récepteur de journaux achemine une entrée de journal vers la destination du récepteur. Si vous ne spécifiez aucun filtre, chaque entrée de journal est acheminée vers la destination du récepteur.
Une entrée de journal est acheminée par un récepteur de journaux en fonction des règles suivantes :
Si l'entrée de journal ne correspond pas au filtre d'inclusion, elle n'est pas acheminée. Lorsqu'un récepteur ne spécifie pas de filtre d'inclusion, chaque entrée de journal correspond à ce filtre.
Si l'entrée de journal correspond au filtre d'inclusion et à au moins un filtre d'exclusion, elle n'est pas acheminée.
Si l'entrée de journal correspond au filtre d'inclusion et à aucun filtre d'exclusion, elle est acheminée vers la destination du récepteur.
Les filtres d'un récepteur de journaux sont spécifiés à l'aide du langage de requête Logging.
Vous ne pouvez pas utiliser de filtres d'exclusion pour réduire la consommation de votre quota d'API entries.write ni le nombre d'appels d'API entries.write. Les filtres d'exclusion sont appliqués après la réception des entrées de journal par l'API Logging.
Récepteurs de journaux créés par le système
Pour chaque projet, compte de facturation, dossier et organisation Google Cloud , Cloud Logging crée deux récepteurs de journaux, l'un nommé _Required et l'autre _Default. Les filtres d'inclusion et d'exclusion de ces récepteurs vérifient que chaque entrée de journal qui atteint la ressource est routée par l'un de ces récepteurs.
Les deux récepteurs acheminent les données de journaux vers un bucket de journaux qui se trouve dans la même ressource que le récepteur de journaux.
Le reste de cette section fournit des informations sur les filtres et les destinations des récepteurs de journaux créés par le système.
Récepteur de journaux _Required
Le récepteur de journaux _Required d'une ressource achemine un sous-ensemble de journaux d'audit vers le bucket de journaux _Required de la ressource.
Ce récepteur ne spécifie aucun filtre d'exclusion, et le filtre d'inclusion est le suivant :
LOG_ID("cloudaudit.googleapis.com/activity") OR
LOG_ID("externalaudit.googleapis.com/activity") OR
LOG_ID("cloudaudit.googleapis.com/system_event") OR
LOG_ID("externalaudit.googleapis.com/system_event") OR
LOG_ID("cloudaudit.googleapis.com/access_transparency") OR
LOG_ID("externalaudit.googleapis.com/access_transparency")
Le récepteur de journaux _Required ne correspond qu'aux entrées de journal provenant de la ressource dans laquelle il est défini._Required Par exemple, supposons qu'un récepteur de journaux route une entrée de journal d'activité du projet A vers le projet B.
Comme l'entrée de journal ne provient pas du projet B, le récepteur de journaux _Required du projet B n'achemine pas cette entrée de journal vers le bucket de journaux _Required.
Vous ne pouvez ni modifier, ni supprimer le récepteur de journaux _Required.
Récepteur de journaux _Default
Le récepteur de journaux _Default d'une ressource achemine toutes les entrées de journal, à l'exception de celles qui correspondent au filtre du récepteur de journaux _Required, vers le bucket de journaux _Default de la ressource.
Étant donné que le filtre d'inclusion de ce récepteur est vide, il correspond à toutes les entrées de journal. Toutefois, le filtre d'exclusion est configuré comme suit :
NOT LOG_ID("cloudaudit.googleapis.com/activity") AND
NOT LOG_ID("externalaudit.googleapis.com/activity") AND
NOT LOG_ID("cloudaudit.googleapis.com/system_event") AND
NOT LOG_ID("externalaudit.googleapis.com/system_event") AND
NOT LOG_ID("cloudaudit.googleapis.com/access_transparency") AND
NOT LOG_ID("externalaudit.googleapis.com/access_transparency")
Vous pouvez modifier et désactiver le récepteur de journaux _Default. Par exemple, vous pouvez modifier le récepteur de journaux _Default et changer la destination. Vous pouvez également modifier les filtres existants et ajouter des filtres d'exclusion.
