Verarbeitungsantwort verarbeiten
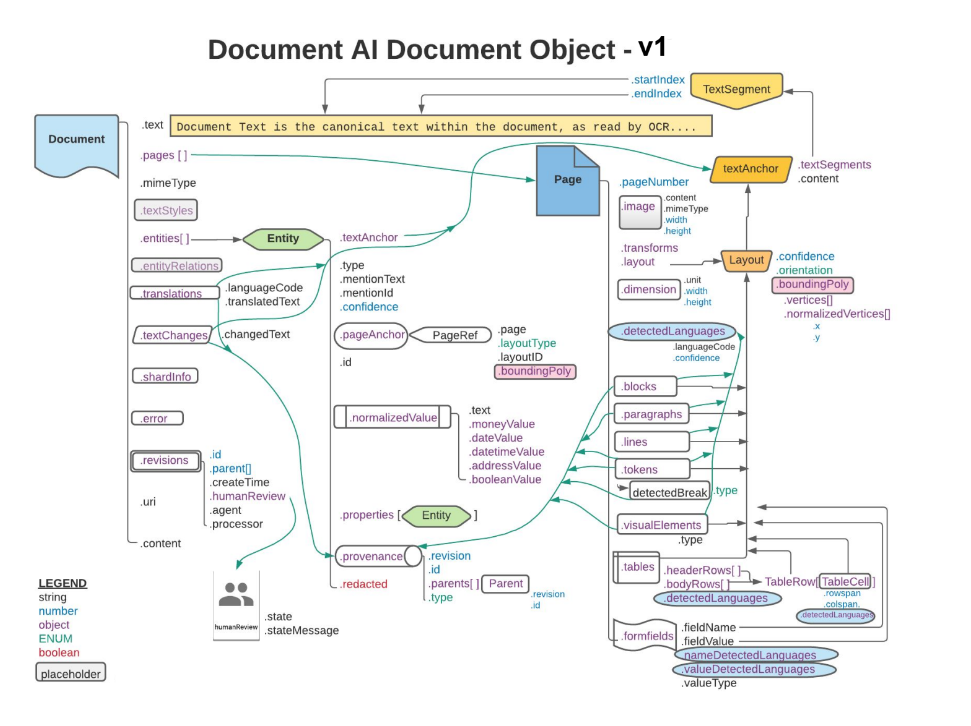
Die Antwort auf eine Verarbeitungsanfrage enthält ein Document-Objekt mit allen bekannten Informationen zum verarbeiteten Dokument, einschließlich aller strukturierten Informationen, die Document AI extrahieren konnte.
Auf dieser Seite wird das Layout des Document-Objekts erläutert. Dazu werden Beispieldokumente bereitgestellt und Aspekte der OCR-Ergebnisse den spezifischen Elementen des Document-Objekt-JSON zugeordnet.
Außerdem finden Sie hier Codebeispiele für Clientbibliotheken und das Document AI Toolbox SDK.
In diesen Codebeispielen wird die Onlineverarbeitung verwendet, die Document-Objektanalyse funktioniert jedoch für die Batchverarbeitung genauso.
Verwenden Sie ein JSON-Anzeige- oder Bearbeitungstool, das speziell zum Ein- und Ausblenden von Elementen entwickelt wurde. Die Überprüfung von rohem JSON in einem Texteditor ist ineffizient.
Text, Layout und Qualitätsfaktoren
Hier ein Beispiel für ein Textdokument:

Hier ist das vollständige Dokumentobjekt, das vom Prozessor Enterprise Document OCR zurückgegeben wird:
Diese OCR-Ausgabe ist auch immer in der Ausgabe des Document AI-Prozessors enthalten, da die OCR von den Prozessoren ausgeführt wird. Dabei werden die vorhandenen OCR-Daten verwendet. Deshalb können Sie solche JSON-Daten mit der Inline-Dokumentoption in Document AI-Prozessoren eingeben.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Hier sind einige der wichtigen Felder:
Rohdaten
Das Feld text enthält den Text, der von Document AI erkannt wird.
Dieser Text enthält keine Layoutstruktur außer Leerzeichen, Tabulatoren und Zeilenumbrüchen. Dies ist das einzige Feld, in dem die Textinformationen eines Dokuments gespeichert werden. Es dient als „Source of Truth“ für den Text des Dokuments. Andere Felder können sich anhand der Position (startIndex und endIndex) auf Teile des Textfelds beziehen.
