Questa pagina descrive come registrare i dati utente con l'API Consent Management.
Gli elementi di dati vengono registrati con l'API Consent Management e collegati ai consensi utilizzando i mapping dei dati utente. I dati utente non vengono mai archiviati nell'API Consent Management.
I mapping dei dati utente, rappresentati come risorse UserDataMappings, includono i seguenti elementi:
- Un ID utente che identifica l'utente. Questo ID corrisponde all'ID che l'applicazione ha fornito all'API Consent Management durante la registrazione del consenso.
- Un ID dati che identifica i dati utente archiviati altrove, ad esempio su Google Cloud o on-premise. L'ID dati può essere un ID opaco, un URL o qualsiasi altro identificatore.
- Attributi delle risorse, che descrivono le caratteristiche dei dati utente utilizzando
valori degli attributi delle risorse configurati per l'archivio del consenso utilizzando definizioni
degli attributi. Ad esempio, i dati potrebbero includere
attribute_definition_iddata_identifiablecon il valorede-identified.
Il seguente diagramma mostra il flusso di dati per la creazione di mappature dei dati utente:
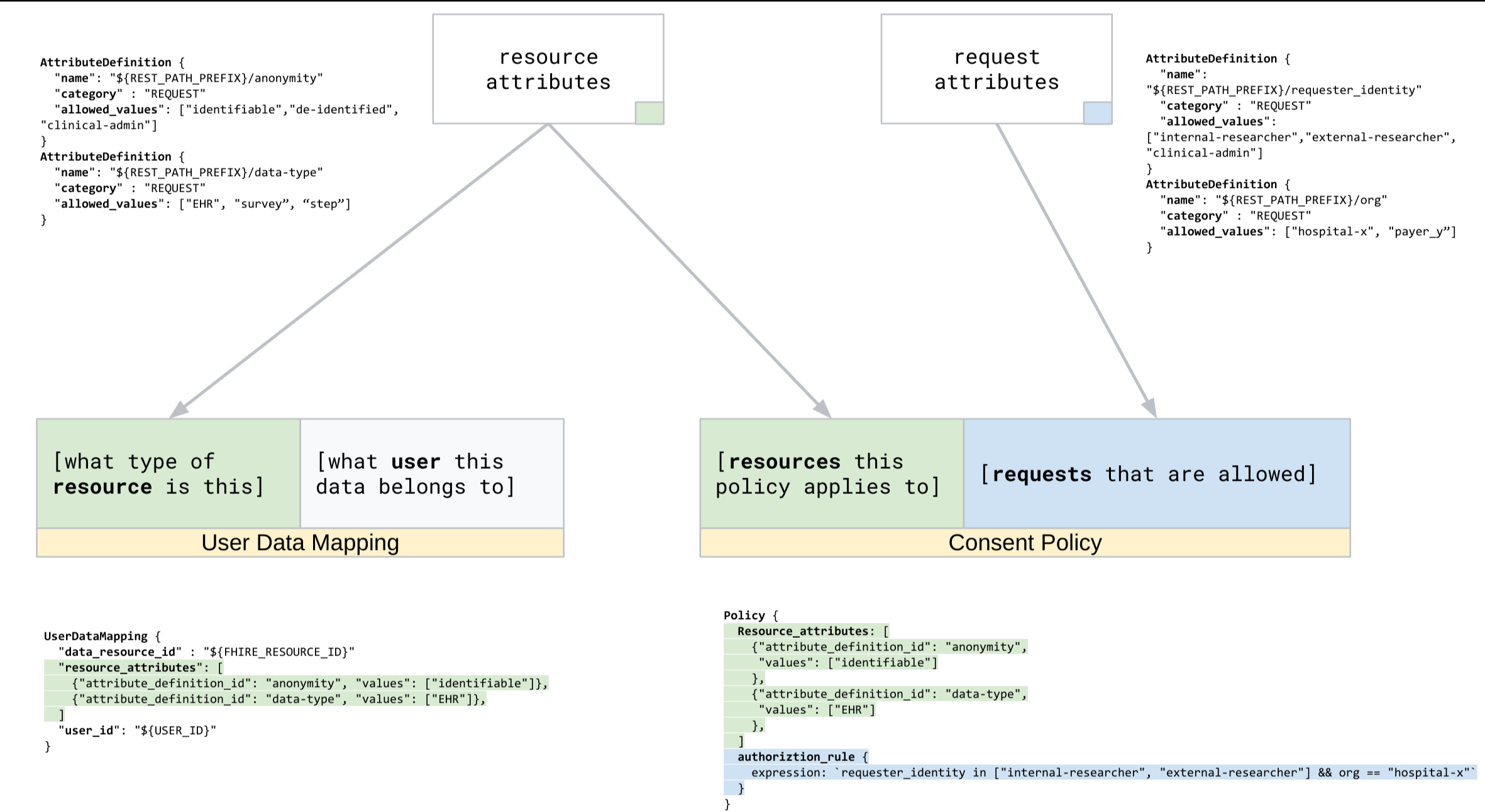
Registrazione delle mappature dei dati utente
Per creare una mappatura dei dati utente, utilizza il
metodo
projects.locations.datasets.consentStores.userDataMappings.create. Invia una richiesta POST e specifica le seguenti informazioni nella
richiesta:
- Il nome dello store per il consenso dei genitori
- Un
userIDunivoco e opaco che rappresenta l'utente a cui è associato l'elemento di dati - Un identificatore per la risorsa di dati utente, ad esempio il percorso REST a una risorsa univoca
- Un insieme di attributi
RESOURCEche descrivono l'elemento di dati - Un token di accesso
curl
Il seguente esempio mostra una richiesta POST mediante curl:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \ -H "Content-Type: application/consent+json; charset=utf-8" \ --data "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" \ "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings"
Se la richiesta riesce, il server restituisce una risposta simile a quella dell'esempio seguente in formato JSON:
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
PowerShell
Il seguente esempio mostra una richiesta POST mediante Windows PowerShell:
$cred = gcloud auth application-default print-access-token $headers = @{ Authorization = "Bearer $cred" } Invoke-WebRequest ` -Method Post ` -Headers $headers ` -ContentType: "application/consent+json; charset=utf-8" ` -Body "{ 'user_id': 'USER_ID', 'data_id' : 'DATA_ID', 'resource_attributes': [{ 'attribute_definition_id': 'data_identifiable', 'values': ['de-identified'] }] }" ` -Uri "https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings" | Select-Object -Expand Content
