FHIR R4 데이터를 의료 검색 앱으로 가져온 후 가져온 데이터를 쿼리하여 관련 결과를 가져올 수 있습니다. 다음 유형의 검색어를 사용하여 검색할 수 있습니다.
- 키워드 검색어
- 자연어 쿼리
- 생성형 AI 답변이 포함된 자연어 검색어
또한 날짜 필터링 검색어를 사용하여 검색을 필터링할 수 있습니다. 자세한 내용은 resource_datetime 필터 정의를 참조하세요.
Google Cloud 콘솔에서 검색할 때는 먼저 환자 ID를 입력하고 한 번에 환자 한 명 데이터를 검색해야 합니다. REST API를 사용하여 검색하면 전체 데이터 스토어를 검색할 수 있습니다.
이 페이지에서는 다양한 유형의 검색어를 사용하여 의료 데이터를 검색하는 방법을 보여줍니다.
의료 데이터 검색에 Vertex AI Search를 사용하는 목적
Vertex AI Search의 용도는 질병이나 질환의 예방, 진단 또는 치료와 관련된 정보를 제공하는 것이 아닙니다. 진단 또는 치료 추천과 관련된 질문을 다루기 위해 만들어진 제품이 아닙니다. 이 제품의 용도는 사용자가 제공한 기존 의료 정보를 검색하고 요약하는 것입니다.
테스트 데이터가 제한되어 있으므로 0~18세 및 85세 이상의 연령대에는 이 제품이 적용되지 않을 수도 있습니다. 따라서 고객은 생성된 출력을 검토할 때 소스 데이터 내 하위 집단의 대표성을 고려해야 합니다.
다음은 이 제품의 용도에 대한 몇 가지 예시입니다.
주제와 관련된 환자 정보를 찾기 위한 탐색 검색어:
- '아스피린 사용 요약'
- '혈압'
- '당뇨병 관리?'
정형 검색어에 매핑할 수 있는 특정 리소스를 찾는 탐색 검색어:
- '가장 최근 a1c 수치 보여 줘'
증거가 리소스 전체에 흩어져 있을 수 있는 특정 질문에 답하는 추출 질문 및 답변:
- '이 환자가 세팔로스포린으로 치료받은 적이 있나요?'
- '환자가 정신과 평가를 받은 적이 있나요?'
다음은 이 제품의 용도가 아닌 방법의 예시입니다.
진단 권장사항 및 치료 권장사항:
- '이 환자의 감별 진단은 무엇인가요?'
- '환자에게 어떤 약을 처방해야 하나요?'
질문 가이드라인
다음 가이드라인은 더 나은 검색 결과를 제공할 수 있는 쿼리를 구성하는 데 도움이 됩니다.
특정 의도가 있는 질문 검색: 모델은 사용자가 무엇을 찾고 있는지 모르므로 모호한 질문보다는 타겟팅된 질문을 제공하는 것이 좋습니다. 예를 들어 '요약'이라는 키워드를 검색하는 것보다 '고혈압'이라는 키워드를 검색하는 것이 좋습니다. '고혈압'이라는 질문을 하면 관련 문서의 구체적인 결과가 표시되지만 '요약'이라는 질문을 하면 관련이 없는 문서의 결과가 표시될 수 있습니다.
문맥 유지: 검색은 대화형이 아니므로 각 질문에 대한 전체 문맥을 제공하는 것이 좋습니다. 예를 들어 초기 질문이 '고혈압'이고 동일한 주제를 후속 질문하고 싶다면 '고혈압은 언제 진단받았어?'가 '그것은 언제 진단받았어?'보다 더 나은 두 번째 질문입니다.
쿼리 간소화: 가능하면 복잡한 쿼리를 더 간단한 쿼리로 분할합니다. 예를 들어 '크레아티닌 및 알부민'을 검색하는 대신 목표에 따라 '크레아티닌', '알부민', '크레아티닌 알부민 비율'에 대한 다양한 검색어를 만드세요.