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Seitengröße und Sprachen
Jedes page im Dokumentobjekt entspricht einer physischen Seite des Beispieldokuments. Die JSON-Beispielausgabe enthält eine Seite, da es sich um ein einzelnes PNG-Bild handelt.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- Das Feld
pages[].detectedLanguages[]enthält die auf einer bestimmten Seite gefundenen Sprachen sowie den Konfidenzwert.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
OCR-Daten
Mit Document AI OCR wird Text mit unterschiedlicher Granularität oder Organisation auf der Seite erkannt, z. B. Textblöcke, Absätze, Tokens und Symbole (die Symbolebene ist optional, wenn die Ausgabe von Daten auf Symbolebene konfiguriert ist). Das sind alles Mitglieder des Seitenobjekts.
Jedes Element hat ein entsprechendes layout, das seine Position und seinen Text beschreibt. Nicht textbasierte visuelle Elemente (z. B. Kästchen) sind ebenfalls auf Seitenebene verfügbar.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
Der Roh-Text wird im textAnchor-Objekt referenziert, das mit startIndex und endIndex in den Haupttextstring indexiert wird.
Bei
boundingPolyist die obere linke Ecke der Seite der Ursprung(0,0). Positive X-Werte befinden sich rechts und positive Y-Werte unten.Das
