開始使用媒體推薦內容
您可以迅速建構最先進的媒體推薦應用程式。媒體推薦功能可讓目標對象發掘更貼近個人需求的內容 (例如 YouTube 推薦內容或接下來要看的內容),以及根據最佳化目標自訂、品質媲美 Google 的結果。
如需 Vertex AI Search for media 的一般資訊,請參閱「媒體搜尋和推薦簡介」。在這個入門教學課程中,您將使用 Movielens 資料集,示範如何將媒體內容目錄和使用者事件上傳至 Vertex AI Search,並訓練個人化電影推薦模型。Movielens 資料集含有電影 (文件) 和使用者電影評分 (使用者事件) 的目錄。
在這個教學課程中,您會訓練已針對點閱率最佳化的「您可能喜歡的其他項目」類型推薦模型。訓練完成後,模型可以根據使用者 ID 和種子電影推薦電影。
為符合模型最低資料門檻,系統會將每部正面電影評分 (4 分以上) 視為觀看項目事件。
完成本教學課程的預估時間:
如果您已完成「Get started with media search」教學課程,而且仍保留資料儲存庫 (建議名稱 quickstart-media-data-store),您可以使用該資料儲存庫,不必另外建立一個。在這種情況下,建議您先從本教學課程的「建立用於媒體推薦的應用程式」步驟著手。
目標
- 瞭解如何將 BigQuery 中的媒體文件和使用者事件資料匯入 Vertex AI Search。
- 訓練及評估推薦模型。
按照本教學課程操作前,請確認您已完成「事前準備」部分的步驟。
如要直接在 Google Cloud 控制台按照逐步指南操作,請按一下「Guide me」(逐步引導):
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
前往「IAM」頁面 - 選取專案。
- 按一下「授予存取權」。
-
在「New principals」(新增主體) 欄位中,輸入您的使用者 ID。 這通常是 Google 帳戶的電子郵件地址。
- 在「Select a role」(選取角色) 清單中,選取角色。
- 如要授予其他角色,請按一下 「新增其他角色」,然後新增每個其他角色。
- 按一下 [Save]。
-
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI Search (Discovery Engine), Cloud Storage, BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Make sure that you have the following role or roles on the project: Discovery Engine Admin
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
前往「IAM」頁面 - 選取專案。
- 按一下「授予存取權」。
-
在「New principals」(新增主體) 欄位中,輸入您的使用者 ID。 這通常是 Google 帳戶的電子郵件地址。
- 在「Select a role」(選取角色) 清單中,選取角色。
- 如要授予其他角色,請按一下 「新增其他角色」,然後新增每個其他角色。
- 按一下 [Save]。
-
- 開啟 Google Cloud 控制台。
- 選取 Google Cloud 專案。
- 記下資訊主頁頁面「專案資訊」資訊卡中的專案 ID。您需要專案 ID 才能執行下列程序。
按一下主控台視窗頂端的「Activate Cloud Shell」(啟用 Cloud Shell) 按鈕。 系統會在Google Cloud 控制台底部的新頁框中開啟 Cloud Shell 工作階段,並顯示指令列提示。請參閱「啟動 Cloud Shell」,瞭解啟動 Cloud Shell 的其他方式。

使用專案 ID 執行以下指令,設定指令列的預設專案。
gcloud config set project PROJECT_ID建立 BigQuery 資料集
bq mk movielens將
movies.csv載入新的moviesBigQuery 資料表:bq load --skip_leading_rows=1 movielens.movies \ gs://cloud-samples-data/gen-app-builder/media-recommendations/movies.csv \ movieId:integer,title,genres將
ratings.csv載入新的ratingsBigQuery 資料表:bq load --skip_leading_rows=1 movielens.ratings \ gs://cloud-samples-data/gen-app-builder/media-recommendations/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp建立 view,將電影資料表轉換為 Google 定義的