추론 요청 피하기: 모델이 검색된 정보에서 계산하거나 추론하는 대신 검색된 문서에서 정보를 그대로 반환할 수 있으면 검색에서 더 정확한 결과를 제공합니다. 예를 들어 '환자 체중이 얼마나 변했어?'라고 묻는 대신 '최근 10번의 방문에서 환자 체중을 나열해 줘'라고 물은 다음 체중 변화를 별도로 계산할 수 있습니다.
결과에서 일치 항목 강조 표시
일치 강조 표시는 검색 결과에서 검색어와 문맥상 일치하는 텍스트 부분을 강조 표시하는 구성입니다.
다음 리소스 유형의 결과는 일치 강조 표시를 지원합니다.
- 구성:
Composition.section[].text.div필드의 컨텍스트 텍스트를 강조 표시합니다. - DiagnosticReport:
DiagnosticReport.conclusion필드의 컨텍스트 텍스트를 강조 표시합니다. DocumentReference:
DocumentReference.content[0].attachment.url필드에서 참조된 문서의 맥락에 맞는 텍스트를 강조 표시합니다. 강조 표시된 텍스트가 경계 상자 안에 있습니다. 경계 상자는 검색 응답에서 정규화된 좌표 두 집합으로 표현됩니다. 일치 항목 강조 표시를 지원하는 문서는 PDF 파일과 지원되는 유형의 이미지 파일입니다. 다음 이미지는 DocumentReference 리소스 유형에서 스캔한 문서에서 텍스트가 강조 표시되는 방식을 보여줍니다.
그림 1. 스캔한 DocumentReference 문서에서 강조 표시를 일치시킵니다.
REST API를 사용하여 검색할 때는 matchHighlightingCondition 필드를 사용하여 검색 요청에서 일치 항목 강조 표시를 사용 설정해야 합니다.
응답에는 검색 애플리케이션에서 강조 표시된 텍스트를 렌더링하는 데 사용할 수 있는 match_highlighting 필드가 포함됩니다.
- Composition 및 DiagnosticReport 문서의 경우
match_highlighting필드에는 강조 표시해야 하는 토큰의 시작 및 종료 색인이 포함됩니다. - DocumentReference 문서의 경우
match_highlighting필드에 텍스트를 강조 표시하는 경계 상자의 좌표가 포함됩니다. 경계 상자는 문서의 왼쪽 상단 모서리에 원점이 있는 두 세트의 정규화된 좌표로 표시됩니다. 이 필드는 이미지의 경우0로, PDF 파일의 첫 페이지의 경우1로 설정된page_number필드도 중첩합니다.
Google Cloud 콘솔을 사용하여 검색 결과를 미리 볼 때 일치 항목 강조 표시가 기본적으로 사용 설정됩니다.
시작하기 전에
검색하기 전에 다음을 수행합니다.
- 의료 검색 앱과 의료 검색 데이터 스토어를 만들고 FHIR R4 데이터를 가져옵니다. 자세한 내용은 의료 검색 앱 만들기 및 의료 검색 데이터 스토어 만들기를 참조하세요.
- 의료 데이터 검색 결과를 구성합니다.
- 검색할 때 유용한 검색어 추천 용어를 받으려면 자동 완성을 사용 설정합니다. 이 기능은 미리보기 기능입니다.
- Vertex AI Search에서 지원하는 FHIR R4 리소스 목록을 검토합니다. 자세한 내용은 의료 FHIR R4 데이터 스키마 참조를 참조하세요.
키워드를 사용하여 검색
키워드를 사용하여 의료 데이터 스토어를 검색할 수 있습니다. 예를 들어 'a1c', '인슐린' 또는 '궤양'과 같은 키워드를 사용하여 검색해 관련 FHIR 리소스를 가져올 수 있습니다.
다음 이미지에서는 키워드가 '지질'인 경우의 검색 결과를 보여줍니다. 이 예시에는 요약이나 생성형 AI 답변이 포함되지 않습니다.