vertices-Objekt verwendet dieselben Koordinaten wie das Originalbild, währendnormalizedVerticesim Bereich[0,1]liegt. Es gibt eine Transformationsmatrix, die die Entzerrung der Messwerte und andere Attribute der Normalisierung des Bildes angibt.
- Um das
boundingPolyzu zeichnen, zeichnen Sie Liniensegmente von einem Eckpunkt zum nächsten. Schließen Sie das Polygon, indem Sie ein Liniensegment vom letzten zum ersten Eckpunkt zeichnen. Das orientation-Element des Layouts gibt an, ob der Text relativ zur Seite gedreht wurde.
Die folgenden Bilder zeigen Begrenzungspolygone für page.paragraphs, page.lines und page.tokens, um die Struktur des Dokuments zu veranschaulichen.
Absätze

Linien

Tokens

Blöcke

Der Prozessor Enterprise Document OCR kann die Qualität eines Dokuments anhand seiner Lesbarkeit bewerten.
- Sie müssen das Feld
processOptions.ocrConfig.enableImageQualityScoresauftruefestlegen, um diese Daten in der API-Antwort zu erhalten.
Diese Qualitätsbewertung ist ein Qualitätsfaktor in [0, 1], wobei 1 für perfekte Qualität steht.
Der Qualitätsfaktor wird im Feld Page.imageQualityScores zurückgegeben.
Alle erkannten Fehler werden als quality/defect_* aufgeführt und absteigend nach Konfidenzwert sortiert.
Hier sehen Sie ein PDF, das zu dunkel und verschwommen ist, um es bequem lesen zu können:
Hier sind die Informationen zur Dokumentqualität, die vom Prozessor Enterprise Document OCR zurückgegeben werden:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Codebeispiele