Destinations des récepteurs
La destination d'un récepteur peut se trouver dans une ressource différente de celle du récepteur. Par exemple, vous pouvez utiliser un récepteur de journaux pour acheminer des entrées de journaux d'un projet vers un bucket de journaux stocké dans un autre projet.
Les destinations suivantes sont acceptées :
- Google Cloud projet
Sélectionnez cette destination lorsque vous souhaitez que les récepteurs de journaux du projet de destination réacheminent vos entrées de journal ou lorsque vous avez créé un récepteur agrégé d'interception. Les récepteurs de journaux du projet qui est la destination du récepteur peuvent rediriger les entrées de journal vers n'importe quelle destination compatible, à l'exception d'un projet.
- Bucket de journaux
Sélectionnez cette destination lorsque vous souhaitez stocker vos données de journaux dans des ressources gérées par Cloud Logging. Les données de journaux stockées dans des buckets de journaux peuvent être consultées et analysées à l'aide de services tels que l'explorateur de journaux et l'analyse de journaux.
Si vous souhaitez joindre vos données de journaux à d'autres données d'entreprise, vous pouvez stocker vos données de journaux dans un bucket de journaux et créer un ensemble de données BigQuery associé. Un ensemble de données associé est un ensemble de données en lecture seule qui peut être interrogé comme n'importe quel autre ensemble de données BigQuery.
- Ensemble de données BigQuery
- Sélectionnez cette destination lorsque vous souhaitez associer vos données de journaux à d'autres données d'entreprise. L'ensemble de données que vous spécifiez doit être activé en écriture. Ne définissez pas la destination d'un récepteur sur un ensemble de données BigQuery associé. Les ensembles de données associés sont en lecture seule.
- Bucket Cloud Storage
- Sélectionnez cette destination si vous souhaitez stocker vos données de journaux à long terme. Le bucket Cloud Storage peut se trouver dans le même projet que celui d'où proviennent les entrées de journal ou dans un autre projet. Les entrées de journaux sont stockées sous forme de fichiers JSON.
- Sujet Pub/Sub
- Sélectionnez cette destination lorsque vous souhaitez exporter vos données de journaux depuisGoogle Cloud , puis utiliser des intégrations tierces comme Splunk ou Datadog. Les entrées de journal sont mises au format JSON, puis acheminées vers un sujet Pub/Sub.
Limites de destination
Cette section décrit les limites spécifiques aux destinations :
- Si vous acheminez des entrées de journal vers un bucket de journaux dans un autre projet Google Cloud , Error Reporting n'analyse pas ces entrées de journal. Pour en savoir plus, consultez Présentation d'Error Reporting.
- Si vous acheminez des entrées de journal vers un ensemble de données BigQuery, celui-ci doit être accessible en écriture. Vous ne pouvez pas router les entrées de journaux vers des ensembles de données associés, qui sont en lecture seule.
- Le démarrage des nouveaux récepteurs qui acheminent les données de journaux vers les buckets Cloud Storage peut prendre plusieurs heures. Ces récepteurs sont traités toutes les heures.
Les limites suivantes s'appliquent lorsque la destination d'un récepteur de journaux est un projet Google Cloud :
- Il existe une limite d'un saut.
- Les entrées de journal qui correspondent au filtre du récepteur de journaux
_Requiredne sont acheminées vers le bucket de journaux_Requireddu projet de destination que si elles proviennent du projet de destination. - Seuls les récepteurs agrégés qui se trouvent dans la hiérarchie des ressources d'une entrée de journal traitent cette entrée.
Par exemple, supposons que la destination d'un récepteur de journaux dans le projet
Asoit le projetB. Les conditions suivantes sont alors remplies :- En raison de la limite d'un saut, les récepteurs de journaux du projet
Bne peuvent pas rediriger les entrées de journaux vers un projet Google Cloud . - Le bucket de journaux
_Requireddu projetBne stocke que les entrées de journal provenant du projetB. Ce bucket de journaux ne stocke aucune entrée de journal provenant d'une autre ressource, y compris celles provenant du projetA. - Si la hiérarchie des ressources du projet
Aet du projetBdiffère, une entrée de journal qu'un récepteur de journaux du projetAachemine vers le projetBn'est pas envoyée aux récepteurs agrégés de la hiérarchie des ressources du projetB. - Si les projets
AetBont la même hiérarchie de ressources, les entrées de journal sont envoyées aux collecteurs agrégés de cette hiérarchie. Si une entrée de journal n'est pas interceptée par un récepteur agrégé, le routeur de journaux l'envoie aux récepteurs du projetA.