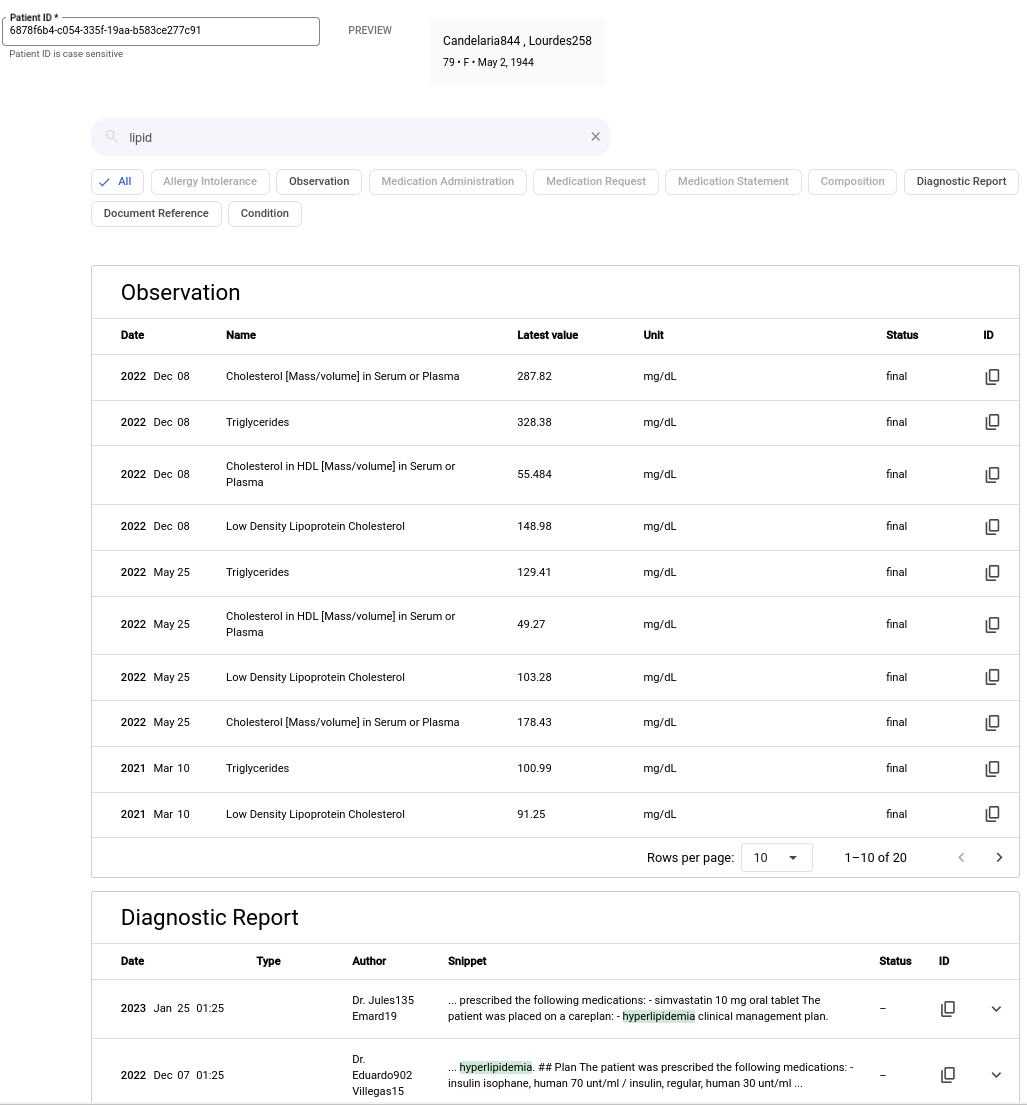
키워드를 사용하여 검색하려면 다음 단계를 완료합니다.
콘솔
Google Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
쿼리할 의료 검색 앱을 선택합니다.
탐색 메뉴에서 미리보기를 클릭합니다.
환자 ID 필드에 데이터를 쿼리하려는 환자의 ID를 입력합니다. 환자 ID는 대소문자를 구분합니다.
Enter 키를 누르거나 미리보기를 클릭하여 환자 ID를 제출합니다.