Die folgenden Codebeispiele zeigen, wie Sie eine Verarbeitungsanfrage senden und dann die Felder lesen und im Terminal ausgeben:
Java
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Java API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Node.js API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Formulare und Tabellen
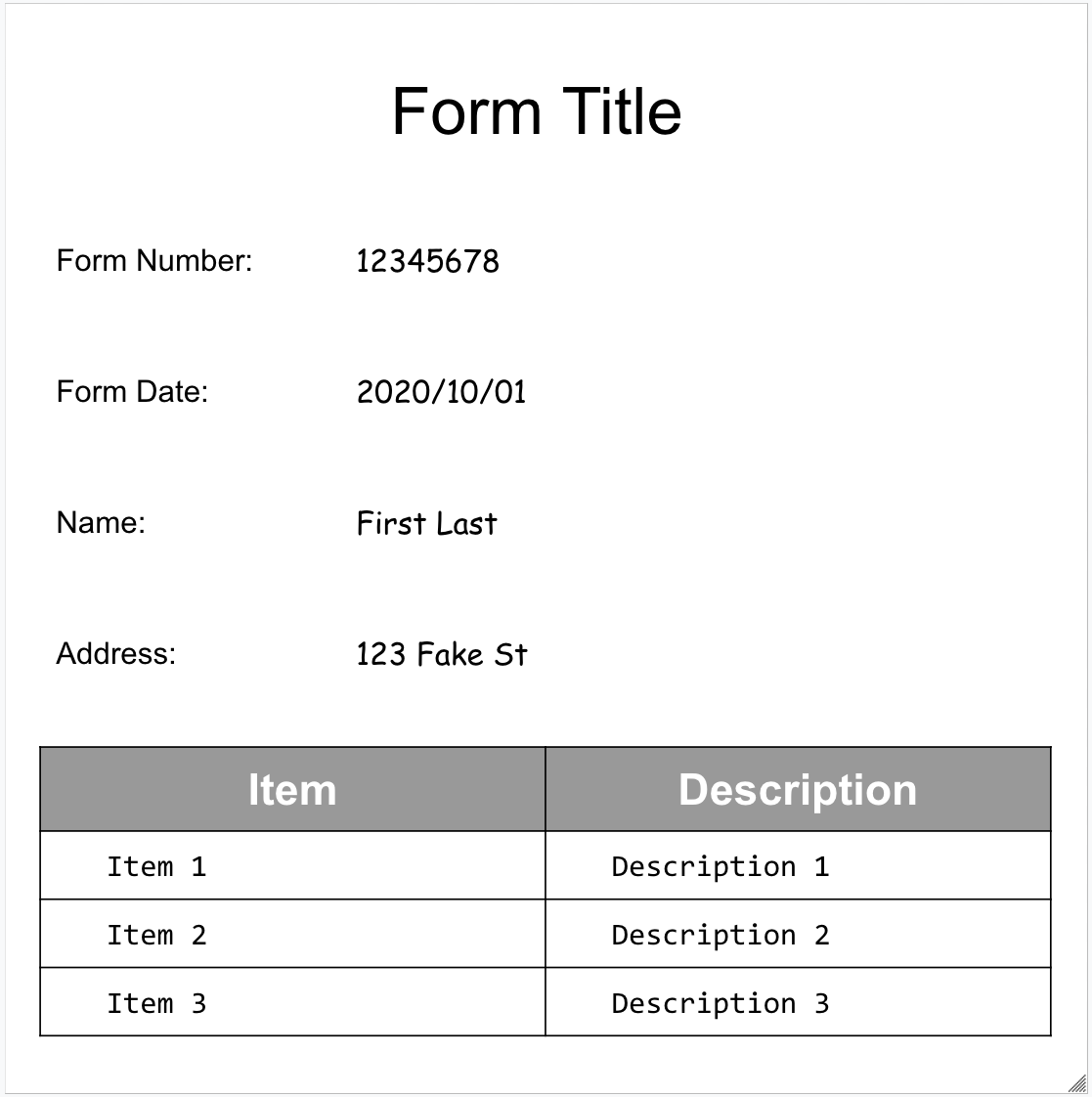
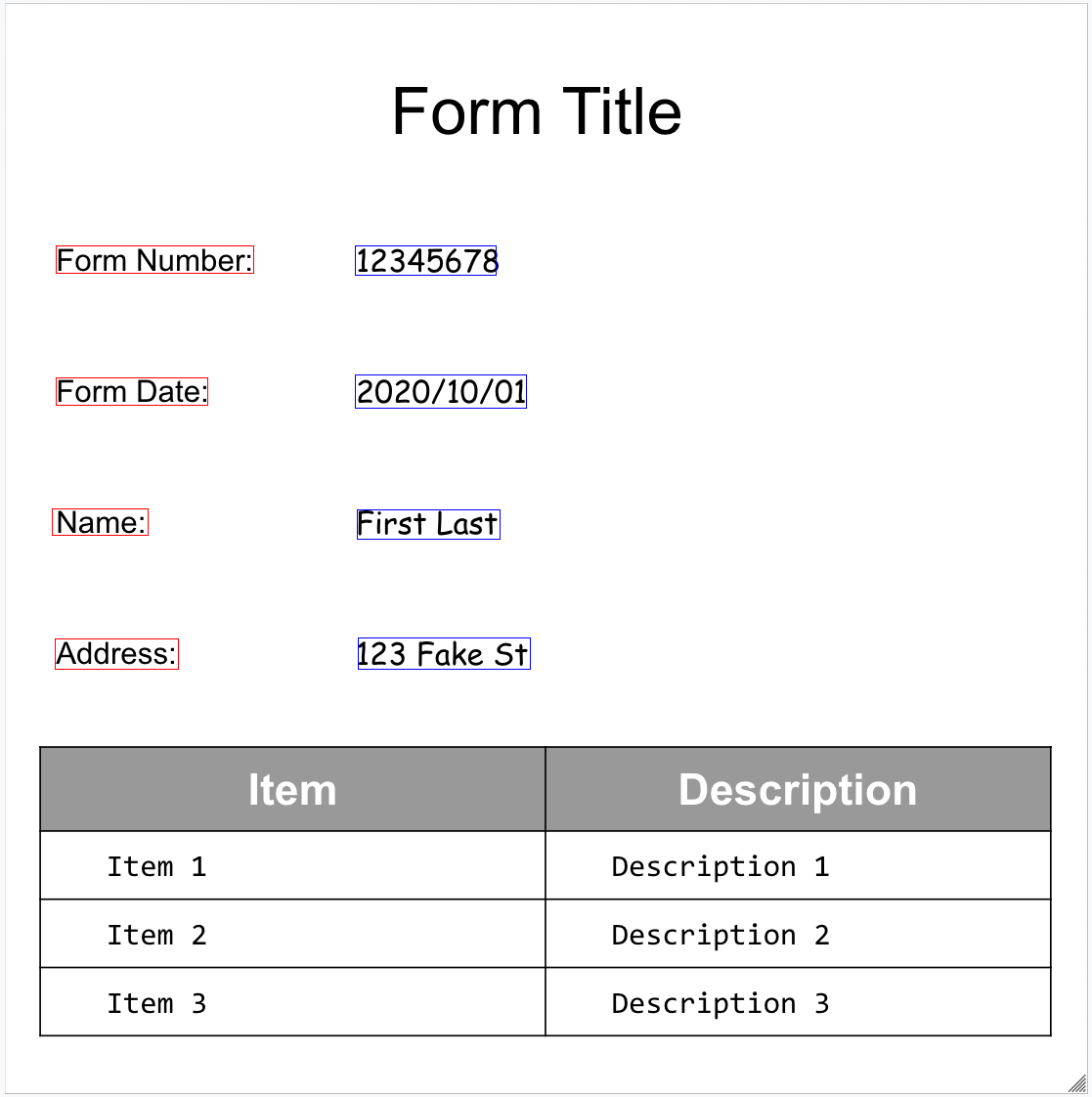
Hier ist unser Musterformular:
Hier ist das vollständige Dokumentobjekt, das vom Formularparser zurückgegeben wird:
Hier sind einige der wichtigen Felder:
Der Formularparser kann FormFields auf der Seite erkennen. Jedes Formularfeld hat einen Namen und einen Wert. Diese werden auch als Schlüssel/Wert-Paare bezeichnet. Beachten Sie, dass sich KVP von (Schema-)Entitäten in anderen Extraktoren unterscheiden:
Entitätsnamen sind konfiguriert. Die Schlüssel in KVPs sind genau der Schlüsseltext im Dokument.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
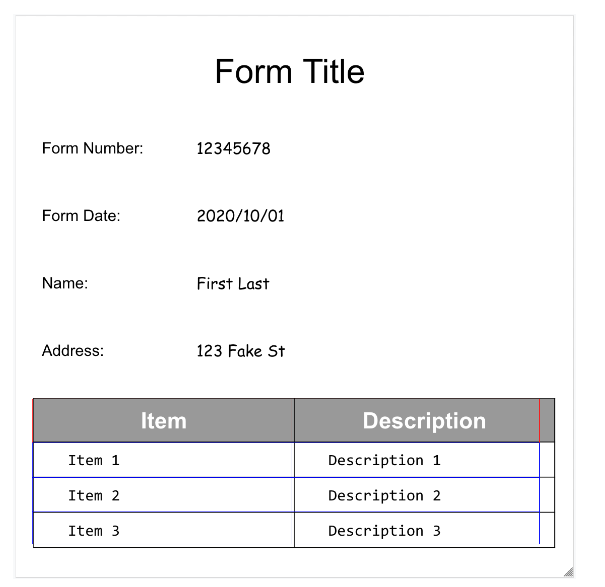
- Document AI kann auch
Tablesauf der Seite erkennen.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Die Tabellenextraktion in Form Parser erkennt nur einfache Tabellen, also solche ohne Zellen, die sich über Zeilen oder Spalten erstrecken. rowSpan und colSpan sind also immer 1.