Impact du routage des entrées de journal sur les métriques basées sur les journaux
Les métriques basées sur les journaux sont des métriques Cloud Monitoring dérivées du contenu des entrées de journal. Par exemple, vous pouvez utiliser une métrique basée sur les journaux pour compter le nombre d'entrées de journal contenant un message particulier ou pour extraire les informations de latence enregistrées dans les entrées de journal. Vous pouvez afficher les métriques basées sur les journaux dans les graphiques Cloud Monitoring, et les règles d'alerte peuvent surveiller ces métriques.
Les métriques basées sur les journaux définies par le système s'appliquent au niveau du projet. Les métriques basées sur les journaux définies par l'utilisateur peuvent s'appliquer au niveau du projet ou du bucket de journaux. Les métriques basées sur les journaux à l'échelle du bucket sont utiles lorsque vous utilisez des collecteurs agrégés pour acheminer des entrées de journal vers un bucket de journaux, et lorsque vous acheminez des entrées de journal d'un projet vers un bucket de journaux dans un autre projet.
- Métriques basées sur les journaux définies par le système
-
Le routeur de journaux comptabilise une entrée de journal lorsque toutes les conditions suivantes sont remplies :
- L'entrée de journal transite par les récepteurs de journaux du projet dans lequel la métrique basée sur les journaux est définie.
L'entrée de journal est stockée dans un bucket de journaux. Le bucket de journaux peut se trouver dans n'importe quel projet.
Par exemple, supposons que le projet
Adispose d'un récepteur de journaux dont la destination est le projetB. Supposons également que les récepteurs de journaux du projetBacheminent les entrées de journal vers un bucket de journaux. Dans ce scénario, les entrées de journal acheminées du projetAvers le projetBcontribuent aux métriques basées sur les journaux définies par le système du projetA. Ces entrées de journal contribuent également aux métriques basées sur les journaux définies par le système du projetB.
- Métriques basées sur les journaux définies par l'utilisateur
-
Le routeur de journaux comptabilise une entrée de journal lorsque toutes les conditions suivantes sont remplies :
- La facturation est activée pour le projet dans lequel la métrique basée sur les journaux est définie.
- Pour les métriques à l'échelle du bucket, l'entrée de journal est stockée dans le bucket de journaux où la métrique basée sur les journaux est définie.
- Pour les métriques à l'échelle du projet, l'entrée de journal transite par les collecteurs de journaux du projet dans lequel la métrique basée sur les journaux est définie.
Pour en savoir plus, consultez la présentation des métriques basées sur les journaux.
Bonnes pratiques
Pour connaître les bonnes pratiques d'utilisation du routage pour la gouvernance des données ou pour les cas d'utilisation courants, consultez les documents suivants :
Données de journaux: guide par étapes pour résoudre les problèmes de conformité courants
Gouvernance des données : principes de sécurisation et de gestion des journaux
Exemples : centraliser le stockage de vos journaux
Cette section explique comment configurer un stockage centralisé. Le stockage centralisé fournit un emplacement unique pour interroger les données de journaux, ce qui simplifie vos requêtes lorsque vous recherchez des tendances ou examinez des problèmes. Du point de vue de la sécurité, vous ne disposez que d'un seul emplacement de stockage, ce qui peut simplifier les tâches de vos analystes de sécurité.
Si vous centralisez le stockage de vos journaux, réfléchissez à l'opportunité de placer un blocage sur le projet qui stocke vos données de journaux. Un privilège peut empêcher la suppression accidentelle d'un projet. Pour en savoir plus, consultez Protéger les projets à l'aide de privilèges.
Centraliser le stockage des journaux pour les projets d'un dossier
Supposons que vous gérez un dossier et que vous souhaitez centraliser le stockage de vos entrées de journal. Dans ce cas d'utilisation, vous pouvez procéder comme suit :
- Dans votre dossier, créez un projet nommé
CentralStorage. - Créez un récepteur agrégé d'interception pour votre dossier et configurez-le pour acheminer toutes les entrées de journal. Vous définissez la destination du récepteur sur le projet nommé
CentralStorage.