여기에서 검색 검색창에 검색할 키워드를 입력합니다.
자동 완성을 사용 설정한 경우 입력할 때 검색창 아래에 자동 완성 추천 용어가 표시됩니다.
Enter 키를 눌러 검색어를 제출합니다.
- 검색 결과는 FHIR 리소스 유형에 따라 분류된 페이지가 지정된 테이블에 표시됩니다.
- 기본적으로 모든 FHIR 리소스 유형의 검색 결과는 시간 역순으로 표시됩니다.
선택사항. 결과를 필터링하려면 검색창 아래에 있는 FHIR 리소스 카테고리를 하나 이상 선택합니다.
선택사항. Composition, DocumentReference, DiagnosticReport 리소스 관련성에 따라 결과를 정렬하려면 정렬: 시간 역순 필터를 클릭하고 목록에서 관련성을 선택합니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
REST
다음 샘플에서는 키워드를 사용하여 의료 검색 앱에서 환자 1명의 FHIR R4 데이터를 검색하는 방법을 보여줍니다. 이 샘플에서는 servingConfigs.search 메서드를 사용합니다.
기본적으로 검색 결과는 시간 역순으로 반환됩니다. Composition, DiagnosticReport, DocumentReference 리소스를 검색할 때 관련성에 따라 검색 결과를 정렬할 수 있습니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
키워드를 사용하여 검색합니다.
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "KEYWORD_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}} "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'다음을 바꿉니다.
PROJECT_ID: Google Cloud 프로젝트의 ID입니다.APP_ID: 쿼리할 Vertex AI Search 앱의 ID입니다.KEYWORD_QUERY: 필터링된 환자의 환자 임상 데이터에서 검색하려는 키워드입니다(예: '당뇨' 또는 'a1c').PATIENT_ID: 데이터를 검색하려는 환자의 리소스 ID입니다.MATCH_HIGHLIGHTING_CONDITION: 다음 값을 가질 수 있는 문자열입니다.MATCH_HIGHLIGHTING_DISABLED: 모든 문서에서 일치 강조 표시를 사용 중지합니다.MATCH_HIGHLIGHTING_ENABLED: 모든 문서에서 일치 강조 표시를 사용 설정합니다. 이 필드를 비워 두거나 지정하지 않으면 일치 항목 강조 표시가MATCH_HIGHLIGHTING_DISABLED로 설정되고 모든 문서에서 사용 중지됩니다.