Ab der Prozessorversion
pretrained-form-parser-v2.0-2022-11-10kann der Formularparser auch generische Entitäten erkennen. Weitere Informationen finden Sie unter Formular-Parser.Die folgenden Bilder zeigen Begrenzungspolygone für
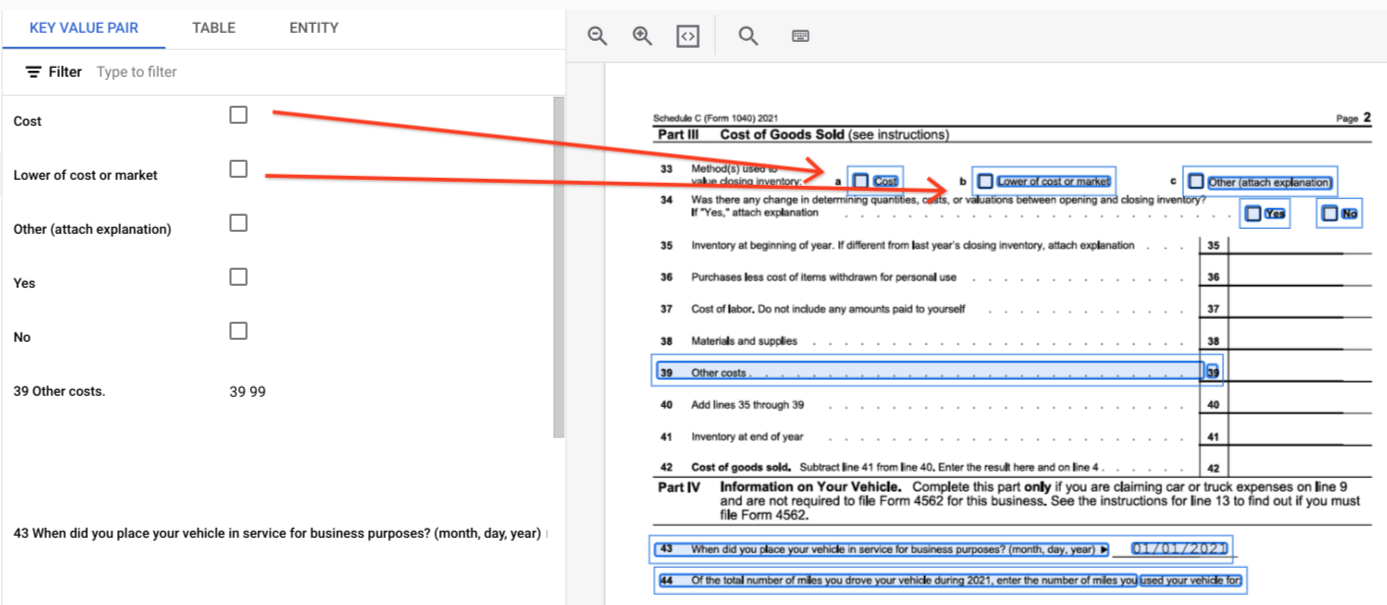
page.formFieldsundpage.tables, um die Struktur des Dokuments zu veranschaulichen.Kästchen in Tabellen. Mit Form Parser können Kästchen aus Bildern und PDFs als KVP digitalisiert werden. Ein Beispiel für die Digitalisierung von Kästchen als Schlüssel/Wert-Paar.
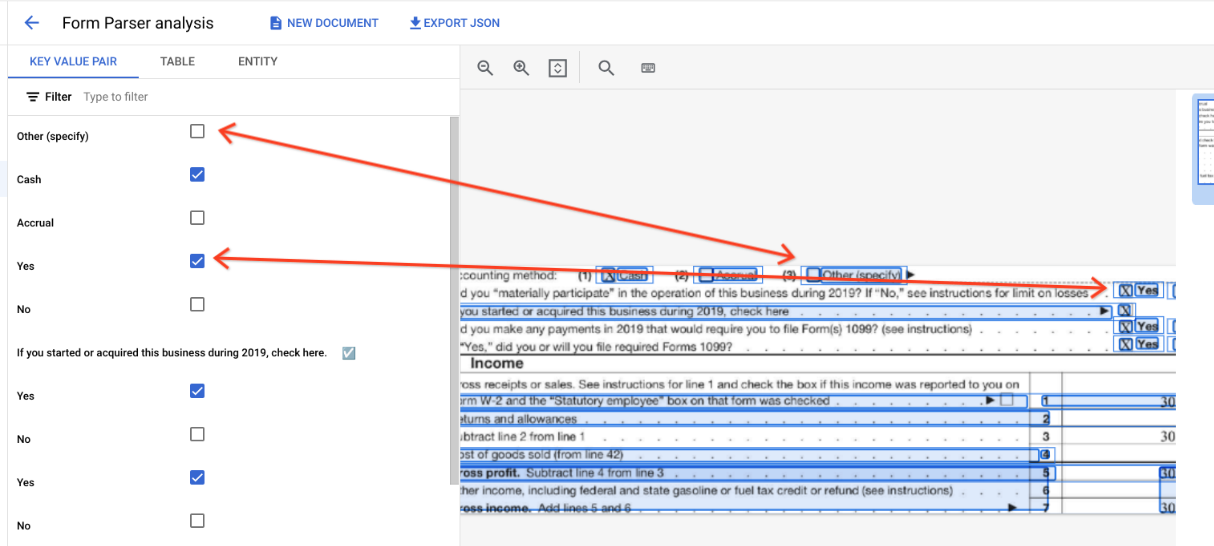
Außerhalb von Tabellen werden Kästchen im Formularparser als visuelle Elemente dargestellt. Hervorhebung der quadratischen Kästchen mit Häkchen in der Benutzeroberfläche und des Unicode-Zeichens ✓ in der JSON-Datei.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
In Tabellen werden Kästchen als Unicode-Zeichen wie ✓ (aktiviert) oder ☐ (deaktiviert) angezeigt.