Document結構定義:bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`) SELECT id, "default_schema" as schemaId, null as parentDocumentId, TO_JSON_STRING(STRUCT(title as title, categories as categories, CONCAT("http://mytestdomain.movie/content/", id) as uri, "2023-01-01T00:00:00Z" as available_time, "2033-01-01T00:00:00Z" as expire_time, "movie" as media_type)) as jsonData FROM t;' \ movielens.movies_view現在新的檢視表已採用 Discovery Engine API 預期的結構定義。
前往 Google Cloud 控制台的「BigQuery」頁面。
在「Explorer」窗格中展開專案名稱,展開「
movielens」資料集,然後點選「movies_view」開啟這個 view 的查詢頁面
前往「Table Explorer」(資料表探索工具) 分頁。
在「Generated query」(產生的查詢) 窗格中,按一下「Copy to query」(複製到查詢) 按鈕。查詢編輯器隨即開啟。
按一下「Run」(執行),在您建立的 view 中查看電影資料。
執行下列 Cloud Shell 指令,根據電影評分建立虛構的使用者事件:
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS userPseudoId, "view-item" AS eventType, FORMAT_TIMESTAMP("%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(movieId AS id, null AS name)] AS documents, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4;' \ movielens.user_events前往 Google Cloud 控制台的「AI Applications」頁面。
選用:點選「Allow Google to selectively sample model input and responses」(允許 Google 對模型輸入內容和回覆進行選擇性取樣)。
點選「Continue and activate the API」。
前往 Google Cloud 控制台的「AI Applications」頁面。
點按
「Create app」(建立應用程式) 。在「Create app」(建立應用程式) 頁面,點選「Media recommendations」(媒體推薦) 下方的「Create」(建立)。
在「App name」(應用程式名稱) 欄位輸入應用程式的名稱,例如
quickstart-media-recommendations。應用程式 ID 會顯示在應用程式名稱下方。在「Recommendations type」(推薦類型) 下方,確定已選取「Others you may like」(您可能會喜歡的其他項目)。
在「Business Objective」(業務目標) 下方,確認已選取「Click-through rate (CTR)」(點閱率)。
點選「Continue」(繼續)。
建立資料儲存庫。
在「Data stores」(資料儲存庫) 頁面,點選「Create data store」(建立資料儲存庫)。
輸入資料儲存庫的顯示名稱 (例如
quickstart-media-data-store),然後點選「Create」(建立)。
選取剛建立的資料儲存庫,然後按一下「Create」(建立),以建立應用程式。
在「Import documents」(匯入文件) 頁面,選取「Native sources」(原生來源) 下方的「BigQuery」。
輸入您建立的
moviesBigQuery view 名稱,然後點選「Import」(匯入)。PROJECT_ID.movielens.movies_view等待所有文件都匯入完成,大約需要 15 分鐘。完成後應該有 86537 份文件。
您可以透過「Activity」(活動) 分頁查看匯入作業狀態。匯入完成後,匯入作業狀態會變更為「Completed」(已完成)。
在「Events」(事件) 分頁,點選「Import Events」(匯入事件)。
在「Import documents」(匯入文件) 頁面,選取「Native sources」(原生來源) 下方的「BigQuery」。
輸入您建立的