자연어 검색어를 사용하여 검색
Vertex AI Search를 사용하면 복잡한 자연어 검색어 결과를 얻을 수 있습니다. 예를 들어 다음 이미지에서는 '당뇨와 관련된 실험실 결과'라는 자연어 검색어 결과를 보여줍니다.
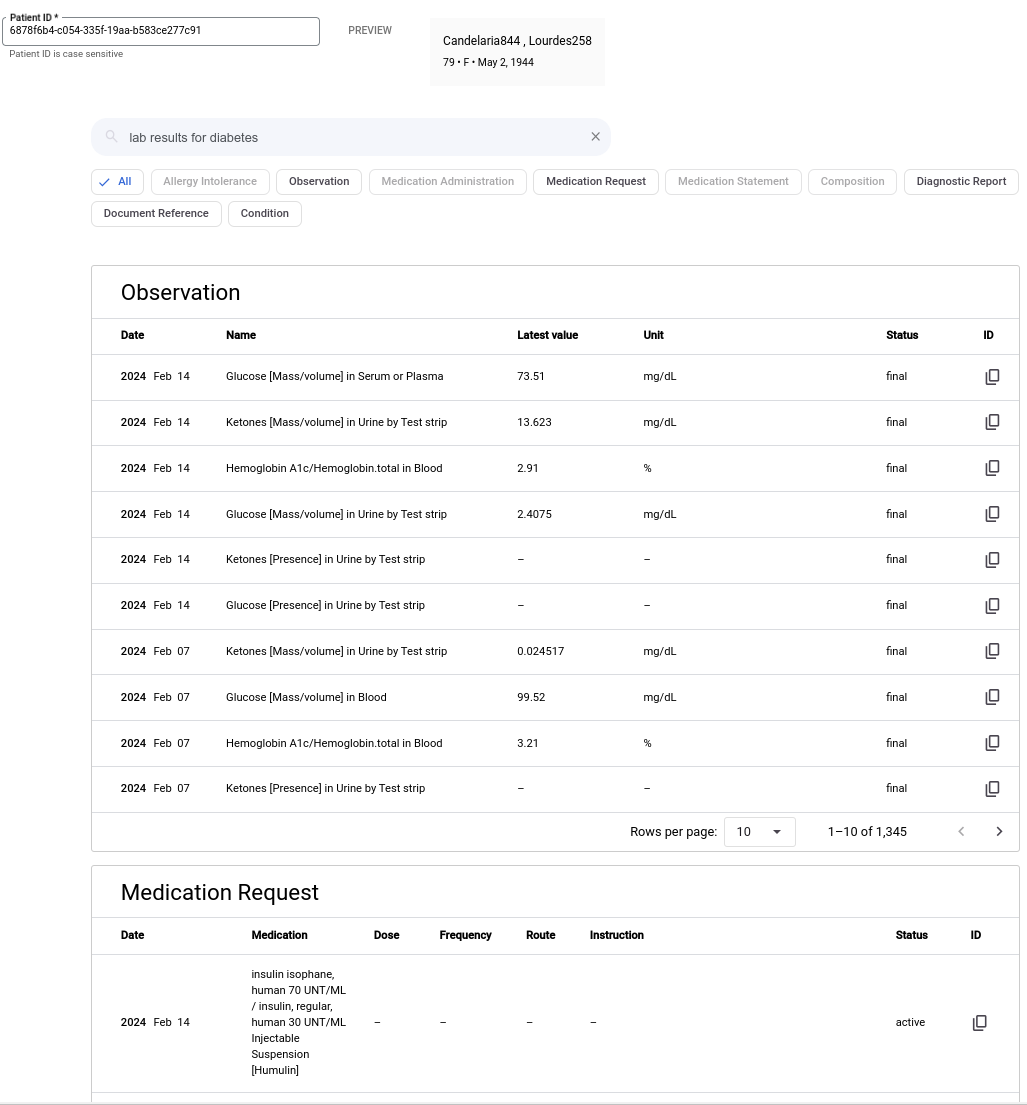
자연어 검색어를 사용하여 검색하려면 다음 단계를 완료합니다.
콘솔
Google Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
쿼리할 의료 검색 앱을 선택합니다.
탐색 메뉴에서 미리보기를 클릭합니다.
환자 ID 필드에 데이터를 쿼리하려는 환자의 환자 ID를 입력합니다. 환자 ID는 대소문자를 구분합니다.
Enter 키를 누르거나 미리보기를 클릭하여 환자 ID를 제출합니다.
여기에서 검색 검색창에 '당뇨와 관련된 실험실 결과'와 같은 자연어 검색어를 입력합니다.
자동 완성을 사용 설정한 경우 입력할 때 검색창 아래에 자동 완성 추천 용어가 표시됩니다.
Enter 키를 눌러 검색어를 제출합니다.
- 검색 결과는 FHIR 리소스 유형에 따라 분류된 페이지가 지정된 테이블에 표시됩니다.
- 기본적으로 모든 FHIR 리소스 유형의 검색 결과는 시간 역순으로 표시됩니다.
선택사항. 검색창 아래에 있는 FHIR 리소스 카테고리를 하나 이상 선택하여 결과를 필터링합니다.
선택사항. Composition, DocumentReference, DiagnosticReport 리소스 관련성에 따라 결과를 정렬하려면 정렬: 시간 역순 필터를 클릭하고 목록에서 관련성을 선택합니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
REST
다음 샘플에서는 자연어 검색어를 사용하여 의료 검색 앱에서 환자 1명의 FHIR R4 데이터를 검색하는 방법을 보여줍니다. 이 샘플에서는 servingConfigs.search 메서드를 사용합니다. 자연어 검색어를 사용하여 검색하려면 naturalLanguageQueryUnderstandingSpec 필드를 요청 본문에 추가해야 합니다.