Die angekreuzten Kästchen haben den Wert filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. Die nicht angekreuzten Kästchen haben den Wert unfilled_checkbox.
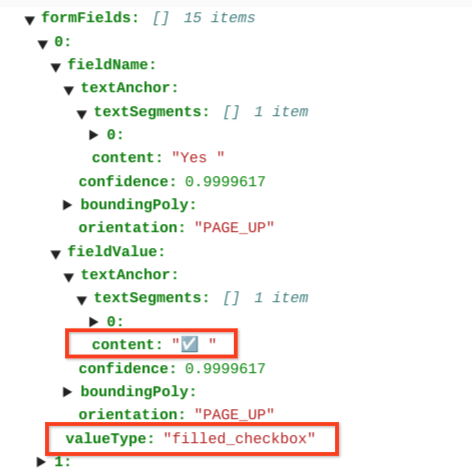
In den Inhaltsfeldern wird der Wert des Kontrollkästchens als hervorgehobenes ✓ unter dem Pfad pages>formFields>x>fieldValue>textAnchor>content angezeigt.
Die folgenden Bilder zeigen Begrenzungspolygone für page.formFields und page.tables, um die Struktur des Dokuments zu veranschaulichen.
Formularfelder
Tabellen
Codebeispiele
Die folgenden Codebeispiele zeigen, wie Sie eine Verarbeitungsanfrage senden und dann die Felder lesen und im Terminal ausgeben:
Java
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Java API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Node.js API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Entitäten, verschachtelte Entitäten und normalisierte Werte
Viele der spezialisierten Prozessoren extrahieren strukturierte Daten, die auf einem genau definierten Schema basieren. Der Rechnungs-Parser erkennt beispielsweise bestimmte Felder wie invoice_date und supplier_name. Hier ist ein Beispiel für eine Rechnung:
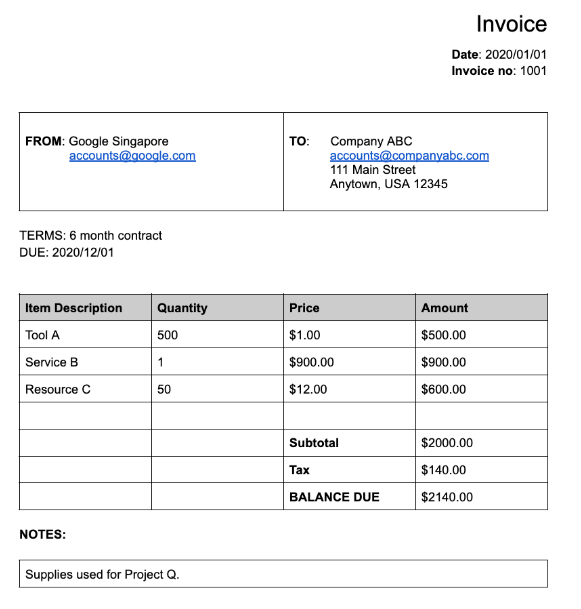
Hier ist das vollständige Dokumentobjekt, das vom Rechnungs-Parser zurückgegeben wird:
Hier sind einige wichtige Teile des Dokumentobjekts:
Erkannte Felder:
Entitiesenthält die Felder, die der Prozessor erkennen konnte, z. B.invoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Bei bestimmten Feldern normalisiert der Prozessor den Wert auch. In diesem Beispiel wurde das Datum von
2020/01/01auf2020-01-01normalisiert.Normalisierung: Für viele bestimmte unterstützte Felder normalisiert der Prozessor auch den Wert und gibt auch ein
entityzurück. Das FeldnormalizedValuewird dem Rohfeld hinzugefügt, das über dietextAnchorjeder Einheit abgerufen wird. Der Literaltext wird normalisiert und der Textwert wird oft in Unterfelder aufgeteilt. Ein Datum wie der 1. September 2024 würde beispielsweise so dargestellt:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
In diesem Beispiel wurde das Datum vom 01.01.2020 in das standardisierte Format 2020-01-01 normalisiert, um die Nachbearbeitung zu reduzieren und die Konvertierung in das ausgewählte Format zu ermöglichen.