Se la richiesta riesce, il server restituisce una risposta simile a quella dell'esempio seguente in formato JSON:
{
"name": "projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/consentStores/CONSENT_STORE_ID/userDataMappings/USER_DATA_MAPPING_ID",
"dataId": "DATA_ID",
"userId": "USER_ID",
"resourceAttributes": [
{
"attributeDefinitionId": "data_identifiable",
"values": [
"de-identified"
]
}
]
}
Configurazione degli ID dati
Il campo data_id della risorsa di mappatura dei dati utente contiene una
stringa specificata dal cliente che descrive i dati a cui fa riferimento la risorsa di mappatura dei dati utente. È consentita qualsiasi stringa, ad esempio un ID o un URI opaco.
Gli ID dati possono essere granulari quanto richiesto dalla tua applicazione. Se
i dati che stai registrando possono essere descritti a livello di
tabella o bucket, definisci data_id come percorso REST alla risorsa.
Se i dati che stai registrando richiedono una maggiore granularità,
potresti voler specificare righe o celle specifiche. Se la tua applicazione utilizza risorse concettuali, come azioni consentite o classi di dati, devi
definire data_id con una convenzione che supporti questi casi d'uso.
Di seguito sono riportati, a titolo esemplificativo, alcuni esempi di data_id che descrivono i dati archiviati in servizi diversi e a vari livelli di granularità:
Oggetto Google Cloud Storage
'data_id' : 'gs://BUCKET_NAME/OBJECT_NAME'
Oggetto Amazon S3
'data_id' : 'https://BUCKET_NAME.s3.REGION.amazonaws.com/OBJECT_NAME'
Tabella BigQuery
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID'
Riga BigQuery (non esiste un percorso REST per una riga BigQuery, quindi è necessario un identificatore personalizzato. Di seguito è riportato un possibile approccio)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID'
Cella BigQuery (non esiste un percorso REST per una cella BigQuery, quindi è necessario un identificatore personalizzato. Di seguito è riportato un possibile approccio)
'data_id' : 'bigquery/v2/projects/PROJECT_ID/datasets/DATASET_ID/tables/TABLE_ID/myRows/ROW_ID/myColumns/COLUMN_ID'
Risorsa FHIR
'data_id' : 'https://healthcare.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/datasets/DATASET_ID/fhirStores/FHIR_STORE_ID/fhir/Patient/PATIENT_ID'
Rappresentazione concettuale
'data_id' : 'wearables/fitness/step_count/daily_sum'