기본적으로 검색 결과는 시간 역순으로 반환됩니다. Composition, DiagnosticReport, DocumentReference 리소스를 검색할 때 관련성에 따라 검색 결과를 정렬할 수 있습니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
자연어로 검색어를 게시합니다.
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "NATURAL_LANGUAGE_QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec":{"snippetSpec":{"returnSnippet":true}}, "naturalLanguageQueryUnderstandingSpec":{"filterExtractionCondition":"ENABLED"}, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } }'다음을 바꿉니다.
PROJECT_ID: Google Cloud 프로젝트의 ID입니다.APP_ID: 쿼리할 Vertex AI Search 앱의 ID입니다.NATURAL_LANGUAGE_QUERY: '당뇨와 관련된 실험실 결과' 또는 '환자가 현재 약물을 복용하고 있나요?'와 같은 자연어로 된 검색어입니다.PATIENT_ID: 데이터를 검색하려는 환자의 리소스 ID입니다.MATCH_HIGHLIGHTING_CONDITION: 다음 값을 가질 수 있는 문자열입니다.MATCH_HIGHLIGHTING_DISABLED: 모든 문서에서 일치 강조 표시를 사용 중지합니다.MATCH_HIGHLIGHTING_ENABLED: 모든 문서에서 일치 강조 표시를 사용 설정합니다. 이 필드를 비워 두거나 지정하지 않으면 일치 항목 강조 표시가MATCH_HIGHLIGHTING_DISABLED로 설정되고 모든 문서에서 사용 중지됩니다.
생성형 AI 답변이 포함된 자연어 검색어를 사용하여 검색
자연어 검색어를 사용하여 환자의 FHIR 데이터를 검색할 때 검색 결과와 함께 생성형 AI 답변을 받을 수 있습니다. 대답은 검색 결과를 요약하고 대답을 생성하는 데 사용된 참조도 표시합니다.
콘솔을 사용할 때 생성형 AI 대답의 대규모 언어 모델(LLM)을 선택할 수 있습니다. 자세한 내용은 의료 데이터 검색 결과 구성을 참조하세요.
REST API를 사용할 때 다음 LLM 모델 중 하나를 지정하여 version 필드에 생성형 AI 답변을 제공할 수 있습니다.
gemini-1.5-flash-001/answer_gen/v1또는stable:gemini-1.5-flash-001모델을 기반으로 하는 안정적인 정식 버전 모델입니다. 자세한 내용은 정식 버전(GA) 모델을 참조하세요.gemini-1.5-pro-002또는preview:gemini-1.5-pro모델을 기반으로 하는 미리보기 모델입니다.
다음 이미지에서는 생성형 AI 대답이 포함된 자연어 검색어의 예시를 보여줍니다. 검색 요약은 관련 결과의 발견항목을 요약하여 검색어에 대한 답변을 제공합니다. 인용이 있는 세그먼트를 펼쳐 선택한 세그먼트를 생성하는 데 사용된 참조를 확인할 수 있습니다. 생성된 답변 중 일부에만 인용이 포함됩니다.