Adressen werden auch häufig normalisiert, d. h., die Elemente der Adresse werden in einzelne Felder aufgeschlüsselt. Zahlen werden normalisiert, indem eine Ganzzahl oder eine Gleitkommazahl als normalizedValue verwendet wird.
- Anreicherung: Bestimmte Prozessoren und Felder unterstützen auch die Anreicherung.
Beispiel: Das ursprüngliche
supplier_nameim DokumentGoogle Singaporewurde anhand des Enterprise Knowledge Graph aufGoogle Asia Pacific, Singaporenormalisiert. Da der Enterprise Knowledge Graph Informationen zu Google enthält, leitet Document AI diesupplier_addressab, obwohl sie im Beispieldokument nicht vorhanden war.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Verschachtelte Felder: Verschachtelte Schemas (Felder) können erstellt werden, indem Sie zuerst eine Entität als übergeordnetes Element deklarieren und dann untergeordnete Entitäten unter dem übergeordneten Element erstellen. Die Parsing-Antwort für das übergeordnete Element enthält die untergeordneten Felder im
properties-Element des übergeordneten Felds. Im folgenden Beispiel istline_itemein übergeordnetes Feld mit zwei untergeordneten Feldern:line_item/descriptionundline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Die folgenden Parser halten sich daran:
- Extrahieren (benutzerdefinierter Extrahierer)
- Alt
- Kontoauszugsparser
- Kostenparser
- Rechnungsparser
- Lohnabrechnungsparser
- W2-Parser
Codebeispiele
Die folgenden Codebeispiele zeigen, wie Sie eine Verarbeitungsanfrage senden und dann die Felder eines spezialisierten Prozessors lesen und im Terminal ausgeben:
Java
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Java API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Node.js API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Benutzerdefinierter Dokumentextraktor
Mit dem benutzerdefinierten Dokumentextraktor-Prozessor können benutzerdefinierte Entitäten aus Dokumenten extrahiert werden, für die kein vortrainierter Prozessor verfügbar ist. Dies kann durch das Trainieren eines benutzerdefinierten Modells oder durch die Verwendung von Foundation Models für generative KI erreicht werden, um benannte Einheiten ohne Training zu extrahieren. Weitere Informationen finden Sie unter Benutzerdefinierten Dokumentextraktor in der Console erstellen.
- Wenn Sie ein benutzerdefiniertes Modell trainieren, kann der Prozessor genau wie ein vortrainierter Prozessor zum Extrahieren von Entitäten verwendet werden.
- Wenn Sie ein Fundierungsmodell verwenden, können Sie eine Prozessorversion erstellen, um für jede Anfrage bestimmte Entitäten zu extrahieren. Alternativ können Sie die Konfiguration auch für jede Anfrage einzeln vornehmen.
Informationen zur Ausgabestruktur finden Sie unter Entitäten, verschachtelte Entitäten und normalisierte Werte.
Codebeispiele
Wenn Sie ein benutzerdefiniertes Modell verwenden oder eine Prozessorversion mit einem Basismodell erstellt haben, verwenden Sie die Codebeispiele für die Extraktion von Entitäten.
Das folgende Codebeispiel zeigt, wie Sie bestimmte Entitäten für einen benutzerdefinierten Dokumentextraktor für Foundation Models pro Anfrage konfigurieren und die extrahierten Entitäten ausgeben:
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Zusammenfassung
Der Summarizer-Prozessor verwendet Generative AI Foundation Models, um den extrahierten Text aus einem Dokument zusammenzufassen. Länge und Format der Antwort können auf folgende Weise angepasst werden:
- Länge
BRIEF: Eine kurze Zusammenfassung in ein oder zwei SätzenMODERATE: Eine Zusammenfassung in AbsatzlängeCOMPREHENSIVE: Die längste verfügbare Option
- Format
Sie können entweder eine Prozessorversion für eine bestimmte Länge und ein bestimmtes Format erstellen oder sie pro Anfrage konfigurieren.