user_eventsBigQuery view 名稱,然後點選「Import」(匯入)。PROJECT_ID.movielens.user_events請等到至少匯入一百萬個事件後再繼續下一個步驟,以便符合訓練新模型的資料要求。
您可以在「Activity」(活動) 分頁中查看作業狀態。由於您會匯入數百萬列的資料,這項程序大約需要一小時才能完成。
為確認是否符合規定,請依序點選「Data quality」(資料品質) >「Requirements」(要求) 分頁標籤。即便已匯入使用者事件,「Requirements」(要求) 分頁可能需要一段時間,才會將狀態更新為「Data requirements met」(符合資料要求)。
前往「Configurations」(設定) 頁面。
按一下「Serving」(供應) 分頁標籤。供應設定已建立。
如要調整「Recommendation demotion」(降低推薦的排名) 或「Result diversification」(結果多樣化) 設定,您可以在這個網頁進行操作
按一下「Training」(訓練) 標籤。
只要達到資料要求,系統就會自動開始訓練模型。您可以在這個頁面查看訓練和調整狀態。
模型可能需要幾天才能訓練完成並準備好接受查詢。程序完成時,「Ready to query」(可接受查詢) 欄位會顯示「Yes」(是)。您需要重新整理頁面,才能看到「No」(否) 變更為「Yes」(是)。
在導覽選單中,按一下
「Preview」(預覽) 。按一下「Document ID」(文件 ID) 欄位。畫面上就會顯示文件 ID 清單。
輸入種子文件 (電影) ID,例如
4993可以代表「魔戒首部曲:魔戒現身 (2001)」。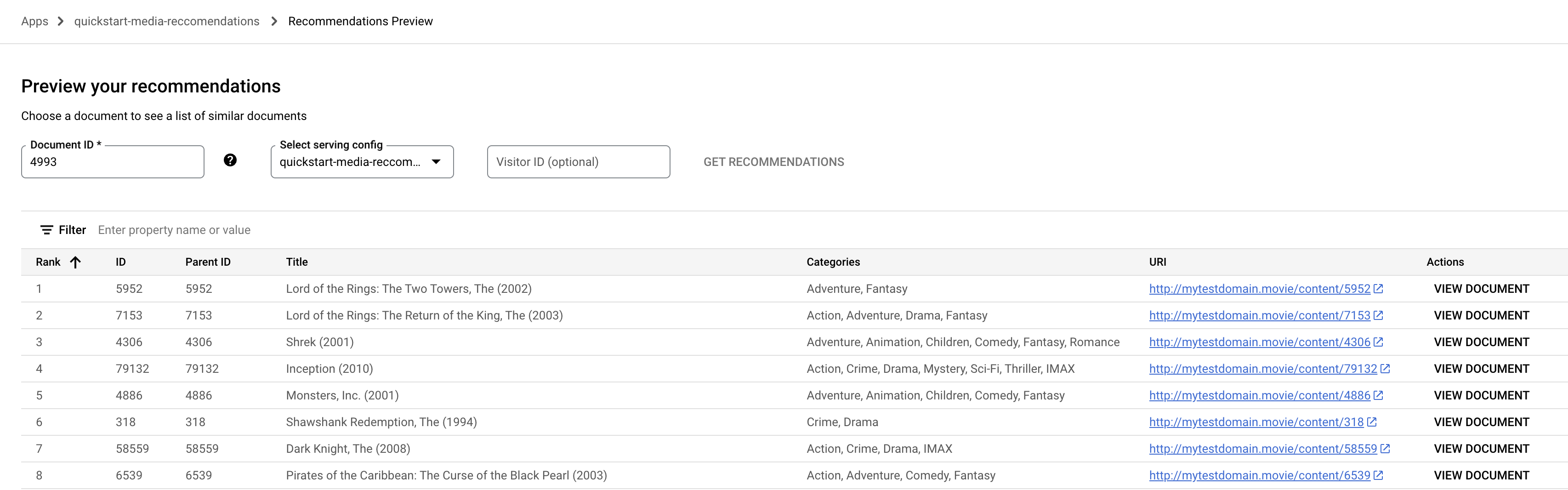
從下拉式選單中選取「Serving config」(供應設定) 名稱。
按一下「Get recommendations」(推薦內容)。畫面上就會顯示建議的文件清單。
前往「Data」(資料) 頁面和「Documents」(文件) 分頁,複製文件「ID」。
前往「Integration」(整合) 頁面。本頁提供 REST API「
servingConfigs.recommend」方法的範例指令。將您稍早複製的文件 ID 貼入「Document ID」(文件 ID) 欄位。
「User Pseudo ID」(使用者虛擬 ID) 欄位維持不變。
複製範例要求,並在 Cloud Shell 中執行。
- 請透過Google Cloud console 刪除不需要的專案,以免產生不必要的 Google Cloud 費用。
- 如果您是為了瞭解 Vertex AI Search 而建立新專案,但現在已不再需要,請刪除專案。
- 如果您使用現有的 Google Cloud 專案,請刪除稍早建立的資源,以免系統向您的帳戶收取費用。如要瞭解詳情,請參閱刪除應用程式的相關說明。
- 按照「關閉 Vertex AI Search」一文中的步驟操作。
如果您建立了 BigQuery 資料集,請在 Cloud Shell 中刪除該資料集:
bq rm --recursive --dataset movielens
準備資料集
您將使用 Cloud Shell 匯入 Movielens 資料集,並為 Vertex AI Search for Media 重新建構資料集。
開啟 Cloud Shell
匯入資料集
Movielens 資料集會存放在公開的 Cloud Storage bucket 中,讓您輕鬆匯入。
建立 BigQuery 檢視表
在這個步驟中,您會重新建構 Movielens 資料集,使其符合媒體推薦的預期格式。
媒體推薦需要使用者事件資料才能建立模型。在本指南中,您會根據正面評分 (>= 4) 建立過去 90 天內的 view-item 假事件。
啟用 Vertex AI Search
建立用於媒體推薦的應用程式
本節所述程序會引導您建立及部署媒體推薦應用程式。
匯入資料
接下來,請匯入先前已設定格式的電影和使用者事件資料。
匯入文件
將在「建立 BigQuery view」部分建立的 movies_view 文件匯入 quickstart-media-data-store 資料儲存庫。
匯入使用者事件
將在「建立 BigQuery view」部分建立的 user_events 記錄匯入資料儲存庫。
訓練推薦模型
預覽建議內容
模型準備好查詢後,請執行以下操作:
針對結構化資料部署您的應用程式
目前沒有可用於部署應用程式的建議小工具。部署前,如要先測試應用程式,請按照下列步驟操作:
如需協助將推薦應用程式整合至網頁應用程式,請參閱「取得媒體推薦內容」一文中的程式碼範例。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本頁所用資源的費用,請按照下列步驟操作。
在「開始使用媒體搜尋」教學課程中,您可以重複使用為媒體搜尋建立的資料儲存庫。請先嘗試進行該教學課程,再執行這項清除程序。