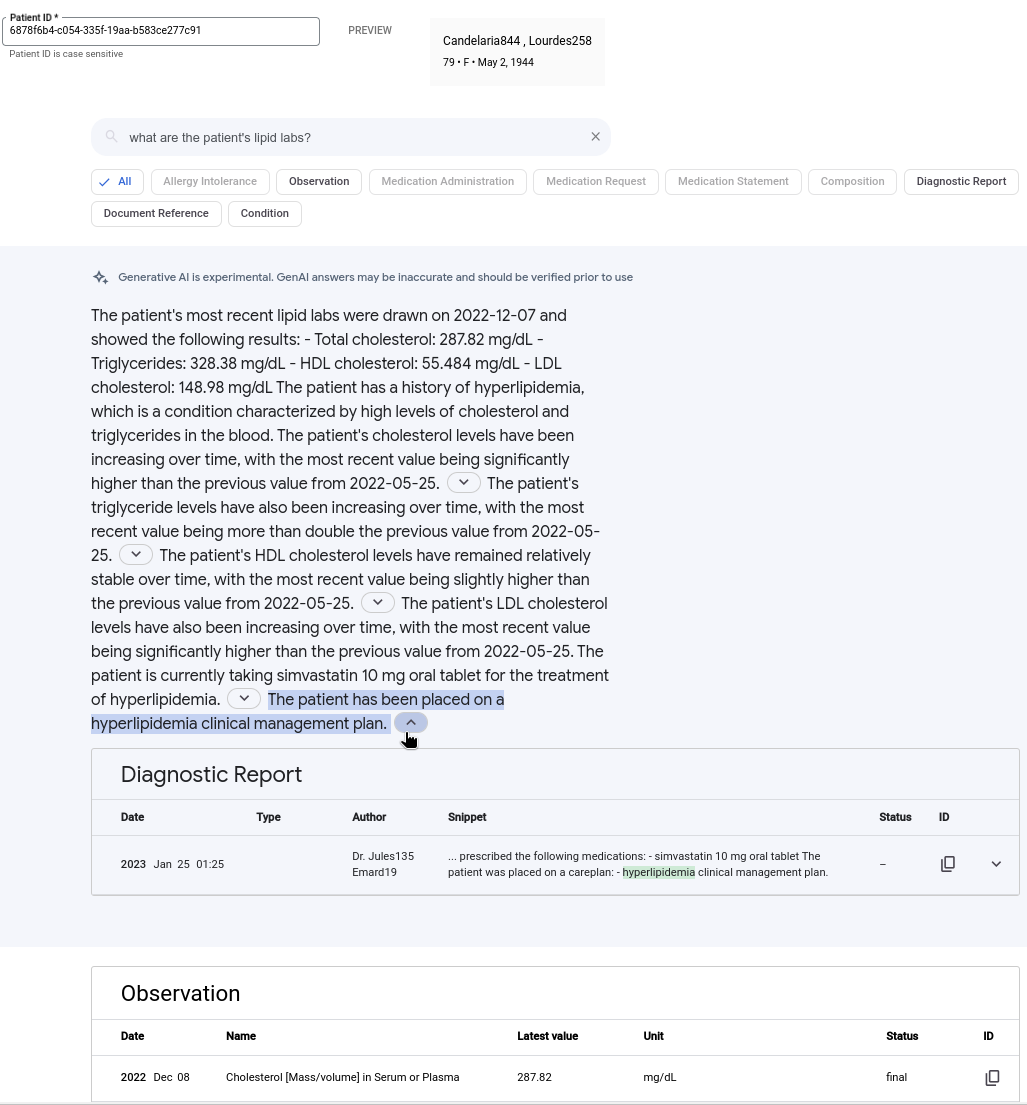
생성형 AI 답변으로 검색하려면 다음을 수행합니다.
콘솔
Google Cloud 콘솔에서 AI 애플리케이션 페이지로 이동합니다.
쿼리할 의료 검색 앱을 선택합니다.
탐색 메뉴에서 구성을 클릭합니다.
검색 위젯을 맞춤설정하려면 다음 안내를 따르세요.
- 검색 유형 필드에서 답변이 포함된 검색을 선택합니다.
- 요약을 생성하는 데 사용할 모델을 선택합니다. 자세한 내용은 의료 데이터 검색 결과 구성을 참조하세요.
- 환경설정을 저장하고 게시합니다.
탐색 메뉴에서 미리보기를 클릭합니다.
환자 ID 필드에 데이터를 쿼리하려는 환자의 환자 ID를 입력합니다. 환자 ID는 대소문자를 구분합니다.
Enter 키를 누르거나 미리보기를 클릭하여 환자 ID를 제출합니다.