Der zusammengefasste Text wird in Document.entities.normalizedValue.text angezeigt. Eine vollständige Beispiel-JSON-Datei für die Ausgabe finden Sie unter Beispiel für die Prozessorausgabe.
Weitere Informationen finden Sie unter Document Summarizer in der Console erstellen.
Codebeispiele
Das folgende Codebeispiel zeigt, wie Sie eine bestimmte Länge und ein bestimmtes Format in einer Verarbeitungsanfrage konfigurieren und den zusammengefassten Text ausgeben:
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Aufteilen und Klassifizieren
Hier ist ein zusammengesetztes 10-seitiges PDF mit verschiedenen Arten von Dokumenten und Formularen:
Hier ist das vollständige Dokumentobjekt, das vom Lending Document-Splitter und -Klassifikator zurückgegeben wird:
Jedes Dokument, das vom Splitter erkannt wird, wird durch ein entity dargestellt. Beispiel:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorGibt an, dass dieses Dokument zwei Seiten lang ist. Beachten Sie, dasspageRefs[].pagenullbasiert ist und den Index für das Felddocument.pages[]darstellt.Entity.typegibt an, dass dieses Dokument ein Formular für Schedule SE (Formular 1040) ist. Eine vollständige Liste der Dokumenttypen, die erkannt werden können, finden Sie in der Prozessordokumentation unter Erkannte Dokumenttypen.
Weitere Informationen finden Sie unter Verhalten von Dokument-Splittern.
Codebeispiele
Trennzeichen identifizieren Seitengrenzen, teilen das Eingabedokument aber nicht tatsächlich für Sie auf. Mit der Document AI Toolbox können Sie eine PDF-Datei anhand der Seitenränder physisch aufteilen. In den folgenden Codebeispielen werden die Seitenbereiche ausgegeben, ohne die PDF-Datei aufzuteilen:
Java
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Java API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Node.js
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Node.js API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Document aufzuteilen.
Python
Weitere Informationen finden Sie in der Referenzdokumentation zur Document AI Python API.
Richten Sie zur Authentifizierung bei Document AI Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Document AI Toolbox
Die Document AI Toolbox ist ein SDK für Python, das Dienstfunktionen zum Verwalten, Bearbeiten und Extrahieren von Informationen aus der Dokumentantwort bietet.
Es wird ein „umschlossenes“ Dokumentobjekt aus einer Antwort für ein verarbeitetes Dokument aus JSON-Dateien in Cloud Storage, lokalen JSON-Dateien oder der direkten Ausgabe der Methode process_document() erstellt.
Sie kann die folgenden Aktionen ausführen:
- Kombinieren Sie fragmentierte
Document-JSON-Dateien aus der Batchverarbeitung in einem einzelnen „umschlossenen“ Dokument. - Shards als einheitliche
Documentexportieren. -
Document-Ausgabe abrufen von: - Zugriff auf Text aus
Pages,Lines,Paragraphs,FormFieldsundTables, ohneLayout-Informationen zu verarbeiten. - Suchen Sie nach einem
Pages, das einen Zielstring enthält oder einem regulären Ausdruck entspricht. - Suchen Sie nach
FormFields. - Nach
Entitiesnach Typ suchen. - Konvertieren Sie
Tablesin einen Pandas-DataFrame oder eine CSV-Datei. - Fügen Sie
EntitiesundFormFieldsin eine BigQuery-Tabelle ein. - Eine PDF-Datei basierend auf der Ausgabe eines Splitter-/Klassifikatorprozessors aufteilen.
- Extrahiere das Bild
Entitiesaus denDocument-Begrenzungsrahmen. -
Documentsin häufig verwendete Formate konvertieren und umgekehrt:- Cloud Vision API
AnnotateFileResponse - hOCR
- Formate für die Dokumentverarbeitung durch Drittanbieter
- Cloud Vision API
- Erstellen Sie Batches von Dokumenten zur Verarbeitung aus einem Cloud Storage-Ordner.
Codebeispiele
Die folgenden Codebeispiele zeigen, wie Sie die Document AI Toolbox verwenden.