Lorsqu'une entrée de journal provenant du dossier ou de l'une de ses ressources enfants arrive, elle est envoyée au récepteur agrégé d'interception que vous avez créé. Ce récepteur achemine les entrées de journal vers le projet nommé CentralStorage. Les récepteurs de journaux de ce projet traitent les entrées de journal :
Le récepteur de journaux
_Defaultachemine vers le bucket de journaux_Defaulttoutes les entrées de journal qui correspondent au filtre du récepteur. Ce bucket de journaux est votre emplacement de stockage centralisé.Le récepteur de journaux
_Requiredachemine vers le bucket de journaux_Requiredles entrées de journal qui correspondent aux filtres du récepteur et qui proviennent du projetCentralStorage. Ce bucket de journaux n'est pas un emplacement de stockage centralisé. Toutefois, vous pouvez stocker de manière centralisée toutes vos données de journaux. Pour obtenir un exemple, consultez Stocker les journaux d'audit dans un emplacement centralisé.
Une fois le traitement du récepteur agrégé terminé, l'entrée de journal est envoyée au récepteur de journaux _Required dans la ressource à partir de laquelle l'entrée de journal a été générée. Lorsque l'entrée de journal correspond au filtre du récepteur de journaux _Required, elle est acheminée vers le bucket de journaux _Required de la ressource. Par conséquent, chaque projet Google Cloud de votre dossier stocke les entrées de journal dans son bucket de journaux_Required.
Centraliser le stockage des journaux pour un ensemble de projets
Vous pouvez également stocker les entrées de journal dans un emplacement unique lorsque vous n'avez pas d'organisation ni de dossier. Par exemple, vous pouvez effectuer les opérations suivantes :
- Créez un projet nommé
CentralStorage. - Pour chaque projet, à l'exception de
CentralStorage, modifiez le collecteur de journaux_Defaultet définissez la destination sur le projet nomméCentralStorage.
Vous vous demandez peut-être pourquoi l'exemple précédent définit la destination des récepteurs de journaux _Default sur un projet, au lieu du bucket de journaux _Default de ce projet. Les principales raisons sont la simplicité et la cohérence.
Lorsque vous acheminez des entrées de journal vers un projet, les récepteurs de journaux du projet de destination contrôlent les entrées de journal stockées et leur emplacement.
En d'autres termes, vous centralisez les fonctionnalités de filtre et de destination. Si vous souhaitez modifier les entrées de journal stockées ou leur emplacement de stockage, il vous suffit de modifier les récepteurs de journaux dans un seul projet.
Centraliser le stockage des journaux d'audit
Vous pouvez stocker de manière centralisée les entrées de journal qui correspondent au récepteur de journaux _Required. Si vous souhaitez stocker ces entrées de journal de manière centralisée, effectuez l'une des opérations suivantes :
Créez des récepteurs de journaux qui acheminent les entrées de journal correspondant au récepteur de journaux
_Requiredvers un bucket de journaux centralisé.Configurez des récepteurs de journaux comme dans les deux exemples précédents, puis ajoutez un récepteur de journaux dans le projet de destination qui achemine les entrées de journaux correspondant au récepteur de journaux
_Requiredvers un bucket de journaux. Vous pouvez également modifier les filtres dans le récepteur de journaux_Default.
Avant d'implémenter une telle stratégie, consultez les consignes relatives aux prix.
Tarifs
Pour en savoir plus sur les tarifs de Cloud Logging, consultez la page Tarifs de Google Cloud Observability.
Étapes suivantes
Pour vous aider à acheminer et à stocker les données Cloud Logging, consultez les documents suivants :
Pour créer des récepteurs afin d'acheminer les entrées de journal vers des destinations compatibles, consultez la section Acheminer les journaux vers des destinations compatibles.
Pour savoir comment créer des récepteurs agrégés capables d'acheminer les entrées de journal à partir des ressources dans des dossiers ou des organisations, consultez Présentation des récepteurs agrégés.
Pour en savoir plus sur le format des entrées de journal acheminées et sur l'organisation des journaux dans les destinations, consultez les documents suivants :