여기에서 검색 검색창에 'nsaids', '환자의 지질 실험 결과는 무엇인가요?', '최근 A1C 결과는 무엇인가요?'와 같은 자연어 검색어를 입력합니다.
자동 완성을 사용 설정한 경우 입력할 때 검색창 아래에 자동 완성 추천 용어가 표시됩니다.
Enter 키를 눌러 검색어를 제출합니다.
- 생성형 AI 답변이 검색창 아래에 표시됩니다.
- 검색 결과는 FHIR 리소스 유형에 따라 분류된 페이지가 지정된 테이블에 표시됩니다.
- 기본적으로 모든 FHIR 리소스 유형의 검색 결과는 시간 역순으로 표시됩니다.
선택사항. 인용이 있는 답변의 세그먼트를 펼쳐 검색 결과에서 참조를 확인합니다.
선택사항. 검색창 아래에 있는 FHIR 리소스 카테고리를 하나 이상 선택하여 결과를 필터링합니다.
선택사항. Composition, DocumentReference, DiagnosticReport 리소스 관련성에 따라 결과를 정렬하려면 정렬: 시간 역순 필터를 클릭하고 목록에서 관련성을 선택합니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
REST
다음 샘플에서는 생성형 AI 답변이 포함된 자연어 검색어를 사용하여 의료 검색 앱에서 환자 1명의 FHIR R4 데이터를 검색하는 방법을 보여줍니다.
이 샘플에서는 servingConfigs.search 메서드를 사용합니다.
- 자연어 검색어를 사용하여 검색하려면
naturalLanguageQueryUnderstandingSpec필드를 요청 본문에 추가해야 합니다. - 인라인 인용 색인을 포함하려면
includeCitations필드를 추가해야 합니다. 이 필드는 불리언 필드이며 기본값은false입니다.
기본적으로 검색 결과는 시간 역순으로 반환됩니다. Composition, DiagnosticReport, DocumentReference 리소스를 검색할 때 관련성에 따라 검색 결과를 정렬할 수 있습니다. 자세한 내용은 의료 검색 결과 정렬을 참조하세요.
자연어로 검색어를 게시합니다.
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://us-discoveryengine.googleapis.com/v1alpha/projects/PROJECT_ID/locations/us/collections/default_collection/engines/APP_ID/servingConfigs/default_search:search" \ -d '{ "query": "QUERY", "filter": "patientId: ANY(\"PATIENT_ID\")", "contentSearchSpec": { "snippetSpec": { "returnSnippet": true }, "displaySpec": { "matchHighlightingCondition": "MATCH_HIGHLIGHTING_CONDITION" } "summarySpec": { "summaryResultCount": 1, "includeCitations": true, "modelSpec": { "version": "MODEL_VERSION" } } }, "naturalLanguageQueryUnderstandingSpec": { "filterExtractionCondition": "ENABLED" } }'다음을 바꿉니다.
PROJECT_ID: Google Cloud 프로젝트의 ID입니다.APP_ID: 쿼리할 Vertex AI Search 앱의 ID입니다.QUERY: 'nsaids', '환자의 지질 실험 결과는 무엇인가요?', '최근 A1C 결과는 무엇인가요?'와 같은 자연어로 된 검색어입니다. 검색어에 아포스트로피(')가 포함된 경우 아포스트로피를 아포스트로피의 숫자 문자 참조(')로 바꿔야 합니다.PATIENT_ID: 데이터를 검색하려는 환자의 리소스 ID입니다.MODEL_VERSION: 답변을 생성하는 데 사용할 모델 버전입니다.MATCH_HIGHLIGHTING_CONDITION: 다음 값을 가질 수 있는 문자열입니다.MATCH_HIGHLIGHTING_DISABLED: 모든 문서에서 일치 강조 표시를 사용 중지합니다.MATCH_HIGHLIGHTING_ENABLED: 모든 문서에서 일치 강조 표시를 사용 설정합니다. 이 필드를 비워 두거나 지정하지 않으면 일치 항목 강조 표시가MATCH_HIGHLIGHTING_DISABLED로 설정되고 모든 문서에서 사용 중지됩니다.